







目录
问题场景
在使用PaddleOCR对图像或PDF进行OCR处理后,会返回一个结果数组,每个item包含了文本框,文字和识别置信度。如果我们识别的内容比较多,并且内容带有一定的顺序关系,比如识别一个答题卡,这样对于结果数组中的顺序性会有一定要求。
在实际测试下,我们发现如果识别的图片出现一定的倾斜或手写内容不工整时,返回的结果数组会发生乱序,导致在获取关键信息的时候出现问题。
在查阅PaddleOCR的官方文档后,我们发现导致乱序的原因是因为PaddleOCR在识别完成后它有自己一套的排序规则,如下图所示。它首先通过文本框的左上角坐标对它们进行排序,然后遍历排序后的文本框,如果相邻两个文本框的垂直距离小于10并且后一个文本框的横坐标小于前一个文本框的横坐标,则交换它们的位置。最后返回排好序的文本框数组。
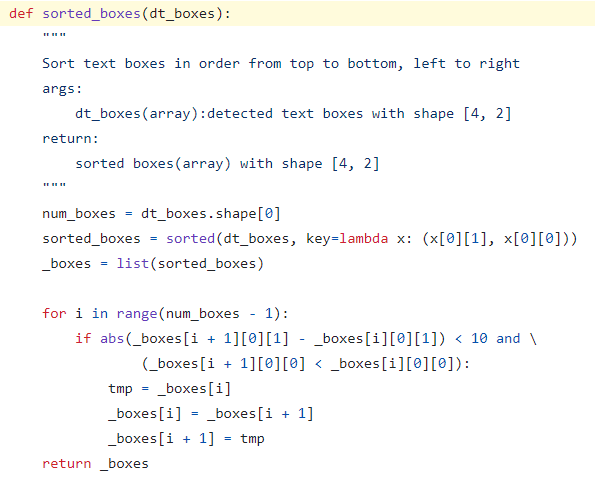
图1 官方排序逻辑
由于判定垂直的距离是固定的而且太小,这样的排序规则就导致了当识别的图片出现一定的倾斜,它会把右边后方的内容排到前面去,还有就是如果某一题中的手写字体比较大,由于它的识别框比前面的要大,所以也会排到前面去,从而造成乱序的问题。
解决方法
在搞清楚问题的原因后我们想到的解决方法是,根据返回的可能乱序的结果数组,重新再根据一套规则再排一次序,具体排序逻辑为根据识别结果中识别框的位置,先计算中心点y坐标,即平均y坐标,再设定一个可以调整的阈值,如果接下来的结果少于这个数,则视为同一行,然后每一行根据x坐标从左到右排列。算法流程图如下图所示。
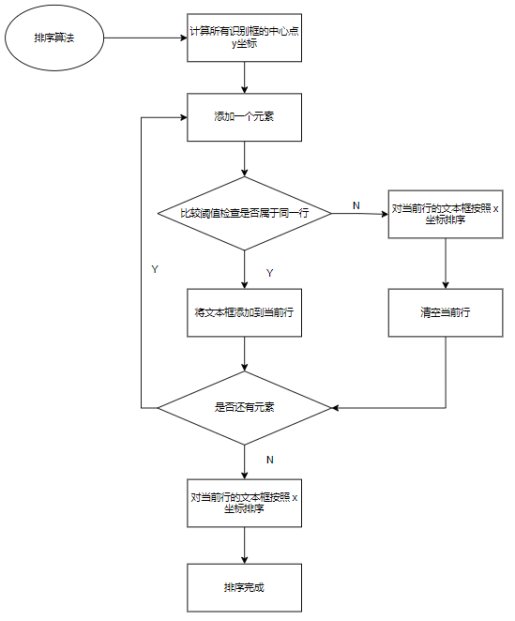
图2 排序算法流程图
在实际的测试下,在确保识别的图片倾斜角度不大的条件下,排序算法能够很好的把结果数组的顺序还原出来,接下来在只需按序捕获即可得到学生的选择题答案。使用算法优化的前后效果如下图所示。
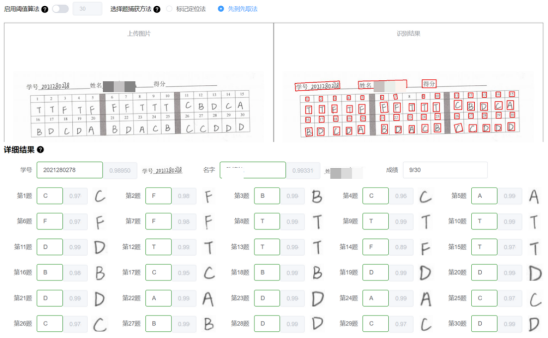
图3 不使用排序算法识别结果
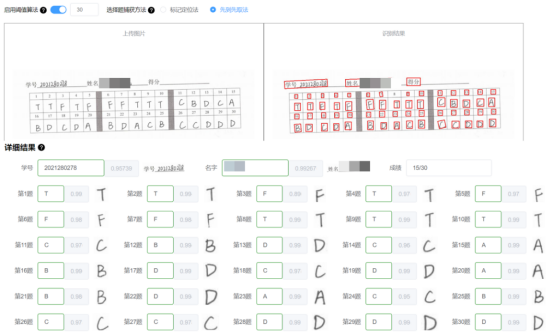
图4 使用排序算法识别结果
可以看到尽管不使用排序算法依然可以把结果识别出来,但由于图片存在一定的倾斜,导致识别结果乱序。在使用排序算法把结果数组的顺序还原后,获取的结果为全部正确。
参考代码
以下代码仅供参考,可根据自身需求调整,比如可以在python端OCR处理后立即排序,也可以像下面那样返回前端后再处理。
// 参数
// data: 识别框坐标数组
// threshold: 阈值
sortByCoordinates(data, threshold = 20) {
// 计算每个框的平均 y 坐标
const avgYCoordinates = data.map((box) => {
const [topLeft, topRight, bottomRight, bottomLeft] = box;
const avgY =
(topLeft[1] + topRight[1] + bottomRight[1] + bottomLeft[1]) / 4;
return avgY;
});
const sortedData = [];
const sortedIndex = [];
const sortedCharacter = [];
const sortedAccuracy = [];
let currentRow = [];
// 根据平均 y 坐标分组并排序
for (let i = 0; i < data.length; i++) {
if (currentRow.length === 0) {
// 如果当前行为空,则直接添加第一个元素
currentRow.push({ index: i, avgY: avgYCoordinates[i] });
} else {
// 判断是否在同一行
if (Math.abs(avgYCoordinates[i] - currentRow[0].avgY) <= threshold) {
// 在同一行,加入当前行
currentRow.push({ index: i, avgY: avgYCoordinates[i] });
} else {
// 不在同一行,对当前行进行排序,然后加入结果数组
currentRow.sort((a, b) => {
// eslint-disable-next-line no-unused-vars
const [aLeft, aRight] = data[a.index][0];
// eslint-disable-next-line no-unused-vars
const [bLeft, bRight] = data[b.index][0];
return aLeft - bLeft; // 按照 x 坐标排序
});
sortedData.push(...currentRow.map((item) => data[item.index]));
sortedCharacter.push(
...currentRow.map((item) => this.character[item.index])
);
sortedAccuracy.push(
...currentRow.map((item) => this.accuracy[item.index])
);
sortedIndex.push(...currentRow.map((item) => item.index)); // 记录排序后的索引
// console.log(currentRow);
// 清空当前行
currentRow = [{ index: i, avgY: avgYCoordinates[i] }];
}
}
}
// 处理最后一行
if (currentRow.length > 0) {
currentRow.sort((a, b) => {
// eslint-disable-next-line no-unused-vars
const [aLeft, aRight] = data[a.index][0];
// eslint-disable-next-line no-unused-vars
const [bLeft, bRight] = data[b.index][0];
return aLeft - bLeft; // 按照 x 坐标排序
});
sortedData.push(...currentRow.map((item) => data[item.index]));
sortedCharacter.push(
...currentRow.map((item) => this.character[item.index])
);
sortedAccuracy.push(
...currentRow.map((item) => this.accuracy[item.index])
);
sortedIndex.push(...currentRow.map((item) => item.index)); // 记录排序后的索引
}
return sortedData;
}

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









