







 文章详细介绍了音频预处理的流程,包括Loader、Padder、LogSpectrogramExtractor、MinMaxNormaliser和Saver模块,以及PreprocessingPipeline类的整合。通过这些步骤,将音频文件转化为频谱图并进行正则化。接着,文章提到了使用预处理后的数据集训练PyTorch模型,特别是Audio2Mel数据集的实现,以及VAE模型的训练过程。
文章详细介绍了音频预处理的流程,包括Loader、Padder、LogSpectrogramExtractor、MinMaxNormaliser和Saver模块,以及PreprocessingPipeline类的整合。通过这些步骤,将音频文件转化为频谱图并进行正则化。接着,文章提到了使用预处理后的数据集训练PyTorch模型,特别是Audio2Mel数据集的实现,以及VAE模型的训练过程。
文章目录
概述
- 这部分是将原来基于mnist手写数据集生成模型,一个用到基于FSDD音频数据集的声音生成模型的关键。二者差别,就在于多了预处理这一步。
- 通过预处理,将音频文件转为频谱图,所以,后半部分生成图片的就可以重复利用了,这部分是关键。
- 具体流程如下图,就是多了前后的预处理这部分。
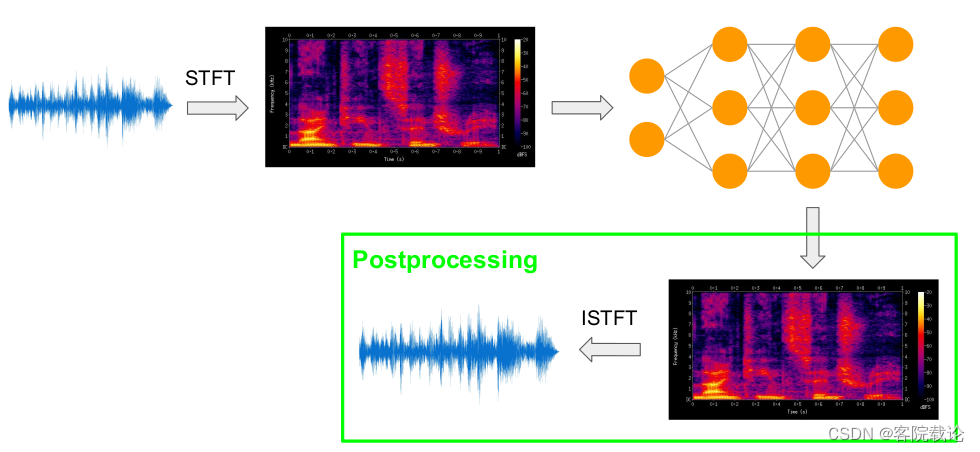
- 除此之外,还需要修改一下train.py文件,使之能够调用生成的频谱图,进行训练。这里也会给出这个文件的实现
Preprocessline模块实现以及代码讲解
- 这部分需要一些基础知识,需要自己学一下,这里也会做相关介绍:
省流,直接看流程图
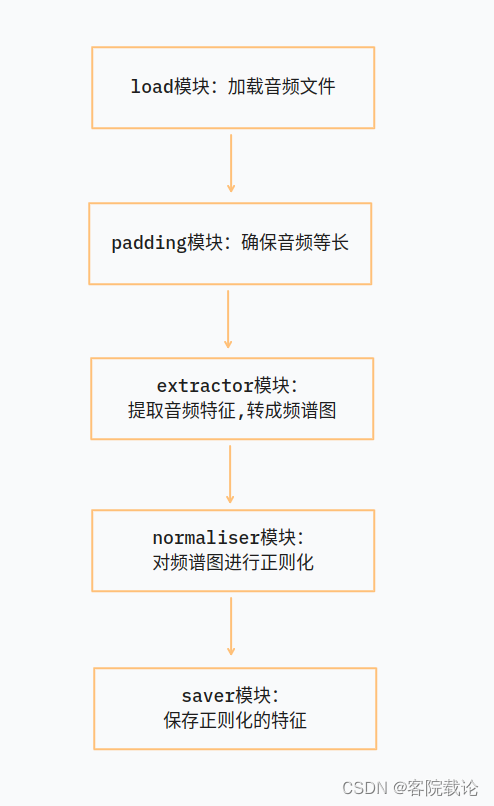
预处理流程
- 在代码中,作者将预处理分成了几个模块,并且每一个模块都负责一个功能,然后再用一个preprocess类,按照需求将各个模块进行组装。
- 具体功能如下
- Loader模块:负责读取音频文件,并返回对应的信号序列
- Padder模块:对信号的进行补充,确保每一个信号的长度都是统一长度相同
- LogSpectrogramExtractor模块:从数据序列中,提取出对应的频谱数据,并返回
- MinMaxNormaliser模块:正则化模块,对频谱数据,按照要求,将之隐射到对应的范围之内
- Saver模块:保存模块,将数据进行保存,主要保存两种特征,分别如下
- 数据的最值,这个是用来进行数据恢复的,因为数据还需要从正则化之后的数据恢复到原来的数据
- 提取出来的特征:将提取出来的频谱数据和声音的振幅,以及声音的时间序列进行保存
下面几个部分也是按照流程图的顺序,逐个实现的
Loader模块
class Loader:
""" 关于这个函数还是有一些不懂的地方,需要学习一下,相关的音频知识 """
def __init__(self,
sample_rate,
duration,
mono # 这是单声道还是双声道
):
self.sample_rate = sample_rate
self.duration = duration
self.mono = mono
def load(self,file_path):
""" 加载文件,这里加载的是什么东西 """
signal = librosa.load(file_path,
sr = self.sample_rate,
duration = self.duration,
mono = self.mono)[0]
return signal
- 参数说明
- sample_rate:采样频率
- duration:加载的音频时长,默认是完全加载的
- mono:是否将音频转换为单声道
- 返回值
- numpy数组:音频的时间序列,支持多通道
- 采样率

Padder模块
class Padder:
""" padder这个类别是用来对数组进行填补,保证数据的大小一致 """
def __init__(self,mode ="constant"):
self.mode = mode
def left_pad(self,array,num_missing_items):
paded_array = np.pad(array,
(num_missing_items,0),
mode = self.mode)
return paded_array
def right_pad(self, array, num_missing_items):
paded_array = np.pad(array,
( 0,num_missing_items),
mode=self.mode)
return paded_array
- 很常见的就是对数组进行扩充,是的数组能够保证大小一致
- 这里就是根据需要添加对应的列,使得所有的array的shape一致
LogSpectrogramExtractor模块
class LogSpectrogramExtractor:
""" LogSpectrogram是提取了时间序列中的频谱信息(以DB为单位) """
def __init__(self,frame_size,hop_length):
self.frame_size = frame_size
self.hop_length = hop_length
def extract(self,signal):
stft = librosa.stft(signal,
n_fft = self.frame_size,
hop_length=self.hop_length)[:-1] # 注意,这里为了能够输入模型训练,原来是(257,64)变成了(256,64),取出了最后一列
spectrogram = np.abs(stft) # 取绝对值,化成频谱图
log_spectrogram = librosa.amplitude_to_db(spectrogram) # 加上分贝图
return log_spectrogram
-
这部分主要是负责提取时域中音频信息的频域信息,主要用了两种方法,具体介绍如下
-
librosa.stft:
- 这部分是用来短时傅立叶变换,返回一个复数矩阵
- 参数说明
- n_fft:进行傅立叶变化的时域窗口
- hop_length:帧移动的跳数,时域窗口的每一次迭代的移动步数
- 返回
- 复数矩阵,这里仅仅不需要最后一个输出,具体执行如下效果图,
-
原来生成复数矩阵是(257,64),这里去除了最后一列
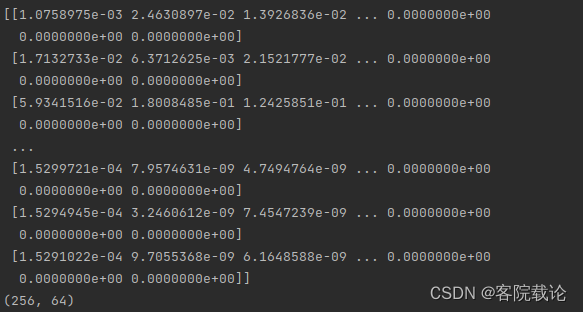
-
短时傅立叶如何将波形图转成频谱图的
-
librosa.amplitude_to_db:
- 将幅度频谱转换为dB标度频谱,就是用分贝表示幅度
- 参数
- 输入幅度
- 返回
- 复数序列,将原来的数据替换为对应的dB,下面是转换之后的db图
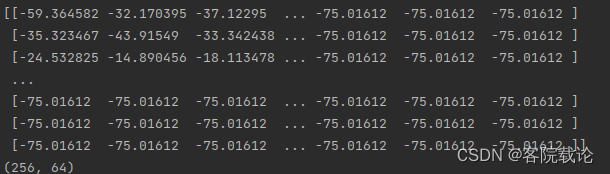
-
在网上找了一下,关于这块,这部分介绍的是比较详细的
- 链接
- 一般来说,这里需要了解一下对应的log-spectrogram数据到底是什么样的,有什么特征
-
振幅和分贝的关系,为啥需要这样转换
MinMaxNormaliser模块
class MinMaxNormaliser:
""" 对数据进行正则化 """
def __init__(self,min_val,max_val):
self.min = min_val
self.max = max_val
def nomalise(self,array):
"""" 将原来的数组映射到min_val,max_val之间,这部分是用来将声音提取出来,提取特征"""
norm_array = (array - array.min) / (array.max - array.min)
norm_array = norm_array * (self.max - self.min) + self.min
return norm_array
def denormalise(self,norm_array,original_min,original_max):
""" 这个是用来还原的,后续生成声音 """
array = (norm_array -self.min) / (self.max - self.min)
array = array * (original_max - original_min) * original_min
return array
- 这部分使用来对数据进行正则化的,我觉得他大部分函数都是自己实现的,可能就是让你学习一下的
- normalise:对数据进行正则化,将原来的数据映射到新的min和max之间
- denormalise:对数据进行还原
Saver模块
class Saver:
""" 保存特征和对应的min和max """
def __init__(self,feature_save_dir,min_max_values_save_dir):
self.feature_save_dir = feature_save_dir # 这是特征保存的路径,和原来的路径并不相同
self.min_max_values_save_dir = min_max_values_save_dir
def save_feature(self,feature,file_path):
""" 经过处理之后的特征 """
save_path = self._generate_save_path(file_path)
np.save(save_path,feature)
def save_min_max_values(self,min_max_values):
""" 保存音频文件对应的最大最小值 """
save_path = os.path.join(self.min_max_values_save_dir,"min_max_values.pkl")
self._save(min_max_values,save_path)
@staticmethod
def _save(data,save_path):
with open(save_path,"wb") as f:
pickle.dump(data,f)
def _generate_save_path(self,file_path):
file_name = os.path.split(file_path)[1]
save_path = os.path.join(self.feature_save_dir,file_name + ".npy")
return save_path
- 这个模块是负责保存提取出来的特征和保存原数据的最值
- min_max_values.pkl
- 将提取出来的数据,获取其最大值和最小值,保存为对应的pkl文件
- 文件名.npy
- 将提取出来的频谱特征保存为对应的npy文件
- min_max_values.pkl
PreprocessPipeLine模块
class PreprocessingPipeline:
""" 将上述的每一个文件经过下述流程处理:
1、加载音频文件
2、对数据进行padding,确保等长
3、从数据中提取出log频谱图
4、将频谱图进行正则化
5、保存频谱图
store the min max values for all the log spectrogram
"""
def __init__(self):
""" 这里并没有写死,考虑到了代码的鲁棒性,可以通用于不同的预处理模块 """
self.padder = None
self.extractor = None
self.normaliser = None
self.saver = None
self._loader = None
self._num_expected_samples = None
self.min_max_value = dict()
# 这部分是用来判定是否需要进行padding的
# 将成员变量定义为padder,判定是否需要进行
@property
def loader(self):
return self._loader
@loader.setter
def loader(self,loader):
self._loader = loader
self._num_expected_samples = int(loader.sample_rate * loader.duration)
def process(self,audio_files_dir):
for root, _, files in os.walk(audio_files_dir):
for file in files:
file_path = os.path.join(root, file)
self._process_file(file_path)
print(f"Processed file {file_path}")
self.saver.save_min_max_values(self.min_max_value)
# 这里还需要保存对应每一个音频文件对应的最大和最小值,便于还原
self.saver.save_min_max_values(self.min_max_value)
def _process_file(self,file_path):
""" 处理单个文件的过程 """
signal = self.loader.load(file_path) # 加载信号
if self._is_padding_necessary(signal): # 判定是否需要进行padding
signal = self._apply_padding(signal)
feature = self.extractor.extract(signal) # 提取特定的特征,这里保留一个通用的函数
norm_feature = self.normaliser.normalise(feature) # 对特征进行正则化
save_path = self.saver.save_feature(norm_feature,file_path)
self._store_min_max_value(save_path,feature.min(),feature.max())
# 4.3 逐步实现上述的方法
def _is_padding_necessary(self,signal):
""" 判定是否需要对这个array进行扩充 """
if len(signal) < self._num_expected_samples:
return True
return False
def _apply_padding(self,signal):
""" 对array进行padding """
padding_signal = self.padder.right_pad(signal,self._num_expected_samples - len(signal))
return padding_signal
def _store_min_max_value(self,save_path,min_value,max_value):
self.min_max_value[save_path] = {
"min" :min_value,
"max":max_value
}
- 数据预处理的完整流程,主要是调用的process方法实现,然后处理单个文件,是调用私有函数_process方法
知识补充
property修饰词
- 参考连接 , property修饰词的说明
- 作用
- 使用property来创建只读属性,将方法转为相同名称的只读属性,防止属性被修改。
train模块实现以及代码讲解
- 这部分是调用上一节生成的频谱图数据集,调整对应的vae模型的参数进行训练,生成对应的模型。
- 由于vae很多结构已经搭建完了,只需要传入各个层的参数就行,并不需要修改代码。
- 这个py文件主要有load_fsdd和train两个功能模块
- load_fsdd加载对应音频数据集,这里是已经处理好的频谱文件
- train设置用于音频训练的模型参数,并进行训练
load_fsdd函数实现
def load_fsdd(spectrograms_path):
x_train = []
for root, _, file_names in os.walk(spectrograms_path):
for file_name in file_names:
file_path = os.path.join(root, file_name)
spectrogram = np.load(file_path) # (n_bins, n_frames, 1)
x_train.append(spectrogram)
x_train = np.array(x_train)
print(x_train.shape)
# 三个点是省略多个切片的操作,相当于是多个维度,但是省略前三个维度的写法
x_train = x_train[..., np.newaxis] # -> (3000, 256, 64, 1)
return x_train
- 这里加载了spectrogram_path指向的频谱图的路径,并且加载对应的npy文件,即提取之后的数据特征,但是这里需要注意,就是提取的数据只有(256,63)两个维度,所以需要增加新的维度,表示channel,也就是下面这句
x_train = x_train[..., np.newaxis] # -> (3000, 256, 64, 1)
train函数实现
def train(x_train, learning_rate, batch_size, epochs):
autoencoder = VAE(
input_shape=(256, 64, 1),
conv_filters=(512, 256, 128, 64, 32),
conv_kernels=(3, 3, 3, 3, 3),
# 注意,这里最后一个strides是一个元组,这里是制定了行和列采用不同的移动步长。
conv_strides=(2, 2, 2, 2, (2, 1)),
latent_space_dim=128
)
autoencoder.summary()
autoencoder.compile(learning_rate)
autoencoder.train(x_train, batch_size, epochs)
return autoencoder
- 这里不同于mnist的数据集,为了让那你观察特征空间,将之设置为2维,这里设置为128维度,能够容纳更多的数据特征。
- 然后就是卷积的层数,也比之前更多了,使用了五层,并且都是小卷积核。
总的实现代码
import os
import numpy as np
from vae import VAE
LEARNING_RATE = 0.0005
BATCH_SIZE = 16
EPOCHS = 2
SPECTROGRAMS_PATH = "/root/PycharmProjects/VAEGenerate/Mycode/fsdd/spectrogram"
def load_fsdd(spectrograms_path):
x_train = []
for root, _, file_names in os.walk(spectrograms_path):
for file_name in file_names:
file_path = os.path.join(root, file_name)
spectrogram = np.load(file_path) # (n_bins, n_frames, 1)
x_train.append(spectrogram)
x_train = np.array(x_train)
print(x_train.shape)
# 三个点是省略多个切片的操作,相当于是多个维度,但是省略前三个维度的写法
x_train = x_train[..., np.newaxis] # -> (3000, 256, 64, 1)
return x_train
def train(x_train, learning_rate, batch_size, epochs):
autoencoder = VAE(
input_shape=(256, 64, 1),
conv_filters=(512, 256, 128, 64, 32),
conv_kernels=(3, 3, 3, 3, 3),
conv_strides=(2, 2, 2, 2, (2, 1)),
latent_space_dim=128
)
autoencoder.summary()
autoencoder.compile(learning_rate)
autoencoder.train(x_train, batch_size, epochs)
return autoencoder
if __name__ == "__main__":
x_train = load_fsdd(SPECTROGRAMS_PATH)
autoencoder = train(x_train, LEARNING_RATE, BATCH_SIZE, EPOCHS)
autoencoder.save("model")
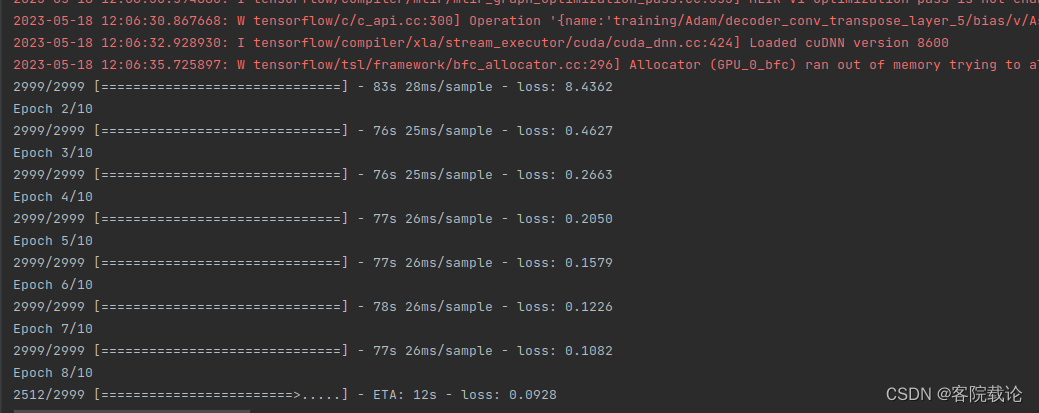
运行效果
pytorch版本:直接读取音频并将之转为张量进行计算
import torch
import librosa
from scipy.io.wavfile import read as loadwav
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# 归一化音频信号的最大值
# 这里相当于一个位深度,将每一个数据点都缩小到对应的范围内
MAX_WAV_VALUE = 32768.0
""" Mel-Spectrogram extraction code from Turab ood_audio"""
# def mel_spectrogram(audio, n_fft, n_mels, hop_length, sample_rate):
# # Compute mel-scaled spectrogram
# mel_fb = librosa.filters.mel(sr=sample_rate, n_fft=n_fft, n_mels=n_mels)
# spec = librosa.stft(audio, n_fft=n_fft, hop_length=hop_length)
# mel = np.dot(mel_fb, np.abs(spec))
#
# # return librosa.power_to_db(mel, ref=0., top_db=None)
# return np.log(mel + 1e-9)
""" Mel-Spectrogram extraction code from HiFi-GAN meldataset.py"""
def dynamic_range_compression(x, C=1, clip_val=1e-5):
'''
描述:用于压缩音频信号的动态范围——非深度学习版本
作用:将音频信号的动态范围压缩到一个较小的范围内,提高音频信号的稳定性
:param x:
:param C:
:param clip_val:
:return:
'''
# clip对信号进行裁剪,clip_val为裁剪的最小值
# 然后在乘以常数,转为对数,对信号进行压缩
return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
def dynamic_range_decompression(x, C=1):
'''
描述:用于解压缩音频信号的动态范围
作用:上述过程的逆过程,用于对音频数据进行恢复
:param x:
:param C:
:return:
'''
return np.exp(x) / C
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
'''
描述:用于压缩音频信号的动态范围 --深度学习版本
作用:将音频信号的动态范围压缩到一个较小的范围内,提高音频信号的稳定性
:param x:
:param C:
:param clip_val:
:return:
'''
return torch.log(torch.clamp(x, min=clip_val) * C)
def dynamic_range_decompression_torch(x, C=1):
'''
描述:用于解压缩音频信号的动态范围
作用:上述过程的逆过程,用于对音频数据进行恢复
:param x:
:param C:
:return:
'''
return torch.exp(x) / C
def spectral_normalize_torch(magnitudes):
'''
用于归一化音频信号的幅度
:param magnitudes:
:return:
'''
output = dynamic_range_compression_torch(magnitudes)
return output
def spectral_de_normalize_torch(magnitudes):
'''
用于解归一化音频信号的幅度
:param magnitudes:
:return:
'''
output = dynamic_range_decompression_torch(magnitudes)
return output
mel_basis = {}
hann_window = {}
def mel_to_spectrogram(
audio, n_fft, n_mels, sample_rate, hop_length, fmin, fmax, center=False
):
'''
描述:用于提取音频信号的mel频谱图)
原理:
:param audio:音频信号
:param n_fft:FFT(快速傅里叶变换)的窗口大小。
:param n_mels: 生成的 Mel 频谱图的 Mel 滤波器数量,每一个滤波器对应于一个 Mel 频率。
:param sample_rate:音频的采样率。
:param hop_length:FFT 窗口的跳跃长度。
:param fmin: Mel 滤波器的最小频率。
:param fmax: Mel 滤波器的最大频率。
:param center:是否在进行 FFT 时居中窗口。
:return:
'''
# 将声音信号转为张量,并增加一个维度,第一个维度表示batch_size
audio = torch.FloatTensor(audio)
audio = audio.unsqueeze(0)
# 检查音频信号的最大值和最小值是否在-1到1之间
if torch.min(audio) < -1.0:
print('min value is ', torch.min(audio))
if torch.max(audio) > 1.0:
print('max value is ', torch.max(audio))
# Mel 基础和 Hann 窗口:生成或检索 Mel 滤波器矩阵和 Hann 窗口
global mel_basis, hann_window
if fmax not in mel_basis:
mel_fb = librosa.filters.mel(
sr=sample_rate, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax
)
mel_basis[str(fmax) + '_' + str(audio.device)] = (
torch.from_numpy(mel_fb).float().to(audio.device)
)
hann_window[str(audio.device)] = torch.hann_window(n_fft).to(audio.device)
print(audio.shape)
# 音频信号的预处理:对音频信号进行填充,FFT要求输入的信号必须要是2的整数倍
# 有增加一个维度表示多通道音频数据
audio = torch.nn.functional.pad(
audio.unsqueeze(1),
(int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)),
mode='reflect',
)
# 去除多余的维度
audio = audio.squeeze(1)
# 使用短时傅里叶变换(STFT)将音频信号转换为频谱图
spec = torch.stft(
audio,
n_fft,
hop_length=hop_length,
window=hann_window[str(audio.device)],
center=center,
pad_mode='reflect',
normalized=False,
onesided=True,
return_complex=False,
)
# 计算频谱图的幅度
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-9)
# 将频谱图转换为 Mel 频谱图
mel = torch.matmul(mel_basis[str(fmax) + '_' + str(audio.device)], spec)
# 动态压缩 Mel 频谱图的幅度
mel = spectral_normalize_torch(mel).numpy()
return mel
""" Mel-Spectrogram extraction code from HiFi-GAN meldataset.py"""
# 声明为Dataset类,继承torch.utils.data.Dataset
# 重写__init__(), __getitem__(), __len__()方法
# 方便和torch.utils.data.DataLoader配合使用,实现批量读取数据,数据预处理,数据增强等功能
class Audio2Mel(torch.utils.data.Dataset):
def __init__(
self,
audio_files,
max_length,
n_fft,
n_mels,
hop_length,
sample_rate,
fmin,
fmax,
):
self.audio_files = audio_files
self.max_length = max_length # max length of audio
self.n_fft = n_fft
self.n_mels = n_mels
self.hop_length = hop_length
self.sample_rate = sample_rate
self.fmin = fmin
self.fmax = fmax
def __getitem__(self, index):
# 实现根据索引获取数据,获得数据的文件名、类别、标签等信息
filename = self.audio_files[index]['file_path']
class_id = self.audio_files[index][
'class_id'
] # datasets.get_class_id(filename)
salience = 1 # datasets.get_salience(filename)
sample_rate, audio = loadwav(filename)
audio = audio / MAX_WAV_VALUE
if sample_rate != self.sample_rate:
raise ValueError(
"{} sr doesn't match {} sr ".format(sample_rate, self.sample_rate)
)
# 超过了最大长度,就截断
if len(audio) > self.max_length:
# raise ValueError("{} length overflow".format(filename))
audio = audio[0 : self.max_length]
# pad audio to max length, 4s for Urbansound8k dataset
# 不足最大长度,就填充
if len(audio) < self.max_length:
# audio = torch.nn.functional.pad(audio, (0, self.max_length - audio.size(1)), 'constant')
audio = np.pad(audio, (0, self.max_length - len(audio)), 'constant')
# mel = mel_spectrogram(audio, n_fft=self.n_fft, n_mels=self.n_mels, hop_length=self.hop_length, sample_rate=self.sample_rate)
mel_spec = mel_to_spectrogram(
audio,
n_fft=self.n_fft,
n_mels=self.n_mels,
hop_length=self.hop_length,
sample_rate=self.sample_rate,
fmin=self.fmin,
fmax=self.fmax,
)
# print(mel_spec.shape)
return mel_spec, class_id, salience, filename
def __len__(self):
return len(self.audio_files)
def extract_flat_mel_from_Audio2Mel(Audio2Mel):
'''
将 Audio2Mel 中的 mel 频谱图展平, 用于训练 VAE
:param Audio2Mel:
:return:
'''
mel = []
for item in Audio2Mel:
mel.append(item[0].flatten())
return np.array(mel)
if __name__ == '__main__':
sample_rate, audio = loadwav(r'/home/yunlong/PycharmProjects/VAEGenerate/data/samples/original/0.wav')
# 规范化音频数据
MAX_WAV_VALUE = 32768.0
audio = audio / MAX_WAV_VALUE
# 调用 mel_to_spectrogram 函数
mel_spec = mel_to_spectrogram(
audio,
n_fft=1024,
n_mels=80,
hop_length=256,
sample_rate=44100,
fmin=0,
fmax=8000,
)
# 输出 mel 频谱图
print("Mel Spectrogram Shape:", mel_spec.shape)
Audio2Mel(torch.utils.data.Dataset)自己实现的数据集
- 这里是继承实现了Dataset这个类,使得这个类能够和dataloader一块进行操作,方便处理。
对比
- 不同于那个tensorflow的处理,这里是直接将音频读取,然后直接加载训练。不同于上文,是将数据保存为npy文件,然后直接读取npy文件。
- 具体那个更快要做个实验才知道。
总结
-
这段代码的复用性还是很强的,如果你是实现不同的预处理流程,只需要实现特定阶段的类即可,然后将新的对象,组装到新的preprocess pipeline即可,这里需要学习一下。说到这里,还是需要了解一下设计模式,毕竟是前人总结出来,针对不同情况的编程的习惯。现在的编码习惯太差了,一点都不好,无论是python、java还是C++都是可以面向对象编程,我忽然间想起,我在程序精英编程大赛中,居然还使用一个一个函数进行实现功能,羞愧。
-
这部分是对音频进行预处理,将之变为图片,然后音频生成就转成了图片的生成问题。
-
这里预处理的流程,涉及到很多环节,都是音频处理的基础知识,需要好好学习一下。
- log spectrogram和spectrogram的关系
- 短时傅立叶怎么把波形图转成频谱图的
- 。。。。
-
现在会的都是一些皮毛。这篇博客,也仅仅会讲述这个项目中会用到的相关知识,多的并不会讲,但是如果想去专门了解一下这个版块,还是需要专门学习一下相关的基础知识。
-
9-5补充
-
最近又看了一个pytorch编程的,发现这里写的确实很好,但是操作起来太慢了,只能用来单步调试,或者小批量数据。因为他并没有将数据转成张量进行批量操作。

















 5481
5481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









