







今天介绍的主干网络模型叫VGG,是一个比较早期,比较简单的特征提取网络,包括VGG16和VGG19等,由牛津大学的Visual Geometry Group提出;接下来我将从模型拓扑结构、模型特点、模型优缺点和模型代码实现这几个部分来展示,一起了解学习VGG系列模型;
一、模型介绍
VGG代表的是Visual Geometry Group,这是位于英国牛津大学的一个研究小组。该团队专注于计算机视觉的研究工作,特别是在图像识别领域有着深入的研究。VGG网络是他们在2014年发表的一篇论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》中提出的一种深度卷积神经网络结构。
二、拓扑结构
VGG网络以其简洁明了的设计著称,主要特点是使用了大量小尺寸的卷积核(通常是3x3的卷积核),并且每个卷积层后面都跟着一个ReLU激活函数。此外,网络中还包含了池化层,用来降低特征图的空间维度。整个网络由一系列这样的卷积层和池化层组成,最终通过几个全连接层输出分类结果。
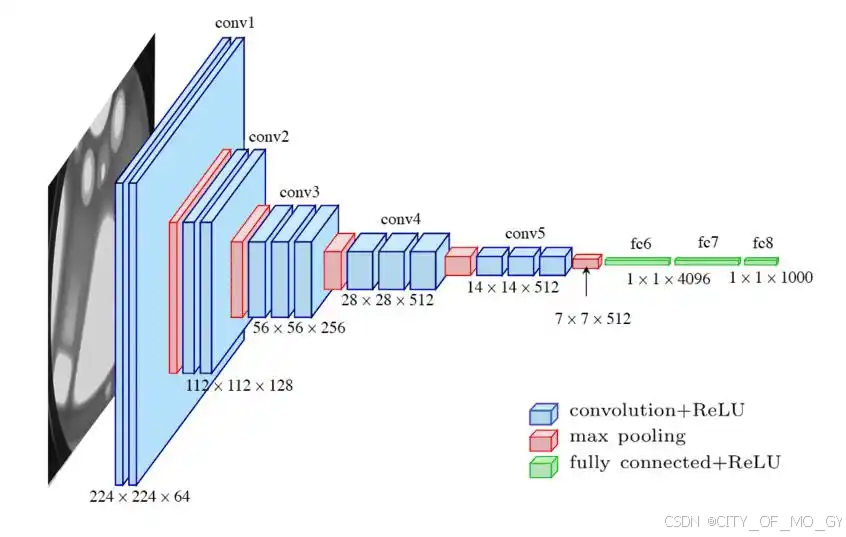
上图是一个VGG-16模型的拓扑图, 从图中我们可以很直观的看到组成模型的基本就只有三种类型的网络层,分别是蓝色的卷积层、红色的池化层和绿色的全链接层;在这三类层中,只有最大池化层不包含权重信息,所以可以进行反向传播训练的只有卷积层和全链接层,而这两种层的数量和为16,所以上图的VGG拓扑图为VGG-16的拓扑结构;
在卷积操作中,VGG-16使用3x3的小卷积核,可以减少参数数量,同时保持足够的感受野,每一个卷积核后面会接一个ReLU激活函数来提高模型非线性拟合能力;每一组卷积层后面跟随一个最大池化层,这种模式在整个网络中重复出现,在最后的几层,使用了较大的全连接层来进行分类,这就是整个网络的结构,非常的简洁清晰;
三、代码实现
根据上面的模型拓扑介绍,我们大概了解了VGG-16模型的结构,而在实际的应用中,VGG经常用来做各种视觉任务的Backbone部分,用于提取特征信息,即经常使用的VGG是不包含最后三个全链接层的网络;我们试着用pytorch来实现一下VGG作为Backbone的代码;
# Backbone-VGG16
import torch
import torch.nn as nn
import torch.nn.functional as F
class VGG16Features(nn.Module):
def __init__(self):
super(VGG16Features, self).__init__()
# 卷积层和池化层
self.features = nn.Sequential(
# 第一组卷积层
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第二组卷积层
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第三组卷积层
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第四组卷积层
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第五组卷积层
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
def forward(self, x):
x = self.features(x)
return x
# 示例用法
if __name__ == "__main__":
model = VGG16Features()
input_tensor = torch.randn(1, 3, 224, 224) # 假设输入图像大小为224x224
output = model(input_tensor)
print(output.shape) # 输出形状应为 (1, 512, 7, 7)代码解释:
1.初始化:__init__ 方法中定义了所有的卷积层和池化层,这些层按照 VGG-16 的标准结构进行排列;
2.前向传播:forward 方法中调用了 self.features,将输入图像通过所有的卷积层和池化层;
3.示例用法:在 if __name__ == "__main__": 部分,创建了一个 VGG16Features 实例,并传入一个随机生成的输入张量,输出形状为 (1, 512, 7, 7),这符合 VGG-16 的特征提取部分的输出;
这样以来,模型可以作为一个特征提取器,用于各种计算机视觉任务,如目标检测、语义分割等;
四、模型优缺点
优点:
- 简单有效:VGG网络的设计非常直观,易于理解和实现,这对于新手来说是一个很大的优势。
- 强大的特征表示能力:由于其深度,VGG能够在不同的抽象层次上捕获图像的特征,这对于复杂的视觉任务非常重要。
- 广泛的应用:VGG不仅是图像分类的强大工具,也被广泛应用于目标检测、语义分割等多个视觉任务中。
缺点:
- 计算成本高:特别是VGG16和VGG19,由于层数较多且全连接层的参数量巨大,导致计算资源消耗大,训练和推理速度相对较慢。
- 内存占用大:大量的参数意味着模型在训练和部署时需要更多的内存空间。
- 过拟合风险:因为参数量庞大,在小规模数据集上容易发生过拟合现象。
总的来说,尽管VGG网络在参数量和计算效率方面存在一些不足,但它凭借其简单有效的设计和强大的特征提取能力,仍然是计算机视觉领域中一个重要的基础模型。

















 7374
7374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









