










DeepSeek R1 14B + LM Studio 本地大模型实测
💡 本文将介绍如何使用 LM Studio 启动大语言模型(LLM),并进行推理测试。LM Studio 是一款轻量级的本地大模型推理工具,适用于 Windows 和 macOS,支持 Llama.cpp 推理引擎,可轻松运行 LLaMA2、Mistral、Qwen、DeepSeek 等模型。
🚀 本教程适合入门用户,重点讲解 LM Studio 的安装、模型下载、配置及测试步骤,并附带截图演示!
1. LM Studio 介绍
什么是 LM Studio?
- 一款 开源 的本地 LLM 推理 GUI 工具
- 支持 GGUF 格式大模型(Llama.cpp 后端)
- 支持 GPU 加速,可用 RTX 4060 / 4070 / 4090 运行大模型
- 可直接在本地进行 离线 AI 对话,不依赖 OpenAI API
支持的模型
- Meta LLaMA2 / LLaMA3
- Mistral / Mixtral
- Qwen / DeepSeek
- Gemma / Phi-2
- Hugging Face 上的任意 GGUF 格式模型
本地大模型部署方式对比
| 部署方式 | Ollama | LM Studio | vLLM |
|---|---|---|---|
| 产品定位 | 本地快速体验 | 图形化交互工具 | 生产级推理引擎 |
| 用户群体 | 开发者/爱好者 | 非技术用户 | 企业/工程师 |
| 部署复杂度 | 低 | 低 | 中高 |
| 性能优化 | 基础 | 一般 | 极致 |
| 适用场景 | 开发测试、原型验证 | 个人使用、教育演示 | 高并发生产环境 |
| 扩展性 | 有限 | 无 | 强(分布式/云原生) |
2. LM Studio 安装
下载 & 安装
👉 官网下载地址:https://lmstudio.ai/
Windows / macOS 用户可直接下载并安装,安装步骤很简单,默认下一步即可。
🚀 安装完成后,启动 LM Studio,进入主界面:点击跳过即可。
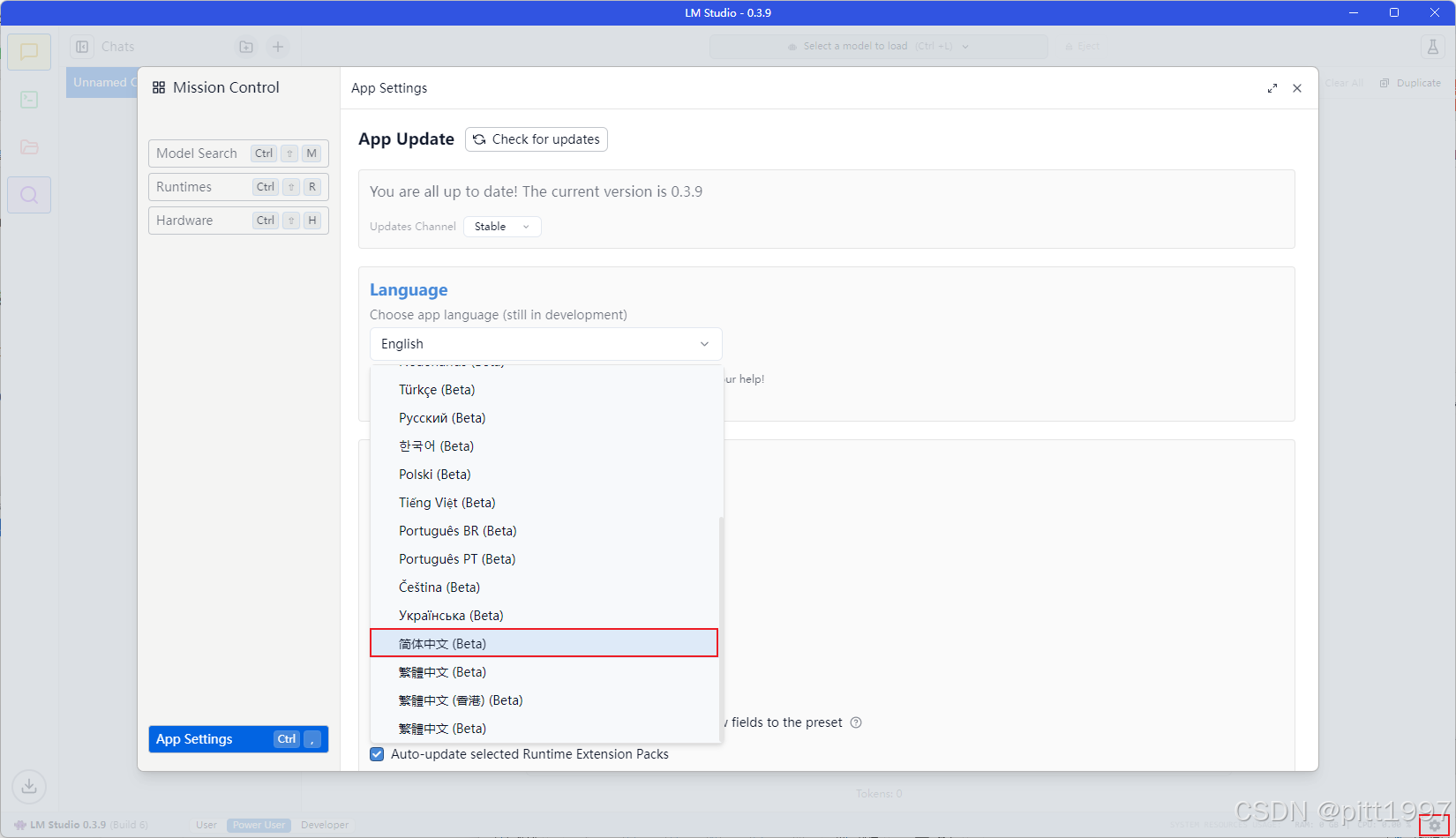
点击右下角设置,选择语言,设置简体中文。
3. 下载 & 加载大模型
方式 1:LM Studio 直接下载
- 打开 LM Studio,进入
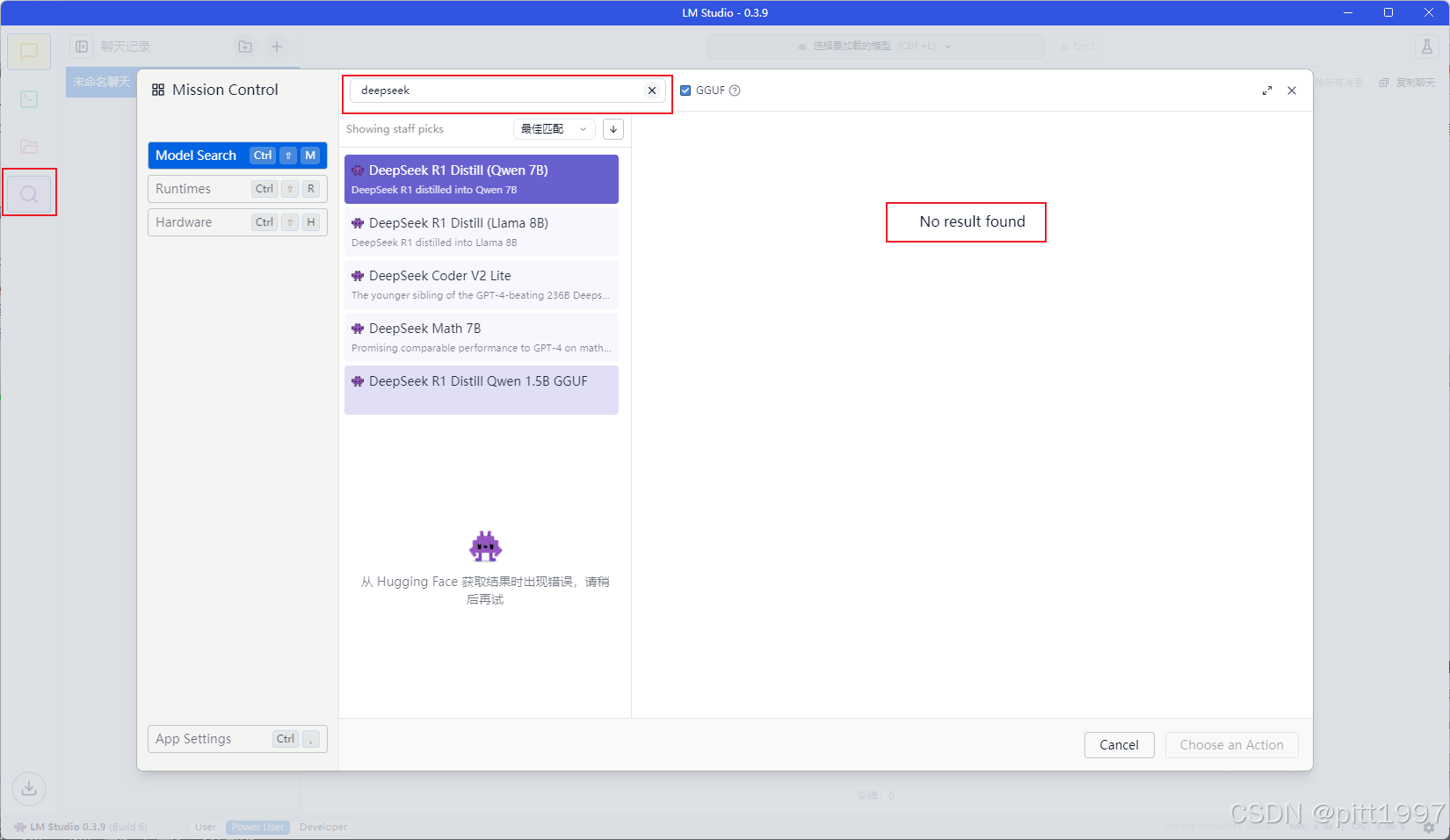
Model(模型)页面 - 在 发现 处搜索 LLaMA2-7B / Qwen-7B / DeepSeek-7B/DeepSeek-R1-Distill-Qwen-14B 等
- 选择 GGUF 格式(如 DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf)
- 点击下载,等待模型下载完成(可能会出现网络问题无法下载)
💡 建议选择 4-bit / 5-bit 量化模型(Q4_K_M、Q5_K_M),更适合消费级显卡(如 4060Ti)
方式 2:手动下载 GGUF 模型
如果 LM Studio 下载速度慢(或者搜索访问不到模型结果),可以去 Hugging Face 或者魔塔社区 手动下载:
-
打开 Hugging Face 模型仓库:huggingface 或者 魔塔社区
-
搜索 DeepSeek-R1-Distill-Qwen-14B-GGUF 或其他模型(可根据个人PC条件进行选择)
个人PC情况:CPU:12600KF / 显卡:七彩虹 RTX4060Ti Ultra W OC 8G / 内存:32G
DeepSeek 7B(Q4_K_M / Q5_K_M) ✅ 可运行(推荐)
Qwen 7B(Q4_K / Q5_K) ✅ 可运行(推荐)
DeepSeek 14B(Q4_K_M) ⚠️ 勉强可跑(性能会受影响,会占满 8GB 显存,可能部分数据溢出到内存,导致性能下降)
DeepSeek 32B(Q4_K_M) ⚠️ 不推荐(性能问题)
两个网站的14B模型的具体链接如下:
https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/tree/main
https://www.modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/files量化版本 模型大小(VRAM占用) 适用设备 Q2_K ~3GB-4GB VRAM 轻量运行,最低精度 Q3_K_M ~4GB-5GB VRAM 平衡性能与精度 Q4_K_M ~5GB-6GB VRAM 高质量、适用于 4060 Ti Q5_K_M ~6GB-7GB VRAM 更高精度,但可能略卡顿 Q6_K ~7GB-8GB VRAM 最高量化精度,但对 8GB 显存设备来说压力大 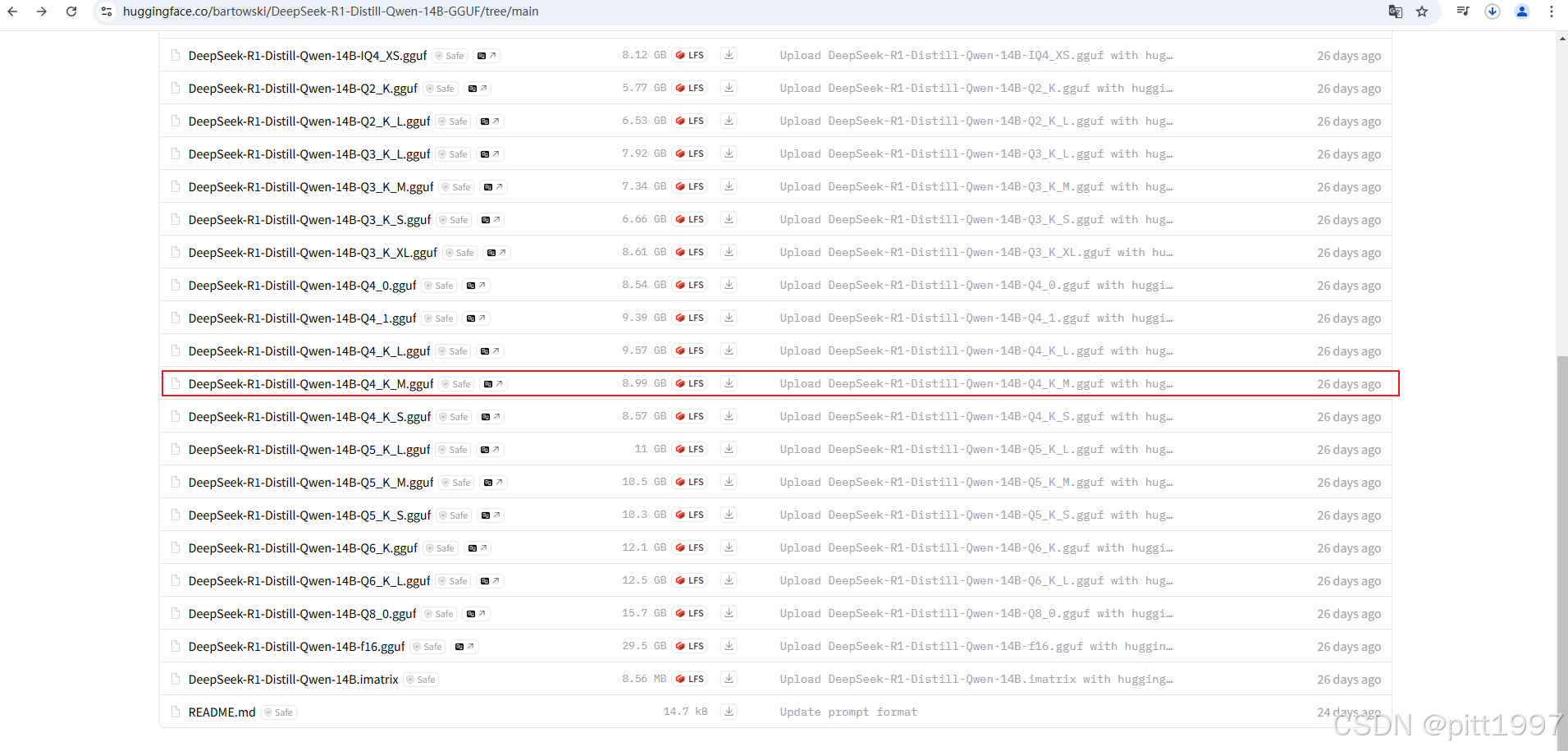
-
下载
.gguf文件,并手动放入LM Studio的模型目录注意默认模型目录在C盘,我们手动改一下 📂 默认模型路径(可手动调整):
Windows:C:\Users\你的用户名\.lmstudio\models
macOS:~/Library/Application Support/LM Studio/models/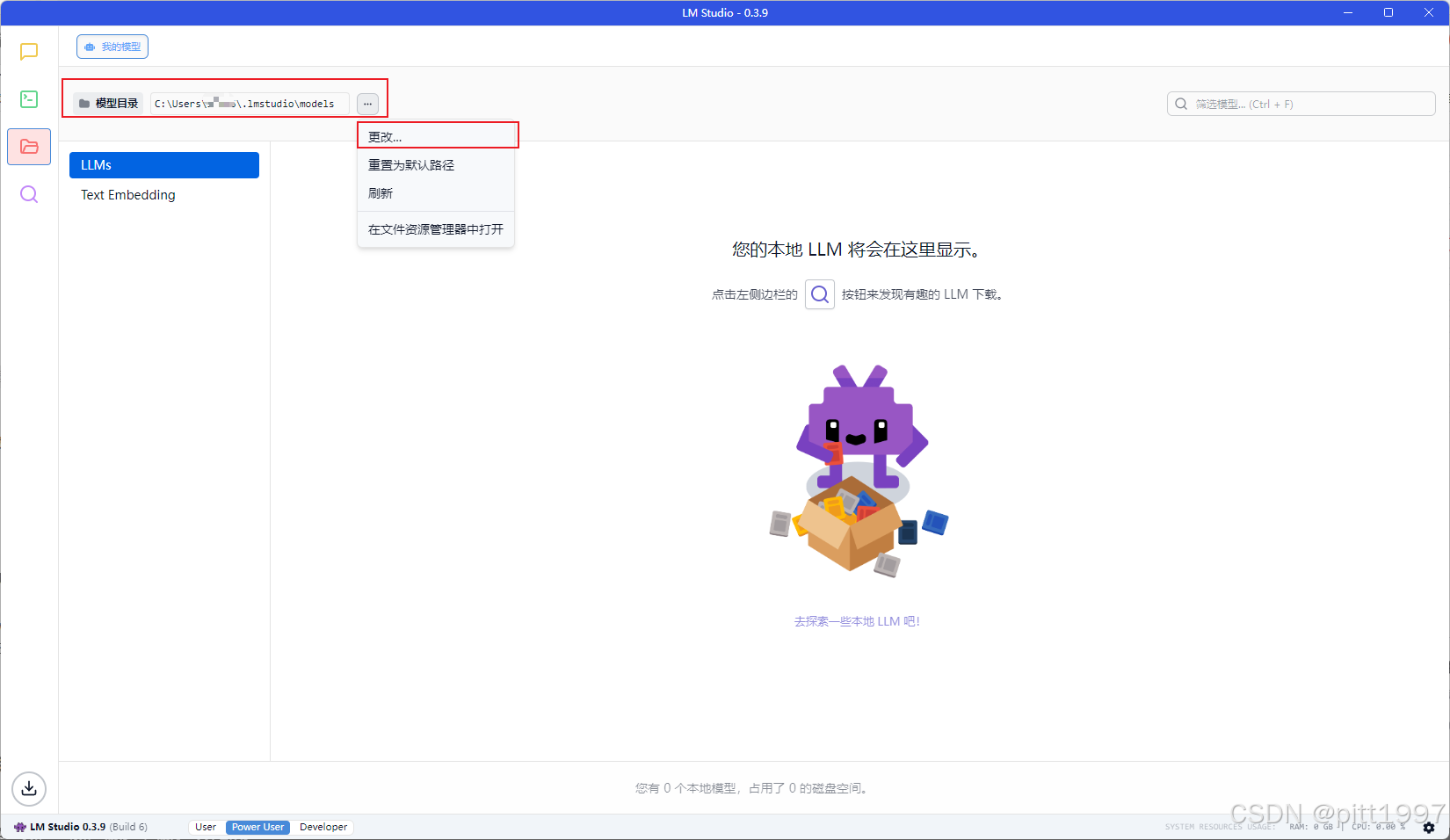
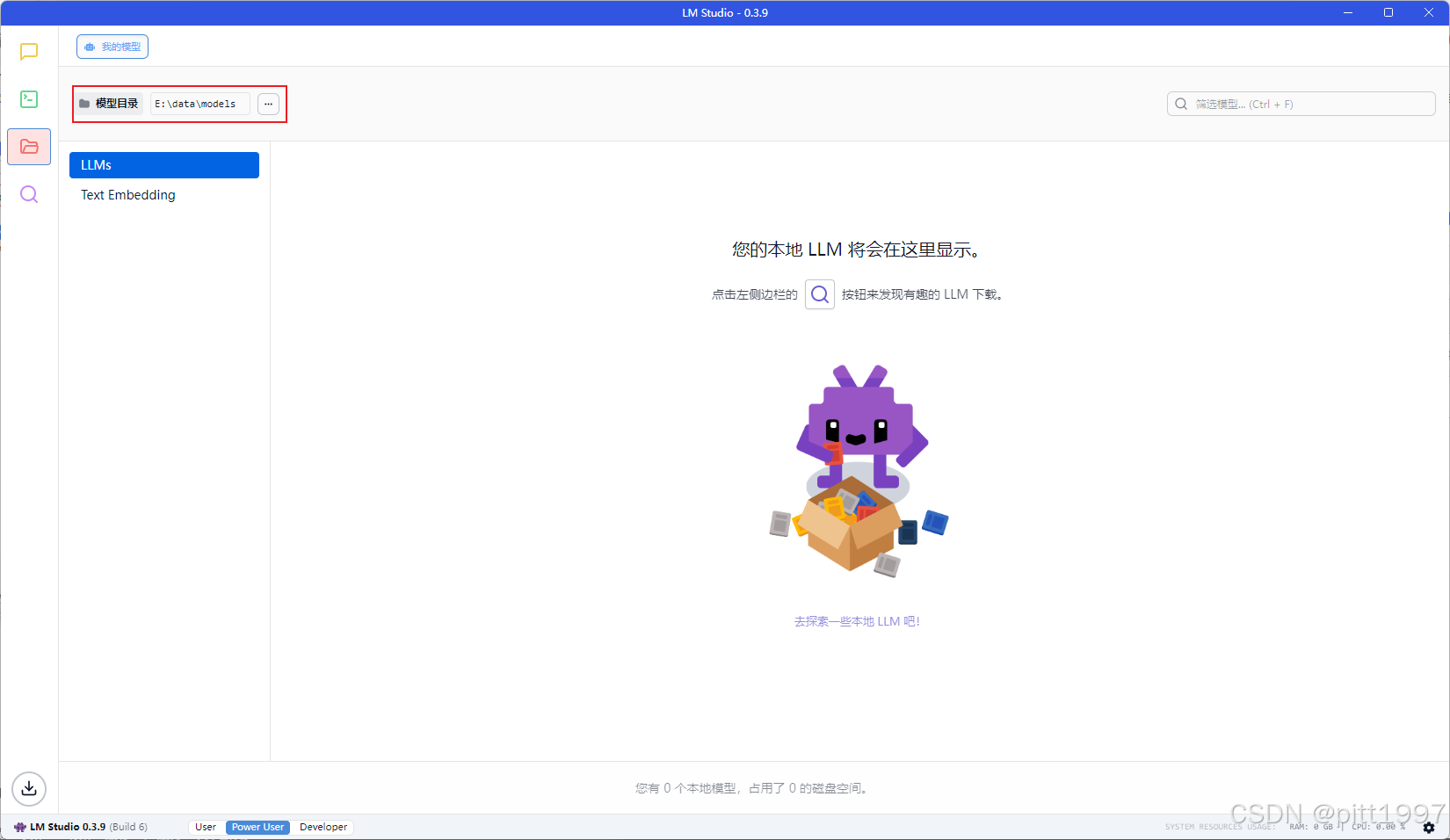
保存后注意还需要在模型目录下手动创建一个 Publisher/Repository 目录,并将我们的模型放在此处。
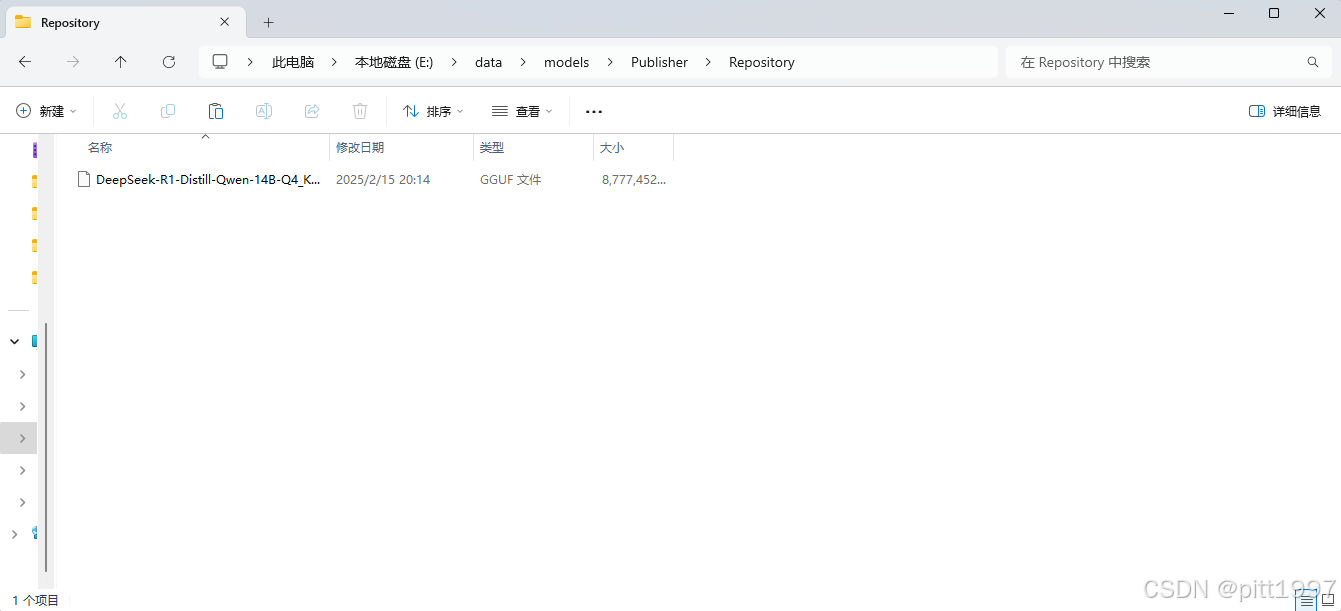
再回到 LMStudio 中可以看到我们下载的模型。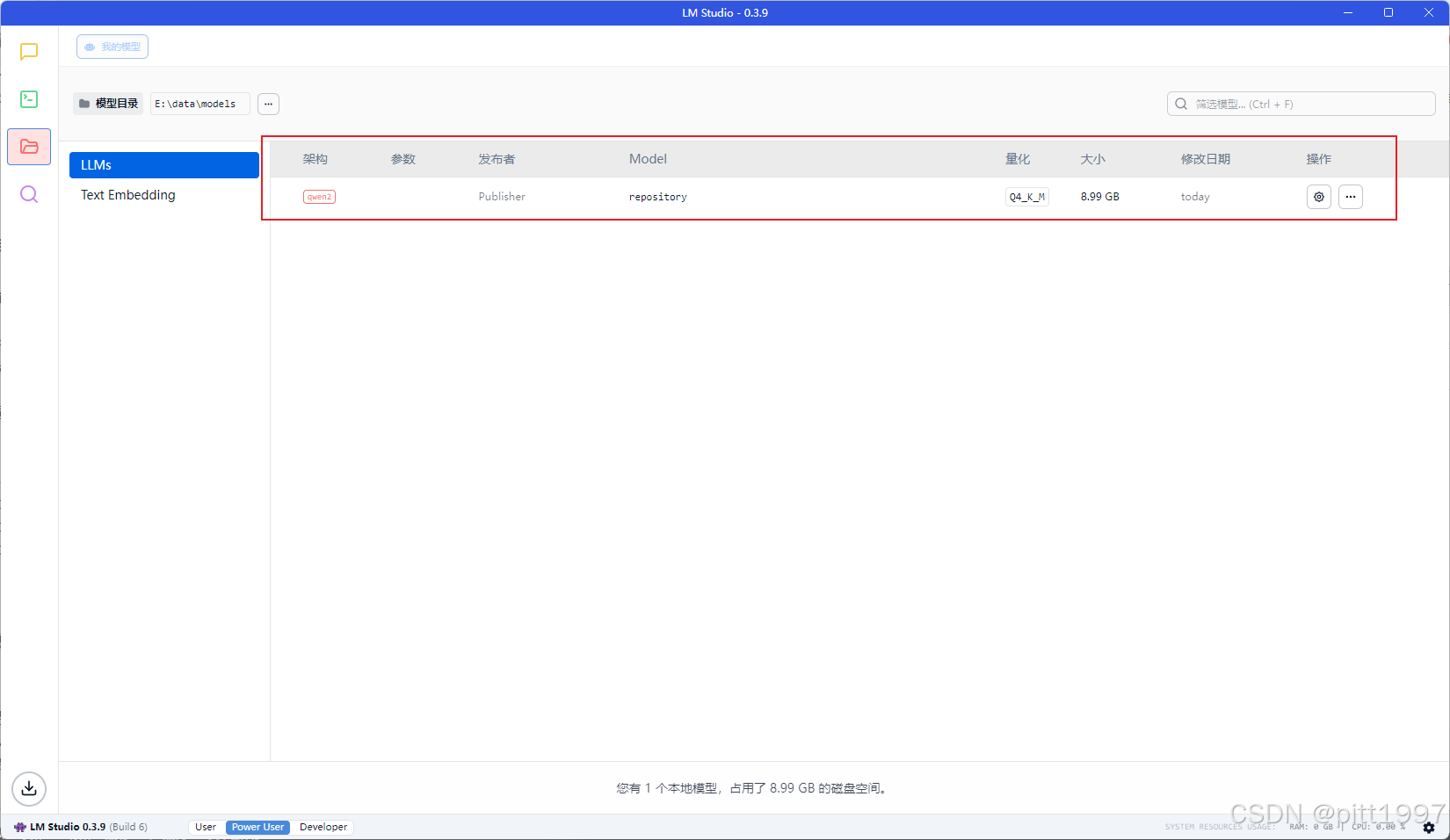
4. 启动模型 & 运行测试
运行 DeepSeek-R1-Distill-Qwen-14B-GGUF
-
进入
Chat(聊天)界面 -
选择下载好的模型(如 DeepSeek-R1-Distill-Qwen-14B-GGUF)
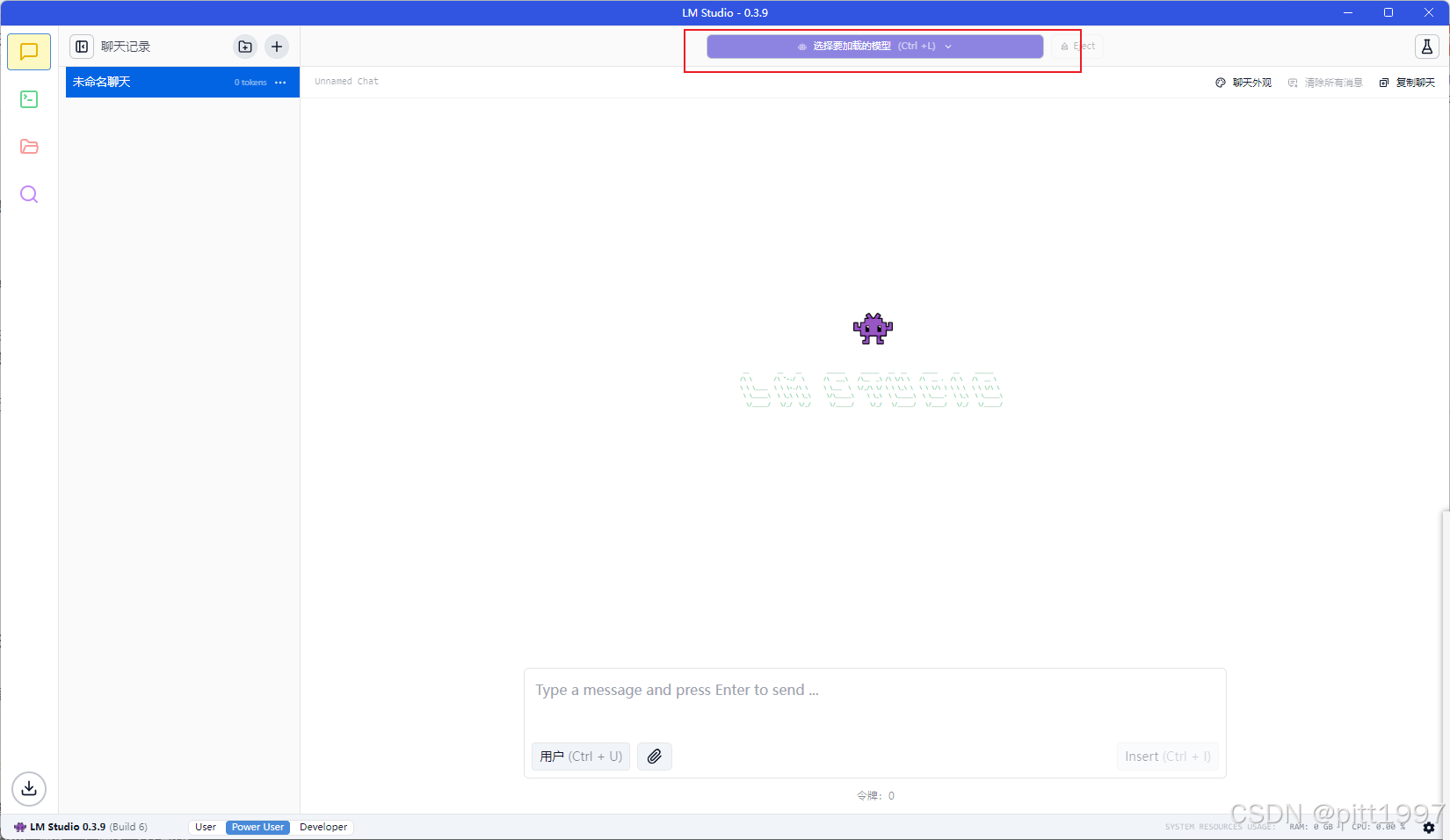
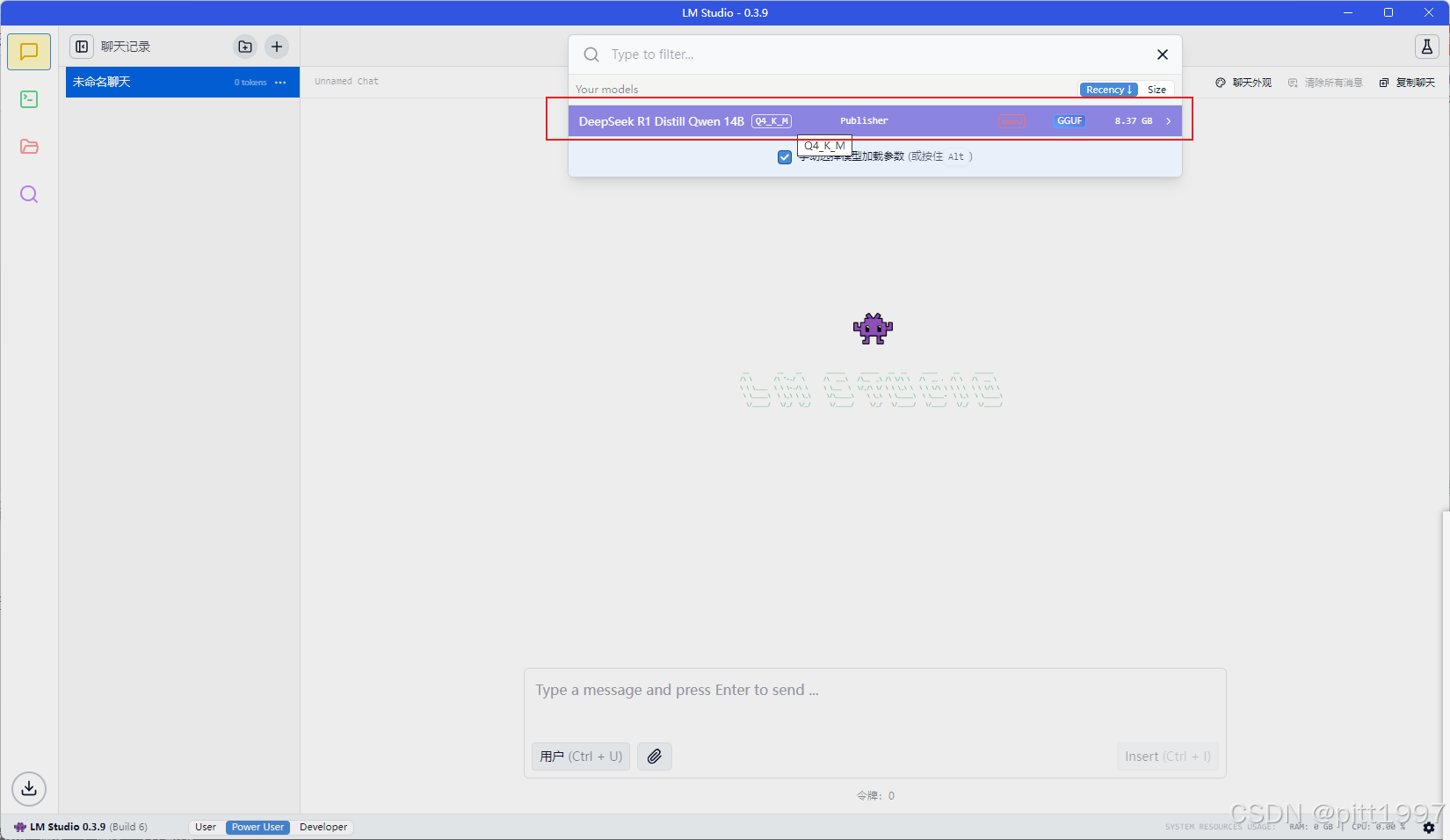
-
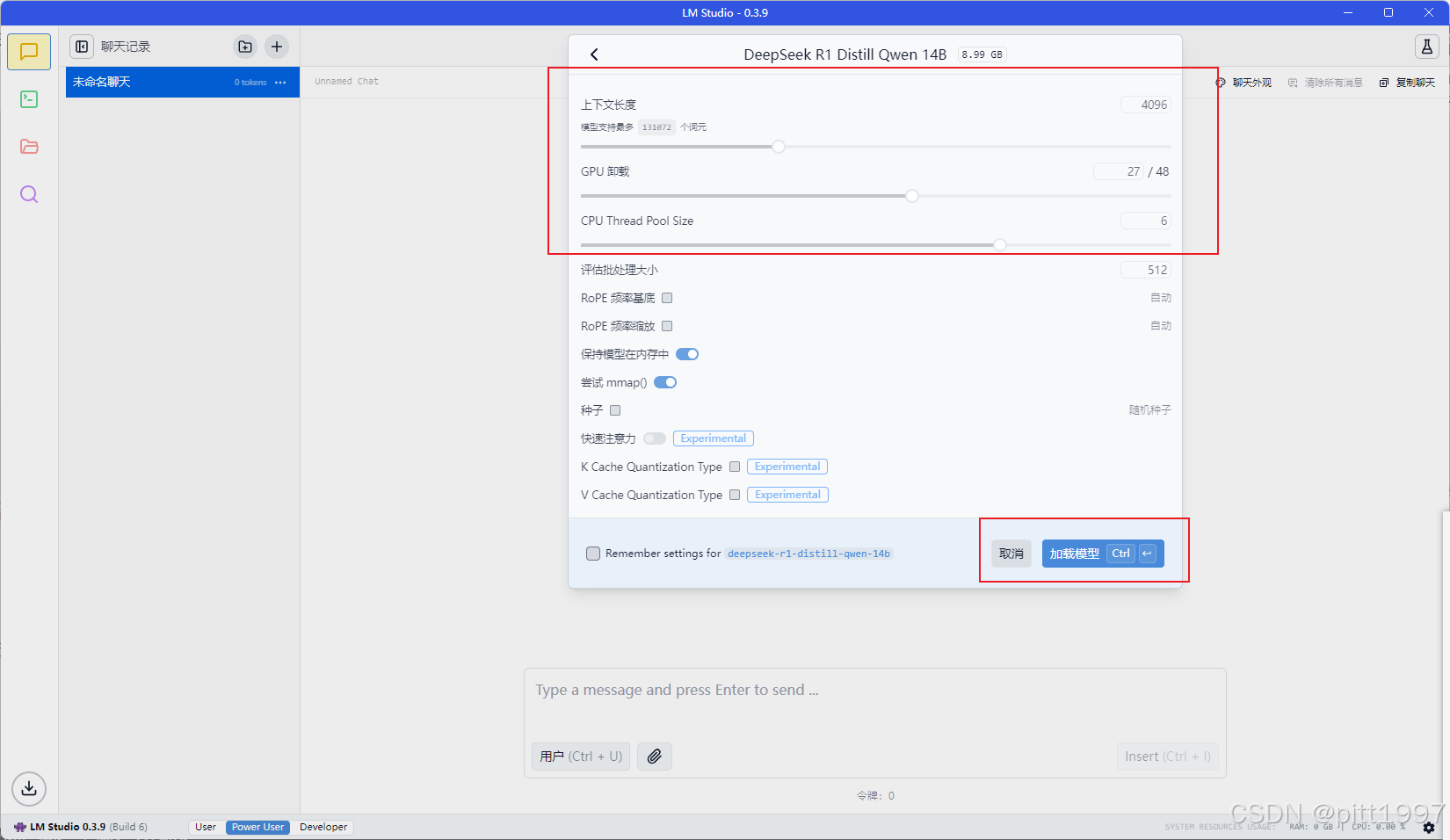
调整参数,点击加载模型(这里GPU卸载应该是是翻译问题,意思是GPU负载)
-
输入问题,进行 AI 对话测试
提示词:Java实现一个单例模式
Java实现一个单例模式(思考推理稍微有点慢,但是结果比较准确)
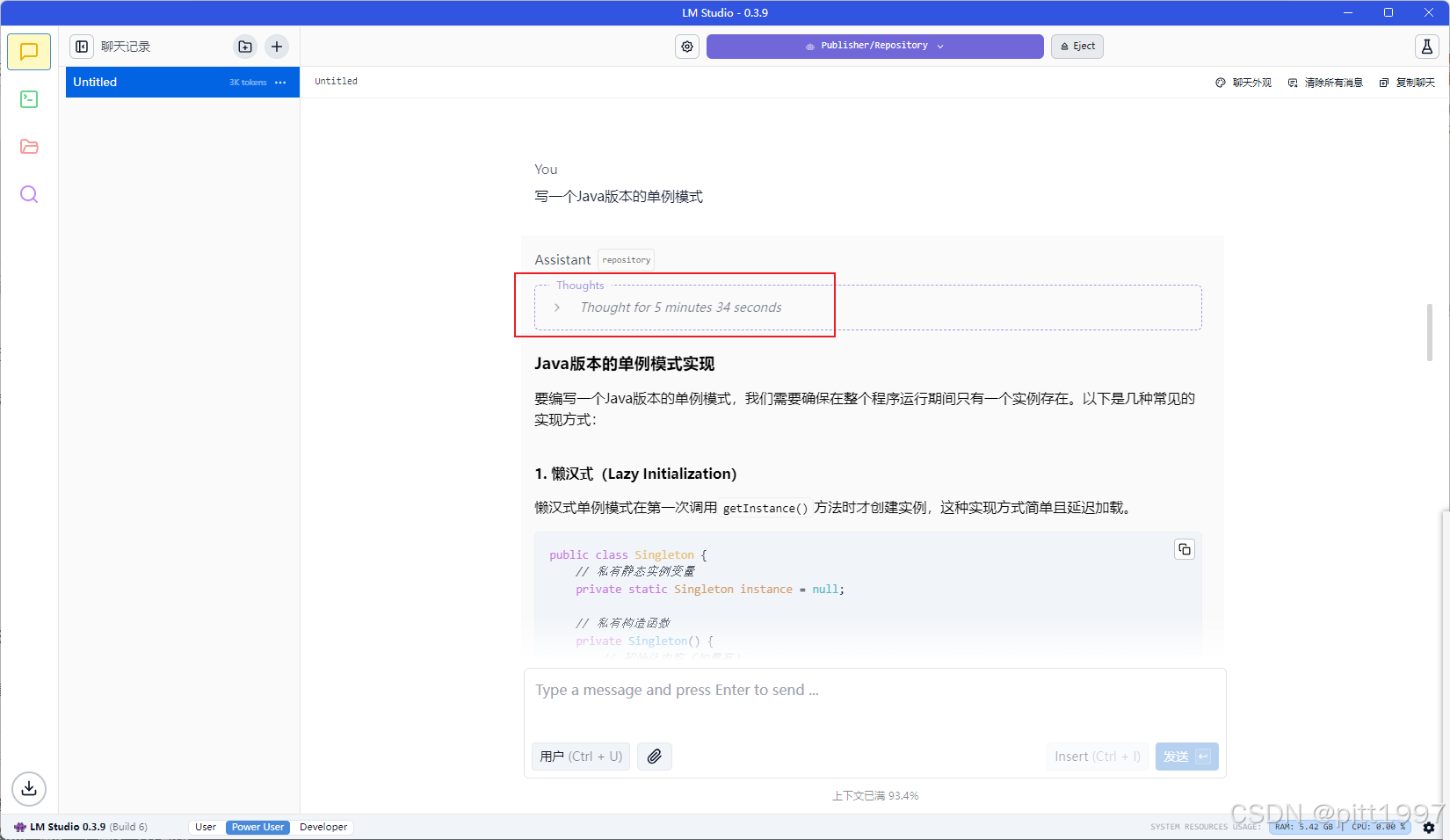
推理过程
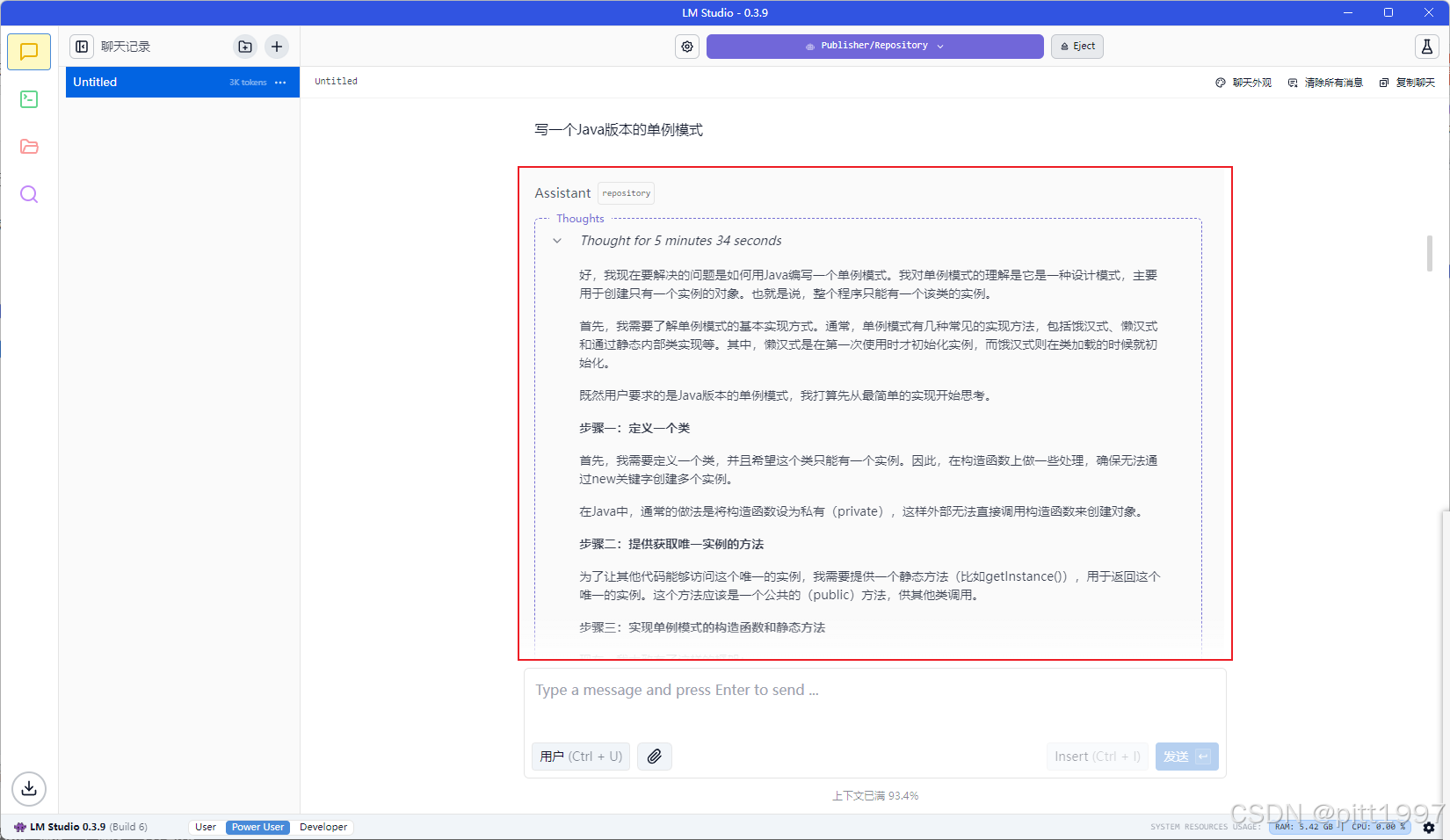
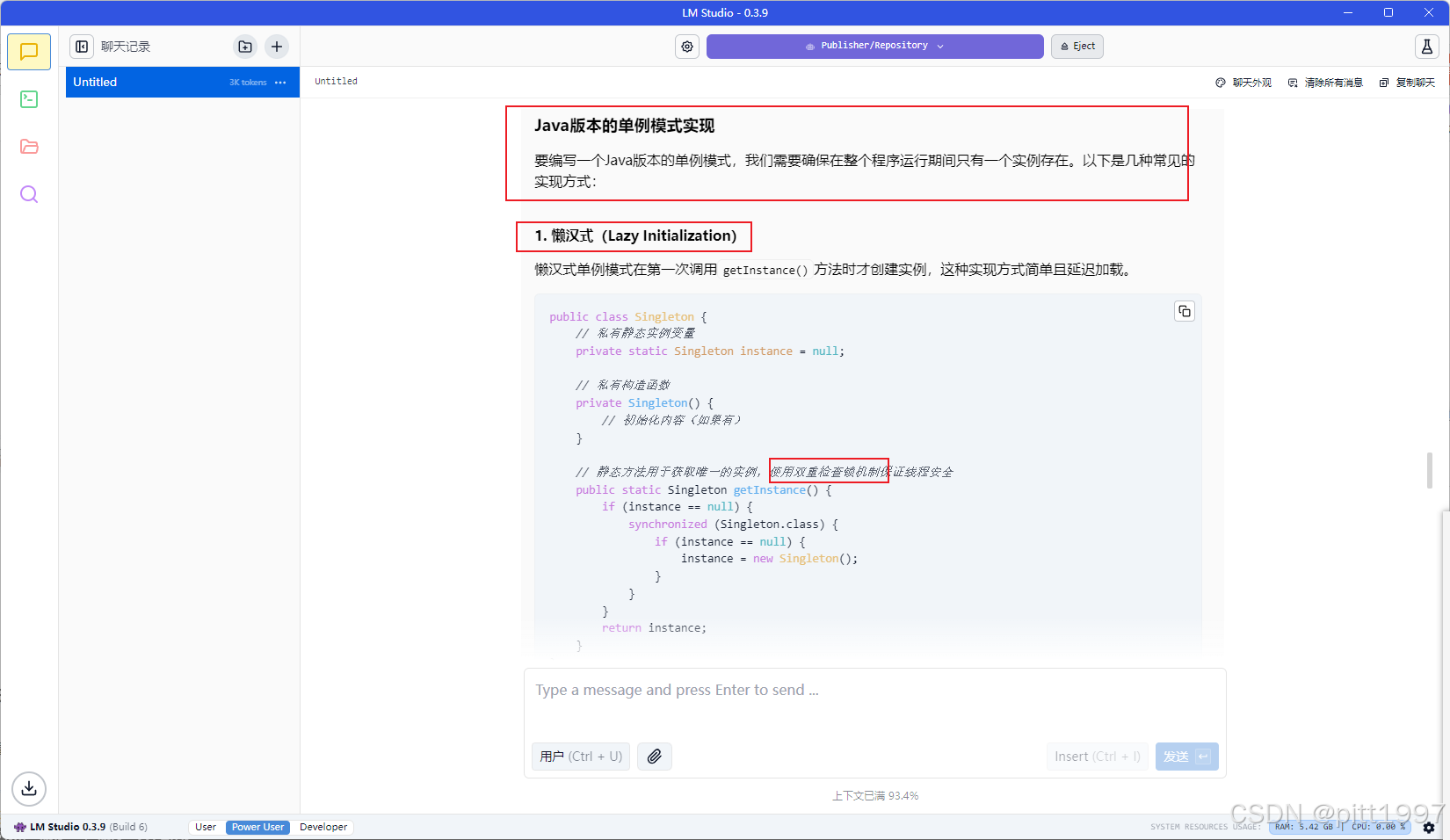
结果比较准确,两个方式都解答出来了。
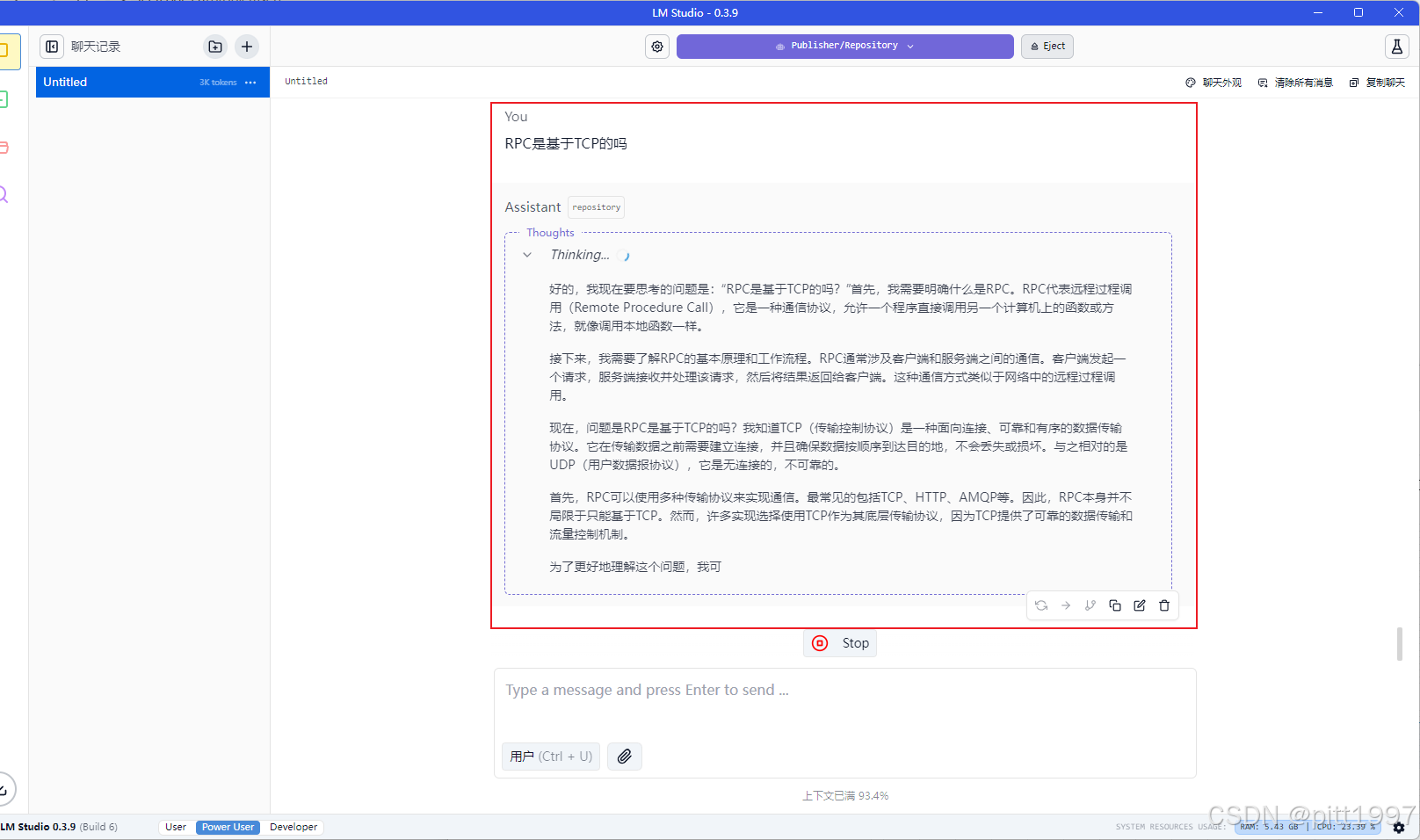
提示词:RPC是基于TCP的吗RPC是基于TCP的吗(思考推理稍微有点慢,但是结果比较准确)
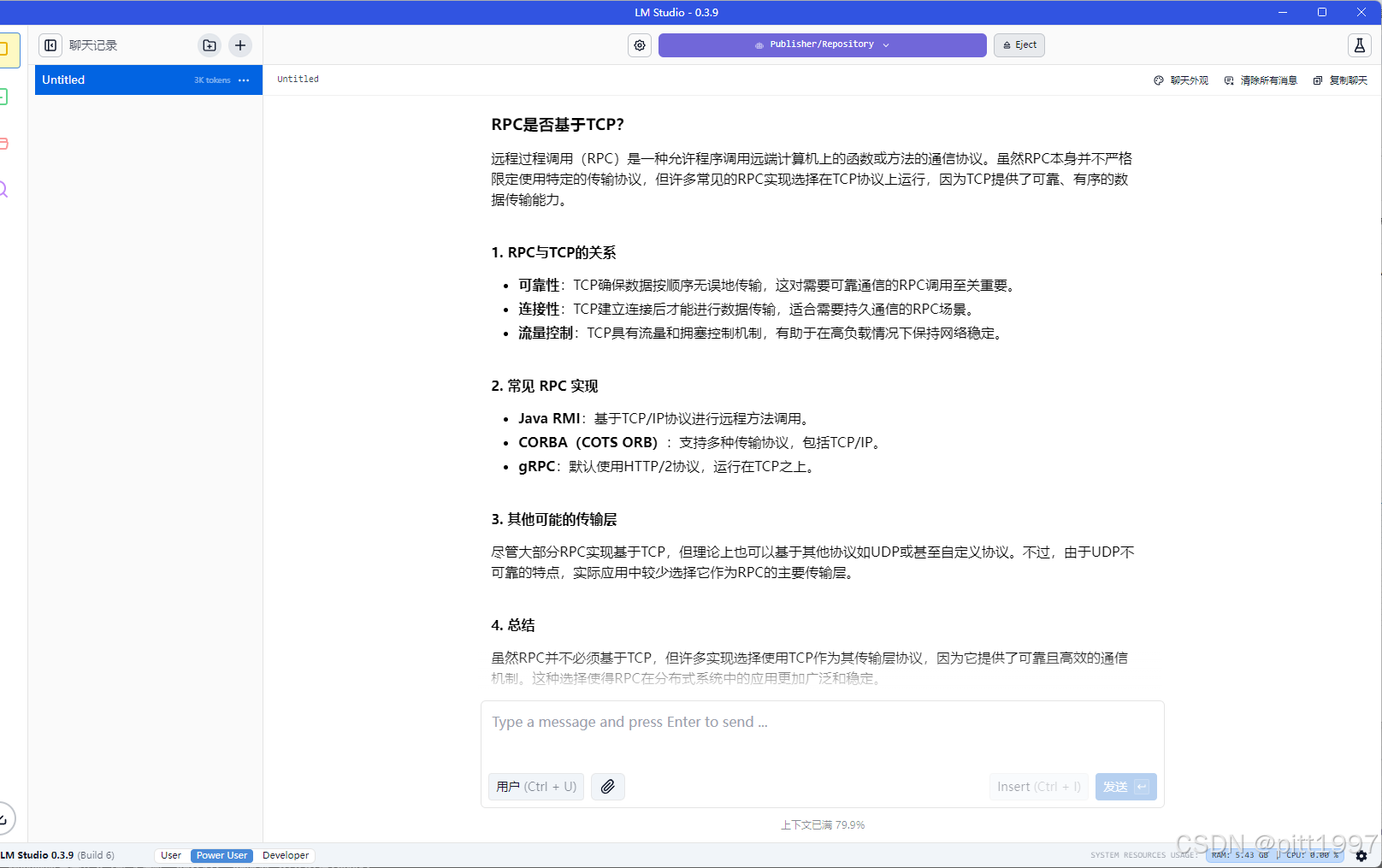
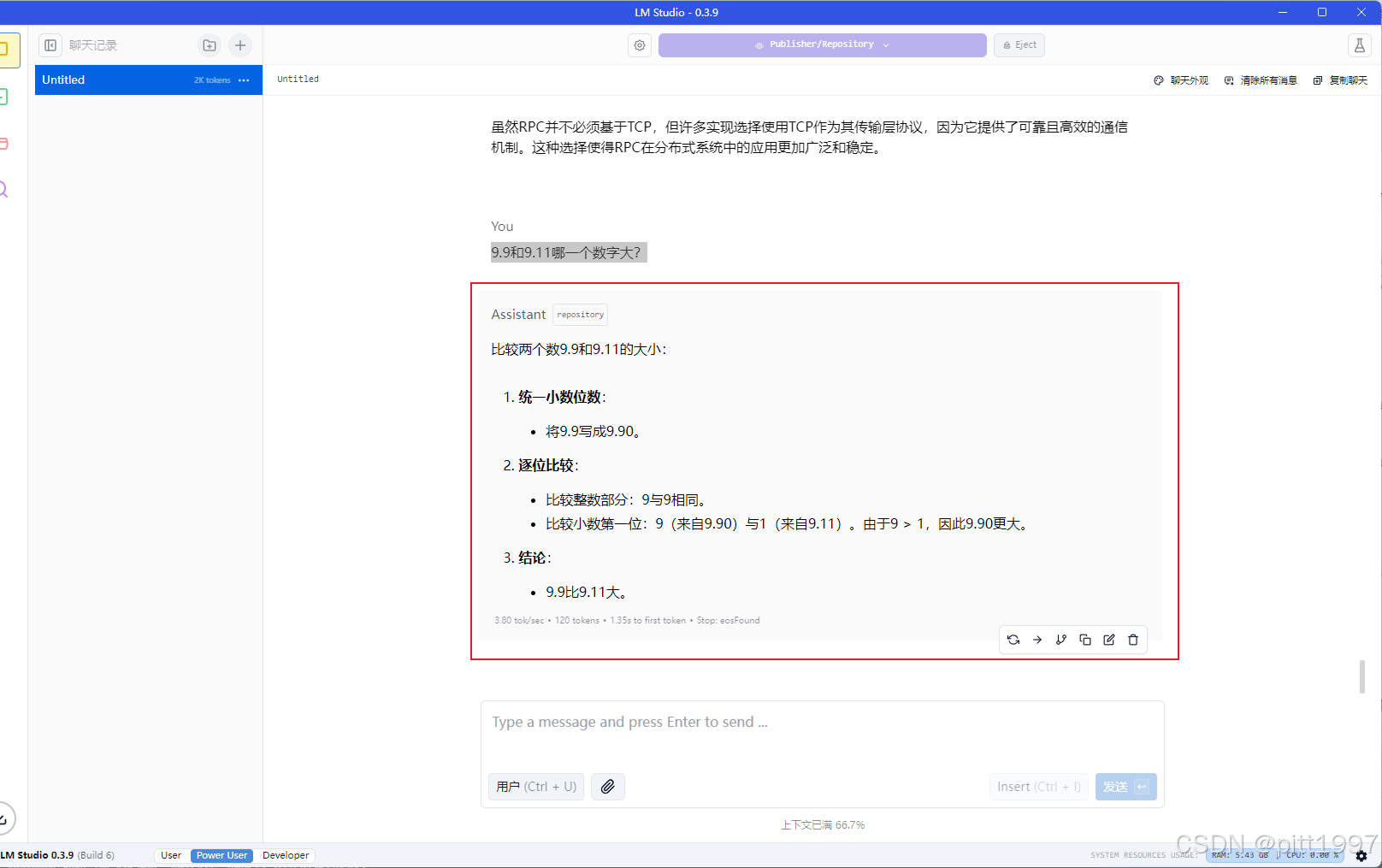
提示词:9.9和9.11哪一个数字大?这是一个比较有意思的问题(哈哈哈思考推理比较快,但是结果不太对,比较独特的推理,这个问题很多大模型都会答不太对)
5. GPU 加速 & 参数优化
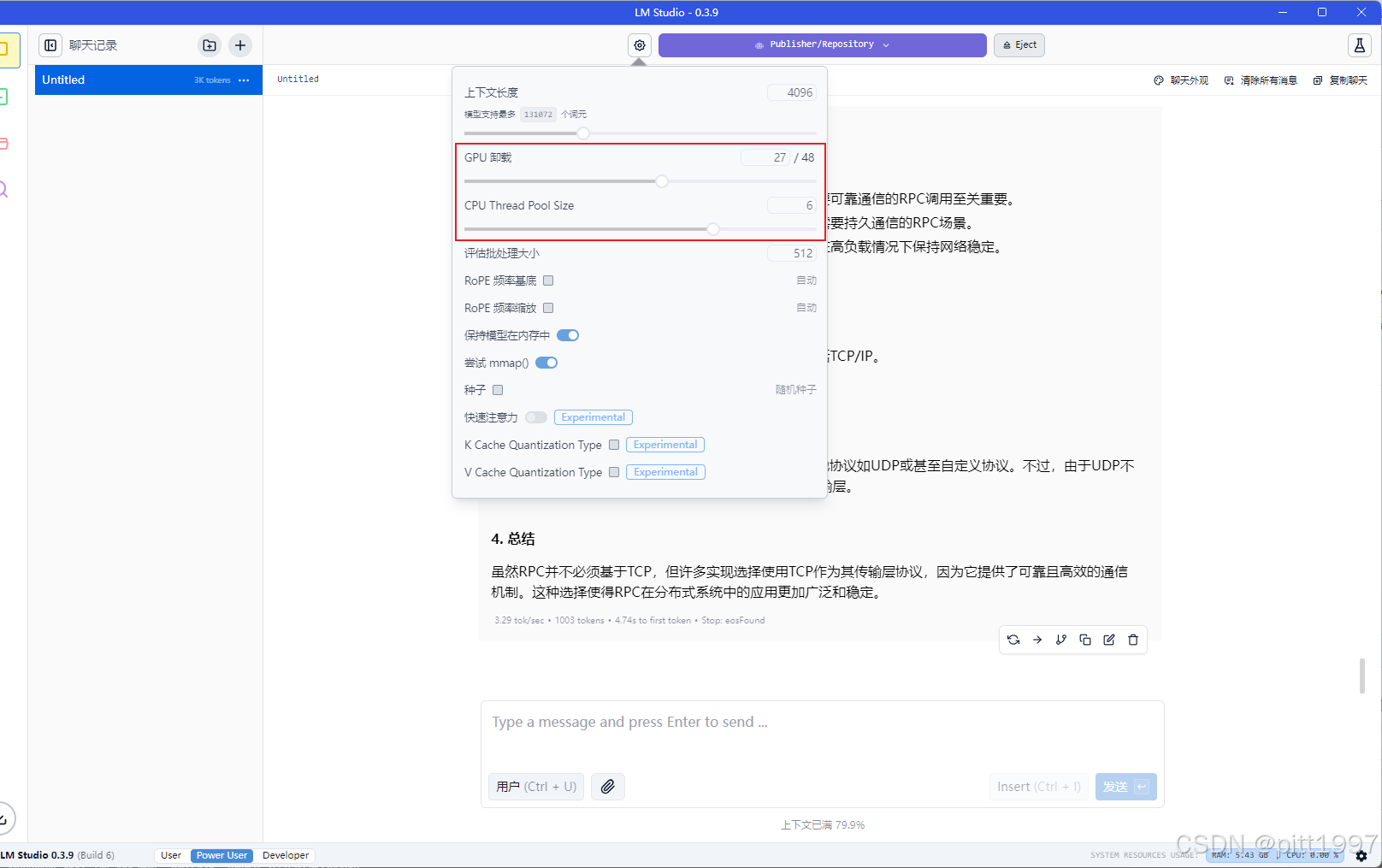
开启 GPU 推理
在 Settings(设置) 里调整:
GPU Offload→ 建议 20-30(启用 GPU 加速)
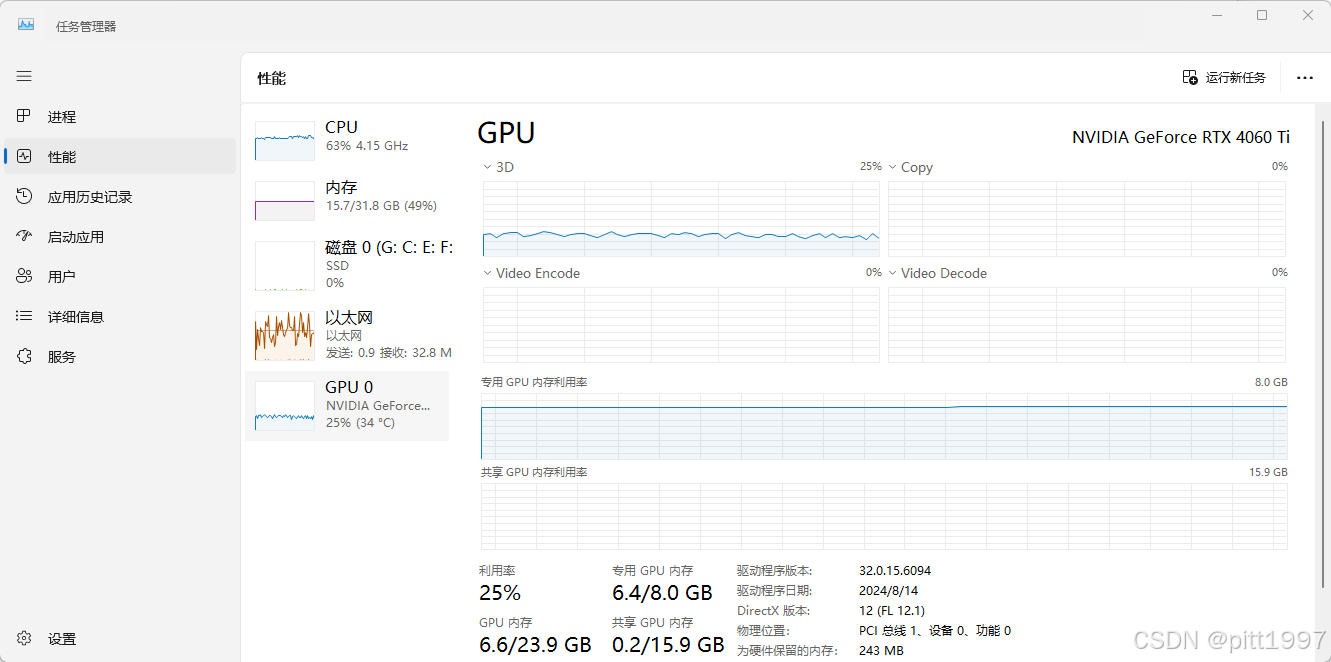
验证运行过程还是比较吃资源,运行时电脑稍微有点卡。
💡 不同显存推荐参数
| 模型 | 参数量 (B) | 原始 FP16 (GB) | Q4_K_M (GB) | Q5_K_M (GB) | 推荐显卡 |
|---|---|---|---|---|---|
| DeepSeek 7B | 7B | ~28GB | ~4GB | ~5GB | 4060Ti 8G |
| DeepSeek 14B | 14B | ~56GB | ~8GB | ~10GB | 4070 12G |
| DeepSeek 32B | 32B | ~128GB | ~18GB | ~22GB | 4090 24G |
| Qwen 7B | 7B | ~28GB | ~4GB | ~5GB | 4060Ti 8G |
- DeepSeek-7B / Qwen-7B 适合 4060Ti
- DeepSeek-14B 推荐 4070 12G 以上
- DeepSeek-32B 推荐 4090 24G+
6. 总结
✅ LM Studio 是最简单的本地大模型推理工具之一
✅ 支持 LLaMA / Qwen / Mistral / DeepSeek 等 GGUF 模型
✅ 可以用 RTX 4060Ti / 4070 / 4090 跑 7B / 14B/ 32B 量化模型
✅ 适合 AI 开发者 / 学习者 / 自媒体从业者本地跑大模型
📢 模型测试验证视频后续更新,包含由清华大学新闻与传播学院沈阳团队出品的《DeepSeek:从入门到精通》PDF版DeepSeek课程课件,可通过关注B站账号私信获取。
MacBook Air (Apple M2)DeepSeek R1 7B 本地大模型效果实测
💡 你是否用过 LM Studio 跑本地大模型?欢迎评论区交流!🌟 你的支持是我持续创作的动力,欢迎点赞、收藏、分享!


















 3653
3653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











