







导读
TL;DR: 本文介绍了一种全身姿态估计新方法,以及如何通过知识蒸馏技术来提高这种方法的效率和准确性。截至目前为止,所提方法目前在 paperwithcode 上的2D Human Pose Estimation on COCO-WholeBody榜单登顶榜首,超越 OpenMMLab 社区此前发布的 SOTA 模型 RTMPose.
全身姿态估计是指在图像中定位出人体、手部、面部和脚部关键点的任务,由于涉及到多尺度的身体部位、低分辨率区域的细粒度定位以及数据稀缺性,这是一个很有挑战性的任务,具体体现在两点:
- 人体的分层结构、手和脸的小分辨率、多人图像中复杂的身体部位匹配,尤其是遮挡和复杂的手部姿势等。2. 此外,为了部署模型,将其压缩成轻量级网络也是必要的,以更好的满足实时性要求。
为此,作者提出了一种名为DWPose的两阶段全身姿态估计器的知识蒸馏方法,以提高其效果和效率:
- 第一阶段蒸馏设计了一种权重衰减策略,同时利用教师模型的中间特征和最终的逻辑信息,包括可见和不可见的关键点,来监督从头开始训练的学生模型。
- 第二阶段蒸馏则进一步提升学生模型的性能。与以前的自知识蒸馏不同,这一阶段仅在20%的训练时间内对学生模型的
head部分进行微调,采用即插即用的训练策略。
此外,为了应对数据限制,论文探索了一个名为UBody的数据集,其中包含了多样的面部表情和手势,用于真实应用场景中。
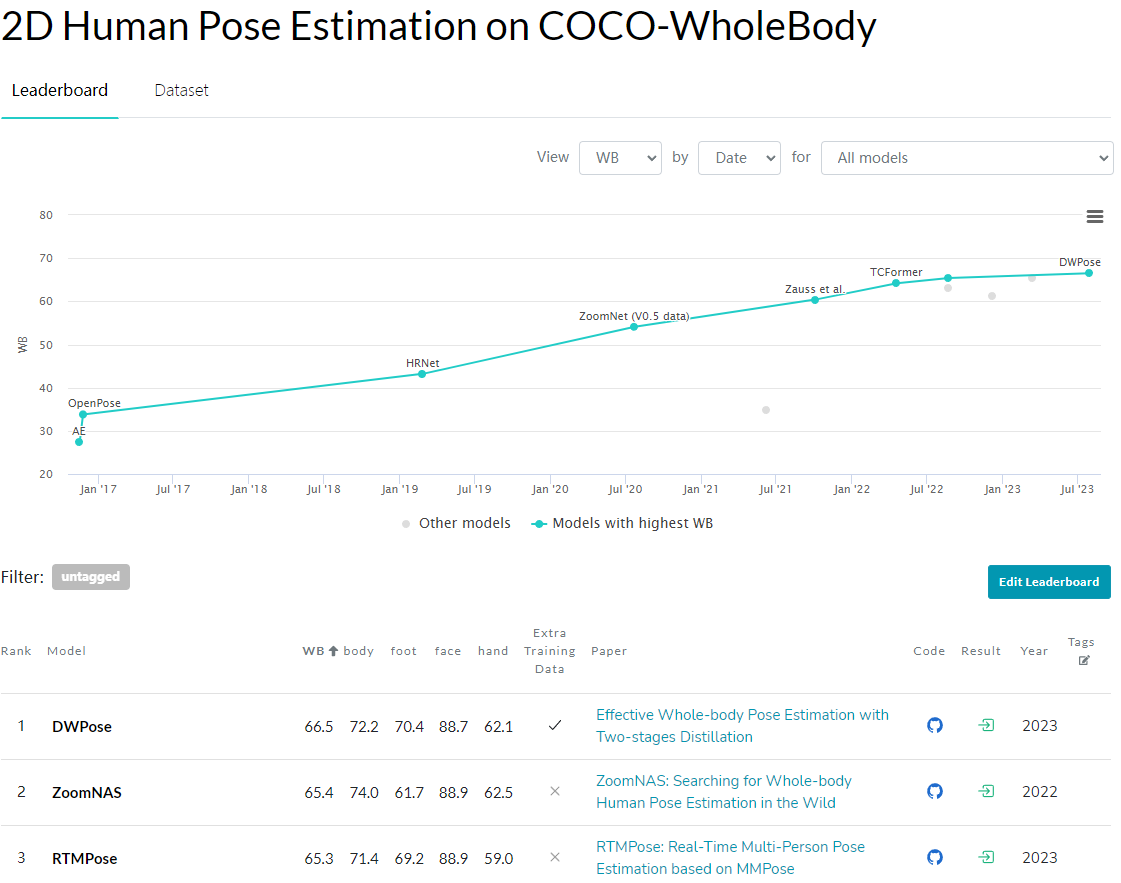
最终通过全面的实验证明了所提方法的简单有效性。如上所述,DWPose在COCO-WholeBody数据集上取得了新的 SOTA,将RTMPose-l的整体姿态平均精度(AP)从64.8%提升到了66.5%,甚至超过了RTMPose-x教师模型的65.3% AP。同时,为了满足各种下游任务的需求,作者还发布了一系列不同大小的模型,按需使用,代码已开源。
背景介绍
2D Whole-body Pose Estimation
列举几个现有的 SOTA 模型,包括:
OpenPose:结合不同数据集对不同身体部位进行训练,以实现分离的关键点检测。MediaPipe:构建了一个感知 pipeline,特别适用于整体人体关键点检测。ZoomNet:首次提出了一种自顶向下的方法,使用层次结构的单一网络来解决不同身体部位的尺度变化问题。ZoomNAS:进一步探索了神经架构搜索框架,以同时搜索模型结构和不同子模块之间的连接,以提高准确性和效率。TCFormer:引入了逐步聚类和合并视觉特征,以在多个阶段中捕捉不同位置、大小和形状的关键点信息。RTMPose:讨论了姿态估计的关键因素,构建了实时模型,在COCO-WholeBody数据集上取得了最新的成果。但仍然存在模型设计冗余和数据限制,特别是对于多样的手部和脸部姿势。
还不了解 MediaPipe 可以先去了解关注下,这是谷歌开源的一个超级棒的仓库,我们后面单独拆一期来讲解。
Knowledge Distillation
知识蒸馏是一种用于压缩模型的常用方法。最初由Hinton等人在提出,该方法通过使用教师模型输出的软标签来指导学生模型。该方法最初设计用于分类任务,也被称为逻辑回归(logit-based)蒸馏。随后的研究工作采用不同的方式利用了教师模型的逻辑信息,传递更多的知识,包括软标签、目标和非目标的逻辑信息。从基于逻辑信息的蒸馏到基于特征的蒸馏,知识可以从中间层传递,并扩展到各种任务,包括检测、分割、生成等。本文提出的DWPose是第一个探索有效的知识蒸馏策略用于此任务的工作。
方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cMZjxWIx-1693106299790)(https://files.mdnice.com/user/13977/4d19893b-e897-43ec-bc29-924e4b69bf48.png)]
如上图所示,DWPose 是一个两阶段姿态蒸馏(Two-stage Pose Distillation,TPD)方法,包括两个独立的阶段。下面是对每个阶段的详细解释。
first-stage
这一阶段的目标是利用预训练的教师模型指导学生模型从零开始学习,同时在特征和逻辑层面上进行蒸馏。
基于特征的蒸馏
在这种蒸馏方法中,作者让学生模仿教师模型的主干网络中的某一层。为了实现这一目标,文中使用均方误差(MSE)损失来计算学生特征与教师特征之间的距离。损失函数的表达式如下:
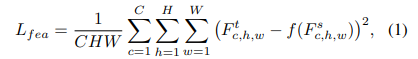
其中, F t F_t Ft 是教师模型的特征, F s F_s Fs 是学生模型的特征, f f f 是一个简单的 1 × 1 1 \times 1 1×1 卷积层,只是用于对齐空间维度,将学生特征调整到与教师特征相同的尺寸。
基于逻辑的蒸馏
RTMPose 中使用 SimCC 算法预测关键点,将关键点定位视为水平和垂直坐标的分类任务。
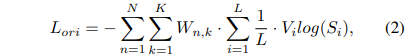
论文指出,基于逻辑的知识蒸馏方法也适用于这种情况。这里作者将RTMPose的原始分类损失进行了简化,去除了目标权重掩码(Weight Mask):
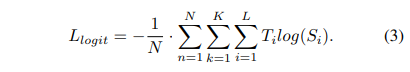
其中,
N
N
N 是批次中的人数,
K
K
K 是关键点的数量,
L
L
L 是
x
x
x 或
y
y
y 的 localization bin 长度,
T
i
T_i
Ti 是目标值,
S
i
S_i
Si 是预测值。
蒸馏的权重衰减策略
在特征蒸馏损失和逻辑蒸馏损失的基础上,本文引申出了一种权重衰减策略,以逐渐减少蒸馏的惩罚力度。这种策略帮助学生模型更专注于标签,从而获得更好的性能。具体地,文中使用一个时间函数 r ( t ) r(t) r(t) 来实现这个策略,其中 t t t 是当前的训练轮数, t max t_{\text{max}} tmax 是总的训练轮数。最终,第一阶段蒸馏的损失可以表示为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NGKbMjEb-1693106299792)(https://files.mdnice.com/user/13977/2c69be7b-9e1b-45dc-a4b4-66dcbdece6c4.png)]
简单小结下,这里我们向大家描述了第一阶段蒸馏的特征和逻辑损失,以及引入的权重衰减策略。通过这些方法,DWPose 可以通过教师模型引导学生模型,实现了对模型的有效蒸馏。
secode-stage
在第二阶段的蒸馏中,作者尝试利用训练好的学生模型来教导“自己”,以实现更好的性能。通过这种方式,无论学生模型是经过蒸馏训练还是从头开始训练,都可以获得性能的提升。
简单来说,我们可以在训练好的模型基础上,首先构建一个具有训练好的主干网络和未训练头部的学生模型,教师模型与之相同,但具备训练好的主干网络和头部。在训练过程中,固定学生模型的主干网络,并更新头部。由于教师和学生具有相同的架构,我们只需要从主干网络中提取特征一次。然后,将特征分别输入到教师的训练好的头部和学生的未训练头部,得到对应的逻辑信息 T i T_i Ti 和 S i S_i Si。
其次,我们采用逻辑蒸馏损失 L logit L_{\text{logit}} Llogit 对学生进行第二阶段蒸馏的训练。值得注意的是,这里放弃了原始的损失 L ori L_{\text{ori}} Lori,这个损失是基于标签值计算的。通过引入超参数 γ γ γ 表示损失的缩放,最终第二阶段蒸馏的损失可以表示为:
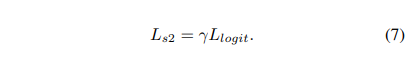
与之前的自知识蒸馏方法不同,论文提出的面向头部的蒸馏方法能够在仅使用20%的训练时间内高效地从头部蒸馏出知识,进一步提高了定位能力。综合起来,第二阶段蒸馏利用训练好的学生模型自我指导,通过更新头部来实现性能提升,这种方法具有高效性和有效性,对于改进模型在有限的训练时间内产生更好结果具有重要作用。
实验
由于超参数等细节对本文方法的复现比较关键,今天我们详细过一遍。
数据集
论文在 COCO 和 UBody 数据集上进行了实验。
- 对于 COCO 数据集,文中采用了 train2017 和 val2017 的标准分割,使用了 118K 张训练图像和 5K 张验证图像。在 COCO 验证数据集上,使用了 SimpleBaseline 提供的通用人体检测器,其平均精度(AP)为 56.4%。
- UBody 数据集包含来自 15 个真实场景的超过 100 万帧图像,提供了对应的 133 个 2D 关键点和 SMPL-X 参数。需要注意的是,原始数据集仅关注 3D 全身姿态估计,并未验证 2D 标注的有效性。论文从视频中每隔10帧选择一帧进行训练和测试。
实现细节
- 对于第一阶段蒸馏,采用公式6中使用了两个超参数 α α α 和 β β β 来平衡损失。在所有实验中包括在 COCO 和 UBody 数据集上都采用了{α = 0.00005,β = 0.1}。
- 第二阶段蒸馏有一个超参数 γ γ γ 来平衡公式7中的损失,此处 γ = 1 γ = 1 γ=1。
定量分析
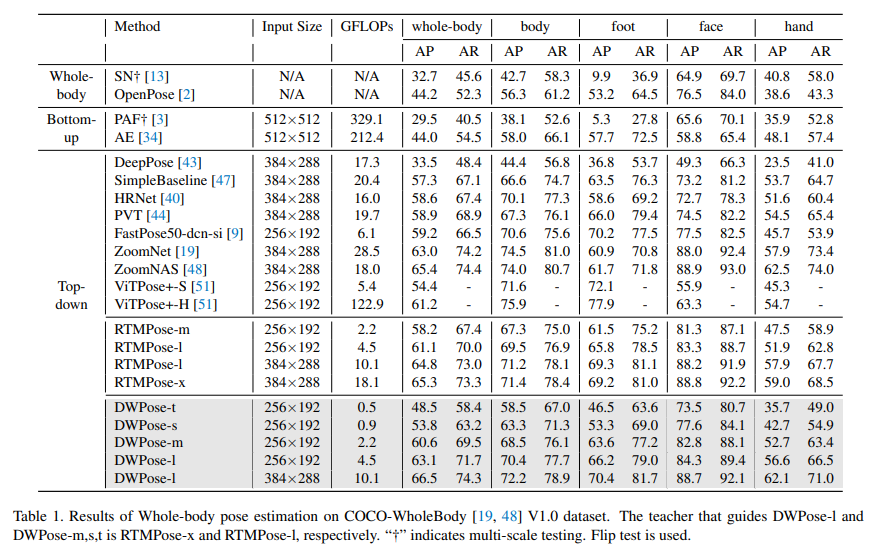
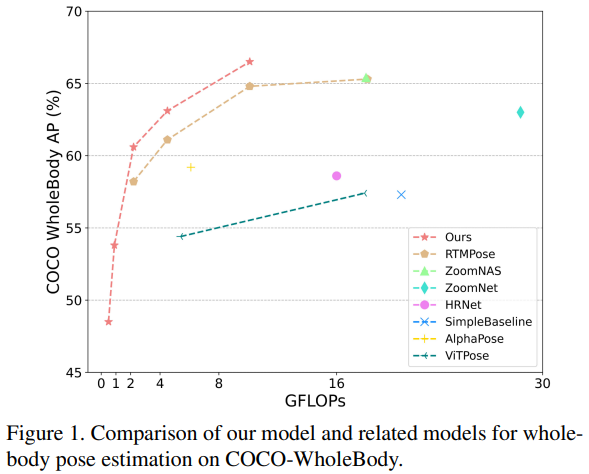
通过表1可以看出,作者使用较大的RTMPose-x和RTMPose-l作为教师模型,分别指导DWPose-l和其他学生模型。通过所提两阶段姿态蒸馏(TPD)方法,不同尺寸和输入分辨率的模型都取得了显著的改进。特别地,DWPose-m在 2.2 GFLOPs 下实现了60.6的整体平均精度(AP),相比基线提高了4.1%,同时推断的消耗保持不变,易于部署。
有趣的是,DWPose-l在两种不同的输入分辨率下分别达到了63.1和66.5的整体平均精度(AP),都超过了教师模型RTMPose-x,而参数和计算量都更小。
定性分析

图3展示了一些定性比较,说明了蒸馏如何帮助学生模型表现更好。两阶段姿态蒸馏(TPD)帮助模型更准确地预测,减少了虚假的姿态检测,增加了真实的姿态检测,特别是对于手指关键点定位的改进。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EMgXqNa0-1693106299793)(https://files.mdnice.com/user/13977/1149c0d8-d18f-47a3-ae5a-f50f8695e32e.png)]
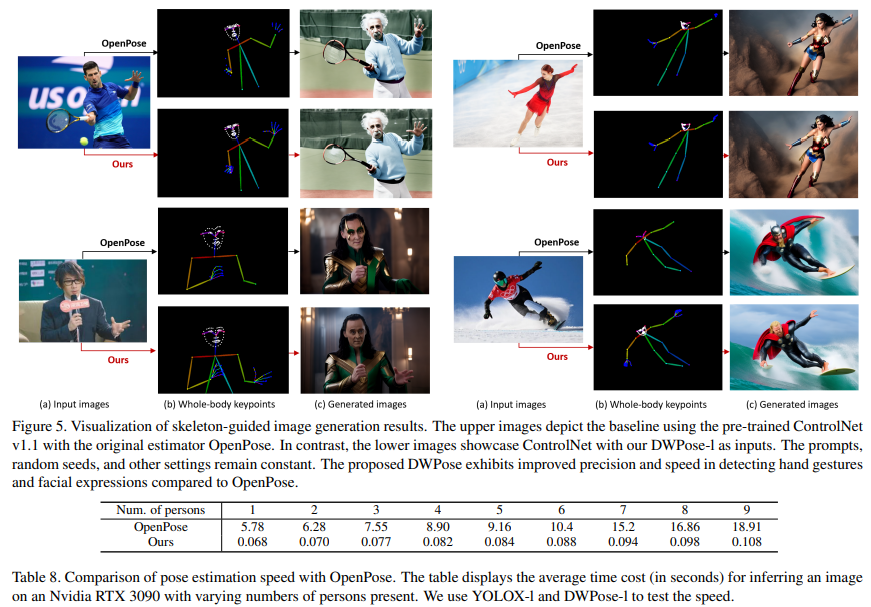
此外,图4中比较了作者提出的方法与常用的OpenPose和MediaPipe中提供的基线方法。可以看出,DWPose 也显著超越了另外两种方法,特别是在截断、遮挡以及细粒度定位的鲁棒性方面。
泛化性
总结
本文旨在解决人类全身姿态估计任务中的效率和有效性问题。作者基于RTMPose,应用蒸馏技术,提出了一种名为“Two-stage Pose Distillation”的方法来增强轻量级模型的性能。通过这种方法,他们首先通过教师模型指导学生模型的特征和逻辑层进行训练,以获得更好的模型性能。在没有更大教师模型的情况下,第二阶段蒸馏在短时间内通过自教导学生模型的头部,进一步提高了性能。
此外,通过研究UBody数据集,进一步提升了性能,最终形成了DWPose模型。实验证明这种方法虽然简单,但非常有效。论文还探索了更好的姿态估计模型对于可控图像生成任务的影响。综合来看,所提方法在人类全身姿态估计领域提出的蒸馏方法为模型的效率和准确性提供了新的思路和实验结果支持。
写在最后
欢迎对姿态估计等基础视觉相关任务与应用感兴趣的童鞋扫描屏幕下方二维码或者直接搜索微信号 cv_huber 添加小编好友,备注:学校/公司-研究方向-昵称,与更多小伙伴一起交流学习!



















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











