







目录
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Mahalanobis distance-based detector
前言
本次要介绍的文章是deep Mahalanobis detector,顾名思义,这是一篇基于马氏距离来做OOD样本检测的文章。另外文章中还提出了如何检测对抗攻击样本,也就是我们之前用FGSM方法得到的那些样本。我们暂时只关注OOD检测,要了解对抗攻击的细节可以阅读文章中的相关章节。
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
论文链接:https://arxiv.org/pdf/1807.03888.pdf
在这篇文章中,作者用马氏距离来作为“置信度”,并且给出了一种形式上的连续学习的方法。但是需要说明的一点是,改文章显式使用了OOD数据来训练检测器,因此,在你的文章中,此方法可能并不适合直接与其他技术进行比较,可以考虑将本文的指标作为一个OOD检测的upper bound。
Motivation
作者考虑到可能仅仅通过卷积神经网络最后的分类层输出信息不足以判断OOD和ID数据,因此,作者充分利用卷积神经网络的每一个特征层,并在此基础上,计算马氏距离,得到一个类似于生成式模型的检测器。要想这么做需要满足一个前提:那就是卷积神经网络的每层特征是符合多元高斯分布的,这样才可以计算马氏距离。当然,这是一个假设,并不容易验证。
Mahalanobis distance-based detector
对于一个按照有监督学习方式训练好的分类器,通过前向传播我们可以获得每一个卷积层上的特征,从而就可以计算出每个类别在每个卷积层的均值,以及所有样本在每个卷积层的协方差矩阵。
利用上面的表达式,我们就可以得到每个卷积层的协方差矩阵,以及每个类别在每个卷积层上的均值。协方差矩阵是一个方针,维度等于特征图的尺寸,也就是。有了上述定义,对于一个新的样本
,我们可以通过选择最小的马氏距离来判断其类别:
上式中的便可以用来作为置信度得分,可以直接与真实标签计算AUROC以及AUPR等指标。对应的,样本的类别就是使得置信度得分最高的下标
,即:
在上述的过程中,我们一直没有表明使用的是哪一层的特征。在原文中,作者为了增强算法的检测性能,使用了全部特征层马氏距离的加权结果来作为置信度,并在,在该过程中,还使用了ODIN中提出的Input Preprocessing方法来进一步拉开ID数据与OOD数据之间的差异,算法的详细流程如下:

算法的流程比较清晰,对于每一个卷积层,先判断样本的类别,然后利用Input Preprocessing方法进一步提升马氏距离得分(即马氏距离的相反数),然后利用处理后的样本计算置信度得分。最后输出的得分是每一层马氏距离得分的加权值。
这里需要说明一下,就是计算AUROC以及AUPR时,只需要给出预测的置信度得分即可,这里的置信度并不限制数值范围,只要与标签一致即可:也就是说,如果标签中1代表ID数据,0代表OOD数据,那么你的置信度得分应该是越大越代表是ID数据,越小越代表OOD数据。这是因为AUROC和AUPR是基于排序来逐个选择阈值的。在本文中,作者使用的是马氏距离的相反数来表示样本来自于ID的置信度。
另外,在文章中,权重系数是这样得到的:在每一层的特征上训练一个二分类器(逻辑回归),将二分类器对ID数据和OOD数据的分类准确率作为本层马氏距离得分的组合系数。从文章的代码来看,作者是直接使用了OOD数据参加训练来得到该系数,因此,相当于利用了额外的信息,分类性能好的层权重就会很高,而分类性能差的层,权重就较低。但是,在实际中,我们无法预料OOD数据的分布,也就无法判断哪一层更重要,因此该方法存在一些值得商榷的地方。
Incremental Learning
除了检测OOD数据之外,作者还提供了一种适用于连续学习或者是增长学习的方法。对于一个新的类别,直接在每一层的特征上计算新类别的均值,然后使用滑动平均的思想,将协方差矩阵更新为原来的协方差矩阵与新类别协方差矩阵的加权和,加权系数为类别数量的占比。详细的算法流程如下,是很容易理解的:

这种连续学习的方法,如果新的类别数据本身就能够被原来的卷积神经网络在特征空间聚集在一起,那么它的性能是不错的,但是往往卷积神经网络对于新类别数据并不能很好的处理,常常倾向于将新类别数据与原始数据混淆,从而使得方法失效。
Experiments
作者给出了在OOD检测、连续学习以及对抗样本攻击等实验上的结果,这里我们只关注一下OOD检测的效果:
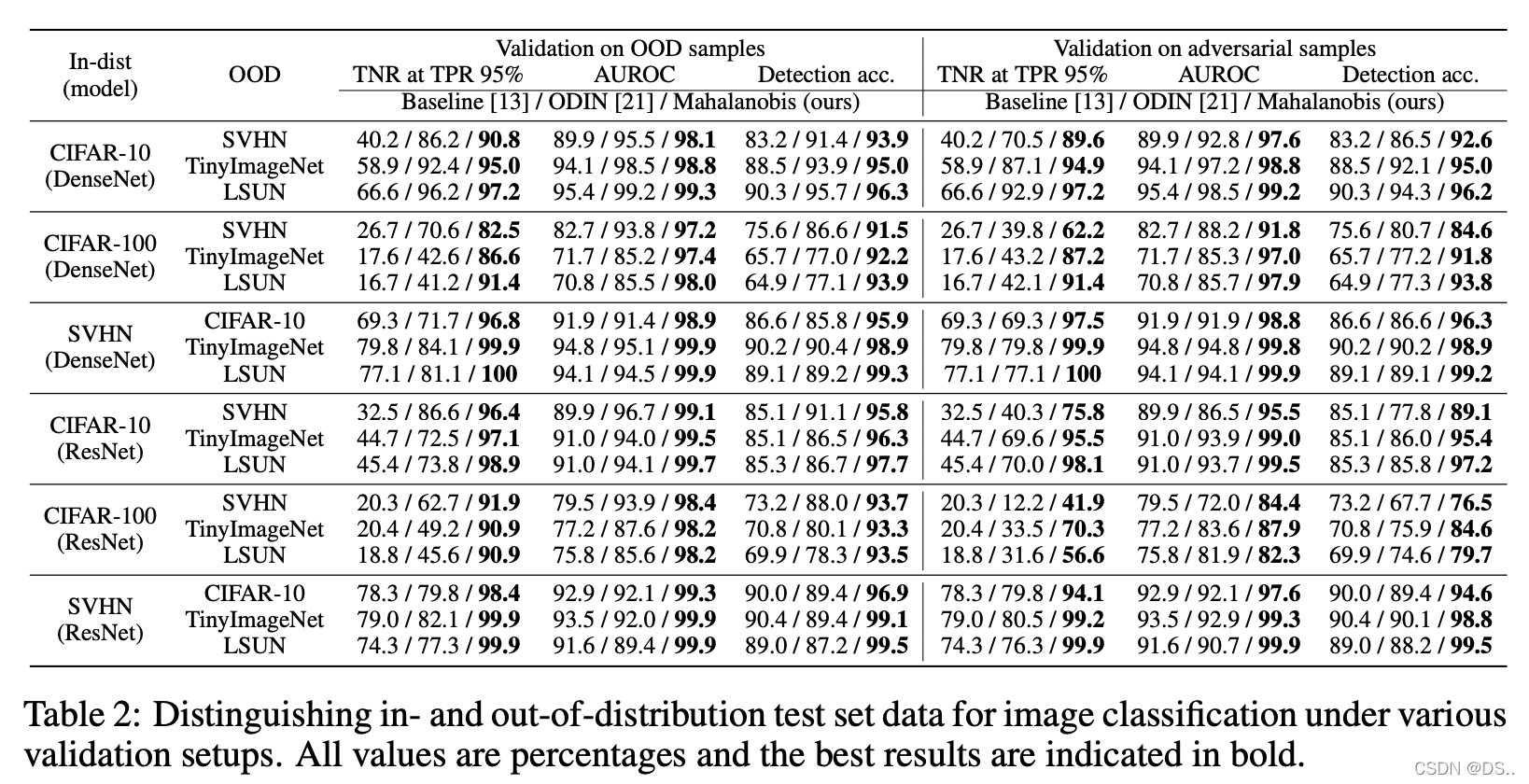
从上表可以看出,deep Mahalanobis detector的性能是超过了Max-Softmax以及ODIN的,但是有一点我们要注意,就是这个方法使用了OOD数据,所以表格中的结果会远远高于未使用OOD数据的Max-Softmax方法以及之前介绍过的ODIN方法。不过,我们还是可以从这个方法中得到一些启发:检测OOD数据要充分利用分类网络各层的特征,从而增强检测的鲁棒性。
最后展示一下作者尝试过的不同距离度量的性能差异:
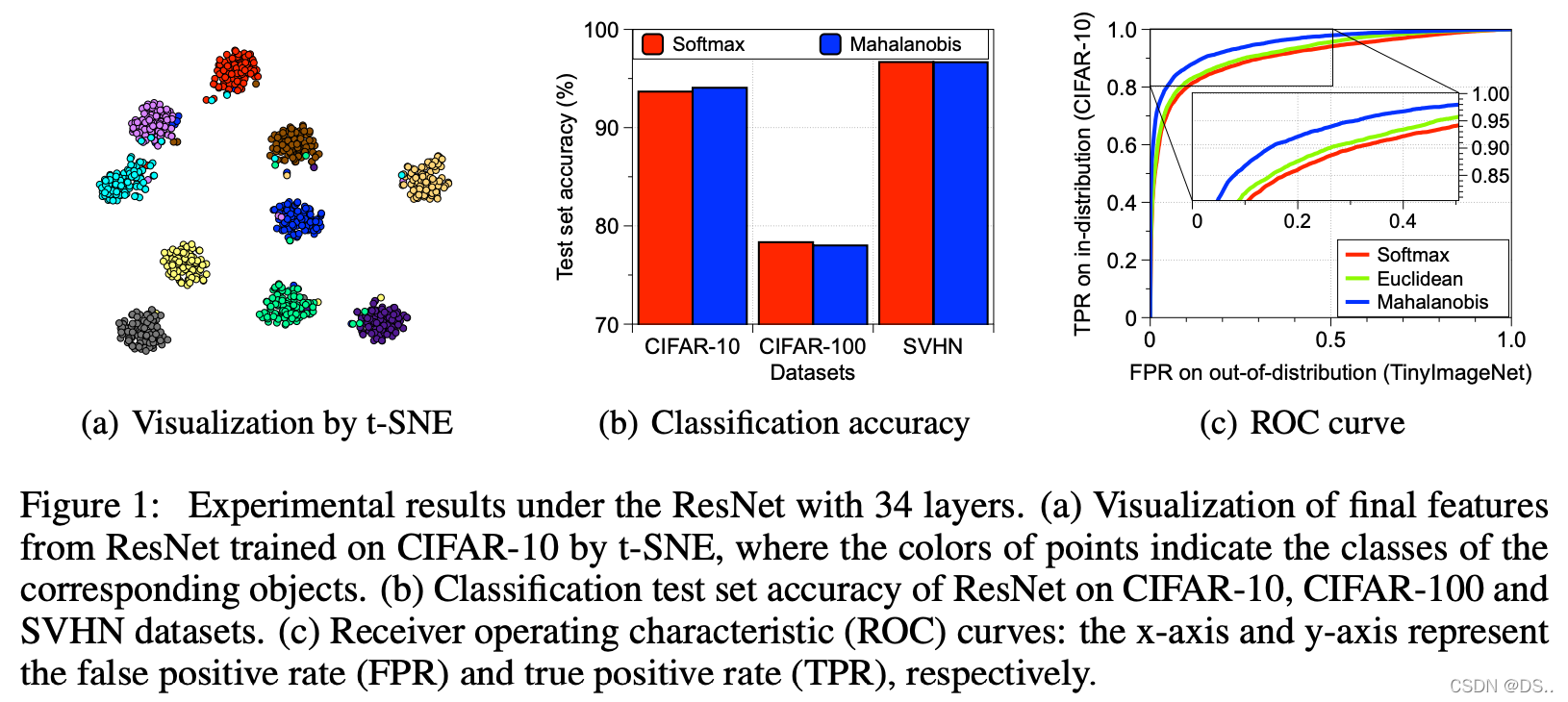
可以看出,马氏距离要好于直接使用Softmax或者是欧氏距离等方法,更多的实验细节可参考原始论文。

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









