







目录
1 全连接层误差反向传播
以简单的2层全连接层网络(即单隐藏层的多层感知机)为例分析误差反传算法。
1.1 网络模型
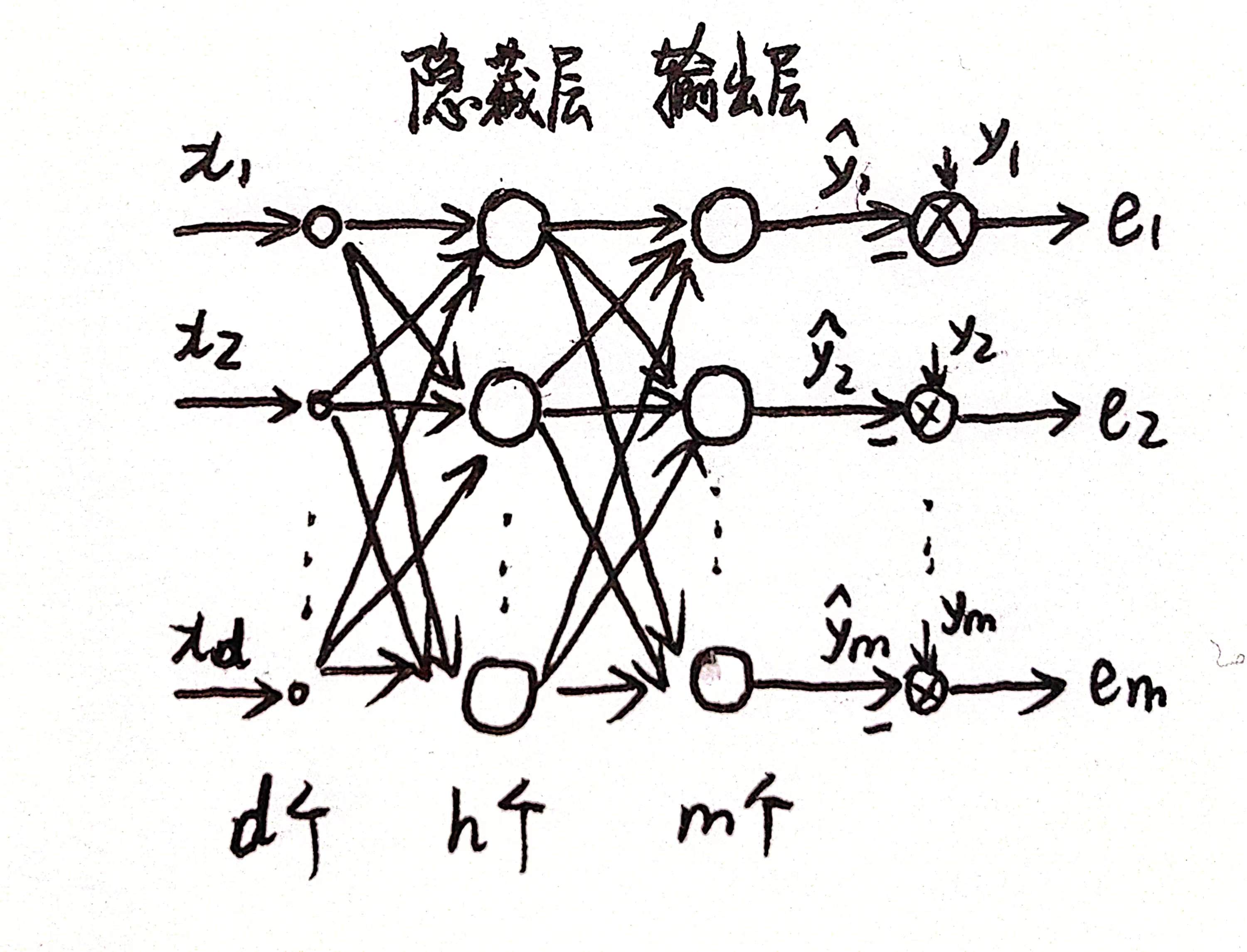
记号解释
上标表示层数,输入层为第0层,隐藏层为第1层。a表示神经元的输出,z表示神经元的线性输出,为了理解起见暂不采用向量表示。
为
层的第
个神经元的输出,
为
层的第
个神经元的线性输出,满足
其中,为第
层第
个神经元和前一层第
个神经元的连接权值(包含了偏置项),
采为sigmoid函数,其导数为
1.2 前向传播
前向传播即输入经过隐藏层到输出层的传播。
目标函数为
1.3 误差反传
1.3.1 输出层权值更新
输出层神经元的权值只影响了该神经元的输出,因此以输出层第个神经元和前一层第
个神经元的连接权值更新为例,有
令
里含有误差
,因此可以认为误差
反传给第2层(即输出层)的量就是
。
则权值的更新公式为
由于单个神经元的Hebb规则是权值的调整量和输入输出的乘积成正比,对于权值,可以认为输入为
,输出为
。
1.3.2 隐藏层权值更新
对于隐藏层的权值来说,某个权值首先传到该隐藏层神经元的输出,然而该输出接下来会传到输出层的每个神经元的输出里,因此较为复杂,但本质也是多元函数求偏导数的链式求导法则:

令
里含有误差
,因此可以认为误差
反传到第1层(即隐藏层)的量就是
,为了后续表达方便,下文中称
为每一层的误差。
则权值的更新公式为
总结:
- 当前层误差为下一层误差的加权和再乘以当前层激活函数的导数。
- 当前层连接权值的更新调整量与当前层误差有关。
2 卷积神经网络误差反向传播
在卷积神经网络(CNN)中,同样有前向传播和反向传播,为将不同BP算法的思路进行整理,下面对CNN的BP算法进行简要介绍。对于CNN的详细介绍将在后续文章中给出。
2.1 池化层误差反向传播
卷积神经网络的基本结构是输入层-卷积层-池化层-全连接层,一般卷积层和池化层以组合的形式出现,可以有多个这样的组合。误差从输出进行反传时,首先传入全连接层,而全连接层的误差反传算法已在前面介绍过了,假定误差已经传到池化层,池化层没有参数学习,只需考虑误差的反向传播即可,即池化层前一层(一般是卷积层)的误差是多少。
基本思路是将卷积层和池化层(二维)转化为我们熟悉的神经网络结构形式,即将二维的层“压扁”成为单个神经元构成的层,两层之间的权重由池化方法决定,若是最大池化,则连接权值仅由0和1组成,若是平均池化,则连接权值是1/(池化窗口包含神经元的个数)。
然后利用全连接层所得出的结论得到卷积层的误差(加权和乘以激活函数的导数)。
2.2 卷积层误差反向传播
卷积层包含参数的更新和误差的反向传播,参数的更新与当前层(卷积层)的误差有关,而其误差反传是求得其前一层(若为输入层则不用继续反传了)的误差。
和池化层思路类似,也是将卷积操作转化为普通神经网络连接形式,连接权值由卷积核决定。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









