






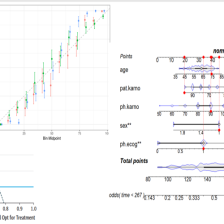
关于临床预测模型的基础知识,小编之前已经写过非常详细的教程,包括了临床预测模型的定义、常用评价方法、列线图、ROC曲线、IDI、NRI、校准曲线、决策曲线等。
全都是免费获取的代码和数据:R语言临床预测模型合集
临床预测模型进阶系列目前已推出随机生存森林系列推文:
关于临床预测模型的基础知识,小编之前已经写过非常详细的教程,包括了临床预测模型的定义、常用评价方法、列线图、ROC曲线、IDI、NRI、校准曲线、决策曲线等。
全都是免费获取的代码和数据:R语言临床预测模型合集
临床预测模型进阶系列目前已推出随机生存森林系列推文:
 8079
261
8079
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























