






“ 大模型LLMS面试题相关参考。”

01
—
大模型LLMS面试题相关参考
大模型LLM的 训练目标是什么?
大模型(LLM,Large Language Model)的训练目标主要是通过大规模的语言数据进行预训练,使模型能够理解和生成自然语言。以下是常见的大模型的训练目标和方法:
1. 语言建模目标(Language Modeling Objective)
自回归模型(如 GPT 系列)
-
目标: 通过学习给定之前的词预测下一个词(Token),自回归模型只能依赖前面的上下文来生成后续词语。这种训练目标可以用来生成文本。
-
公式: 最大化序列的概率
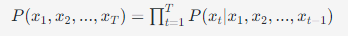
-
应用: 文本生成、对话系统等任务。
自编码模型(如 BERT)
-
目标: 通过学习掩蔽语言建模(Masked Language Modeling, MLM)任务,给定上下文预测被掩蔽的词汇。这是一种双向训练目标,模型可以利用输入的双向上下文信息。
-
公式: 最大化被掩蔽词的概率
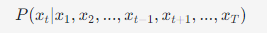
-
应用: 自然语言理解(如分类、命名实体识别)等任务。
2. 因果语言建模(Causal Language Modeling, CLM)
-
目标: 模型只能看到前面的词语,类似于 GPT 的生成任务,通过学习如何从之前的输入序列生成下一个词。
-
特点: 模型只能利用之前的信息,适合语言生成任务。
3. 掩蔽语言建模(Masked Language Modeling, MLM)
-
目标: 给定句子中一部分词被掩蔽,模型需要预测这些被掩蔽的词汇(如 BERT)。这种方法允许模型通过上下文来学习词汇的关系,获得上下文双向表示能力。
-
应用: 主要用于理解任务,比如问答系统、分类任务等。
4. 序列到序列目标(Seq2Seq Objective)
-
目标: 用于机器翻译、文本摘要等任务,模型被训练为给定一个输入序列(源语言),生成一个输出序列(目标语言)。这种目标通常通过 Encoder-Decoder 架构实现。
-
应用: 机器翻译、文本生成、摘要等任务。
5. 对比学习目标(Contrastive Learning Objective)
-
目标: 在某些情况下,LLM 可以通过对比学习的方式进行训练,即将正例与负例进行对比,使得模型可以学习到更丰富的语义表示。
-
应用: 在句子嵌入和对话检索等任务中常见。
6. 强化学习目标(Reinforcement Learning Objective)
-
目标: 通过强化学习优化生成模型的输出,使其更加符合人类的期望,最著名的例子是 GPT 系列在后期通过 “强化学习从人类反馈中优化”(Reinforcement Learning with Human Feedback, RLHF)进行训练,调整生成的语言质量和连贯性。
-
应用: 增强生成任务的输出质量。
总结:
LLM 的主要训练目标包括自回归语言建模、掩蔽语言建模、序列到序列建模以及对比学习等目标。不同的目标设计适合不同的任务,如生成文本、理解文本或生成高度符合人类偏好的内容等。训练这些模型的最终目的是让模型能够更好地理解和生成自然语言,从而适应多种自然语言处理任务。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









