






开放域对话系统:没有限定主题或明确目标,用户与系统之间自由对话。
特定域对话系统,面向具体任务。
如:任务型对话(siri),属于特定域,完成任务或动作,话轮数越少越好。
闲聊型(微软小冰),属于开放域,闲聊,话轮数越多越好。
问答型
目录
1.任务型对话系统
任务型对话系统主要由两种方法:管道方法,端到端方法。
1.1管道方法
关键模块:自动语音识别ASR,自然语言理解NLU,对话管理DM(对话状态跟踪DST,对话策略DP),自然语言生成NLG,语音合成TTS。
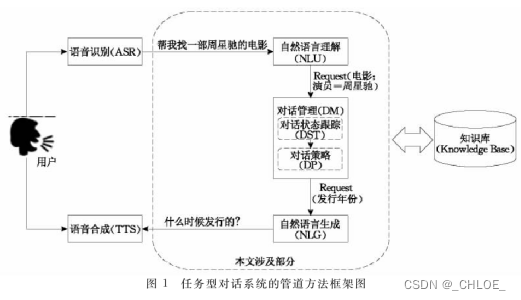
1.1.1 NLU
将用户说出的自然语言尽可能的转化为计算机能理解的形式。通常包括三个任务:领域检测,意图识别,语义槽填充。
领域检测和意图识别都属于文本分类任务,根据用户当前的输入推断出用户的意图和涉及的领域。
应用在文本分类任务的
(1)传统机器学习模型:K近邻,朴素贝叶斯,SVM。
(2)深度学习模型:CNN和RNN结合,可以抓取任意长度的序列,可以分析长句之间的关系,同时具有记忆功能。
语义槽填充本质上属于序列标注问题。
应用在序列标注任务上常用的
(1)线性统计方法:隐马尔科夫HMM,最大熵马尔科夫,条件随机场CRF
(2)深度学习方法:长短期记忆网络LSTM,门控制循环单元GRU,
(3)结合的方法:LSTM+CRF
1.1.2.DM
根据历史对话和用户当前输入,决定系统要采取的的动作,包括追问,澄清,确认等。
比如Book a table at haidilao for 5 ,是5个人,还是5点钟,是上午5点还是下午5点?这时候需要需要再次询问用户。
DST维护对话状态,它根据NLU的结果,将旧对话状态更新为新对话状态。对话状态应该包含对话所需要的各种信息,主要有三种方法
- 基于人工规则的方法:人工定义好所有状态和状态转移的条件,使用分数最高的NLU模块解析结果进行状态更新。
- 基于生成式模型:从训练数据中学习相关联合概率的密度分布, 计算出所有对话状态的条件概率分布作为预测模型,减少了人工成本,但无法精确建模特征之间的依赖关系。
- 基于判别式模型:把DST当做分类任务,结合深度学习进行自动特征提取,但需要大量的标注数据,适用于大规模含有标注的数据集的场景。
1.1.3 DP
根据DST维护的状态,确定当前状态下系统该如何答复,即采取何种策略是最优的。
- 基于监督学习
- 基于模仿学习
- 传统强化学习
- 深度强化学习
1.1.4 NLG
将DM输出结构化对话策略转化成对人友好的自然语言。
主要方法:
(1)基于模板或句子规划的方法:无需训练数据,简单,但难以维护,可移植性差。
(2)基于统计语言模型模型:规则简单,易于实现和理解,但计算效率低,扩展性差。
(3)基于神经网络的方法:seq2seq,动态神经网络DMN,常态知识感知会话模型CCM,GAN。
1.1.5 NLG评估技术
(1)人工评测回复的适当性,流利性,可读性,多样性。
(2)利用BLEU,METEOR,ROUGE分数自动评估
管道方法一般分别建立NLU,DM,NLG等模块,模块又可以分成子任务,各个模块分工明确,解决各自问题。
问题:
(1)领域相关性强,每个领域都需要人工设置语义槽,决策,难以扩展到新领域。
(2)模块之间相互独立,每个模块都需要大量领域相关的标注数据。
(3)模块处理相互依赖,上游模块的错误会关联到下游模块。当将一个模块调整到新环境,其他模块也要相对调整,这个过程会消耗大量的人力。
1.2端到端方法
端到端方法将管道方法中的三个模块用统一的端到端方法代替,根据用户输入,直接生成相应的回复。
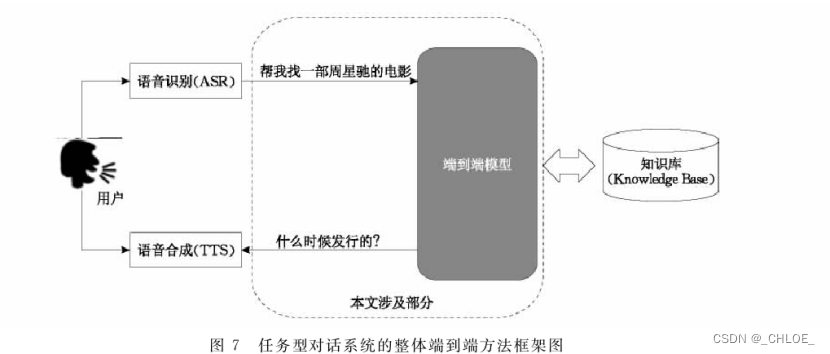
1.2.1端到端代表性方法
(1)基于监督学习框架
(2)基于强化学习框架
(3)混合框架
1.2.2端到端方法总结
端到端的系统一般使用一个Seq2Seq模型,根据用户的输入,直接生成响应的回复,有结构简单,便于移植的优点,同时解决了标注数据不足的问题。由于任务型对话的特殊性,使用简单的Seq2Seq模型无法生成时效性,地点相关等回复,所以还需要相应的知识库和常识库辅助。
1.3任务型对话系统评估方法
1.3.1分模块进行评价
(1)自然语言理解NLU:分类问题,准确率,召回率
(2)对话状态跟踪DST:假设准确率,平均概率,ROC表现,正确接受率5/10/20,平均排序倒数
(3)对话策略:DP:任务完成率,平均对话论述
(4)自然语言生成NLG:主流技术为基于模板的方法,不做评价
1.3.2评估整个对话系统更全面的指标
(1)部署动态系统的评价:在真实用户群中检测用户的满意度。
(2)基于用户模拟的方法:有效且简单,但是真实用户与模拟用户存在差距。
(3)基于人工评价的方法:雇佣测试人员对对话系统生成的结果进行人工评价,缺点是开销很大,还有就是评测人员是否真的能代表所有用户的问题。
(4)多种方法混合。
1.4任务型对话系统面临的问题
(1)如何利用更少的标注数据,开发一个更好的系统?
(2)领域迁移问题
(3)鲁棒性:输入噪音较大,如何正确回应
(4)端到端如何更可控
2.开放型对话系统
开放型对话是对话系统一个重要分支,它不同于任务型对话,具有较强的随机性与不确定性。
可基于检索或生成的方法进行人机对话的交互。对话系统可以分为单轮和多轮对话,单轮对话主要考虑基于问题的回答,而多轮对话则注重上下文的整体信息,输出符合上下文的信息。
2.1基于检索的方法
先构建一个供检索的对话语料库,将用户输入的话视为对该索引系统的查询,从中选一个回复。
2.1.1单轮检索
核心步骤是构建查询-恢复匹配模型,其中包含语义表示模型和语义融合模型,语义表示模型将查询和回复映射到语义向量;语义融合模型是对查询语义向量和回复语义向量融合过程建模。
2.1.2多轮检索
与单轮检索最大的区别在于:多轮对话系统需要整合当前的查询和历史信息作为输入。
2.2基于生成的方法
首先收集大规模对话语料作为训练数据,基于深度神经网络构建端到端的对话模型,系统根据模型计算输入语义向量,再逐个生成词语组成回复语句。
2.2.1单轮生成
(1)seq2seq模型框架,(2)神经语言模型框架 (3)强化学习框架
2.2.2多轮生成
(1)seq2seq模型框架,(2)神经语言模型框架 (3)层次seq2seq模型框架
2.3检索和生成相结合的方法
- 使用检索模型检索到的候选结果和查询同时作为seq2seq模型中encoder的输入生成结果,然后把这个结果加入原检索候选集中,进行重新排序。
- 将两个模型融合,先通过传统的检索模型找出候选集,然后训练带注意力机制的seq2seq的生成模型对候选答案进行重新排序,选择回复时,如果第一候选回复的得分超过某个阈值,就直接输出该回复,否则使用生成模型的回复。
3.补充学习
3.1 Encoder-decoder:
Encoder-decoder并不是一个具体的模型,而是一个通用的框架。
Encoder-decoder部分可以是文字,语音,图像,或者视频
模型可以是CNN,RNN,LSTM等
Seq2seq
输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。Seq2Seq 强调目的,不特指具体方法,满足输入序列,输出序列的目的,都可以统称为 Seq2Seq 模型。Seq2Seq 使用的具体方法基本都是属于 Encoder-Decoder 模型的范畴。
缺陷:输入一个序列,通过RNN转化成向量C,再将C转化成输出序列,中间的向量C长度是固定的,所以RNN结构的Encoder-Decoder模型存在长程梯度消失问题,对于较长的句子,会丢失信息。即便LSTM加了门控制机制可以选择性遗忘和记忆,随着句子难度增加,效果仍不理想
3.2 Attention
为了解决Encoder-Decoder的缺陷,提出了Attention,Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
Attention的思路是带权求和。
将Encoder网络中的hidden layer记为h(t),把Decoder网络中的hidden layer记为H(t),第t个输出词记为y(t),Decoder网络中的式子可以表示为 H(t) = f[ H(t-1) , y(t-1) ]
要让网络注意并利用原文中不同的词句和语句,
Decoder网络中的式子可以写成 H(t) = f[ H(t-1) , y(t-1) , Ct ] Ct指的是时刻t的上下文向量,定义为h(t)加权平均的结果,Ct= Σ ati * h(t) 。给h(t) 分配的权重就叫做全局对齐权重。
全局对齐权重 αk 很好的体现了在计算第 k 个输出词语时,应该给所有的 h(t) 怎样的权重,其中 aki 就代表着计算第k个输出词语时, h(i) 分配到的权重大小。
最后是如何计算出ak
设计一个以H(i-1),h(j)为输入的网络
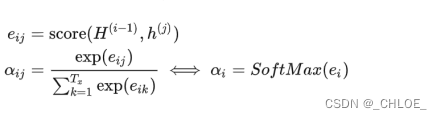
3.3 TF-IDF
TF即是词频,IDF即逆文档频率。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
假如一片文章有 1000 个词,
"中国” 这个词出现了 20 次,
"梦想" 这个词出现了 10 次,
"我" 这个词出现了 50次
有一个文件库,它是用来求IDF用的,文件库包含了5000个文档 在这5000个文档中,
步骤1:计算词频TF
TF公式:
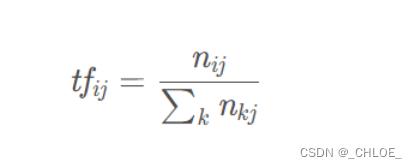
TF(“中国”)=20/1000=0.02
TF(“梦想”)=10/1000=0.01
TF(“我”)=50/1000=0.05
步骤2:计算逆文档频率IDF
IDF公式: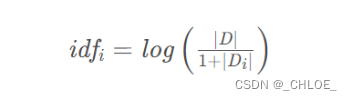 分母之所以加1是采用了拉普拉斯平滑,比避免有部分新的词没有在语料库中出现过而使分母为0的情况出现,增强算法的健壮性。
分母之所以加1是采用了拉普拉斯平滑,比避免有部分新的词没有在语料库中出现过而使分母为0的情况出现,增强算法的健壮性。
包含 “中国” 的文档数为 1000,IDF(“中国”)=log(5000/1001)=0.6985
包含 “梦想” 的文档数为 500,IDF(“梦想”)=log(5000/501)=0.9991
包含 “我” 的文档数为 2000,IDF(“我”)=log(5000/2001)=0.3977
步骤3:计算TF-IDF
公式: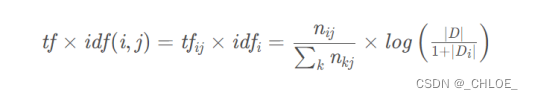
TF-IDF(“中国”)= TF(“中国”) * IDF(“中国”)=0.01397
TF-IDF(“梦想”)= 0.09991
TF-IDF(“我”)= 0.019885
如果某个词比较少见(IDF值较高),但是它在这篇文章中多次出现(TF值较高),那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。 从上面计算可以看出 TF-IDF(“梦想”)的值较高,可以把"梦想"作为这篇文章的关键词

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









