







目录
本文结合课堂学习内容和一篇CNN综述文章(参考文献3)对CNN进行了总结,包括其卷积运算、各种操作、参数计算,以及文献3中所详述的CNN结构的演化史,最后对1998年发表的经典网络LeNet的每一层进行了简要分析。
1 CNN引出
全连接网络对于处理图片数据集会有如下问题:
- 在节点数量很大时,参数的个数非常多,计算速度慢
- 权值过多容易产生过拟合
- 将二维图像信息“压扁”(flatten)为一维向量损失了图像的空间信息
为了解决上述问题,一方面需要减少权值的数量,采用局部连接网络,另一方面增加网络的层数,每一层在上层提取特征的基础上进行再处理,得到更高级别的特征。本文介绍卷积神经网络(Convolutional neural network,CNN),这种网络的参数数量少于全连接架构网络,而且计算高效。
2 CNN基础
2.1 卷积
(1)卷积和互相关运算
数学中卷积的定义为
在物理上,自变量一般为时间,因此积分区域变成,即
若将g看做一个线性定常系统的冲激响应h(t),f看做系统的输入u(t),则这两个函数的卷积就是系统在t时刻的输出y:
该式表明t时刻的输出与t时刻之前的所有输入都有关系。
我们将卷积公式离散后,设自变量在整数集里取值,则变为
进一步,考虑二维情形,则有
如果将这个定义应用在图像上,设图像X大小为n*n,用一个大小为k*k(n>k)的——称为卷积核对其进行卷积操作,分别对应上式中的f和g,f是X中和卷积核重叠的区域。
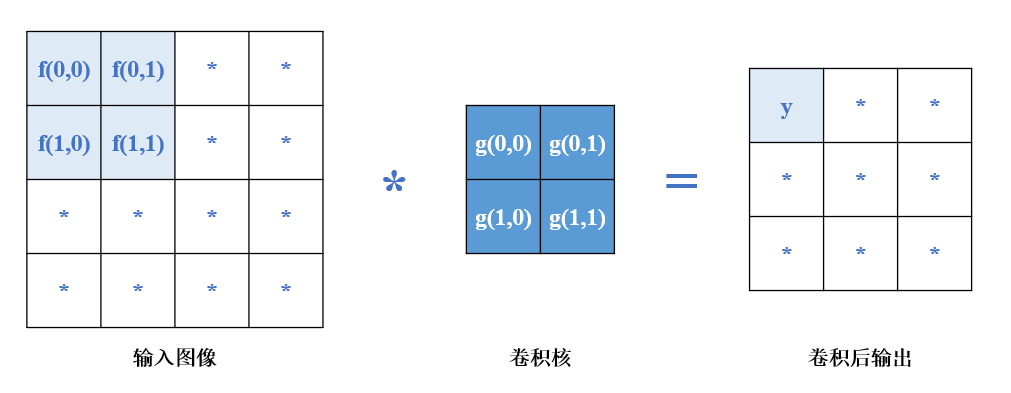
按照上述卷积定义,则有
可以看出卷积操作是把卷积核旋转180°后和f进行加权求和操作。(输出为(f*g)(1,1)是由前面一维以时间为自变量进行类比得出)
而卷积神经网络中使用的“卷积”计算为直接把卷积核对f进行加权求和。用公式表达为
上述运算实际为互相关运算,而非卷积运算,因为卷积运算要把卷积核旋转180°再做互相关运算。但仍然称其为卷积运算,因为无论卷积核旋不旋转,它的参数是通过后续学习来的,本质上没有区别。
(2) 卷积后的大小
设输入大小为,卷积核大小为
,则输出大小(默认步长为1)为
(3) 填充保持卷积前后大小不变
填充行
列后输出大小为
为了填充后保持输出和输入大小相同,需。
(4) 不同步长卷积后的大小
当取不同的步长时,得到不同大小的输出,设步长为s,则输出大小(以下都认为高和宽相等)为
(5)多输入多输出通道
- 对于多输入通道,卷积核的通道数和输入通道数相同,在每一个通道上进行互相关运算后,把所有通道的值加起来就是输出的值。
- 对于多输出通道,各个通道分开独立进行计算,不同通道采用不同的卷积核。
(6) 特征映射和感受野
- 输出的卷积层称为特征映射(feature map)。
- 感受野(receptive field,RF):某一层的某个神经元受多少输入(即原始图像的哪一块区域)的影响。可以采用由后向前的方式计算:即该神经元前一层对该神经元有影响的个数为卷积核的大小,然后依次往后算,直到计算到原始的图像上。
2.2 池化(polling)
(1)最大池化:即选择池化窗口中的最大值作为输出
(2) 平均池化:即选择池化窗口中的平均值作为输出
池化的意义:
- 池化操作可以减少数据的空间尺寸,即降低宽度、高度或通道数。这种降维有助于减少后续层中的参数数量,从而减少计算量和防止过拟合。通过减少数据的维度,网络可以更加高效地处理信息,同时仍然保持对关键特征的敏感性。
- 由于池化减少了数据的空间尺寸,它有助于网络对输入数据中的小的变化和扰动保持不变性。这种不变性使得模型在面对新的、未见过的数据时,仍然能够有效地识别和处理,从而增强了模型的泛化能力。
- ……
2.3 参数和连接数计算
为了评价网络的性能,我们需要知道网络中的参数个数。
假设输入图像是20*20的RGB图像,经过一次卷积核为3*3的卷积运算后得到6个特征映射(即输出的通道数为6),那么对于一个通道来说共有参数3*3*3+1=28个,最后的3是因为输入通道为3,1为偏置,则6个通道共有6*28=168个参数。

全连接的参数个数和连接数相同(将偏置也认为是一个连接),为了将CNN和全连接的参数个数进行比较,我们同样计算上述网络中的连接个数:一个通道中,输出的每个神经元对应3*3*3+1=28个连接,共有18*18个神经元,因此共有18*18*28*6=54432个连接。
可见由于卷积核的权值共享(weight sharing),大大减少了参数的个数。
此外,介绍一个衡量模型计算复杂度的指标,即FLOPs(Floating Point Operations Per Second),每秒浮点运算次数。估算CNN中的FLOPs可以帮助我们理解模型的运算量,从而对模型的效率和性能进行评估。
3 CNN发展历史
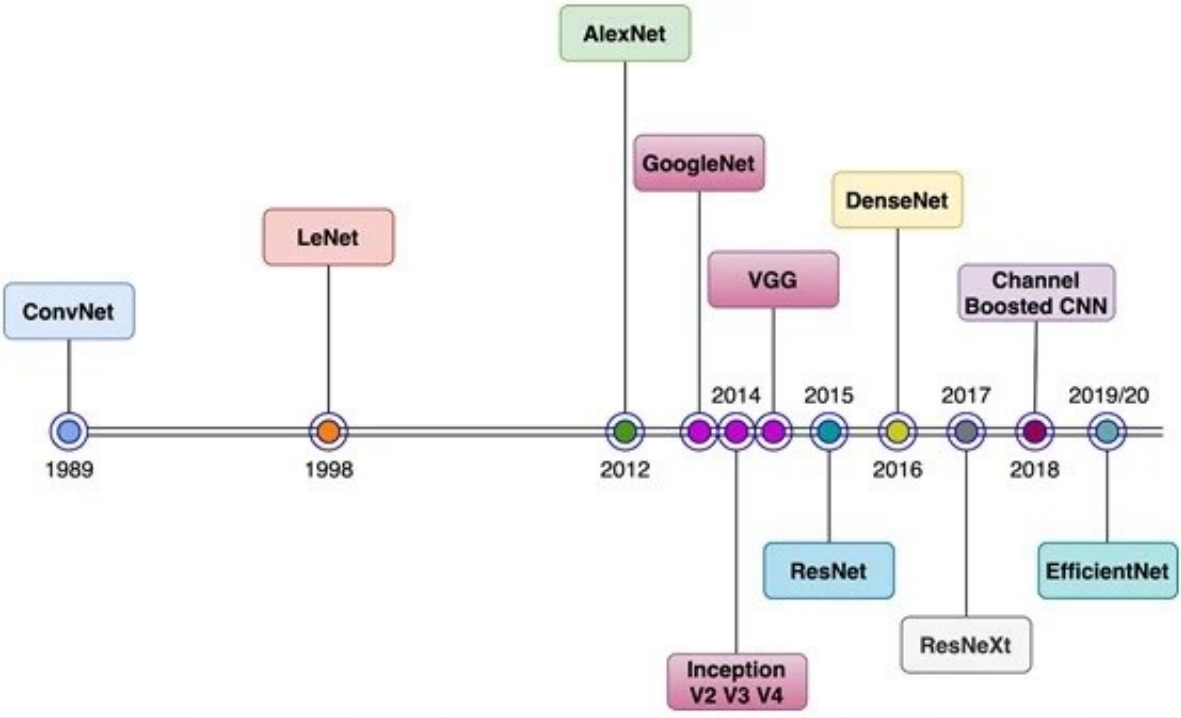
3.1 CNN的起源:1980年代末-1999
上世纪60年代左右,加拿大神经科学家Hubel和Wiesel于1959年提出猫的初级视皮层中单个神经元的感受野概念,紧接着于1962年发现了猫的视觉中枢里存在感受野、双目视觉和其他功能结构,标志着神经网络结构首次在大脑视觉系统中被发现。
1980年前后,日本科学家福岛邦彦(Kunihiko Fukushima)在Hubel和Wiesel工作的基础上,模拟生物视觉系统并提出了一种层级化的多层人工神经网络,即“神经认知”(neurocognitron),以处理手写字符识别和其他模式识别任务。神经认知模型在后来也被认为是现今卷积神经网络的前身。
CNN是上世纪80年代末应用在视觉任务当中的。1989年,LeCun等人基于Fukishima的神经认知提出了第一个多层CNN并命名为ConvNet,其中采用了BP算法进行监督学习,成功应用在手写数字和邮政编码的识别等相关问题上。
在1998年,LeCun又提出了ConvNet的改进版,即著名的LeNet-5,开启了CNN在文档识别中特征分类的应用。在当时的视觉符号识别任务中取得了很多里程碑式的成功,但是在其他图像识别问题中表现得不是很好。
3.2 CNN的停滞:2000初
在90年代末到2000年初,研究者对于CNN内部是如何工作的难以理解,认为它是一个“黑盒子”,复杂的构架设计和繁重的处理使得CNN训练非常困难。在2000年初人们普遍认为训练CNN用的BP算法难以有效地收敛到误差面的全局最小值,因此,由于以高计算时间为代价的CNN性能提升并不显著,因此很少有人关注其在不同应用中的作用,如目标检测、视频监控等。同一时期,另外一些统计学方法尤其是SVM由于其相对高的性能受到人们的青睐。
3.3 CNN的复兴:2006-2011
2000年初,用于深度网络训练的并行处理技术很少,硬件资源有限。从2006年开始,攻克CNN优化问题上开始有了重要的进展。一些初始化和训练策略被提出来,Hinton于2006年提出了贪婪分层预训练概念,实验表明无论是有监督的预训练还是无监督预训练,这种方法都可以比随机初始化更有效地初始化一个网络。Bengio和其他研究者发现sigmoid激活函数并不适用于随机初始化的深度结构的训练,于是人们开始寻找其他的激活函数例如ReLu、tanh等等。2007年Ranzato等人使用最大池化代替了下采样,通过学习不变特征显示出很好的效果。2006年末,研究人员开始使用图形化处理单元(GPU)来加速深度神经网络和CNN架构的训练。2007年,NVIDA推出了CUDA编程平台,允许更大程度地利用GPU的并行处理能力。
2010年,斯坦福大学的李飞飞(Fei-Fei Li)团队建立了一个名为ImageNet的大型图像数据库,其中包含了数百万张属于大量类别的带注释的图像。该数据库与年度ImageNet大规模视觉识别挑战(ILSVRC)结合起来,对各种模型的性能进行了评估和评分。
3.4 CNN的崛起:2012-2014
广泛训练数据的可用性和硬件方面的进步是促成CNN研究进步的因素。但是真正加速了CNN在图像分类和识别中的应用研究的驱动力是参数优化策略和新的架构思路。带来CNN性能关键突破的就是AlexNet,它在2012年的ILSVRC(即上述ImageNet Large Scale Visual Recognition Challenge)中展现出优异的性能(错误率从25.8降到16.4)。
这一时期所做的对CNN性能提升的尝试为深度和参数优化策略。同时不同的架构设计也被提了出来,都在尝试克服以前构架的不足。随着设计深度CNN的趋势,通常很难独立确定每个层的过滤器尺寸、步长、填充和其他超参数。这个问题可以通过设计具有固定拓扑的卷积层来解决,该拓扑可以重复多次。这就将趋势从自定义层设计转向模块化和统一层设计。CNN中模块化的概念使其毫不费力地去完成不同的任务。在这方面,Google小组引入了层内分支和块的不同想法。
3.5 CNN构架的创新和应用的快速增长:2015至今
很容易发现CNN性能的极大提升发生在2015~2019年。不同的实验研究表明,非常先进的深度构架VGG、ResNet、ResNext等架构在语义和基于实例的对象分割、场景解析、场景定位等具有挑战性的识别和定位问题上也显示出良好的效果。
许多现实世界的应用程序,如自动驾驶汽车、机器人、医疗保健和移动应用程序,都需要在计算有限的平台上及时执行需要执行的任务。因此要对CNN进行不同修改使它们适用于资源受限的环境,其中非常突出的修改是知识蒸馏(knowledge distillation),小网络的训练,或预训练网络的压缩(如修剪,量化,哈希,霍夫曼编码等)。GoogleNet利用了小网络的思想,用逐点群卷积运算取代了传统的卷积运算,提高了计算效率。类似地,ShuffleNet使用逐点分组卷积,但采用了通道洗牌(channel shuffle)的新思想,在不影响准确性的情况下显著减少了操作次数。ANTNet以同样的方式提出了一种新的体系结构块——ANTBlock,以较低的计算成本在基准数据集上取得了良好的性能。
从2012年到现在,CNN架构已经有了很多改进。关于CNN的架构改进,最近的研究重点是设计新的块,利用特征图或通过添加人工通道来操纵输入表示,进而增强网络表示。与此同时,在不影响性能的情况下设计轻量级架构,使CNN适用于资源受限的硬件是大势所趋。
4 LeNet简要分析
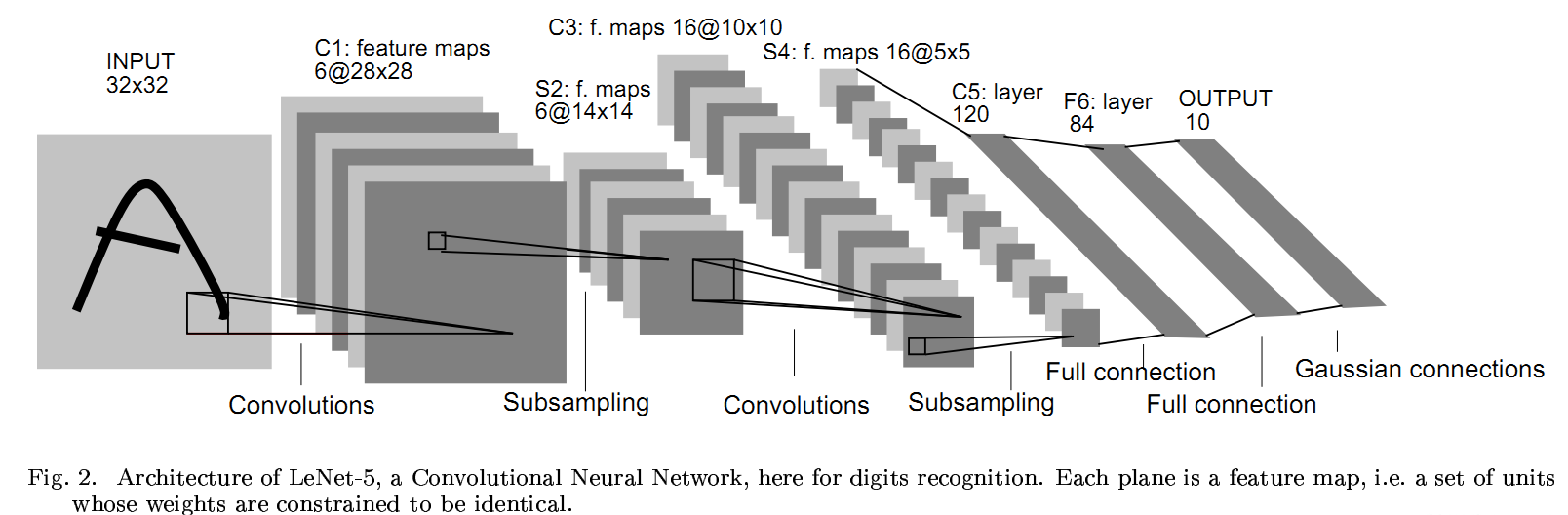
Cx表示卷积层(convolutional layers),Sx表示下采样层(subsampling layers),Fx为全连接层(fully connected layers)
- 输入层:32*32 居中的数字图像
- C1层:6个feature map,卷积核为5*5,参数个数为(5*5+1)*6=156个,连接数为156*28*28=122304个
- S2层:池化层,用大小为2*2的过滤器,采用平均池化(求和后乘以一个可训练系数再加上一个可训练偏置,并通过sigmoid函数传递),降低了特征图的分辨率,减少了输出对移位和失真的灵敏度。该层有2*6=12个参数(即上述乘的系数和偏置),连接数为(2*2+1)*(14*14)*6=5880个连接数
- C3层:卷积层,16个feature map,5*5卷积核,C3层每个feature map并没有连接全部的S2的feature map,一是将连接数保持在合理范围内,二是迫使网络中的对称性被打破,不同的feature map被迫提取不同的特征。不同通道连接的S2层通道的情况如下表所示。C3层共有6*(5*5*3+1)+9*(5*5*4+1)+1*(5*5*6+1)=1516个参数,共有(6*(5*5*3+3)+9*(5*5*4+4)+1*(5*5*6+6))*(10*10)=156000个连接数。

- S4层:池化层,用2*2窗口,参数个数为2*16=32,连接数为(4+1)*5*5*16=2000个
- C5层:对输入(S4)的全部通道上(16个)进行5*5卷积,由于输入也是5*5,因此输出的feature map大小为1*1,共120个feature map,因此共有120个神经元,与S4是全连接,连接数等于参数数,为(5*5*16+1)*120=48120个
- F6层:含有84个神经元(取这个数字的原因来自输出层的设计),并完全连接到C5,有(120+1)*84=10164个参数。
- 输出层:10个,连接数为840个
LeNet总结:
- 卷积时不进行填充
- 池化用平均池化
- 选用sigmoid或tanh而非ReLu作为非线性激活函数
- 层数较浅,参数数量小(参数个数为60 000,连接数为345 308)
参考文献
1 神经网络中感受野的计算_神经网络感受野计算-CSDN博客
3 Khan, A. et al. (2020) ‘A survey of the recent architectures of deep convolutional neural networks’, Artificial Intelligence Review: An International Science and Engineering Journal, 53(8), pp. 5455–5516. doi:10.1007/s10462-020-09825-6.
4 LeCun Y,Bottou L,Bengio Y,Haffner P(1998)Gradient-based learning applied to document recognition.Proc IEEE 86:2278-2324















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









