






(1) 数据集构建,包括:利用词表将句子中的每个中文字符转换成id、对不在词汇表里面的字做出适当处理、在输入中加入句子的分隔符号、在起始位置加入占位符、小批量数据的组装及对齐。构建完成后打印一条mini-batch的数据进行验证。
我们依次使用如下几个函数实现数据集构建
words2id函数使用load_vocab函数加载词表,然后将每个词转换为其对应的id,并且在这个函数中如果一个词不在词表中,它会被转换为[UNK]标记的id。还有它在两个句子之间添加了[SEP]标记。
collate_fn函数则完成了将输入序列截断到指定的最大长度,并将所有序列填充到相同的长度。
load_vocab和load_dataset分别用于加载词表和加载数据
使用这些函数加载处理数据后输出一个批次,并打印出来即可

(2)实现输入编码、分段编码和位置编码,并组装为嵌入层,打印该层的输入输出。(3分)
self.token_embed = nn.Embedding(vocab_size, embed_dim),self.segment_embed = nn.Embedding(2, embed_dim),self.position_embed = nn.Embedding(max_seq_len, embed_dim)实现输入编码、分段编码和位置编码并在forward方法中,相加三种嵌入向量,得到最终的嵌入向量。

(3) 实现多头自注意力层和add&norm层。 (3分)
搭建了一个头自注意力层和add&norm层以便在之后的语义匹配模型中使用。
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.qkv_linear = nn.Linear(embed_dim, embed_dim * 3)
self.fc_out = nn.Linear(embed_dim, embed_dim)
def forward(self, value, key, query):
N = query.shape[0]
value_len, key_len, query_len = value.shape[1], key.shape[1], query.shape[1]
# Split the embedding dimension into heads
value = value.reshape(N, value_len, self.num_heads, self.head_dim)
key = key.reshape(N, key_len, self.num_heads, self.head_dim)
query = query.reshape(N, query_len, self.num_heads, self.head_dim)
# Compute scaled dot-product self-attention
energy = torch.einsum("nqhd,nkhd->nhqk", [query, key])
attention = torch.softmax(energy / (self.embed_dim ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, value]).reshape(N, query_len, self.embed_dim)
out = self.fc_out(out)
return out, attention # 返回输出和注意力权重
def get_attention_weights(self, value, key, query):
_, attention = self.forward(value, key, query)
return attention
(4) 搭建一个transformer编码器,利用嵌入层、transformer编码器和合适的分类器构建完成你的语义匹配模型,并说明你的模型组成,可画图说明。 (3分)
首先使用了嵌入层(函数Embedding Layer):这一层将输入的单词ID和段落ID转换为对应的嵌入向量。
在这之后使用Transformer编码器(函数Transformer Encoder):这一层对嵌入向量进行编码,得到每个单词的上下文表示。其中的TransformerBlock对象,包含了多头注意力机制和前馈神经网络。
最后使用分类器(函数Classifier)即可:这一层将Transformer编码器的输出转换为分类得分。使用了一个线性层,该层的输入维度为嵌入维度,输出维度为2,这样就可以预测语义是还是否了。
此外,根据第七题的我还添加了一个方法get_attention_weights,用于提取多头注意力权重。这个方法首先将输入的单词ID和段落ID转换为嵌入向量,然后调用Transformer编码器的get_attention_weights方法提取多头注意力权重。
class SemanticMatchingModel(nn.Module): def __init__(self, vocab_size, embed_dim, num_heads, dropout, forward_expansion, max_seq_len): super(SemanticMatchingModel, self).__init__() self.embedding_layer = EmbeddingLayer(vocab_size, embed_dim, max_seq_len) self.transformer_block = TransformerBlock(embed_dim, num_heads, dropout, forward_expansion) self.classifier = nn.Linear(embed_dim, 2) # 二分类问题 def forward(self, input_ids, segment_ids): embeddings = self.embedding_layer(input_ids, segment_ids) transformer_out = self.transformer_block(embeddings, embeddings, embeddings) logits = self.classifier(transformer_out[:, 0, :]) # 取CLS位置的输出作为句子表示 return logits def get_attention_weights(self, input_ids, segment_ids): embeddings = self.embedding_layer(input_ids, segment_ids) attention_weights = self.transformer_block.attention.get_attention_weights(embeddings, embeddings, embeddings) return attention_weights # 创建模型 model = SemanticMatchingModel(vocab_size, embed_dim, num_heads=8, dropout=0.1, forward_expansion=4, max_seq_len=512)
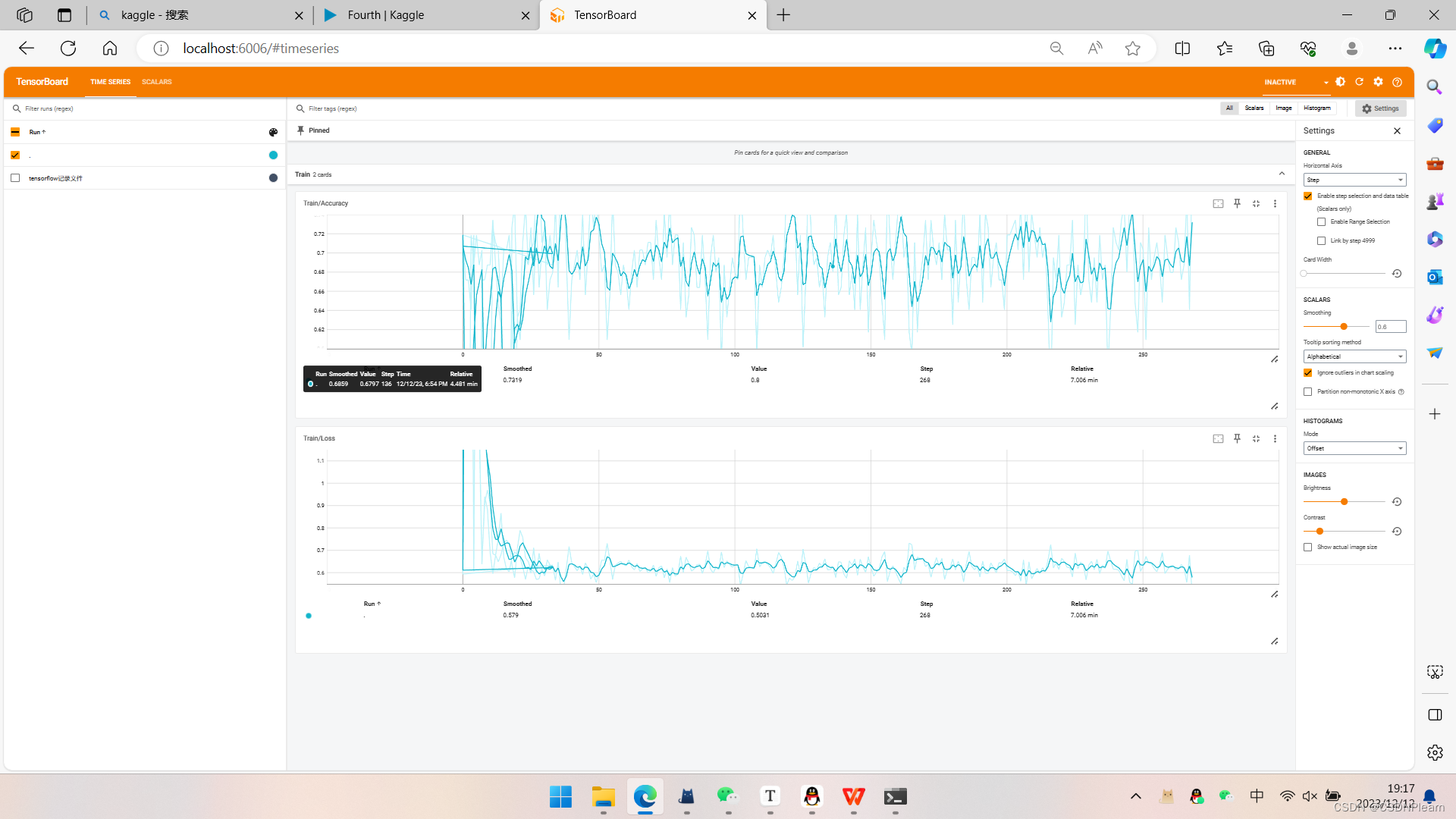
(5) 训练模型,在验证集上计算准确率,并保存在验证集上准确率最高的模型 (2分) 使用tensorboard等可视化插件,展示训练过程中的精度变化和损失变化。 (2分)
普通的训练模型过程,用训练集训练,验证集验证,tensorboard部分也用过很多次了,保存正确率最高模型添加一段判断代码即可
# 如果当前模型的验证集准确率更高,则保存当前模型 if dev_acc > best_acc: best_acc = dev_acc torch.save(model.state_dict(), '/kaggle/working/best_model.pth')
最后的正确率和tensorboard图像如下,值得注意的是正确率一直不变,在后面的验证过程中我注意到是因为模型居然判断都为0。一方面是数据不足,另一方面也是简单模型的局限,复杂的多维度语义交互匹配模型如BiMPM模型等模型过大,不好实现(经费加时间)。
(6) 加载保存的模型,在测试集上随机选取50条数据进行语义匹配测试,展示模型的预测结果。 (2分)
预测结果如下

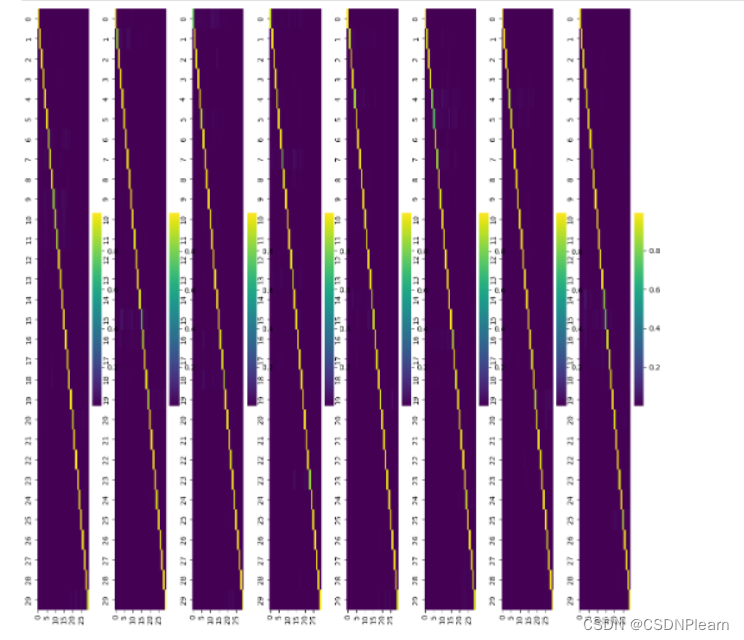
(7) 输入一条样本提取多头注意力权重,对注意力机制的计算结果进行可视化展示(效果如下)(2分)并分析(1分)。
的图像显示的是一个对角线上的明亮线,这可能表示模型在处理序列数据时,主要关注了当前位置的信息,而对其他位置的信息关注较少。
全部注意力权重如图所示
(8)改变transformer的层数再次实验,输出测试集准确率结果,并与之前的结果对比。 (3分)
将self.transformer_block修改为一个nn.ModuleList,其中包含多个TransformerBlock。然后在forward方法中,遍历这些层并依次应用它们即可,这样就添加了Transformer的层数。训练过程没啥变化。
class SemanticMatchingModel(nn.Module): def __init__(self, vocab_size, embed_dim, num_heads, dropout, forward_expansion, max_seq_len, num_layers): super(SemanticMatchingModel, self).__init__() self.embedding_layer = EmbeddingLayer(vocab_size, embed_dim, max_seq_len) self.transformer_blocks = nn.ModuleList([ TransformerBlock(embed_dim, num_heads, dropout, forward_expansion) for _ in range(num_layers) ]) self.classifier = nn.Linear(embed_dim, 2) # 二分类问题 def forward(self, input_ids, segment_ids): embeddings = self.embedding_layer(input_ids, segment_ids) transformer_out = embeddings for transformer_block in self.transformer_blocks: transformer_out = transformer_block(transformer_out, transformer_out, transformer_out) logits = self.classifier(transformer_out[:, 0, :]) # 取CLS位置的输出作为句子表示 return logits def get_attention_weights(self, input_ids, segment_ids): embeddings = self.embedding_layer(input_ids, segment_ids) attention_weights = [] transformer_out = embeddings for transformer_block in self.transformer_blocks: transformer_out, weights = transformer_block.get_attention_weights(transformer_out, transformer_out, transformer_out) attention_weights.append(weights) return attention_weights # 创建模型 model = SemanticMatchingModel(vocab_size, embed_dim, num_heads=8, dropout=0.1, forward_expansion=4, max_seq_len=512, num_layers=2)
结果变化不大,之所以变成69%只是因为我只保留了两位数。

(9) 寻找方法提升模型精度 ,最终根据所有同学的准确度分段排名,最高4分。
正确率0.69,放过自己了。
![]()
(10) 层规范化的位置有两种prenorm和postnorm,查询资料了解二者区别并说明自己的模型中层规范化操作的位置是prenorm还是postnorm(1分),然后尝试另一种层规范化操作,对比二者在具体训练中的区别并分析原因 (2分)。
模型的层规范化(Layer Normalization)是在多头注意力(Multi-Head Attention)或前馈神经网络(Feed Forward Neural Network)之后进行的,所以我的模型使用的是Post-Normalization。所以更改代码,将Layer Normalization(层规范化)应用在每个子层的输入,而不是输出。即可使用另一种层规范化操作。
class TransformerBlock(nn.Module): def __init__(self, embed_dim, num_heads, dropout, forward_expansion): super(TransformerBlock, self).__init__() self.attention = MultiHeadAttention(embed_dim, num_heads) self.norm1 = nn.LayerNorm(embed_dim) self.norm2 = nn.LayerNorm(embed_dim) self.feed_forward = nn.Sequential( nn.Linear(embed_dim, forward_expansion * embed_dim), nn.ReLU(), nn.Linear(forward_expansion * embed_dim, embed_dim), ) self.dropout = nn.Dropout(dropout) def forward(self, value, key, query): # 在输入上应用规范化和注意力 attention = self.attention(self.norm1(value), self.norm1(key), self.norm1(query)) # 添加跳过连接,然后应用第二个规范化和前馈网络 out = self.dropout(self.norm2(attention + query)) forward = self.feed_forward(out) return forward
训练结果如下:![]()
除了PreNorm训练速度快一些,其他似乎没有什么差别,快一些的原因可能是PreNorm可以提供更稳定的训练过程,也就是说它的梯度更稳定,因为它在将数据传递给子层之前就进行了规范化,这可以防止梯度爆炸或消失。所以我们可以采用更高的学习率,这使得它的训练速度更快。















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









