







Classification and Representation
Classification
分类问题的预测返回值为离散量。
以0,1两种返回值为例。线性回归算法不适用于解决分类问题,因为
画成图像后,数据点的y值只有0,1两种,因此边界上的一个单独的
点会对回归直线造成很大影响。
Hypothesis Representation
相对于线性回归模型会出现预测值>1和<0的情况,逻辑回归(logistic
regression)模型保证预测值都在(0,1)之间。
其预测值hθ(x) = g(theta’ * x)
g(t) = 1/(1+e^(-t))
hθ(x)表示x的分类值为1的可能性。
因此该问题的关键是找到最合适的θ。
Decision Boundary
logistic regression保证预测值在(0,1)范围内,这样就可以找到方
法映射到离散值上,比如规定hθ(x)<=0.5时认为属于0分类,>0.5属
于1分类。
因为hθ(x) = g(θTx)
根据g的图像可以发现:
hθ(θTx) >= 0.5 –> θTx>=0
hθ(θTx) <0.5 –> θTx<0
因此,这种分类方法实际上是用直线(或面)θTx =0 将图像分割为
两部分,认为一部分属于分类0,一部分属于分类1。
这条直线就被称为linear decision boundary。
当然对于一些数据集decision boundary不是线性的,因为构造的
θTx =0 不是一条直线(向量X中不只有1次项)。
Cost Function
在Linear Regression中,Cost Function图像关于θ只有一个极值
点,具有凸包性(convex)。
但是在Logistic Regression 中,因为hθ(x) = g(θTx),不再是一个一
次直线,Cost Function也就不再具有凸包性,因此在使用Gradient
Descent 时不能保证找到全局最小点。
因此要改变Cost Function的形式为:

首先保证了单调性,因为hθ(x)是单调的,log也是单调的。
其次保证了正确性:
(y = 1 && hθ(x) = 1) –> cost = 0
(y = 0 && hθ(x) = 1) –> cost = +无穷
Simplified Cost Function and Gradient Descent
将Cost Function两种情况合并为:
-y * log(hθ(x)) - (1-y) * log( 1- hθ(x) )
logistic regression 和 linear regression 的Gradient Descent 的迭
代过程基本是一样的,都是:

区别在于hθ(x)不一样
Advanced optimization
几种相对梯度下降更好的方法:
Conjugate Gradient(共轭梯度法)
BFGS(拟牛顿法改进)
L-BFGS(BFGS改进)
它们的优点是不用人为设定迭代步长a,并且速度更快。
但是大多数这些算法都需要使用两个东西,一是J(θ)公式,二是J(θ)
关于各个theta的偏导数的公式。Octave函数fminunc即可接受上述
参数自动返回最优值。
Multiclass Classification: One-vs-all
对于存在多种分类的分类问题,可以将其转化为二元分类问题解决。
方法是对每种分类分开讨论,将该分类视为0,非该分类视为1,这样
就是二元分类问题了。每种情况都有不同的θ向量。
hθi(x)表示x属于第i分类的可能性。
Regularization
The Problem of Overfitting
拟合效果不好有两种情况:
欠拟合(Underfitting),指的是预测值和training set匹配程度较差。
过拟合(Overfitting),指的是拟合曲线过度追求吻合training set,可能被一些噪音干扰,偏离实际情况。当
数据的参数过多时容易发生这种情况。
解决过拟合有两种方法:
1.减少参数数量,可以人为选择使用哪些参数,也可使用模型选择算法(后面会讲)。但是这可能会导致丢
失信息。
2.正则化(regularization),调整每个参数的权重。
Cost Function
θ参数越小,曲线将会越平滑,越不容易Overfitting。
因此构造新的Cost Function
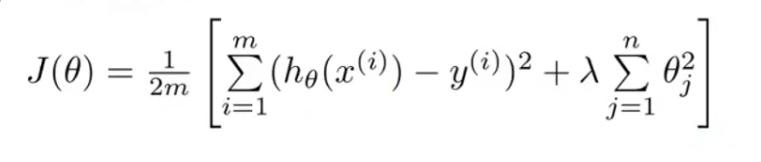
这个函数的前半部分(原Cost Function),控制拟合曲线尽量接近training set,后半部分控制θ参数尽可能
小。正则参数λ控制正则化的程度,λ越大拟合曲线的匹配程度越小。
Regularized Linear Regression
正则化的梯度下降公式为:
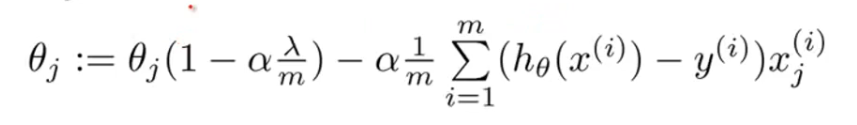
(0















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









