






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文分享 CVPR 2022 Oral 的一篇论文『Knowledge Distillation via the Target-aware Transformer』,由RMIT&阿里&UTS&中山提出Target-aware Transformer,进行one-to-all知识蒸馏!性能SOTA!
详细信息如下:

论文链接:https://arxiv.org/pdf/2205.10793.pdf
01
摘要
知识蒸馏(Knowledge distillation)成为提高小型神经网络性能的方法。以往的大多数研究都提出以一对一的空间匹配方式将表征特征从教师回归到学生。然而,人们往往忽略了这样一个事实,即由于结构的不同,同一空间位置上的语义信息通常是不同的。这极大地削弱了一对一蒸馏方法的基本假设。为此,作者提出了一种新的一对多空间匹配知识提取方法。
具体地说,作者允许将教师特征的每个像素提取到学生特征的所有空间位置,给定其相似性。在各种计算机视觉基准测试中,例如ImageNet、Pascal VOC和COCOStuff10k,本文的方法大大超过了最先进的方法。
02
Motivation
知识蒸馏是一种简单的技术来提高任何机器学习算法的性能。一种常见的情况是从较大的教师神经网络中提取知识到较小的学生神经网络中,这样与单独训练学生模型相比,学生模型的性能可以得到显著提高。具体地说,人们构造了一个外部损失函数来引导学生特征图模仿教师的特征图。最近,它已被应用于各种下游应用,如模型压缩、半监督学习。
以往的工作只从最后一层的神经网络中提取知识,例如图像分类任务中的Logits。近年来,人们发现提取中间特征图是一种更有效的方法。
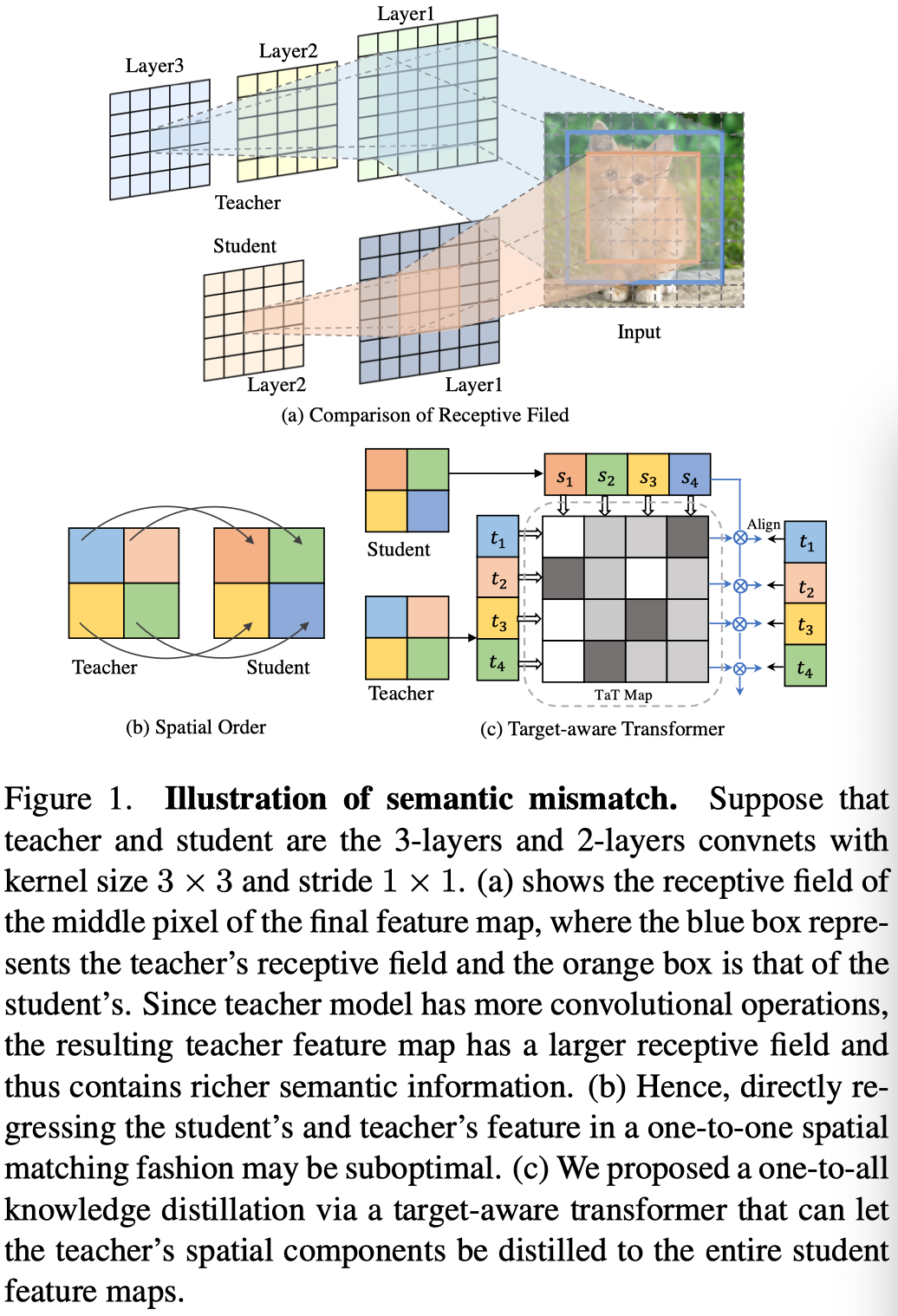
为了计算上述方法的蒸馏损失,需要选择来自教师的源特征图和来自学生的目标特征图,其中这两个特征图必须具有相同的空间维度。如上图b所示,模型通常以一对一空间匹配的方式计算损失。该方法的一个基本假设是每个像素的空间信息是相同的。在实践中,这一假设通常是不成立的,因为学生模型通常比教师模型具有更少的卷积层。
上图 (a) 中显示了一个示例,即使在相同的空间位置,学生特征的感受野通常也明显小于教师的感受野,因此包含较少的语义信息。此外,最近的工作证明了感受野对模型表征能力的影响的重要性。这种差异是当前一对一匹配蒸馏导致次优结果的一个潜在原因。
为此,作者提出了一种新颖的one-to-all空间匹配知识蒸馏方法。在上图 (c) 中,本文的方法通过参数相关性将教师在每个空间位置的特征提炼成学生特征的所有部分,即蒸馏损失是所有学生部分的加权求和。为了对这种相关性进行建模,作者制定了一个Transformer结构,该结构重建了学生特征的相应各个组成部分,并产生了与目标教师特征的对齐。作者将其命名为目标感知transformer(target-aware transformer)。因此,作者使用参数相关性来衡量以学生特征和教师特征的表征成分为条件的语义距离,以控制特征聚合的强度,从而解决了一对一匹配知识提取的缺点。
由于本文的方法计算特征空间位置之间的相关性,当特征图很大时,它可能变得很难处理。为此,作者以两步分层的方式扩展了我们的方法:1)不计算所有空间位置的相关性,而是将特征图分割为几组patch,然后在每组中执行one-to-all的提取;2) 作者进一步将patch中的特征平均化为单个向量,以提取知识。这降低了本文方法的复杂性的数量级。
作者在两个流行的计算机视觉任务评估了本文的方法,即图像分类和语义分割。在ImageNet分类数据集上,tiny ResNet18学生的top-1准确率可以从70.04%提高到72.41%,超过最先进的知识蒸馏0.8%。对于COCOStuff10k上的分割任务,与之前的方法相比,本文的方法能够将mobilenetv2结构的mIoU提高1.75%。
03
方法
在本节中,作者首先简要描述了特征映射知识提取的基本要素,然后介绍了通过目标感知transformer进行知识提取的一般公式。当本文的方法计算给定特征映射的逐点相关性时,计算复杂性在大规模特征上变得难以处理,然后作者引入分层蒸馏方法来解决这一限制。
3.1. Formulation
假设教师和学生是两个卷积神经网络,用T和S表示。和分别表示教师特征和学生特征。在之前的工作中,蒸馏损失由网络最后一层特征的距离来表示:例如,在图像分类领域,它指的是进入softmax层之前的“logits”和交叉熵损失。具体而言,蒸馏损失定义为:
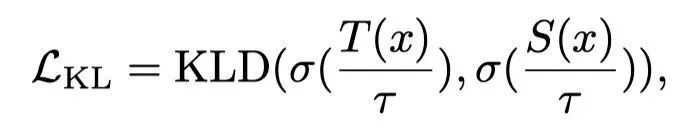
其中,KLD(·)测量Kullback-Leibler散度,σ(·)是softmax函数,T(x)和S(x)是给定特定输入x的输出对数,τ是温度系数。在不丧失一般性的情况下,作者假设通道维度与C对齐,并将和 reshape为2D矩阵:
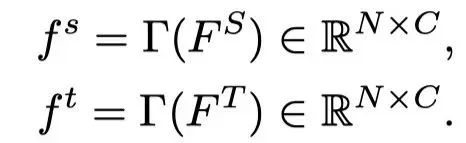
这里,是一个将3D特征张量展平为2D矩阵的函数,其中矩阵的每一行按空间顺序与特征张量中的一个像素相关联,N=H×W。可以用基数N描述两组像素和:
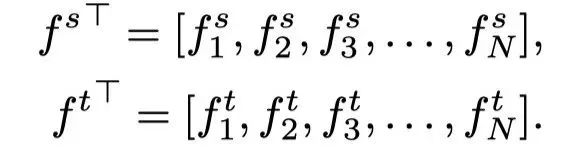
之前的工作简单地以一对一的空间匹配方式最小化两组和之间的差异,作者将这种方法称为特征匹配(FM):
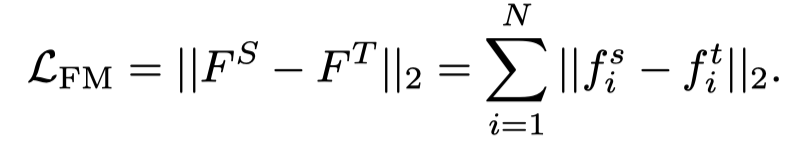
这个公式假设教师和学生的语义分布完全匹配。然而,如前所述,对于通常包含更多层和更大特征通道的教师网络的特征图,与学生网络相比,相同像素位置的空间信息包含更丰富的语义信息。以像素方式直接回归特征可能会导致次优的提取结果。
为此,作者提出了一种one-to-all空间匹配知识提取方法,允许教师的每个特征位置以动态方式指导整个学生特征。为了让整个学生模仿教师的一个空间成分,作者提出了Target-Ware Transformer(TaT)来对学生特征在特定位置的语义进行像素级的重新配置。给定教师的空间分量(对齐目标),作者使用TaT引导整个学生在其相应位置重建特征。以对齐目标为条件,TaT应反映与学生特征组件的语义相似性。作者使用线性算子来避免改变学生语义的分布。变换算子的公式可定义为:
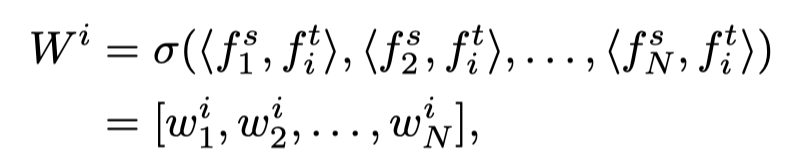
其中,和表示教师和学生的相应第i个分量,表示内积,。作者使用内积来度量语义距离,并使用softmax函数进行归一化。的每个元素都类似于gate,控制将传播到第i个重新配置点的语义量。通过在所有组件中聚合这些相关语义,可以得到了以下结果:

因此,上述两个公式可以表示为:
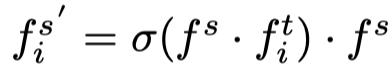
这是一种简单的非参数方法,仅依赖于原始特征。为了便于训练,作者引入了在学生特征和教师特征上应用额外线性变换的参数化方法。作者观察到,在消融研究中,参数化版本比非参数版本表现更好。在目标感知transformer的指导下,可将重新配置的学生特征表示为:
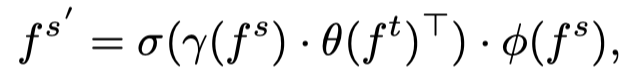
其中是由3×3 conv层加上BN层组成的线性函数。如果的通道数与的通道数不匹配,有助于对齐。
重构后,的每个组件都从原始特征中聚合出有意义的语义,增强了表达能力。本文的模型不要求学生以像素到像素的方式重建教师特征,允许学生作为一个整体“模仿老师”。要求通过教师特征最小化L 2损失。TaT知识蒸馏的目标可以通过以下方式给出:
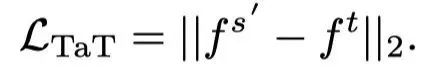
最后,本文提出的方法的总损失可以通过以下方式定义:
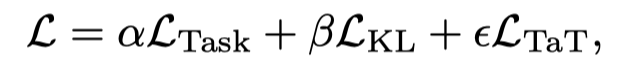
这里的可以是一般机器学习任务上的任何损失。α、 β和ϵ是平衡损失的权重因子。
3.2. Hierarchical Distillation
该算法克服了以往一对一空间匹配方式的局限性。然而,对于大型特征映射,TaT映射的计算复杂度将变得很难解决。假设特征图的空间维数为H和W,这意味着计算复杂度将达到。
因此,作者提出了一种分层蒸馏方法来解决这个大的特征映射限制。它包括两个步骤:1)patch-group蒸馏,将整个特征图分割成较小的patch,从而从老师那里提取局部信息给学生;2) 作者进一步将局部patch总结为一个向量,并将其提取为全局信息。
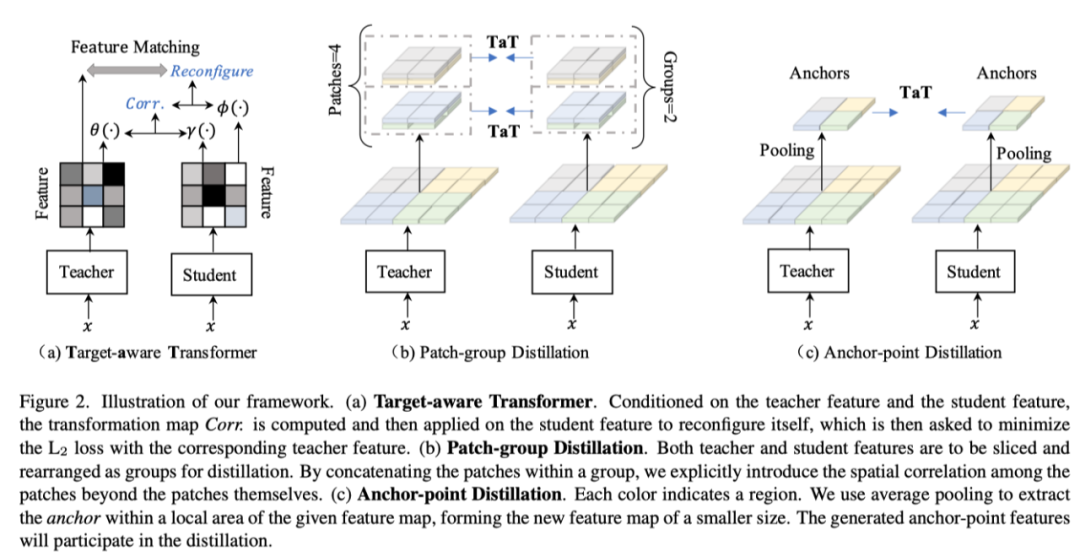
3.2.1 Patch-group Distillation
如上所述,随着输入特征映射的空间维度增加,提取变得更加困难。一个简单的解决方案是将特征图划分为patch,并在patch中单独执行蒸馏。然而,patch之间的相关性被完全忽略,导致次优解。
因此作者提出了patch-group提取(上图(b)),允许学生从patch中学习局部特征,并在一定程度上保留它们之间的相关性。给定原始学生特征和教师特征,将其划分为大小为h×w的n×m个patch,其中h=H/n,w=W/m。它们进一步按顺序排列为g组,每组包含p=n·m/g个patch。
具体而言,group中的patch将在通道维度上concat在一起,形成一个新的尺寸为h×w×c·g的张量。这样,新张量的每个像素都包含来自原始特征p个位置的特征,其中明确包含空间模式。因此,在蒸馏过程中,学生不仅可以学习单个像素,还可以学习它们之间的相关性。直觉上,一个更大的群体将引入更丰富的相关性,但复杂的相关性将变得难以学习。
3.2.2 Anchor-point Distillation
patch-group蒸馏可以在patch层次上学习细粒度特征,并在一定程度上保持patch之间的空间相关性。然而,它无法感知长距离依赖。正如消融研究中所见,通过连接所有patch来保持整体相关性的尝试将失败。对于复杂场景,长距离依赖对于捕获不同对象的关系很重要。
作者通过提出的Anchor-point蒸馏来解决这个难题。如上图(c)所示,作者将局部区域总结为紧凑表示,称为anchor,在局部区域内具有代表性,以描述给定区域的语义,形成新的较小尺寸的特征图。由于新特征映射由原始特征的摘要组成,因此它可以近似地替换原始特征以获得全局依赖关系。
作者只需使用平均池化来提取anchor点。然后将所有anchor点分散回相关位置,以形成新的特征图。anchor点特征用于蒸馏,目标表示为。patch-group蒸馏使学生能够模拟局部特征,而Anchor-point蒸馏使学生能够学习粗Anchor-point特征的全局表示,这些特征相互补充。因此,这两个目标的结合可以带来更好的结果。综上,语义分割设计的目标可以写为:

04
实验
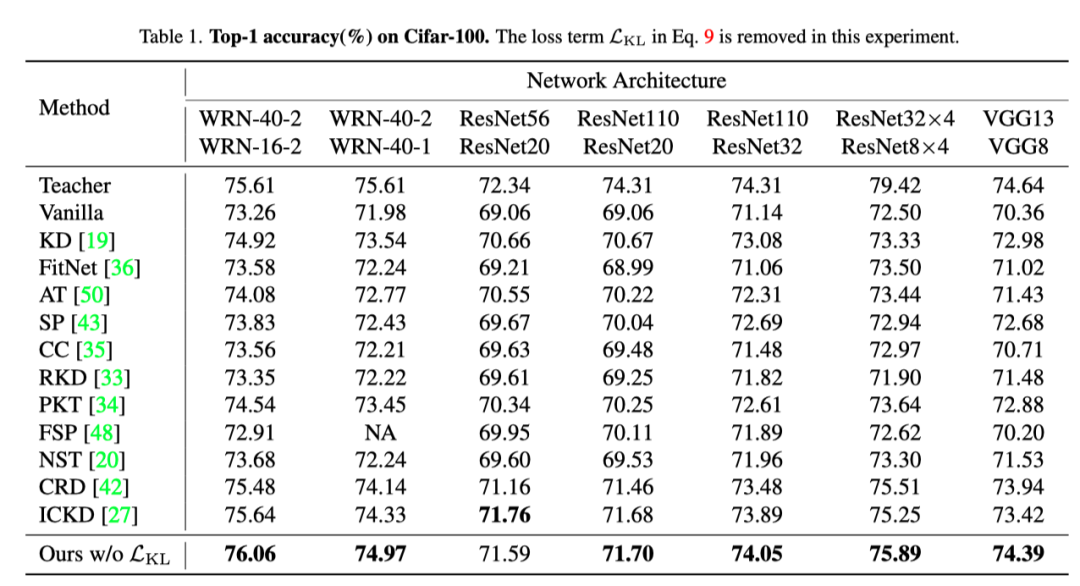
为了证明本文的方法的泛化能力,作者将本文的蒸馏方法应用于各种网络结构。上图展示了在CIFAR10上图像分类的结果,可以看出,本文的想法相比于其他SOTA具有明显的性能优势。

作者分别选择ResNet34和ResNet18作为教师和学生模型。上表中展示了学生和教师模型的最高精确度。本文的方法大大优于最先进的方法。即使没有的帮助,本文的模型在一个很小的ResNet18上也可以达到72.07%。
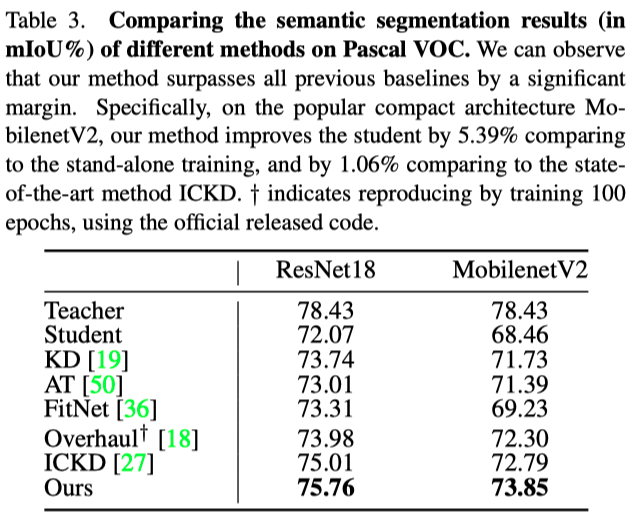
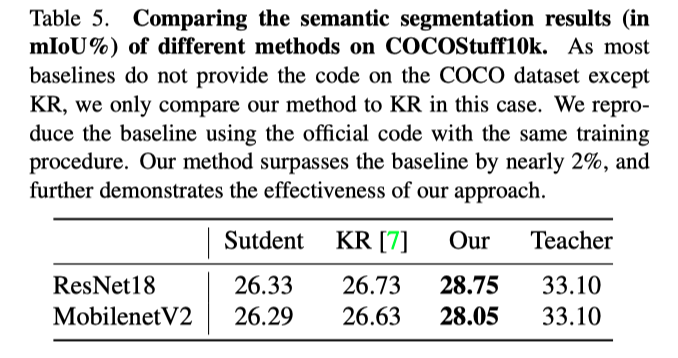
由于在对图像分类进行提取时,特征映射的大小相当小,作者计划进一步研究本文的方法在语义分割上的泛化能力。上表分别展示了本文方法在Pascal VOC和COCOStuff10k上的语义分割实验结果。
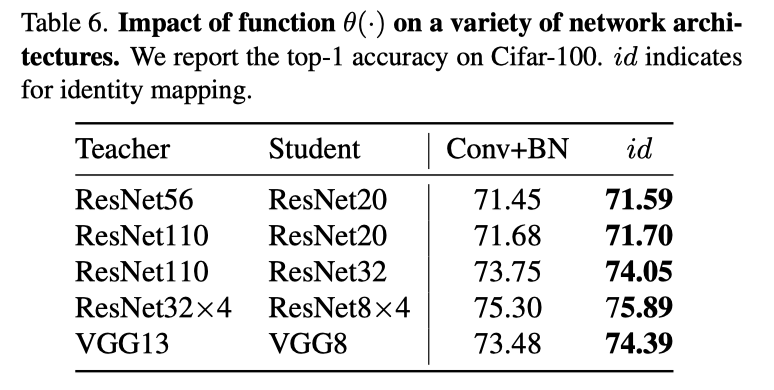
作者比较了θ(·)的不同设置,包括identical mapping与Conv+BN。Cifar100的结果如上表所示。令人惊讶的是,θ(·)的identical mapping总是表现得更好。

通过将θ(·)和γ(·)设置为ImageNet上的identical mapping,作者进一步研究了非参数实现(如上表)。结果表明,半参数版本的性能最好。
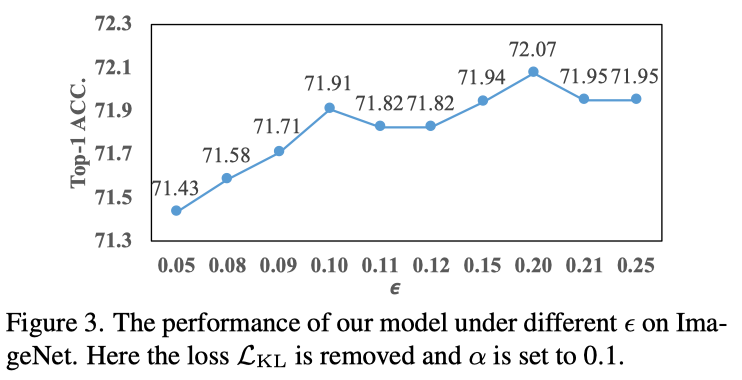
作者进一步探索了系数ϵ的不同设置(见上图)。当从0.05增加到0.25时,目标可以带来积极和稳定的效果。
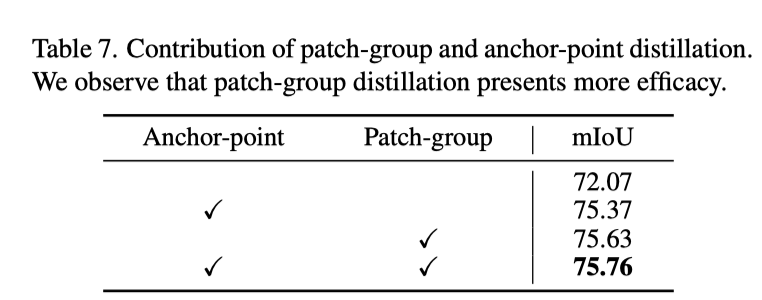
上表展示了本文提出的两种蒸馏方式的消融实验结果,可以看出这两个部分的组合实现了最佳性能,表明两个目标是互补的。
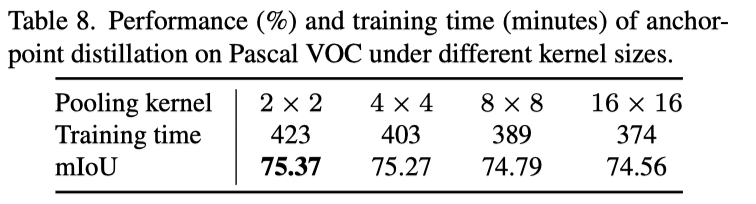
上表显示的结果表明,anchor-point蒸馏中,随着池化大小的增加,蒸馏计算量大大减少。另一方面,过大的池化范围会忽略有用的信息表示,并损害性能。

上表显示的结果表明,patch-group蒸馏中,通常较小的patch大小有利于patch组蒸馏,但过大的patch大小可能会不利,因为它接近原始特征。

上表显示的结果表明,patch-group蒸馏中,不同group数的实验结果,可以看出,4个patch作为一个组可以达到最佳性能。
05
总结
本文通过目标感知transformer开发了一个知识蒸馏框架,使学生能够聚合自身的有用语义,以增强每个像素的表现力,从而使学生作为一个整体模仿老师,而不是平行地最小化每个部分的不同。本文的方法被成功地扩展到语义分割,提出了由patch group和anchor point蒸馏组成的分层蒸馏,旨在关注局部特征和长期依赖性。作者进行了深入的实验,验证了该方法的有效性,提高了SOTA水平。
参考资料
[1]https://arxiv.org/pdf/2109.11295.pdf
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









