







Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
会议:ICCV
时间:2017年
本论文对CAM进行改进,解决了CAM必须添加GAP层,并重新训练等问题,提出Gradient-weighted Class Activation Mapping(Grad-CAM)。
1.Introduction
神经网络在多种计算机视觉任务中取得许多令人印象深刻的结果,但由于其不同于决策树等算法,缺少可分解的能力,因此难以对其行为进行解释。
一般来说,神经网络的透明度(或可解释性)在人工智能(AI)进化的三个不同阶段均具有十分重要的作用。起初,当人工智能的判别性明显弱于人类并无法可靠的部署时(例如视觉问答),这种透明度和可解释的目标就是识别网络失效的原因,从而帮助研究人员对模型进行优化。其次,当人工智能与人类相当并且可靠地部署时(例如,在一组基于足够数据训练的类别上进行图像分类),此时目标是在用户中建立适当的信任和信心。而当AI的性能明显强于人类时(例如在国际象棋和围棋),可解释的目标是machine teaching,即机器教人类如何做出更好的决策。
Zhou等人最近提出的CAM算法能通过在没有任何全连接层的CNN上,有效地识别图像分类任务的判别区域(discriminative region)。从本质上讲,CAM在模型复杂性和性能上进行了权衡,从而使模型的工作更加透明。但相比之下,本文提出的算法没有对模型进行改进,从而无需对可解释性和准确率进行权衡。本文提出的方法是对CAM的推广,适用于更广泛的CNN模型,如带全连接层的CNN,用于结构化输出的CNN(captioning看图写文字描述),强化学习,多模态模型等。
**What makes a good visual explanation?**此外,本文对什么是好的视觉可解释性进行了讨论,认为一个好的可解释模型需要包括类别判别性class-discriminative(例如目标位置和图像所属类别)和高分辨率high-resolution以捕捉细粒度的细节。
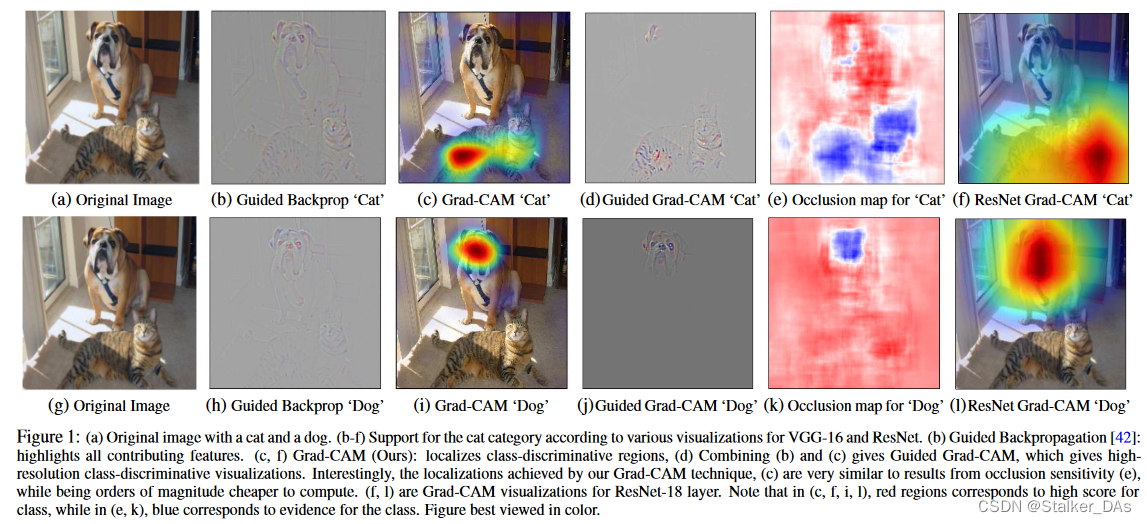
上图展示了分别对狗和猫进行可视化的结果,像素空间梯度可视化方法如Guided Backpropagation[1]和Deconvolution[2],可以突出图像中的细粒度细节,但不能区分类别,如图b和图h十分相似。相比之下,CAM和我们的方法具有很高的类别判别性如图c和图i。为了结合二者的优点,本文将现有的像素空间梯度可视化与Grad-CAM融合在一起,创建同时具有高分辨率和类别区分性的Guided Grad-CAM,结果如图d与图j所示。
本文的主要贡献总结为以下4点:
- 提出Grad-CAM,一种分类判别定位技术,可以从任何基于CNN的网络生成视觉解释,而无需更改架构或重新训练。
- 将Grad-CAM与现有表现最好的分类、VQA等模型进行融合,并通过实验证明其有效性。
- 在图像分类任务和VQA任务上对ResNets进行可视化,从深层到浅层,当遇到不同输出维数的层时,Grad-CAM的判别能力显著降低。
- 通过实验证明,Grad-CAM不仅可以帮助人类建立信任(establish trust),还可以帮助未经训练的用户成功地从“较弱”的网络中区分出“较强”的网络,即使两者做出相同的预测。
2.Related Work
一些方法通过强调像素的重要性来可视化CNN[1,2,3],尽管这些方法可以生成细粒度的可视化方法,但这些方法没有类判别能力,就如上图b和h所示。其他可视化方法合成图像以最大限度地激活网络单元[3,4]或反转潜在表示[5,6]。尽管这些方法同时具有高分辨率和类判别性,但他们将整个模型可视化,而不是对特定输入图像进行预测。(比如3方法就是通过梯度下降求某神经元激活最大的图像)
3.Approach
许多先前的工作都已经证明,更深层次的CNN卷积神经网络会捕捉更高级别的视觉结构或高级语义信息,比如浅层神经网络可能会捕捉一些底层特征比如颜色转角斑块等,而中层网络会提取条纹、纹理等更高级别的特征,而高级神经网络会提取眼睛、鼻子等高级别抽象的语义特征。而由于卷积层能一定程度的保留长宽方向的位置信息,而全连接层会破坏此外置信息,因此这里使用一个折中的方法,使用最后一层卷积层的结果,这样既保留了高层语义信息,同时又有空间长宽方向的信息。这里最后一层卷积层的每个通道都捕捉了某些语义的特征,本文提出的Grad-CAM则是使用梯度信息计算每个Channel的权重,最后合成图像。
整个网络结构如下图所示:
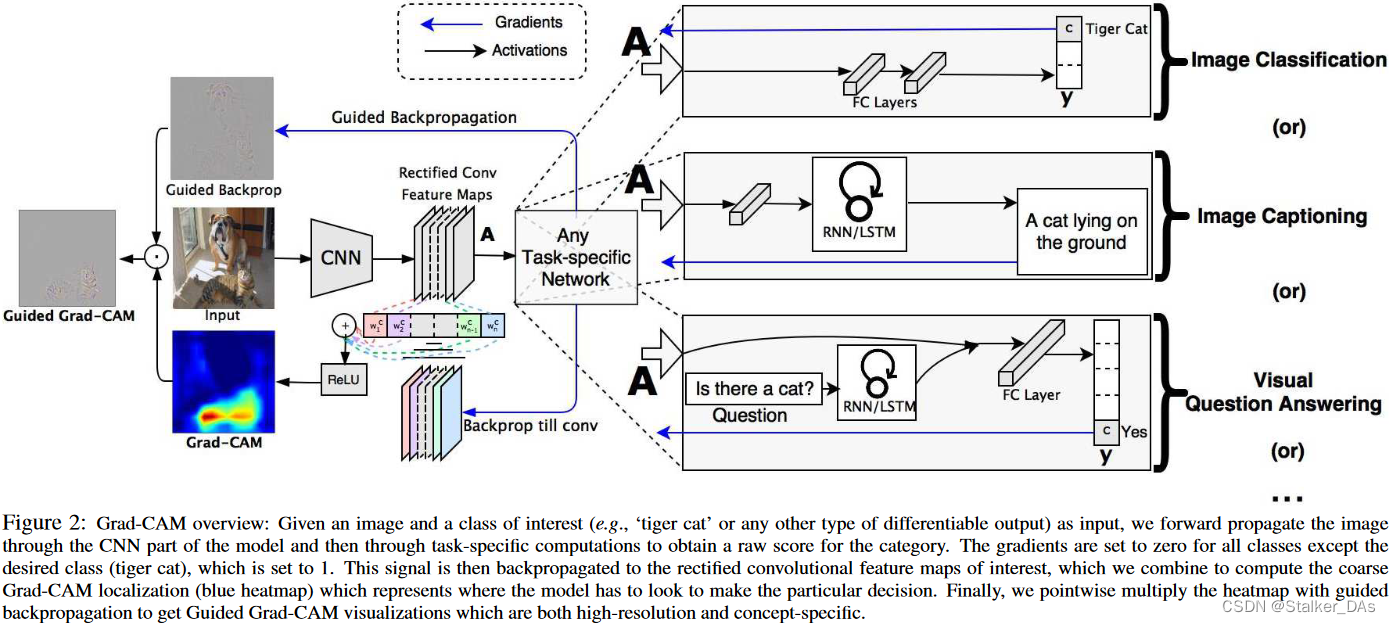
为了得到能够对类进行区分的位置图Grad-CAM
L
G
r
a
d
−
C
A
M
c
∈
R
u
×
v
L^c_{Grad-CAM} \in \mathbb{R}^{u \times v}
LGrad−CAMc∈Ru×v,其中
u
u
u和
v
v
v为宽和高(也就是最后一层输出512x14x14的最后两个维度),
c
c
c为类别。首先计算类
c
c
c的分数
y
c
y^c
yc,注意这个分数是在softmax之前的。之后求分数
y
c
y^c
yc相对于最后一个卷积层输出特征图
A
k
A^k
Ak每个元素的偏导数即
∂
y
c
∂
A
k
\frac{\partial y^c}{\partial A^k}
∂Ak∂yc。之后对这个偏导数进行全局平均池化,以得到最终每个channel的权重:
α k c = 1 Z ∑ i ∑ j ⏞ global average pooling ∂ y c ∂ A i j k ⏟ gradients via backprop \alpha_{k}^{c}=\overbrace{\frac{1}{Z} \sum_{i} \sum_{j}}^{\text {global average pooling }}\underbrace{\frac{\partial y^{c}}{\partial A_{i j}^{k}}}_{\text {gradients via backprop }} αkc=Z1i∑j∑ global average pooling gradients via backprop ∂Aijk∂yc
这里 Z Z Z没有给出具体值,我感觉可以是像素的数量,即14x14。权重 α k c \alpha_{k}^{c} αkc表示特征图 k k k对预测为 c c c类别的重要程度。
之后根据上述权重对k个channel的特征图进行加权求和,并通过 R e L U ReLU ReLU激活函数,得到Grad-CAM
L Grad-CAM c = ReLU ( ∑ k α k c A k ) ⏟ linear combination L_{\text {Grad-CAM }}^{c}=\operatorname{ReLU} \underbrace{\left(\sum_{k} \alpha_{k}^{c} A^{k}\right)}_{\text {linear combination }} LGrad-CAM c=ReLUlinear combination (k∑αkcAk)
这里使用ReLU激活函数的主要原因是过滤无关特征。而且后面要与Guided Backprop进行乘法逐元素相乘,有0会让一些无关位置的像素直接过滤。实验证明,如果没有这个ReLU,位置图有时会突出显示更多所需的类,从而降低定位的性能。
Grad-CAM as a generalization to CAM.
这里通过数学公式推导,证明了Grad-CAM是CAM的一般情况。
回顾CAM的结构,CAM包括一个全连接的卷积神经网络,后面跟着一个global average pooling、一个线性分类层和softmax函数。假设最后一个卷积层输出 K K K个特征图 A k A^k Ak,其中每个元素的索引用i,j表示。因此 A i , j k A^k_{i,j} Ai,jk就表示特征图 A k A^k Ak中(i,j)位置的激活。CAM计算需要对 A i , j k A^k_{i,j} Ai,jk计算全局池化,这里定义全局池化的输出为 F k F^k Fk,公式如下:
F k = 1 Z ∑ i ∑ j A i j k F^k=\frac{1}{Z}\sum_i\sum_jA_{ij}^k Fk=Z1i∑j∑Aijk
而CAM中计算最后分数的公式如下:
Y c = ∑ k w k c ⋅ F k Y^c=\sum_kw_k^c\cdot F^k Yc=k∑wkc⋅Fk
其中 w k c w^c_k wkc为第 k k k个特征图和第 c c c个类别的关系,也可认为是权重。
取类别 c c c的分数( Y c Y^c Yc)对特征图 F k F^k Fk的梯度,可以得到:
(
From Chain Rule
)
∂
Y
c
∂
F
k
=
∂
Y
c
∂
A
i
j
k
∂
F
k
∂
A
i
j
k
(\text{From Chain Rule})\frac{\partial Y^c}{\partial F^k}=\frac{\frac{\partial Y^c}{\partial A_{ij}^k}}{\frac{\partial F^k}{\partial A_{ij}^k}}
(From Chain Rule)∂Fk∂Yc=∂Aijk∂Fk∂Aijk∂Yc
根据上面的式子,我们可以知道
∂
F
k
∂
A
i
j
k
=
1
Z
\frac{\partial F^k}{\partial A_{ij}^k}=\frac{1}{Z}
∂Aijk∂Fk=Z1(这里除了
A
i
,
j
k
A^k_{i,j}
Ai,jk外都是常数),带入后可以得到:
∂ Y c ∂ F k = ∂ Y c ∂ A i j k ⋅ Z \frac{\partial Y^c}{\partial F^k}=\frac{\partial Y^c}{\partial A_{ij}^k}\cdot Z ∂Fk∂Yc=∂Aijk∂Yc⋅Z
从第二个公式中我们可以知道 ∂ Y c ∂ F k = w k c \frac{\partial Y^{c}}{\partial F^{k}}=w_{k}^{c} ∂Fk∂Yc=wkc,因此
w k c = Z ⋅ ∂ Y c ∂ A i j k w_k^c=Z\cdot\frac{\partial Y^c}{\partial A_{ij}^k} wkc=Z⋅∂Aijk∂Yc
现在我们将等式两端同时加上全部的元素(i,j),可以得到:
∑ i ∑ j w k c = ∑ i ∑ j Z ⋅ ∂ Y c ∂ A i j k \sum_i\sum_jw_k^c=\sum_i\sum_jZ\cdot\frac{\partial Y^c}{\partial A_{ij}^k} i∑j∑wkc=i∑j∑Z⋅∂Aijk∂Yc
还可以进一步写成:
Z w k c = Z ∑ i ∑ j ∂ Y c ∂ A i j k Zw_k^c=Z\sum_i\sum_j\frac{\partial Y^c}{\partial A_{ij}^k} Zwkc=Zi∑j∑∂Aijk∂Yc
两边同时约去常数 Z Z Z,得到:
w
k
c
=
∑
i
∑
j
∂
Y
c
∂
A
i
j
k
w_k^c=\sum_i\sum_j\frac{\partial Y^c}{\partial A_{ij}^k}
wkc=i∑j∑∂Aijk∂Yc
可以看到这里
w
k
c
w^c_k
wkc与Grad-CAM中的
α
k
c
\alpha^c_k
αkc一致,因此,Grad-CAM是CAM对任意基于CNN的体系结构的推广,同时保持了CAM的计算效率。
Guided Grad-CAM. 尽管Grad-CAM具有很强的类判别性和定位效果,但其缺乏像像素空间梯度可视化方法(如Guided Backpropagation和Deconvolution等)那样显示细粒度重要性的能力,因此这里将Grad-CAM得到的图像使用双线性插值进行上采样,并与Guided Backpropagation产生的图像逐像素点乘,结果如图1d和j所示,这种图像同时兼顾高分辨率(当感兴趣的类别是“虎猫”时,它会识别出重要的“虎猫”特征,比如条纹、尖耳朵和眼睛)和类别判别性(它显示了“虎猫”,而不是“拳师(狗)”)。这里还讨论了为什么使用Guided Backpropagation而不是Deconvolution,因为在实验过程中发现,Deconvolution产生的图像有许多伪影,而Guided Backpropagation可视化后的效果通常具有更少的噪声,因此这里选择前者。
4.Evaluating Localization
4.1Weakly-supervised Localization
这里在构建Box时使用的方法与CAM相同,均为选取一定数量(前15%)最大荧光强度?(总之就是最亮部分)的像素构成连通块,之后根据连通块构建Box,将全部像素囊括在内。与多种方法对比的实验结果如下所示
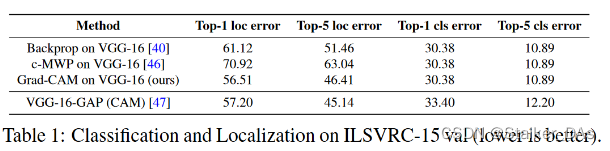
本方法在ILSVRC-15任务中取得了最好的结果,虽然在top-5准确率略低于CAM,但由于CAM需要对模型本身进行修改,其在分类准确率上要明显差于Grad-CAM。
5.Evaluating Visualizations
5.1. Evaluating Class Discrimination
本节的主要目的是验证Grad-CAM能够有效增加类别区分度。本实验在VOC2017的验证集上进行,通过Amazon Mechanical Turk (AMT)亚马逊土耳其机器人寻找43位参与者,并询问可视化后的图像描述了两种对象类别中的哪一种,如下图所示:

实验采用所有4种可视化方法(Deconvolution, Guided Backpropagation和Grad-CAM加前面两种方法)对90个图像类别对进行对比,实验结果表明,在Guided Backpropagation方法上,使用Grad-CAM会提升16.79%识别准确率,而在Deconvolution上准确率则是从53.33%提升至61.23%。有趣的是,本文结果表明,尽管Guided Backpropagation的方法比Deconvolution更加美观,但后者具有更高的判别性。
5.2. Evaluating Trust
本节主要通过调查问卷的方式,对两种准确率几乎相同的模型进行可视化解释,以说明哪个模型更加可靠。这里对VGG-16和AlexNet进行对比,其中VGG-16在PASCAL分类任务上的mAP为79.09,而AlexNet为69.20。为了将可视化的有效性与被可视化的模型的准确性区分开来,这里只考虑两个模型都做出相同预测的图像。实验过程如上图右侧所示,54个被测试者根据clearly more/less reliable (+/-2), slightly more/less reliable (+/-1), and equally reliable (0),规则进行打分。实验结果显示,在Guided Backpropagation下,VGG的平均分数为1.00,这意味着它比AlexNet从人类视角来看更可靠,而Guided Grad-CAM中,VGG分数达到1.27,这同样能证明上述问题。因此,本文提出的可视化方法可以帮助用户信任一个可以更好地泛化的模型,仅仅基于个人预测解释。
5.3. Faithfulness vs. Interpretability
本节对可解释性模型即Grad-CAM本身的可信度进行讨论,这里Faithfulness指可信度。
“可解释性”(interpretability)和"忠实性"(faithfulness)都涉及到对模型的解释和理解,但它们强调的方面略有不同:
- 可解释性(interpretability):指的是可视化结果或模型的解释是否易于被人理解和解释。一个可解释性强的模型或可视化结果能够以直观的方式传达模型的决策逻辑、特征提取和工作原理,使非专业人员也能够理解。可解释性强的模型更易于被应用于实际场景,并且能够帮助人们对模型做出信任和决策。
- 忠实性(faithfulness):指的是可视化结果或解释对模型学习到的函数是否准确进行了解释。一个忠实的可视化结果能够真实地反映模型在输入数据上的决策和特征学习过程,它与模型的行为高度一致。忠实性强的解释可以帮助研究人员了解模型的内部运作,发现模型的强项和弱项,以及对模型的改进和优化提供指导。
在可视化和解释深度学习模型时,可解释性和忠实性之间常常存在一种权衡关系。有时,为了提高可解释性,我们可能需要对模型的复杂性进行抽象或简化,以便更容易理解模型的工作原理。然而,过度简化可能会导致失去对模型行为的准确描述,降低忠实性。因此,研究人员在进行解释时需要综合考虑这两个因素,并根据具体需求和目标选择合适的解释方法和可视化技术。最终的目标是寻找既具有较高可解释性又具有较高忠实性的解释结果,以支持深度学习模型的应用和改进。
也就是faithfulness是对interpretability的解释,保证interpretability的可信度。
这里进行的实验为ZFNET中的滑块遮挡实验,用一个滑块将图中关注的部分遮挡,使模型预测其为该目标类别的可能性显著下降。之后再用Grad-CAM生成该图像的热力图,如果二者定位区域一致,则认为Grad-CAM算法是可信的。之后计算其秩相关性,实验结果发现,Grad-CAM和Guided Grad-CAM的秩相关要大于Guided Backpropagation,c-MWP等方法,这表明Grad-CAM 可视化更faithfulness。
6.Diagnosing image classification CNNs
6.1. Analyzing Failure Modes for VGG-16
本实验用于探讨分析为什么某些模型错误的将一些类识别为其他类别,通过可解释性可视化的方式寻找模型关注的区域,如下图所示:

6.2. Identifying bias in dataset
本节则是讨论如何用Grad-CAM识别并减少训练数据集中的偏差。在有偏见的数据集上训练的模型可能无法推广到现实世界的场景,或者更糟的是,可能会使偏见和刻板印象(例如性别、种族、年龄等)永久化。本实验通过VGG16模型对医生和护士进行分类,经过模型预测的Grad-CAM可视化显示,模型已经学会了通过观察人的脸/发型来区分护士和医生,从而学习了性别刻板印象,并错误地将几名女医生分类为护士,将几名男护士分类为医生。显然,这是存在问题的,因此通过检查数据集的结果发现,训练数据集中存在性别偏见(78%的医生图像是男性,93%的护士图像是女性)。
而消除此性别偏见的最好办法就是在训练数据集中增加男性护士的图像和女性医生的图像,同时保持每个类的图像数量与以前相同。重新训练后的模型可以更好地泛化测试集(达到90%准确率,以前为82%)。此实验表明,Grad-CAM可以帮助检测和消除数据集中的偏见,这不仅对泛化很重要,而且随着社会上越来越多的算法决策的产生,对公平和道德的结果也很重要。
7.Conclusion
在这项工作中,本文提出一种新的类别区分定位技术Grad-CAM,通过产生视觉解释使任何基于cnn的模型更加透明。此外,本文还将Grad-CAM定位与现有的高分辨率可视化相结合,以获得同时具有高分辨率和高类别判别性的Guided Grad-CAM。本方法在可解释性和可信度度上都要优于其他方法。此外,本工作还进行大量实验,如人类研究、信任度测试等,以证明有效性。
8.优点
- 无需GAP层,无需修改模型结构,无需重新训练
- 可分析任意中间层
- 数学上是原生CAM的推广
- 可用于细粒度图像分类、Machine Teaching
9.缺点
- 当图中存在多个同类物体时,只能画出一块热力图。
- 不同位置的梯度值,在GAP平均之后影响是相同的。
- 当梯度消失、梯度爆炸时会影响结果。
- 权重大的channel,不一定对类别预测分数贡献最大。
- 只考虑从后向前的反省传播梯度,没考虑前向预测的影响。
- 深层生成的粗粒度热力图和浅层生成的细粒度热力图都不够精确。(深层生成的图类别判别性强,但是是粗粒度的分辨率低只有14x14维度,而使用浅层网络生成的图像虽然分辨率高,但判别性比较弱)
参考文献
[1]. J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. A. Riedmiller. Striving for Simplicity: The All Convolutional Net. CoRR, abs/1412.6806, 2014. 2, 3
[2]. M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014. 2, 3, 6
[3]. K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. CoRR, abs/1312.6034, 2013. 3, 5
[4]. D. Erhan, Y. Bengio, A. Courville, and P. Vincent. Visualizing Higherlayer Features of a Deep Network. University of Montreal, 1341, 2009. 3
[5]. A. Mahendran and A. Vedaldi. Visualizing deep convolutional neural networks using natural pre-images. International Journal of Computer Vision, pages 1–23, 2016. 3
[6]. A. Dosovitskiy and T. Brox. Inverting Convolutional Networks with Convolutional Networks. In CVPR, 2015. 3
[7]. https://www.bilibili.com/video/BV1PD4y1B77q/?spm_id_from=333.788&vd_source=25d1a12ff92265ad29209fc06224b83d

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









