









 本文分享了一个基于乘积量化(PQ)算法的实验过程与结果,该实验旨在复现一篇检索领域的研究论文成果。通过对GIST1M数据集的处理与分析,详细探讨了PQ算法如何提高大规模数据集的检索效率。
本文分享了一个基于乘积量化(PQ)算法的实验过程与结果,该实验旨在复现一篇检索领域的研究论文成果。通过对GIST1M数据集的处理与分析,详细探讨了PQ算法如何提高大规模数据集的检索效率。
最近邻搜索之乘积量化(Product Quantizer)实验
记得大学三时有个老师跟我们说,检验是否深刻理解一篇论文的做法之一就是给你一篇论文,看你能否将论文中的结果重复实验出来,当时觉得老师的说法好厉害、离我们太远,而且一直没有机会这么干过。恰巧,最近进行了一次关于一篇检索论文的PQ实验结果,终于亲身体验了一回老师之前的话。
闲话少说,这次PQ实验主要是深刻理解论文,通过实验体会PQ算法是如何将大搜索空间分解为小的搜索空间提高检索效率的,并最终得到论文中如下IVFADC的结果:
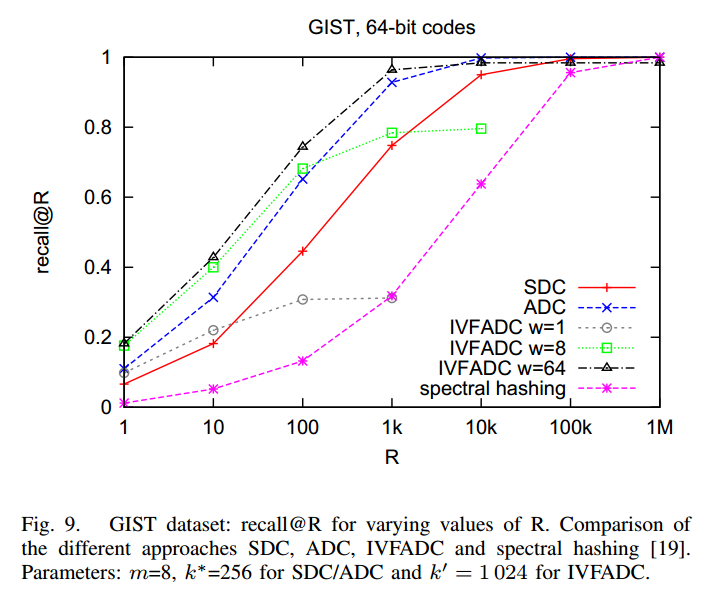
一、实验设置
1.数据集
数据集取自评价最近邻算法的标准数据集之一GIST1M,网址:http://corpus-texmex.irisa.fr/。使用其中的gist_base.fvecs用做训练集,共100万个特征,每个特征960维,解压出来3.57G大小,float类型;使用gist_query.fvecs用作测试集,共1000个特征,float类型;使用gist_groundtruth.ivecs来判断测试集的结果是否正确,int类型,是存储的是1000*100个query id,下标从0开始,对应gist_query.fvecs中1000个query的top100近邻,对每个query的结果id,按照它到query的距离从小到大排列。
2.评价标准
采用recall@R,recall@R的定义如下:
The performance measure is recall@R, that is, for varying values of R, the average rate of queries for which the 1-nearest neighbor is ranked in the top R positions.
因此,在求recall@R的时候只需要看gist_groundtruth.ivecs中每个query的第一个答案是否出现在其TopR中,如果在其中,计算器count加1,最后算count/1000就得到了recall@R。一句话,recall@R就是测试集的TopR结果中包含1-NN的比例。
3.PQ参数设置
训练参数:
- 量化参数。gist特征维数是960,按照64bit编码,乘积量化时分组数m=8,那么每组采用8bit,即每组的类大小为KS=2^8=256。粗糙量化时分类数是1024。
- 迭代次数。在上述参数设置下,经过100次试验发现迭代到50次时错误率不再下降,值为1.106,根据选取误差水平线中间值原理,粗糙量化k-means迭代次数为55次,k-means类中心初始化方法采用随机化方法和KMEANS_INIT_BERKELEY效果一样。乘积量化时,由于共有8次执行k-means过程,收敛时迭代次数不一样,取值为25,保证大多数收敛。
测试参数:
- 测试时采用multiple assignment技术,m_w取值为1,8,64。R取值为10的0到5次幂。由于R取为10的6次幂时程序被killed,这个值就省略了,理论上recall@R应该是1.0。
二、编程实验
代码我放在了csdn上,,网址: http://download.csdn.net/detail/chieryu/9377535。使用的是C++,用到了yael库和blas,压缩包里已经包含了。这个代码是大部分参考了gitHub上另一个代码的:https://github.com/lostmarble/product-quantization。另外要能运行这个代码,要求至少6G内存。
其中gitHub画图的代码如下:
b=[ 0.087 0.214 0.488 0.701 0.74 0.74]
a=[0 1 2 3 4 5]
b=[ 0.077 0.165 0.259 0.292 0.294 0.294]
plot(a,b,'k:');
hold on;
plot(a,b,'rx');
xlabel('R');
ylabel('recall@R');
title('GIST, 64-bit codes');
hold on;
b=[ 0.087 0.214 0.488 0.701 0.74 0.74]
plot(a,b,'-.');
hold on;
plot(a,b,'r*');
hold on;
c=[ 0.086 0.218 0.521 0.845 0.972 0.978];
plot(a,c,'b--');
hold on;
plot(a,c,'rs');
axis([0 5 0 1])
set(gca,'XTick',0:1:5);
set(gca,'YTick',0:0.2:1);
set(gca,'XTickLabel',{'1','10','100','1K','10K','100K'});
text(3.3,0.2,'IVFADC w=1');
plot([4.3 4.5 4.7],[0.2 0.2 0.2],'k:');
plot(4.5,0.2,'rx');
text(3.3,0.16,'IVFADC w=8');
plot([4.3 4.5 4.7],[0.16 0.16 0.16],'-.');
plot(4.5,0.16,'r*');
text(3.3,0.12,'IVFADC w=64');
plot([4.3 4.5 4.7],[0.12 0.12 0.12],'b--');
plot(4.5,0.12,'rs');
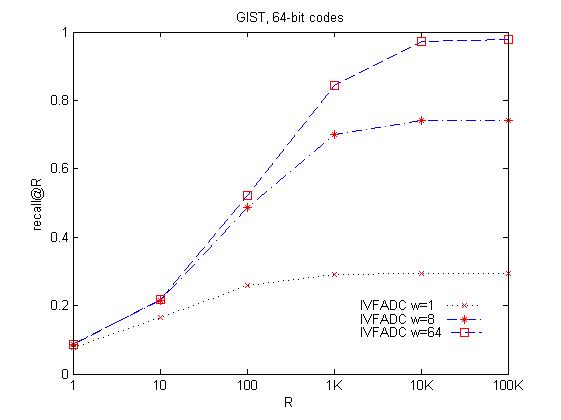
三、实验结果(on GIST1M)
- 我得到的结果如下:
这个横坐标的单位是10的n次幂。
与原文的结果比较。大体趋势时相同的,但是当R取10的0次幂时,我的起点是0.1左右,而作者的是0.2左右,这个地方一直没搞明白。后来通过把KS从256改为1024时,发现在m_w为64时起点可以达到0.36,后来也在文献《Locally Optimized Product Quantization for Approximate Nearest Neighbor Search》中发现这个作者重复的实验起点也在0.1左右。这个原因暂时没搞清。
2.将特征分组由natural order改为structure order,得到的结果如下:
从上到下,各条折线的值依次是:
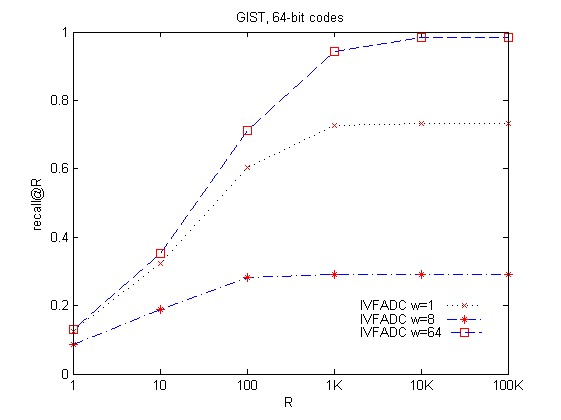
[ 0.085 0.189 0.282 0.291 0.291 0.291]
[ 0.125 0.323 0.603 0.727 0.732 0.732]
[ 0.13 0.351 0.711 0.944 0.984 0.985]
补充说明:这个结果是没有采用原始特征进行重排的结果,原文中的对返回的结果进行重排了,目的是为了跟FLANN进行比较。
代码下载链接:http://download.csdn.net/detail/chieryu/9377535
四、总结
1.重复别人实验结果的过程也是很有意思的,能学到很多东西,可以帮助深刻理解论文,做完实验再回读论文觉得轻松多了。
2.如果有必要,一定要读别人的代码,因为说不定其中隐藏着一些小错误使得实验结果差别很大的。
3.细节决定成败,要大胆假设,更要小心求证,严谨很重要的。
(转载请注明作者和出处:http://blog.csdn.net/CHIERYU 未经允许请勿用于商业用途)

















 4796
4796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









