






作者 | agent 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/442949904
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!

论文题目:Toward Practical Self-Supervised Monocular Indoor Depth Estimation
论文链接:https://arxiv.org/pdf/2112.02306.pdf
前言
自Facebook改名为Meta后,元宇宙的概念被各种追捧,空间虚拟化作为元宇宙的特性之一,与其相关的AR、VR等应用已经被研究了很多年,而深度估计又是AR/VR中不可或缺的基础技术,这里我们对Meta Reality Labs新鲜出炉的一篇面向室内空间的实用性自监督单目深度估计论文进行解读。
研究动机
当前大多数自监督单目深度估计方法(如MonoDepth,MonoDepth2,DepthHints,ManyDepth等)都专注于自动驾驶场景,并且会在大规模的自动驾驶场景数据集(如KITTI、CityScapes等)上进行训练。而相比于自动驾驶场景,利用自监督学习室内场景的深度更加具有挑战性,主要由以下几个原因:
结构先验(structure priors):在自动驾驶场景中进行深度估计时通常会在学习范式中施加一个比较强的场景结构先验,如图像的上面一部分通常是距离较远的天空或建筑物,而下面一部分则通常是由近向远延伸的道路;但是在室内场景中,这种结构先验是很弱的,因为目标往往杂乱无序的排列在近处。
深度分布:在自动驾驶场景中,深度的分布在道路上由近到远往往是 比较均匀的;而在室内场景中,深度可以集中分布在或近或远的范围,例如桌子或者天花板的近景,这就给在室内场景中预测准确的度量深度(metric depth)造成挑战。
相机位姿:在自动驾驶场景中,由于传感器往往被固定在车辆上,因此其平移往往发生在一个平面上,且其旋转仅仅由航向角控制,即位姿估计只包含了3个自由度(2平移+1旋转);而在室内场景中,传感器可以任意移动,即包含了6个自由度的运动(3平移+3旋转),因此一个理想中的位姿估计网络需要能够应对室内场景中任意的相机姿态和复杂的场景结构。
无纹理曲面:在室内场景中存在大量的无纹理区域(如墙面等),这会导致自监督单目深度估计中常用的光度约束产生歧义。
以上原因的存在,使得现有的自监督单目深度估计算法在比较复杂的室内场景中泛化能力较差。
论文贡献
为了提升在复杂室内场景中的深度估计鲁棒性,论文中提出了一种结构蒸馏(structure distillation)的方法——DistDepth,该方法可以从一个预训练过的深度估计模型中学习生成结构化的深度信息,需要注意的是学习到的深度信息是与度量无关的,即其学习到的是相对深度,而不是绝对深度。论文中所提出的蒸馏策略同时考虑了统计意义上的深度结构相似性和空间遮挡边界相似性,使得结构信息可以有效地整合进自监督深度估计模型中。在自监督分支中,还利用左右一致性学习度量信息。最后将二者结合起来,就可以获得室内场景的包含结构化和真实度量的深度信息,并且可以做到实时推理。
另外,论文中还收集了两组数据集:SimSIN数据集是从上千个仿真环境中获取到的;而UniSIN数据集则包含了500组现实场景下室内环境的扫描序列。基于所收集的数据集,论文通过一系列实验提供了覆盖方法、数据和应用的全面研究方案。
最终,论文证明了所提出的面向实际应用的室内场景深度估计模型可以在无需精确的深度真值标注的情况下,仅仅通过在仿真器中高效地采集数据,就可以拥有强的泛化能力,同时其深度感知的精度高,且推理的实时性强。
研究方法
基本问题描述





现在我们将上面的推导与MonoDepth2论文中关于光度损失的描述(见图2)结合起来看,会发现图1中所定义的左图可以看作是target view,右图可以看作是source view,公式(3)中所求解的右图坐标实际上就是图2中proj()所定义的获取source view中坐标的映射过程(注意,一般采用的target camera与source camera的内参矩阵一致,所以在图2中,统一用K表示了),基于映射出来的source view坐标,从source view中采样像素点,也就是图2中的<>操作。由于在source view中采样时,是基于target view中的像素坐标和对应深度来选取source view中的像素的,因此将采样出来的source view像素按照target view中的坐标进行排列,实际上就是利用source image生成了target image的估计图,然后再与原始的target image进行比较。


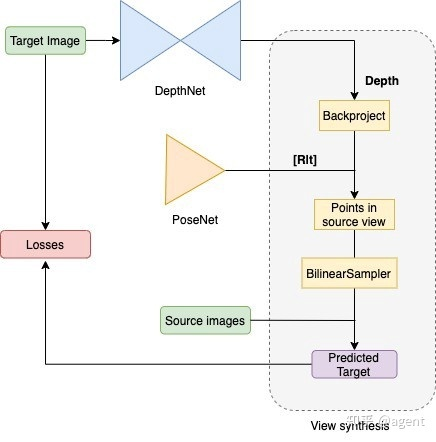
photometric loss描述完毕,我们来看图4中的自监督SFM流程图:通过DepthNet回归出target depth,基于PoseNet回归出从target view到source view的转换矩阵[R|t],然后利用前面所述的重投影过程计算Predicted Target Image,采样的时候使用bilinearSampler是因为计算出来的source images中的采样坐标可能是带有小数的,通过双线性方式可以保证估计出来的target image更平滑。在推理时,实际上只需要执行前面的DepthNet就可以获取Target Image的深度图了。
DistDepth: 从专家网络中进行结构提取
为了应对室内环境中自监督单目深度估计框架所遇到的泛化性问题,论文中提出了DistDepth框架,其结构如图5所示。
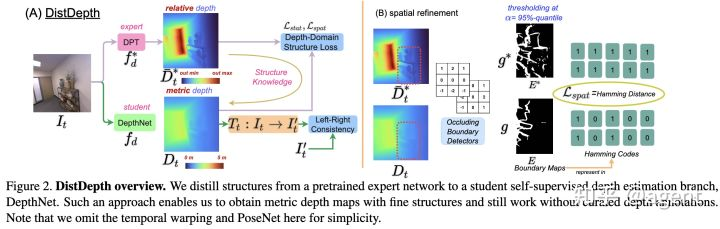

DPT输出值的最小二乘对齐
由于专家网络DPT输出的是相对深度,因此直接用其对student网络进行监督不合适,论文中假设 与 之间存在一个尺度缩放和平移的关系,即认为 与真实的深度值 分布接近,其中 和 分别表示尺度因子和平移因子,二者的计算可以通过最小二乘求得。令 表示 中的第i个像素位置的深度, 表示 中第i个像素位置的深度,则目标是求解下面的最小二乘问题:

Statistical loss
与图像域的结构相比,深度域中仅仅包含几何结构,而没有与深度无关的目标纹理、图案等低层次线索。图像的结构相似度可以基于SSIM从统计角度获得,而深度域中结构相似度也可以用与其深度值分布相关的均值、方差、协方差表示。因此可以基于SSIM计算深度图 与 之间的结构相似度约束结构化的深度信息生成,对应loss如下:
 (4)
(4)

Spatial refinement loss
 (5)
(5) (6)
(6) (7)
(7)
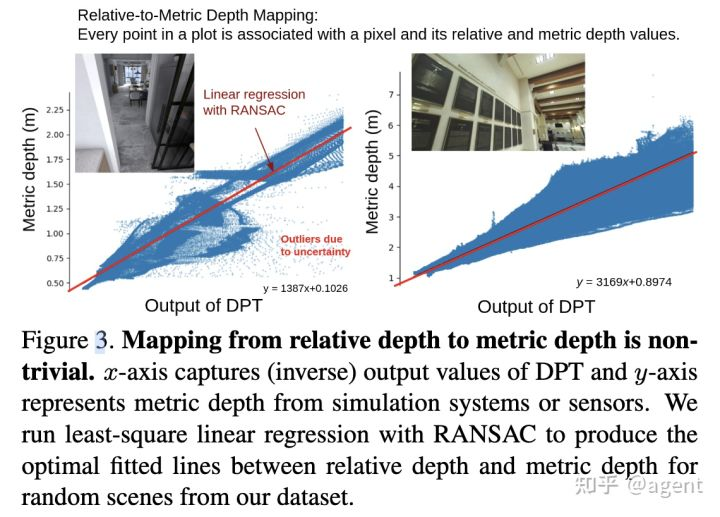
上述DistDepth框架中,结构蒸馏分枝可以使student model具有更高的泛化能力,从而可以更好的分离出底层线索;而自监督分枝则可以帮助DPT学习不同室内场景的室内深度范围。直观上看,有一种更简单的方法是直接基于DPT的结果预测缩放因子和平移因子,从而使得DPT结果能够与度量深度对齐,正如前面所介绍的基于最小二乘估计缩放、平移因子的做法一样,这种做法虽然简单,但是存在一些缺点:因为神经网络由于其模型本身或者数据的影响而不可避免的会包含一些不确定性,因此相对深度与度量深度之间整体呈现线性关系,但是也会存在一些噪声,这些噪声会导致预测的最佳曲线对应的平移缩放因子在不同的场景中可能差异很大。如图6所示,基于最小二乘所计算的DPT相对深度和传感器/仿真系统输出的度量深度之间的线性关系,其在不同场景有比较大的差异。
数据集
训练集SimSIN
为了在自监督训练中引入左右和时域上的光度一致性,论文中采用环境仿真器将3D虚拟环境渲染到立体对图像序列上,所构造的SimSIN数据集包含515K立体对,涉及~1000种不同的环境。
训练集UniSIN
为了对比在虚拟数据集和真实数据集上的gap,论文还基于ZED-2i相机从一所大学的室内空间收集了大量的双目图像序列,所采集的UniSIN数据集共包含500个序列,每一个序列有200组双目图像,共计200K张图像。
测试集
在对算法评估时,论文也分别收集了仿真数据集和真实数据集进行评估。其中虚拟数据集针对一个虚拟公寓渲染出了3.5K图片构建出VA数据集,另外还包含了Hypersim数据集用于定性演示。真实数据集则选择了NYUv2数据集,另外还基于ZED-2i采集了1000组数据集用于数值评估。
实验与分析
仿真数据集实验结果

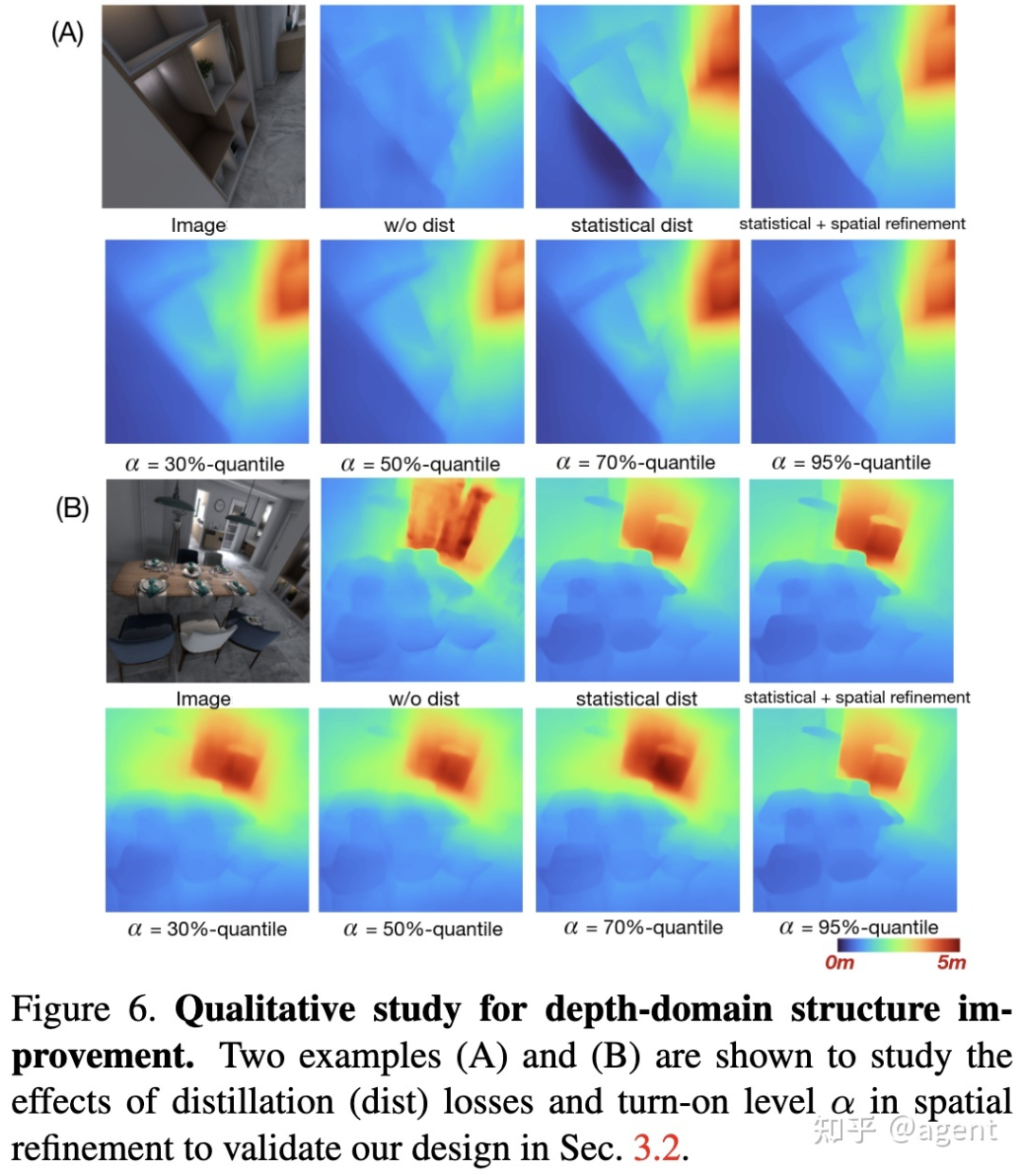
Figure 6中的消融实验证明了以下几点:
引入distillation loss后得到的深度图结构轮廓更清晰;
引入spatial refinement后,其深度边界精度进一步提升(尤其是例子A);
提取深度边界的阈值α取值越大,深度图轮廓越清晰。
真实数据实验结果
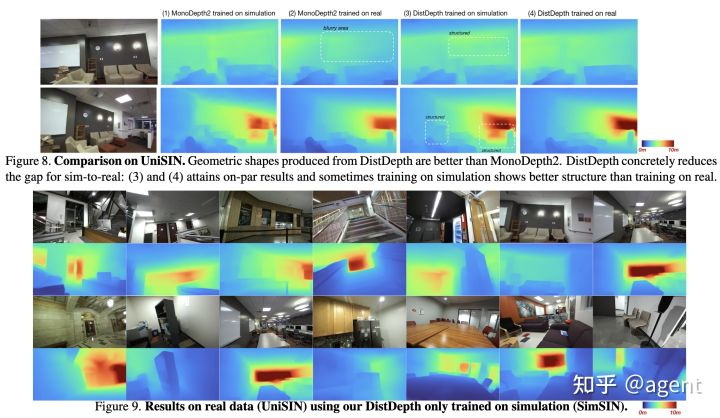
Figure8中,MonoDepth2分别在仿真数据集和真实数据集上训练,然后在真实数据集上测试,两个结果之间的有明显的gap,在真实数据集上训练的效果更好一些;而DistDepth的gap则更小一些,甚至在某些物体轮廓上,基于仿真数据集训练的效果还更好一些,表明了论文中所提出的训练策略有比较好的泛化性。
在Figure9中则展示了DistDepth在仿真数据集SimSIN上训练后的模型,在真实数据集UniSIN上测试结果依然有比较好的结构轮廓。
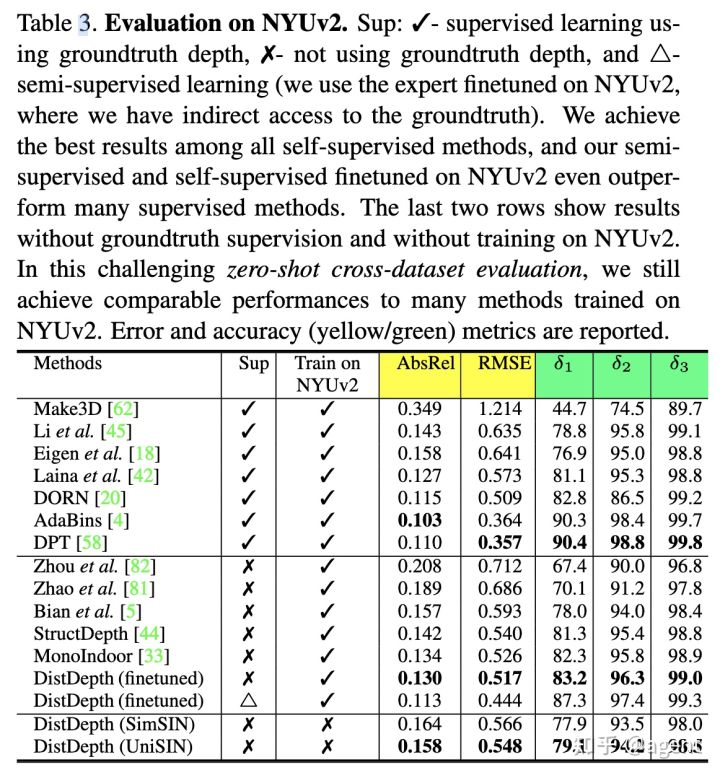
Table3中展示了NYUv2数据集上的一些评测结果,可以看到用无监督方式训练的DistDepth在无监督类方法中表现出了SOTA性能,而引入半监督训练的DistDepth胜过了多数有监督方法。另外,基于仿真数据集SimSIN训练的DistDepth相比于真实数据集UniSIN训练的DistDepth性能相近,且即便不使用NYUv2数据集进行训练,其依然表现出了不错的性能。
下游应用对比
AR效果对比

3D照片效果对比

结论
这篇论文提出了一个实用的室内深度估计框架DistDepth,该框架具有以下特性:
自监督
可高效仿真训练
强泛化能力
精确、实时推理能力
借助于从专家网络那里提取到的深度域结构知识,论文在推理更精细的结构和更精确的度量深度方面都有了实质性的改进。同时通过零样本跨数据集推理,证明了所提出方法在不同数据域上的泛化能力。更重要的是,论文中所提出的蒸馏策略可以将从仿真数据集中学习到的深度很好的转换到真实场景中。在推理时,只需要对DepthNet执行一次前向就可以生成结构化的度量深度,在便携式设备上可以达到35+fps以满足实时性需求。
最后,论文还提出了DistDepth的局限或者可改进的方向:
DistDepth是以每帧为基础推断深度的,可以考虑引入视频的特性,为视频输入生成时域上更一致的深度,不过目前设计出一个实时且高度结构化的视频深度估计器仍是一个悬而未决的问题;
基于左右一致性的深度估计模型对于反射物体的处理依然是一个难题,比如镜子,论文认为一个可能的解决方案是先对镜子进行定位,然后在深度估计的基础上做深度补全。
参考文献
[1] 3D Imaging Technology - Time of Flight
[2] SFM Self Supervised Depth Estimation: Breaking Down The Ideas
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









