







包含全部示例的代码仓库见GIthub
1 导入库
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
2 数据准备
data1 = pd.DataFrame({'X':np.random.randint(1,50,100), 'Y':np.random.randint(1,50,100)})
data = pd.concat([data1+50, data1])
data
绘图
plt.style.use('ggplot')
plt.scatter(data.X, data.Y)
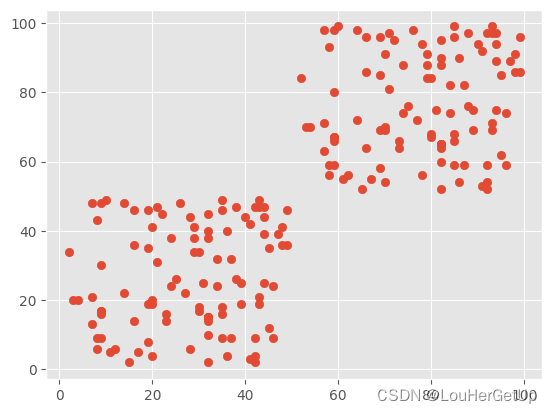
3 模型构建
y_pred = KMeans(n_clusters=2).fit_predict(data)
y_pred
# output
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0])
plt.scatter(data.X, data.Y, c=y_pred)
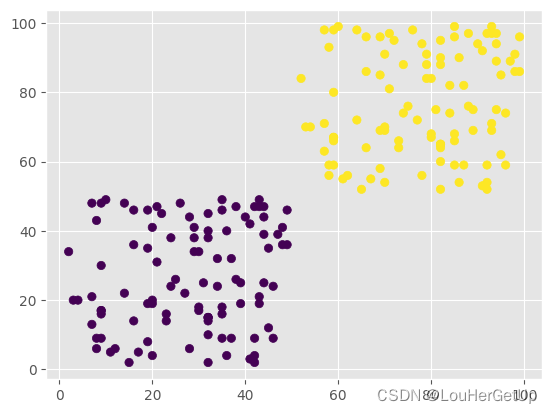
4 模型评价与改进
评价是否聚集
metrics.calinski_harabasz_score(data, y_pred) # 评价是否聚集,值越大效果越好
# output
626.3642402960996
y_pred = KMeans(n_clusters=3).fit_predict(data)
plt.scatter(data.X, data.Y, c=y_pred)
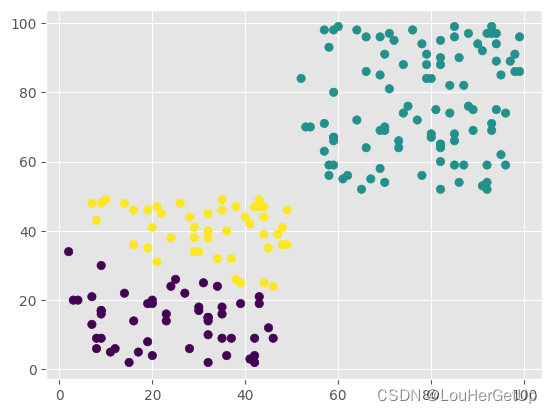
metrics.calinski_harabasz_score(data, y_pred)
# output
437.4815970504506
y_pred = KMeans(n_clusters=4).fit_predict(data)
metrics.calinski_harabasz_score(data, y_pred)
# output
447.54048271842913
改进后评价指标下降,说明应n_clusters=2
4 多变量情况
数据准备
# delim_whitespace=True 空格为分隔符
data = pd.read_csv('./dataset/seeds_dataset.txt',
header=None, delim_whitespace=True,
names=['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'y'])
data
# output
x1 x2 x3 x4 x5 x6 x7 y
0 15.26 14.84 0.8710 5.763 3.312 2.221 5.220 1
1 14.88 14.57 0.8811 5.554 3.333 1.018 4.956 1
2 14.29 14.09 0.9050 5.291 3.337 2.699 4.825 1
3 13.84 13.94 0.8955 5.324 3.379 2.259 4.805 1
4 16.14 14.99 0.9034 5.658 3.562 1.355 5.175 1
... ... ... ... ... ... ... ... ...
205 12.19 13.20 0.8783 5.137 2.981 3.631 4.870 3
206 11.23 12.88 0.8511 5.140 2.795 4.325 5.003 3
207 13.20 13.66 0.8883 5.236 3.232 8.315 5.056 3
208 11.84 13.21 0.8521 5.175 2.836 3.598 5.044 3
209 12.30 13.34 0.8684 5.243 2.974 5.637 5.063 3
模型构建
y_pred = KMeans(n_clusters=3).fit_predict(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']])
y_pre = pd.Series(y_pred)
y_pre = y_pre.map({0:1,1:3})
y_pre
# output
0 1.0
1 1.0
2 1.0
3 1.0
4 1.0
...
205 NaN
206 NaN
207 NaN
208 NaN
209 NaN
data.y
# output
0 1
1 1
2 1
3 1
4 1
..
205 3
206 3
207 3
208 3
209 3
评价
data_p = pd.DataFrame({'y_pre':y_pre, 'y':data.y})、
data_p['acc'] = data_p.y_pre==data_p.y
data_p.acc.sum()/len(data_p)
# output
0.2857142857142857
metrics.calinski_harabasz_score(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']], y_pred) # 评价
# output
375.8049613895007
y_pred = KMeans(n_clusters=4).fit_predict(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']])
metrics.calinski_harabasz_score(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']], y_pred) # 评价
# output
327.43909895952993
y_pred = KMeans(n_clusters=5).fit_predict(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']])
metrics.calinski_harabasz_score(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']], y_pred) # 评
# output
310.331839794128
















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











