






The cluster description problem complexity results formulations and approximations Paper(聚类描述问题的复杂性、结果、公式和近似)论文阅读
论文链接:https://proceedings.neurips.cc/paper/2018/file/3fd60983292458bf7dee75f12d5e9e05-Paper.pdf
可解释性文本聚类
Abstract
聚类作为无监督问题,一个显而易见的问题就是,聚出来的簇如何描述(解释),聚类描述问题可以看作,样本的每个(或其中一部分重要的)维度会对应一些标签,这样就有一个样本集,一个标签集,问:如何为每个簇分配一个描述簇的解释,也就是说,从簇内样本和标签之前的联系中找到簇内部的共性(独特)。同时保证使用最少的标签就可以描述整个簇(紧凑)
寻找一个独特而紧凑的解释, 这是一个组合优化的问题,是NP问题,目前显然是没有多项式时间解法,因此需要对问题做松弛和近似。
Contributions
(1)将聚类描述问题表述为一个组合优化问题,以找到每个聚类的简洁但不同的描述。
(2)证明了即使对于两个聚类,想要找到任何聚类描述的可行性问题也是难以解决的。
(3)基本ILP公式模型是包含多个空间(每个聚类一个)的集合覆盖的复杂形式,扩展公式忽略了一些实例(异常值)和标签上的组合约束。
(4)构造了聚类描述问题可在多项式时间内解决(P)中的一个充分条件,并构造了α−β-CONS-DESC算法(每个描述的长度最多必须为α,并且没有两个描述可以重叠超过β)
Problem
Disjoint Tag Descriptor Feasibility(DTDF)不相交标签描述符可行性问题。如上文所说,如何找到一组对样本的标签,使得标签可以描述簇中的样本且最小化样本-簇的连接。
这是一个NPC问题,可以归约为SAT问题。可以进一步简化为多项式时间算法
针对DTDM问题的ILP(整数线性规划)公式:
优化目标:用最少的聚类-标签对得到覆盖所有样本的解决方法

此整数线性规划的变量数量为 聚类数量k * 标签数量t
约束条件:
每个(共有n个)样本至少有一个标签可以描述
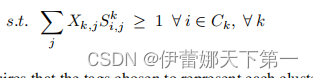
每个标签(共有 t 个)之间不重叠(wj=1),或有重叠有限大小(wj>1,一个松弛条件)对每个聚类的描述应是不同的,至少不完全相同
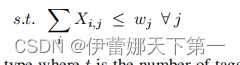
此ILP问题变量数量 O(t*k) 约束总数(n+t)
上式的局限性:
1,ILP问题无法轻松找到一个可行解,在实验求解时往往不收敛到一个可行的解。使wj变大(增大允许标签间重复的范围)可以解决这个问题,但是随后对聚类的描述变得更加相似,降低了它们的有用性。其次,当求解器确实返回了一个解决方案时,为每个聚类返回的描述符有时是不完整或不一致的。
解决方法:
1.Minimizing Overlap 允许一个标签描述多个聚类,而不是最小化总描述长度,但尝试最小化这些重叠。
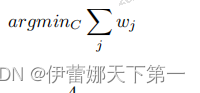
2.Cover-or-Forget 可以忽略聚类中的某些样本,引入变量集Z,若zi=1则说明i样本被忽略
上面的这个公式↓

忽略一部分之后变为这个↓
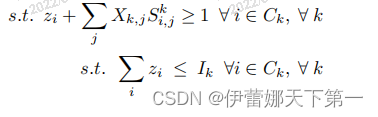
3.Composition Constraints 组合约束,人工引入了两组对“Together”和“Apart”,用于两个标签描述同一个簇,或两个标签不能用于描述同一个簇。(与约束聚类中使用的“必须链接”和“不能链接”约束相似但复杂度不同)是人为的指导。

A Relaxed Setting and Polynomial Time Algorithm
DTDF问题的计算困难的原因之一是要求聚类描述符是成对不相交的。
提出了α,β)-CONS-DESC问题 ((α,β)约束描述) 要求较为宽松,添加了αβ两个参数。
(i)对于每个簇Cj,Cj的描述符必须与簇中每个样本的标签集具有非空交集
(ii)每个描述符最多有α个标签
(iii)任意两个描述符相同的标签不大于β个
若αβ和簇的数量k是固定的,则此问题可以在多项式时间内解决。
k若不固定,即使αβ很小,也是NPC问题
算法:对每个聚类,找到第一个合适的的描述符Di,D_all=(D1,D2,…Dk).用Di和其他所有D相比较,如果D_all中的每对描述符和Di之间最多有β个相同标签,则输出Di作为对簇i的描述


此算法时间复杂度为O(k2 * N(α*k)) k个聚类循环 每个Di与其他所有D_all作比较,k2 在Di D_all比较时,需要比较共k个簇的描述符和每个描述符中的最多α个标签
是多项式时间的算法(因为α,k都是确定值)。
若k不固定,则为NPC问题
Dataset
使用收集于16年1月1日至16年8月22日的推特数据,涵盖了2016年美国总统选举的政治初选季节。选择了1000名政治上最活跃的推特用户,并根据他们的转发行为构建了一个图X。Xij是节点i被节点j转发的次数。收集了136个最常用的政治标签,以获得Y。
Experiment


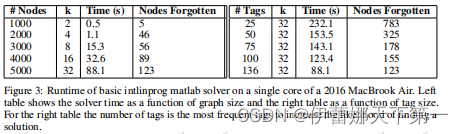















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









