







Classification
机器学习的另一经典问题——分类,与回归的“预测数值”不同,分类需要“预测标签”。

generative model(生成模型)
可以预测任意x在模型中出现的概率,所以我们可以自己生成这个x

Q:为什么是生成模型?
A:假设数据遵循一个均值为μ、协方差矩阵为Σ 的高斯分布。利用从高斯分布中生成数据的概率,即似然(likelihood),来估计P ( x ∣ C 1 ) (从类别C 1 中任取一个样本,它是x的概率)
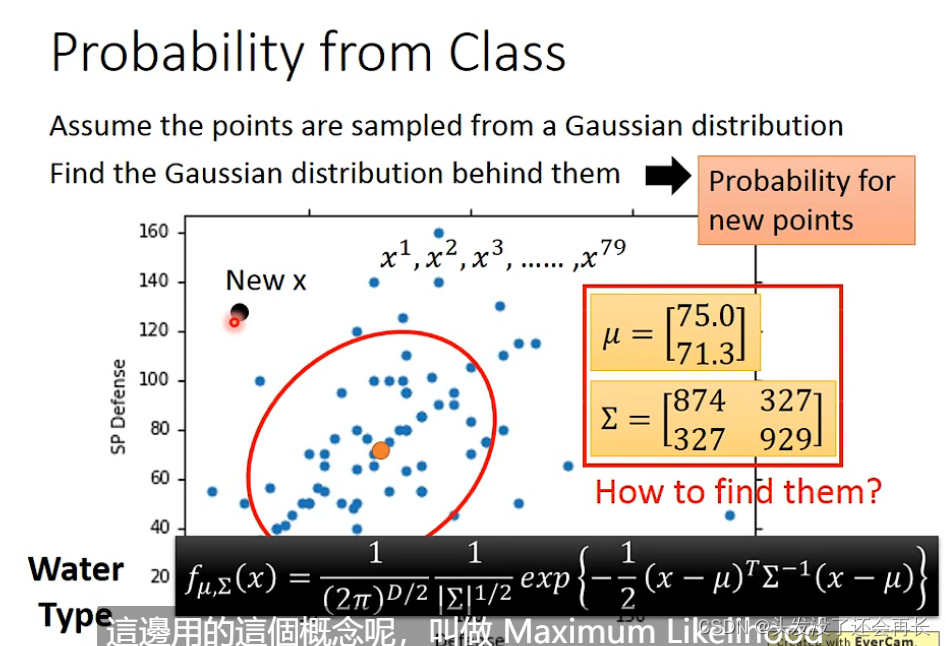
Probability from class —— Feature
想到生成模型P(x),那就要计算出上面四个值
可以通过C1和C2的总数计算出P(C1)和P(C2)
然后考虑如何计算P(x|C1)和P(X|C2)
还是用宝可梦举例,假设已经有了79只宝可梦,我们计算从这些宝可梦里挑出来一只是杰尼龟的概率,杰尼龟目前是不在training data里面的。

假设这些点来自高斯分布
Q:为什么要假设数据的分布是高斯分布?
A:(李宏毅:我知道,就算假设是别的分布,你也一定会问这个问题!)你可以假设任意你喜欢的分布,比如二元分类,可以假设伯努利分布。高斯分布比较简单,参数也比较少(每个类别的高斯分布都共享协方差矩阵Σ )。
Gaussian Distribution
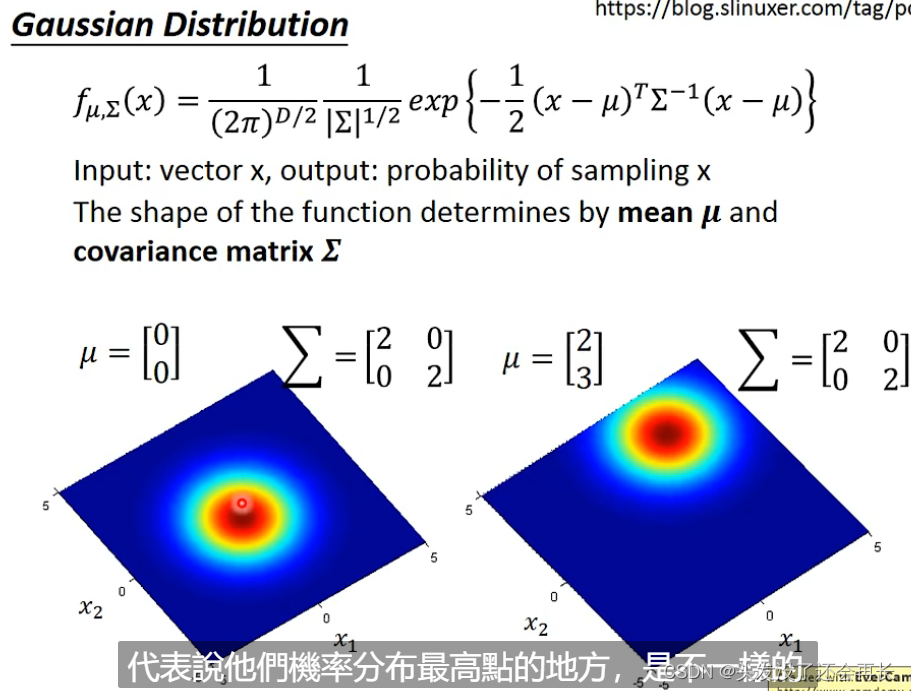
那我们就可以假设这79个点都是用高斯分布sample得到的点,那就要求出来这个高斯函数才能预测某一个x出现的概率,但是这79个点其实可以用任意一个高斯函数sample得到,只是概率不同,那确定给出一个μ和∑就可以算出这个高斯函数的极大似然估计,也就是这个高斯函数sample出这79个点的概率
Probability from class
Likelihood
这个Likelihood用L(μ,∑)来表示,因为L是表示这个Gaussian sample出这79个点的概率,所以计算的公式就是sample出第一个点的概率乘上sample出第二个点的概率…乘上sample出第79个点的概率
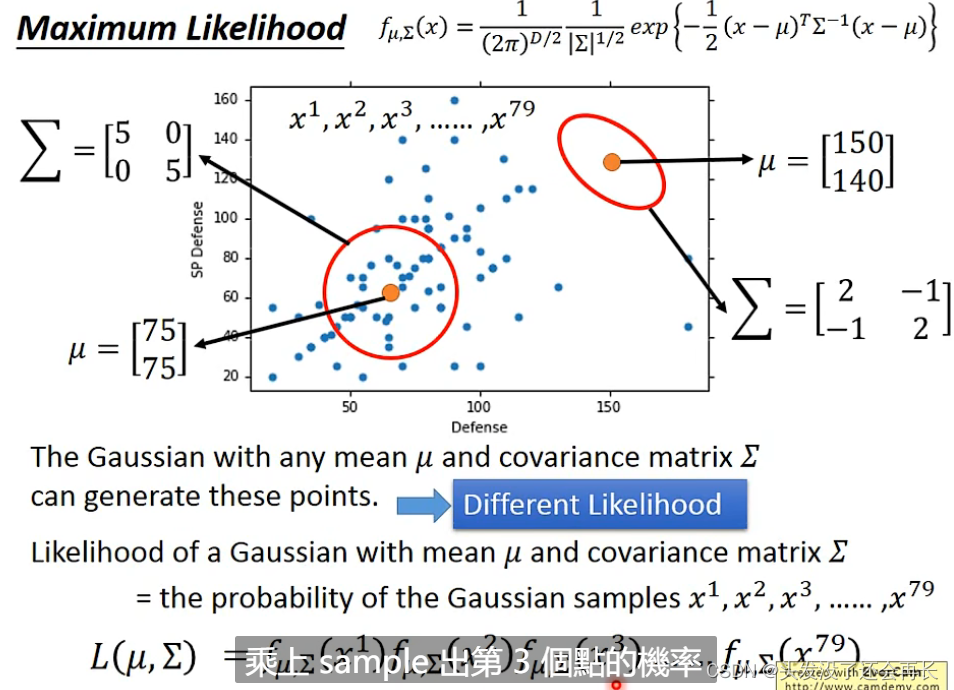
有了likelihood,那要找到一个Gaussian,它sample出这79个点的概率是最大的,也就是这个Gaussian的likelihood最大

然后我们求出了likelihood最大的Class1 和 Class2的∑,μ,那就可以做分类问题了,因为有这些之后,就可以来估计P ( x ∣ C1 ) (从类别C1 中任取一个样本,它是x的概率),和P ( x ∣ C2 )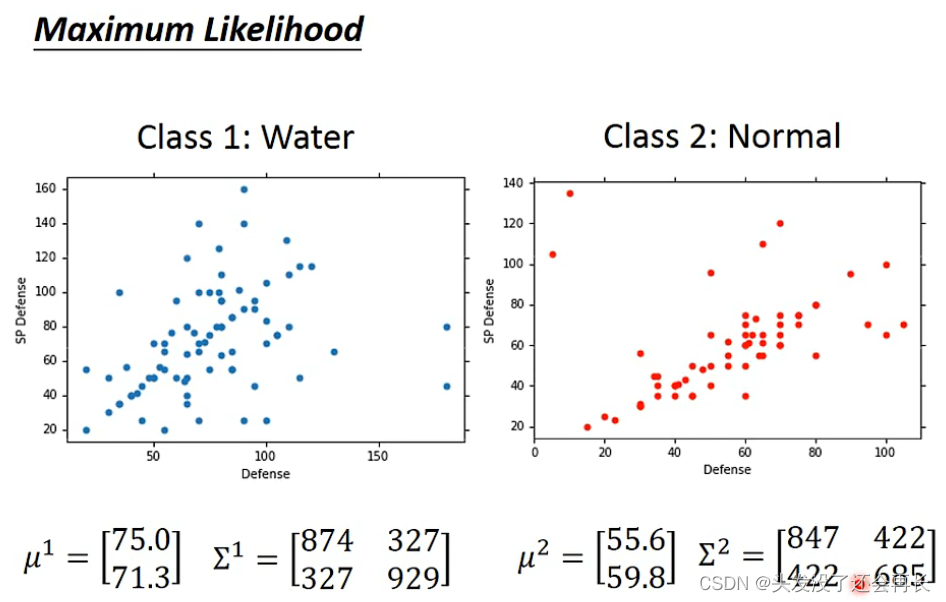
做分类问题,也就是求出来P(C1|x),给一个x,它是来自Class1的概率,前面已经求出来了需要的P,代入公式:
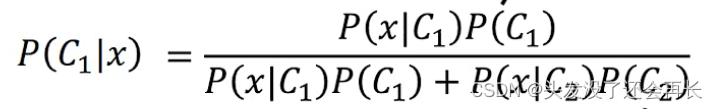

How the results?可以发现结果并不好
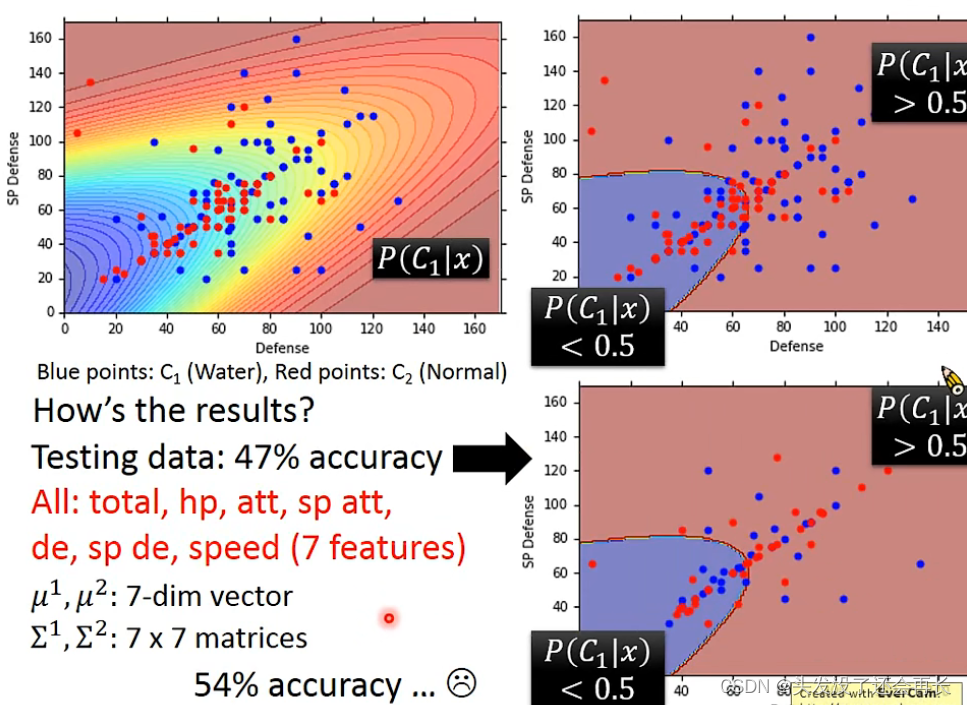
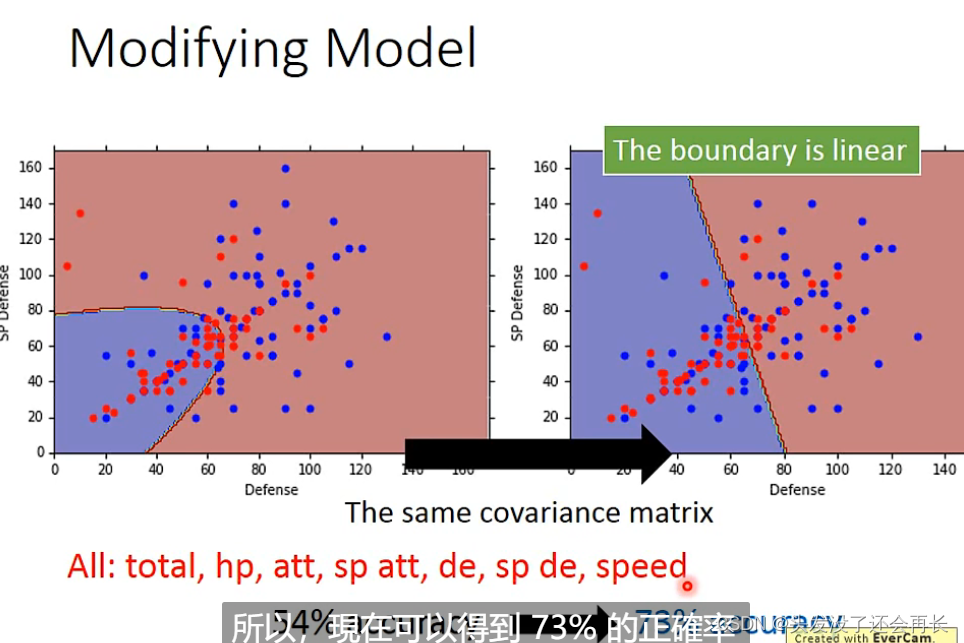
在上面的方法,我们是给水系和一般系的神奇宝贝各一个∑,这样其实并不好,我们可以让他们共用一个∑
Q:为什么不同类别要共享协方差矩阵Σ ?
A:如果每个类别i都有一个协方差矩阵Σ i 那么一方面,variance过大,容易过拟合,另一方面,共享协方差矩阵可以减少参数个数。
Modifying Model

summary
三步模型(来自:iteapoy)

















 6801
6801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









