







前面的推文已经给大家介绍了机器学习中特征选择的常见方法,以及目前在R语言中的实现情况,主要就是3个包:caret、mlr3、tidymodels
今天给大家介绍caret中的递归特征消除法。
递归特征消除(recursive feature elimination, rfe)是变量筛选的方法之一,属于包装法,同时也是向后选择法。
caret中的rfe的基本做法是这样的:对模型进行多次训练,每次训练后消除不重要的特征(这个可以用变量重要性、变量的系数等衡量,不同算法有不同的衡量标准),再使用剩下的特征继续训练。
在caret中通过rfeIter和rfe分别实现递归特征消除和交叉验证的递归特征消除。
rfeIter
做法如下:
-
在训练集中使用所有的预测变量进行建模
-
计算模型表现
-
计算变量重要性并进行排序
-
对每一个样本量大小为S[i],i = 1,2…,S的子集
- 保留S[i]个最重要的变量
- [可选]预处理数据
- 用保留的S[i]个变量在训练集中建模
- 计算模型表现
- [可选]重新计算变量重要性
-
结束
-
计算每个子集的模型表现
-
决定合适的变量个数(即最优的模型对应的变量)
-
使用最优的变量拟合最终的模型
交叉验证rfe
单纯的递归特征消除容易出现过拟合问题,所以出现了交叉验证的递归特征消除(rfecv)。rfecv实现了对整个变量选择过程的重抽样,因此可以获得更加准确的结果。
它的步骤如下:
-
对每一次重抽样做以下事情:
-
重抽样把数据划分为训练集/测试集
-
使用训练集中的所有预测变量进行建模
-
计算模型表现
-
计算变量重要性或者排序
-
对每一个样本量大小为S[i],i = 1,2…,S的子集:
- 保留S[i]个最重要的变量
- [可选]预处理数据
- 用保留的S[i]个变量在训练集中建模
- 在测试集计算模型表现
- [可选]重新计算变量重要性
-
结束
-
-
结束
-
在测试集中计算每个子集的模型表现
-
决定合适的预测变量数量
-
决定最终的预测变量
-
用最初的训练集和最终的预测变量拟合最终模型
rfecv包含两层循环,举个例子,比如最开始的一层循环我们是用10折交叉验证,10折交叉验证把数据分为10份,其中9折用来进行变量选择,剩下的1折用来评估每个变量子集的模型表现。整个变量选择的过程会重复进行10次,最终会得到10个变量子集,选择最好的那个,然后拟合最终的模型。
说起来蛮复杂的,不理解也问题不大,我知道你们只是想要一个牛逼的结果而已…
上面这么多步骤只需要rfe函数即可完成,不用担心,简单得很!
以下是交叉验证递归特征消除的演示,使用rfe函数实现,rfeIter就不演示了。
caret实操
caret支持非常多的模型,可以做递归特征消除,有几个是已经预定义好的,可以写上名字直接用:
- 线性回归
lmFuncs, - 线性判别分析
ldaFuncs, - 广义线性模型
gamFuncs - 逻辑回归
lrFuncs - 随机森林
rfFuncs, - 朴素贝叶斯
nbFuncs, - 袋装树
treebagFuncs
除此之外,所有train()函数可以用的模型,都能做递归特征消除。下面会演示用法。如果你不知道train能用的模型有哪些,参考这篇推文:caret可视化
caret中通过rfe实现交叉验证的递归特征消除,rfe函数有几个主要的参数:
x:预测变量,可以是矩阵或者数据框y:结果变量,需要数值型或者因子型向量,a vector (numeric or factor) of outcomessizes:整数型向量,每次迭代留下的重要性比较高的特征数量,结合下面的例子理解metric:模型评价指标,分类默认Accuracy和Kappa,回归默认RMSE和MAErfecontrol:选择算法,重抽样方法等
用caret自带的BloodBrain数据集进行演示。
Mente和Lombardo(2005)开发了预测大脑中化合物浓度与血液中化合物浓度比值对数的模型。对于每一种化合物,他们计算了三组描述分子的变量:MOE 2D、rule-of-five和Charge Polar Surface Area (CPSA)。
其中数据集bbbDescr总共有134列(134个描述分子性质的预测变量),208行(208个分子化合物)。向量logBBB是浓度比值的对数,是结果变量。
library(caret)
## Loading required package: ggplot2
## Loading required package: lattice
# 加载后会在当前环境下出现自变量数据框bbbDescr,因变量是logBBB
data(BloodBrain)
psych::headTail(bbbDescr)
## tpsa nbasic negative vsa_hyd a_aro weight peoe_vsa.0 peoe_vsa.1 peoe_vsa.2
## 1 12.03 1 0 167.07 0 156.29 76.95 43.45 0
## 2 49.33 0 0 92.64 6 151.16 38.24 25.52 0
## 3 50.53 1 0 295.17 15 366.48 58.05 124.74 21.65
## 4 37.39 0 0 319.11 15 382.55 62.24 124.74 13.19
head(logBBB)
## [1] 1.08 -0.40 0.22 0.14 0.69 0.44
首先对这个数据做一下数据预处理,如果你看不懂下面这段代码,强烈建议你先看前面的推文:R语言机器学习caret-02:数据预处理
x <- scale(bbbDescr[,-nearZeroVar(bbbDescr)])
x <- x[, -findCorrelation(cor(x), .8)]
x <- as.data.frame(x, stringsAsFactors = TRUE)
psych::headTail(x)
## nbasic peoe_vsa.0 peoe_vsa.1 peoe_vsa.2 peoe_vsa.3 peoe_vsa.4 peoe_vsa.5
## 1 1.31 0.4 -0.81 -0.88 -0.76 -0.63 -0.56
## 2 -0.76 -0.72 -1.25 -0.88 -0.16 1.9 -0.56
## 3 1.31 -0.15 1.22 0.39 -0.16 1.27 -0.56
## 4 -0.76 -0.03 1.22 -0.1 0.74 -0.63 -0.56
线性回归
接下来演示一个基于线性回归的递归特征消除,数据量少选择自助法比较好,重抽样方法选择也是一门学问,可以参考之前的推文:临床预测模型和机器学习中的重抽样问题
# 加速
library(future)
##
## Attaching package: 'future'
## The following object is masked from 'package:caret':
##
## cluster
plan("multisession",workers=8)
# 设置rfe的选项
set.seed(1)
rfeControl = rfeControl(functions = lmFuncs,
method = "cv", # 默认自助法重采样 boot
saveDetails = T, # 保存预测值和变量重要性
number = 5, # 重抽样次数
allowParallel = T # 允许多线程,用这个之前你要先准备好多线程!
)
定义好之后,下面是正式进行特征选择:
sizes这么理解:这里如果设置为sizes = c(1:71),意思就是我们要在所有的变量子集中寻找最优的,一共只有71个预测变量,就是要在1,2,3,。。。,71,每一个数量的变量子集都要试一下。
set.seed(1)
lmProfile <- rfe(x, logBBB,
sizes = c(2:25, 30, 35, 40, 45, 50, 55, 60, 65),
rfeControl = rfeControl
)
运行结束之后,即可查看结果:
# 查看运行结果
lmProfile
##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (5 fold)
##
## Resampling performance over subset size:
##
## Variables RMSE Rsquared MAE RMSESD RsquaredSD MAESD Selected
## 2 0.7820 0.01385 0.6135 0.04318 0.01540 0.04276
## 3 0.7917 0.04226 0.6235 0.04771 0.06134 0.04531
## 4 0.7801 0.06268 0.6101 0.06865 0.09728 0.05553
## 5 0.7495 0.11827 0.5840 0.08888 0.16112 0.06200
## 6 0.7377 0.13665 0.5716 0.08566 0.16106 0.06741
## 7 0.7309 0.15437 0.5700 0.05845 0.08013 0.03619
## 8 0.7153 0.18904 0.5546 0.06004 0.09937 0.02895
## 9 0.6984 0.22469 0.5471 0.07742 0.12875 0.05199
## 10 0.6976 0.22220 0.5511 0.07632 0.12143 0.05549
## 11 0.6694 0.28289 0.5244 0.06061 0.06490 0.03248
## 12 0.6648 0.29297 0.5242 0.05517 0.05391 0.02942
## 13 0.6642 0.29852 0.5250 0.06342 0.07266 0.03543
## 14 0.6531 0.32167 0.5137 0.08665 0.12619 0.05820
## 15 0.6584 0.32371 0.5089 0.08956 0.13920 0.05879
## 16 0.6423 0.35466 0.4944 0.10306 0.15733 0.08299
## 17 0.6532 0.34422 0.5054 0.10736 0.14515 0.08796
## 18 0.6525 0.35123 0.5032 0.11508 0.15685 0.09495
## 19 0.6546 0.34789 0.5007 0.10632 0.14159 0.09047
## 20 0.6341 0.37890 0.4858 0.07458 0.08931 0.06239
## 21 0.6359 0.37810 0.4873 0.07951 0.09254 0.06605
## 22 0.6288 0.39270 0.4838 0.08384 0.09001 0.06214 *
## 23 0.6313 0.38975 0.4870 0.08167 0.08728 0.06092
## 24 0.6408 0.37938 0.4939 0.07783 0.07434 0.06306
## 25 0.6395 0.37862 0.4920 0.07773 0.07582 0.06751
## 30 0.6983 0.32262 0.5157 0.09891 0.09837 0.07248
## 35 0.7193 0.29867 0.5234 0.10489 0.09395 0.08779
## 40 0.7079 0.33202 0.5195 0.10378 0.09336 0.07573
## 45 0.7518 0.29916 0.5602 0.07306 0.06445 0.05038
## 50 0.7484 0.30170 0.5592 0.07480 0.05449 0.05324
## 55 0.7477 0.31832 0.5532 0.09521 0.08273 0.06976
## 60 0.7661 0.30018 0.5661 0.08239 0.05746 0.06844
## 65 0.7624 0.30845 0.5688 0.08959 0.07645 0.07412
## 71 0.7598 0.30810 0.5658 0.08384 0.07334 0.06893
##
## The top 5 variables (out of 22):
## hardness, homo, lumo, pnsa1, fnsa2
结果告诉我们很多信息,比如外层循环使用的重抽样方法是Bootstrapped;
然后给出了不同数量的特征子集的模型表现,Variables这一列是使用的特征数量,可以看到最后有个71特征,明明我们设置的特征数量是sizes = c(2:25, 30, 35, 40, 45, 50, 55, 60, 65),最多就是65,为啥会有71呢?因为你看上面那个步骤,在最开始都是要用全部特征拟合模型的!
剩下的几列是模型性能指标,最后一列Selected是选中的模型,有*的就是被选中的,特征数量是22个。此时的RMSE是0.6288,Rsquared是0.39270。
最后给出了前5个选中的变量。
通过以下代码查看选中的22个变量是哪些:
# 查看选中的变量
predictors(lmProfile)
## [1] "hardness" "homo" "lumo"
## [4] "pnsa1" "fnsa2" "o_sp2"
## [7] "fnsa1" "peoe_vsa.5.1" "a_base"
## [10] "most_positive_charge" "vsa_base" "rotatablebonds"
## [13] "peoe_vsa.6" "peoe_vsa.6.1" "rpcg"
## [16] "peoe_vsa.1" "vsa_other" "smr_vsa0"
## [19] "ovality" "rdta" "fpsa3"
## [22] "clogp"
清楚明白!
结果也可以使用图形方式查看,下面这两张图就是大家经常看到的图了,你可以自己用ggplot2语法美化:
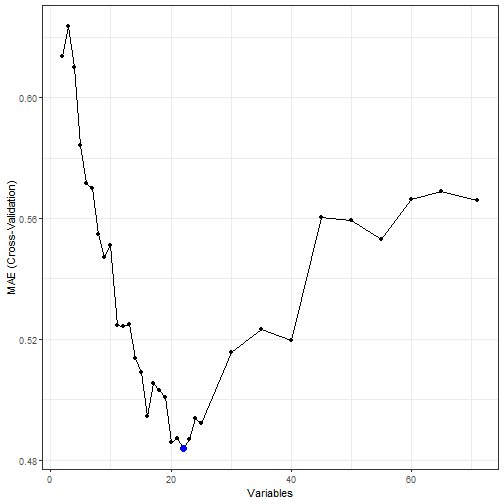
ggplot(data = lmProfile, metric = "RMSE") + theme_bw()
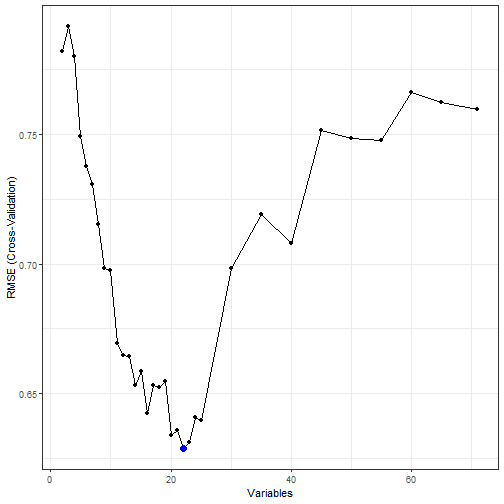
ggplot(data = lmProfile, metric = "MAE") + theme_bw()
查看变量重要性:
varImp(lmProfile)
## Overall
## hardness 307.2096022
## homo 246.7418439
## lumo 192.4442402
## pnsa1 0.9009845
## fnsa1 0.6431244
## o_sp2 0.6270888
## peoe_vsa.5.1 0.5879659
## fnsa2 0.5682413
## most_positive_charge 0.5538182
## rdta 0.5436882
## prx 0.5390927
## andrewbind 0.5334340
## vsa_base 0.5084030
## peoe_vsa.1 0.5020039
## rotatablebonds 0.4785500
## a_base 0.4717276
## tcsa 0.4636548
## mlogp 0.4626432
## peoe_vsa.6.1 0.4526228
## vsa_other 0.4465362
## ovality 0.4464361
## fpsa3 0.4400715
## rpcg 0.4293029
## peoe_vsa.6 0.4221961
## smr_vsa0 0.4015024
## adistd 0.3485839
## slogp_vsa5 0.3426358
## clogp 0.3399694
## chaa2 0.3298837
## peoe_vsa.4.1 0.3285177
## peoe_vsa.5 0.3219318
## wncs 0.3124847
## smr_vsa4 0.3119868
## ub 0.3096761
## slogp_vsa9 0.3094456
## frac.cation7. 0.3013126
## chaa3 0.2795578
## most_negative_charge 0.2775598
## peoe_vsa.3 0.2765230
## o_sp3 0.2750614
## n_sp2 0.2535690
## smr_vsa7 0.2404868
## n_sp3 0.2091113
## peoe_vsa.1.1 0.2014472
只看数字不够直观,可以把变量重要性画图展示,方法非常简单:
varimp_data <- data.frame(feature = row.names(varImp(lmProfile))[1:22],
importance = varImp(lmProfile)[1:22, 1])
ggplot(data = varimp_data, aes(x = reorder(feature, -importance),
y = importance, fill = feature)) +
geom_bar(stat="identity") +
labs(x = "Features", y = "Variable Importance") +
geom_text(aes(label = round(importance, 2)), vjust=1.6, color="white", size=4) +
theme_bw() +
theme(legend.position = "none", axis.text.x = element_text(angle = 45,hjust = 1))
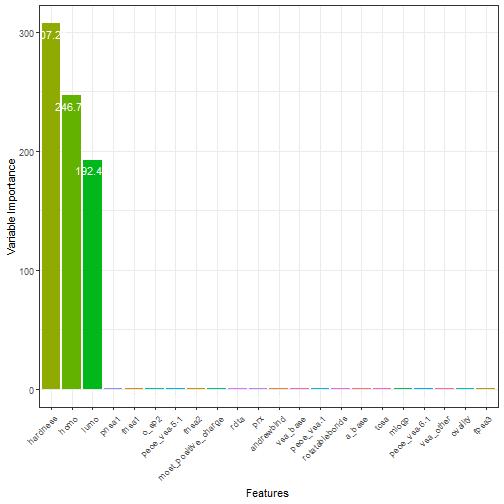
可以看到前3个变量重要性远远超过其他变量!这个图不是很常见,大家可以赶紧用起来!
如果你在一开始划分了训练集/测试集,那此时你就可以使用这22个选中的变量查看在测试集中的表现了,不过我们一开始并没有划分,所以就用原数据集演示了:
# 其实这里应该用测试集
postResample(predict(lmProfile, x), logBBB)
## RMSE Rsquared MAE
## 0.5016721 0.5836101 0.3834269
如果要使用选中的这22变量对新的数据集进行预测,也是非常简单:
# 直接使用predict即可
predict(lmProfile, head(x))
## 1 2 3 4 5 6
## 0.22346973 -0.52855194 -0.09119803 0.29685104 0.22498362 0.15485051
查看每一次迭代结果:
head(lmProfile$resample)
## Variables RMSE Rsquared MAE Resample
## 21 22 0.5682701 0.4369318 0.4686130 Fold1
## 54 22 0.6521735 0.3683946 0.5034888 Fold2
## 87 22 0.6756625 0.3546881 0.5082219 Fold3
## 120 22 0.5198089 0.5205895 0.3861660 Fold4
## 153 22 0.7279476 0.2829001 0.5523393 Fold5
随机森林
再演示一个基于随机森林的递归特征消除。
set.seed(1)
rfeControl = rfeControl(functions = rfFuncs,
method = "cv",
number = 5
)
# 加速
library(future)
plan("multisession",workers=8)
set.seed(1)
rfProfile <- rfe(x, logBBB,
sizes = c(2:25, 30, 35, 40, 45, 50, 55, 60, 65),
rfeControl = rfeControl,
allowParallel = T
)
rfProfile
##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (5 fold)
##
## Resampling performance over subset size:
##
## Variables RMSE Rsquared MAE RMSESD RsquaredSD MAESD Selected
## 2 0.6797 0.2699 0.5247 0.09383 0.1240 0.06923
## 3 0.6339 0.3477 0.4793 0.08518 0.1081 0.06429
## 4 0.6009 0.4098 0.4559 0.10603 0.1500 0.07971
## 5 0.5932 0.4258 0.4500 0.09672 0.1344 0.06971
## 6 0.5936 0.4272 0.4425 0.10719 0.1536 0.07327
## 7 0.5922 0.4280 0.4368 0.09625 0.1346 0.06932
## 8 0.5821 0.4450 0.4234 0.09817 0.1357 0.07087
## 9 0.5755 0.4584 0.4172 0.08825 0.1173 0.06345
## 10 0.5618 0.4863 0.4091 0.08361 0.1098 0.05929
## 11 0.5577 0.4925 0.4067 0.09333 0.1238 0.06680
## 12 0.5527 0.5015 0.4002 0.09667 0.1282 0.06588
## 13 0.5446 0.5166 0.3991 0.08919 0.1142 0.06425
## 14 0.5388 0.5281 0.3975 0.08202 0.1063 0.05540
## 15 0.5390 0.5296 0.3960 0.08311 0.1046 0.05952
## 16 0.5362 0.5336 0.3921 0.08491 0.1096 0.06068
## 17 0.5316 0.5412 0.3910 0.08870 0.1151 0.06519
## 18 0.5349 0.5356 0.3921 0.09198 0.1202 0.06558
## 19 0.5276 0.5475 0.3868 0.09313 0.1234 0.06696
## 20 0.5271 0.5503 0.3836 0.09376 0.1234 0.06771
## 21 0.5293 0.5450 0.3878 0.09410 0.1236 0.06991
## 22 0.5260 0.5528 0.3832 0.09190 0.1200 0.06507
## 23 0.5289 0.5481 0.3871 0.09107 0.1164 0.06989
## 24 0.5283 0.5463 0.3842 0.09108 0.1188 0.06904
## 25 0.5254 0.5546 0.3848 0.09639 0.1261 0.07094
## 30 0.5179 0.5689 0.3775 0.09953 0.1277 0.07627 *
## 35 0.5187 0.5711 0.3767 0.08848 0.1146 0.06470
## 40 0.5195 0.5680 0.3781 0.09101 0.1125 0.07158
## 45 0.5186 0.5709 0.3756 0.09137 0.1168 0.06954
## 50 0.5185 0.5727 0.3768 0.09089 0.1140 0.06905
## 55 0.5218 0.5694 0.3786 0.08865 0.1155 0.06736
## 60 0.5189 0.5733 0.3763 0.08574 0.1062 0.06867
## 65 0.5218 0.5687 0.3788 0.08603 0.1081 0.06711
## 71 0.5219 0.5708 0.3809 0.08333 0.1049 0.06280
##
## The top 5 variables (out of 30):
## tcsa, fpsa3, tcpa, clogp, most_positive_charge
随机森林选出了30个变量,还不如线性回归的效果好。
支持向量机
再演示一下径向基核函数SVM。
径向基核函数svm不是预先定义好的算法,所以在进行特征选择时需要在指定rfeControl中指定functions = caretFuncs,然后在rfe中写method = "svmRadial",其他算法也是类似。
set.seed(1)
rfeControl = rfeControl(functions = caretFuncs,
method = "cv",
number = 5
)
# 加速
library(future)
plan("multisession",workers=8)
set.seed(1)
svmProfile <- rfe(x, logBBB,
sizes = c(2:25, 30, 35, 40, 45, 50, 55, 60, 65),
method = "svmRadial",
rfeControl = rfeControl,
allowParallel = T
)
多个模型比较
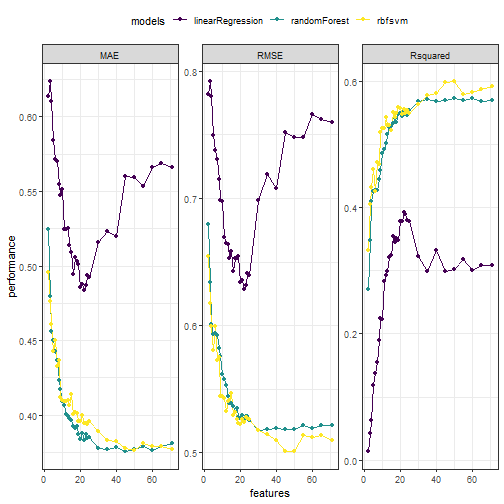
以上我们建立了3个模型,可以通过可视化的方法更加直观的比较模型表现:
xyplot(lmProfile$results$RMSE + rfProfile$results$RMSE + svmProfile$results$RMSE ~ lmProfile$results$Variables,
xlab = "features", ylab = "RMSE",
type = c("g","p","l"),
auto.key = T
)
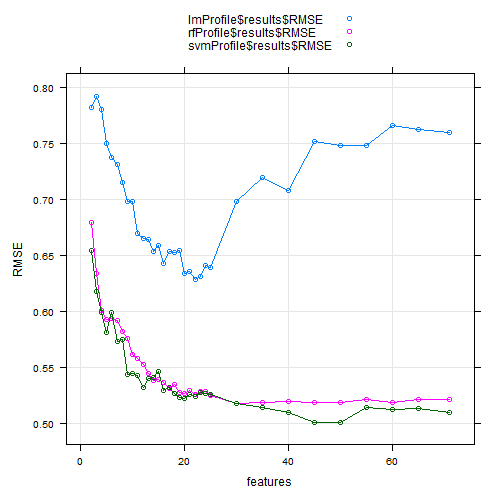
可以选择不同的模型指标画图,这个图用ggplot2画也是很easy,还可以通过分面的形式把多个指标画在一张图里。
plot.df <- data.frame(
performance = c(lmProfile$results$RMSE,lmProfile$results$Rsquared,lmProfile$results$MAE,
rfProfile$results$RMSE,rfProfile$results$Rsquared,rfProfile$results$MAE,
svmProfile$results$RMSE,svmProfile$results$Rsquared,svmProfile$results$MAE
),
metrics = rep(rep(c("RMSE","Rsquared","MAE"),each=length(lmProfile$results$Variables)),3),
features = rep(lmProfile$results$Variables,9),
models = rep(c("linearRegression","randomForest","rbfsvm"),
each = 3*length(lmProfile$results$Variables))
)
library(ggplot2)
ggplot2::ggplot(plot.df, aes(features, performance))+
geom_line(aes(group = models, color = models))+
geom_point(aes(color = models))+
scale_color_viridis_d()+
facet_wrap(~ metrics, scales = "free_y")+
theme_bw()+
theme(legend.position = "top")
knn+调参
下面演示一个knn的例子,在进行特征选择时同时可以调参!
knn不是预先定义好的算法,所以在进行特征选择时需要在指定rfeControl中指定functions = caretFuncs,然后在rfe中写method = "knn",其他算法也是类似。
library(caret)
library(mlbench)
data(Sonar)
# knn,交叉验证
set.seed(1)
rctrl1 <- rfeControl(method = "cv", # 交叉验证
number = 5,
returnResamp = "all",
functions = caretFuncs,
saveDetails = TRUE)
# knn 特征选择,调参
set.seed(1)
knnProfile <- rfe(Class ~ ., data = Sonar,
sizes = c(2:25, 30, 35, 40, 45, 50, 55, 60, 65),
method = "knn", # 不要乱写
trControl = trainControl(method = "cv", # 交叉验证
classProbs = TRUE),
tuneGrid = data.frame(k = 1:10), # 超参数网格
rfeControl = rctrl1)
knnProfile
##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (5 fold)
##
## Resampling performance over subset size:
##
## Variables Accuracy Kappa AccuracySD KappaSD Selected
## 2 0.7545 0.5019 0.05878 0.12072
## 3 0.7645 0.5218 0.04551 0.09357
## 4 0.7692 0.5327 0.06859 0.14152
## 5 0.7448 0.4809 0.05461 0.11213
## 6 0.7548 0.5014 0.07020 0.14407
## 7 0.7595 0.5102 0.08814 0.17986
## 8 0.7304 0.4521 0.07578 0.15435
## 9 0.7739 0.5407 0.06294 0.12867
## 10 0.7547 0.5015 0.06210 0.12747
## 11 0.7454 0.4823 0.07974 0.16396
## 12 0.7793 0.5505 0.09630 0.19648
## 13 0.7551 0.5008 0.09051 0.18883
## 14 0.7837 0.5584 0.09348 0.19819
## 15 0.7790 0.5482 0.08609 0.18333
## 16 0.7739 0.5406 0.10119 0.21049
## 17 0.7833 0.5583 0.09512 0.19835
## 18 0.8317 0.6593 0.03395 0.07109
## 19 0.8220 0.6392 0.03306 0.06930
## 20 0.8509 0.6989 0.04396 0.08925
## 21 0.8124 0.6216 0.08675 0.17529
## 22 0.8218 0.6416 0.03800 0.07586
## 23 0.8316 0.6609 0.06694 0.13398
## 24 0.8316 0.6615 0.06189 0.12303
## 25 0.8655 0.7275 0.02668 0.05632
## 30 0.8705 0.7381 0.03906 0.08043 *
## 35 0.8510 0.6996 0.05532 0.11247
## 40 0.8700 0.7380 0.05047 0.10232
## 45 0.8412 0.6772 0.05784 0.12154
## 50 0.8174 0.6299 0.01081 0.02288
## 55 0.8125 0.6203 0.06145 0.12447
## 60 0.7836 0.5601 0.03849 0.07488
##
## The top 5 variables (out of 30):
## V11, V12, V10, V9, V49
查看交叉验证的结果:
model$fit$results
k Accuracy Kappa AccuracySD KappaSD
1 1 0.8454329 0.6892630 0.06862738 0.1364061
2 2 0.8418182 0.6795104 0.07044070 0.1431458
3 3 0.8318398 0.6609428 0.07523813 0.1510544
4 4 0.8513636 0.7000060 0.06529929 0.1318002
5 5 0.8227706 0.6409301 0.06975862 0.1423341
6 6 0.7944156 0.5854349 0.07880035 0.1605779
7 7 0.7741991 0.5428163 0.08134842 0.1658695
8 8 0.7794372 0.5525427 0.07050749 0.1429124
9 9 0.7982684 0.5898521 0.07648364 0.1573860
10 10 0.7989610 0.5914536 0.09913461 0.2043514
以上就是caret中使用递归特征消除的演示,更多细节大家自己探索。递归特征消除的方法非常多,大家不要天天只知道用支持向量机!
另外,在使用时可能会遇到一些问题,毕竟是一个很老的包了…比如,x和y长度不相等问题…网上答案一搜一大堆,大家遇到了百度下即可。

















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









