






作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!

对于3D检测,标注激光雷达点云是困难的,因此数据增强是充分利用宝贵注释数据的重要模块。作为一种广泛使用的数据增强方法,GT样本通过在训练期间将GT插入激光雷达帧中,有效地提高了检测性能。然而,这些样本通常被放置在不合理的区域,这会误导模型学习目标和背景之间的错误上下文信息。
为了解决这个问题,在本文中提出了一种上下文感知数据增强方法(CA-aug),该方法通过计算激光雷达点云的“有效空间”来确保插入目标的合理放置。CA-aug是轻量级的,与其他增强方法兼容。与GT样本和激光雷达aug(SOTA)中的类似方法相比,它为现有检测器带来了更高的精度。作者还对基于距离视图的(基于RV的)模型的增强方法进行了深入研究,并发现CA-aug可以充分利用基于RV的网络的潜力。KITTI值分割实验表明,CA-aug可以将测试模型的mAP提高8%。
1、简介
在自动驾驶系统中,3D检测是目标跟踪、路径规划等功能的基础。由于能够直接获得精确的空间几何信息,并且成本不断降低,车载激光雷达在自动驾驶的场景感知中发挥着重要作用。因此,激光雷达点云中的3D检测引起了许多研究人员的关注。近年来,得益于KITTI和Waymo等自动驾驶数据集,3D检测模型得到了快速发展。它们的准确性和可靠性不断提高。然而,与图像相比,由于点云的稀疏性和边界框的自由度更高,标注3D训练数据的成本更高,耗时更长。然而,神经网络需要大量的标注数据来确保准确的推断结果。
这个问题的一个解决方案是通过数据模拟器(如Carla和Airsim)生成更多的训练样本。为了解决模拟到真实领域的巨大差距,一些研究人员将来自真实场景的扫描数据与CAD模型相结合。例如,《Augmented lidar simulator for autonomous driving》使用专业3D扫描仪Riegl VMX-1HA构建了高分辨率静态地图,通过将CAD目标模型插入其中,可以从中获得低分辨率场景点云数据。在激光雷达smi中,作者通过多帧配准和表面重建建立了3D地图和物体模型,而不需要昂贵的激光扫描仪。
与数据模拟不同,数据增强不需要太多时间来提前生成合成训练样本。它可以被整合到训练过程中,有效避免过度拟合。与2D检测类似,基本数据增强(如全局旋转、镜像和平移)广泛用于点云。为了提高数据扩充的灵活性,一些研究人员使用optimistic策略来自动化相关的超参数。对抗性学习也可以用于在训练期间调整训练样本的难度,以提高模型的鲁棒性。在GT示例中,作者创建了一个包含所有GT信息的数据库。在训练期间,从中随机选择一些目标,并将其插入到点云场景中。由于其能够纠正正负示例之间的极端数据不平衡,并显著提高检测器的性能,GT样本被广泛用于各种模型中。之后,提出了一系列新的方法。他们中的大多数通过改变GT的表面点的分布来改进网络的泛化,这相当于扩展了GT数据库。
然而,在GT样本中,目标以其原始位置插入激光雷达框架,这意味着它们很可能出现在不合理的区域,例如墙壁或建筑物后面。它对学习有两个不利影响:
由于插入目标的姿势与当前场景无关,因此它们之间的语义信息丢失。
与车辆相比,行人和骑车人的表面点更稀疏,形状更不规则。当它们出现在不合理的区域时,网络很难将它们与噪声区分开来,这会误导神经网络学习错误信息。
近年来,基于距离视图(RV)的检测方法由于易于部署和快速推理而引起了许多研究人员的关注。然而,基于RV的模型需要维持激光雷达点云的2.5D结构。在球面投影过程中,需要丢弃遮挡点。除了上述两个缺点之外,过度遮挡会破坏插入目标的表面结构,从而在训练过程中给网络带来噪声。作者将现有的扩增策略分为三类。
GT样本增强的点云直接投影到距离图像中。
移除因遮挡而丢失过多点的插入目标。
通过删除范围图像的同一像素中的背景点,尽可能多地保持对象点。

如图1所示,为了解决上述问题,作者提出了一种上下文感知3D数据增强CA-aug。通过将激光雷达数据分为地面点和障碍点,很容易计算出目标应该放置的“有效空间”。
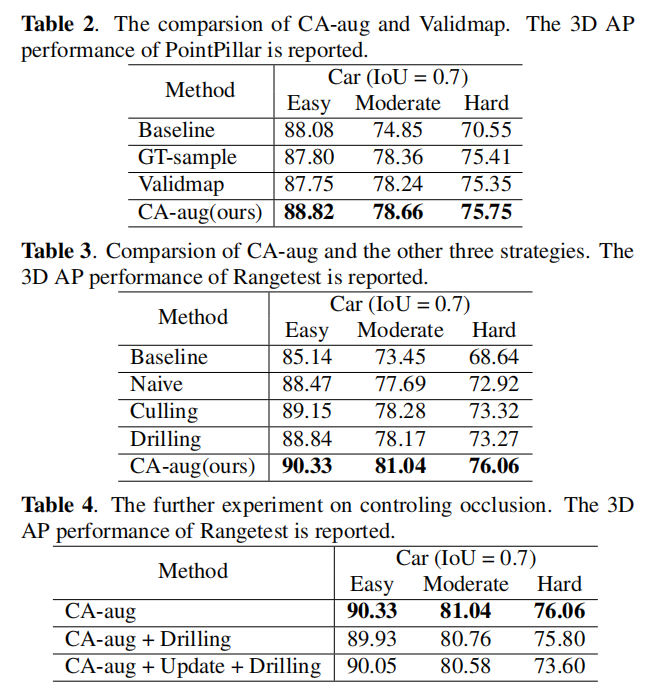
请注意,这里不是第一个尝试这样做的。Lidar-aug通过构建由许多Pillar组成的“Validmap”提出了类似的想法。在训练期间,对这些Pillar进行统一采样,并在其中随机选择对象和CAD模型的位置。然而,本文作者进一步考虑了物体的不同表面点分布。实验表明,本文的方法在提高检测精度方面优于GT样本和Lidar-aug中的类似思想。还证明CA-aug可以控制目标闭塞,并显著提高基于RV的模型的性能。
总之,这项工作的主要贡献如下:
提出了一种上下文感知目标增强方法,该方法解决了GT样本中插入样本的不合理放置问题,并显著提高了不同模型的准确性,尤其是对于行人和骑车人的检测。
研究了几乎没有人注意到的基于RV的检测器的增强。与其他方法相比,CA-aug可以充分利用基于RV的模型的潜力,并在KITTI值集中检测中度目标方面实现8%的mAP改进。
本文的算法是轻量级的,与现有的增强方法兼容。
2、方法
2.1、Overview
在场景点云中找到目标的合理位置是非常重要的,因为检测数据集中的背景点没有标记。然而,可以将这个问题简化为将目标放置在扫描线可以到达的位置。在WYSWYG中,作者使用三维体素化可见性图来记录激光束通过的区域,但这需要大量的计算和存储成本。

如图2(a)所示,提出了一种简单的方法。假设原始点云由地面点和障碍点组成,并将它们投影到距离图像中。对于每列,从底部到最近障碍点的部分是允许出现目标点的位置。所有部分构成“有效空间”,可以用矢量简单表示。如图3(b)所示,它还可以覆盖两行扫描线之间的无意义区域。

如果从“有效空间”中随机选择每个插入目标的位置,则表面点的密度和到激光雷达的距离之间的关系将被打破。因此,像Real3D Aug一样,保持原始范围,并围绕垂直z轴将目标旋转到正确位置。任务是确定每个目标的旋转角度。作者还将目标点投影到距离图像,并使用矢量“Rangebin”来描述其点模式,当围绕z轴旋转时,该模式不会改变。训练前可以计算“Validspace”和“Rangebin”。如图2(c)所示,可以从中获得每个目标的位置。对于基于RV的模型,在放置目标后应用“消隐”。
2.2、验证空间和范围的计算
受pointpillar的启发,将输入点云划分为不同的pillar。和障碍pillar,所以可以得到以下策略:
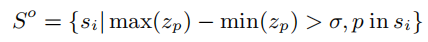
其中是p的z坐标,是第一根pillar。中的所有点都被视为障碍点。
机械激光雷达具有固定的水平和垂直角度分辨率,因此点云可以通过以下公式投影到大小为W×H的范围图像中:

2.3、目标放置
在获得“验证空间”和“测距箱”时,可以通过向量运算快速找到合理的位置。
假设插入的目标的起始列在范围图像中为。可以估计“验证空间”中的点率:
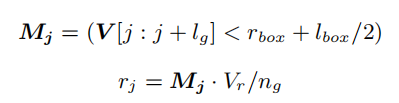
其中,为的长度,为目标点数,和为3D框的长度和距离。向量由0和1组成,它表示目标点的一个列是否在“验证空间”中。当时,认为第列对应的角度是可行的。

位置检查的详细算法见算法1。请注意,简单地将具有可行角度的增强目标添加到背景中就会导致碰撞问题,这意味着样本的三维边界框可能会相交。因此,需要引入避碰算法。假设场景中还有k个框,当添加下一个框时,根据它的4个角是否在k个框内来检查碰撞。它比计算所有box中的IoU要快。
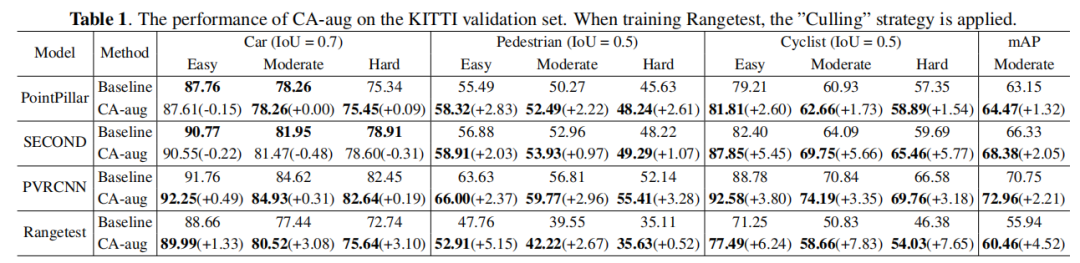
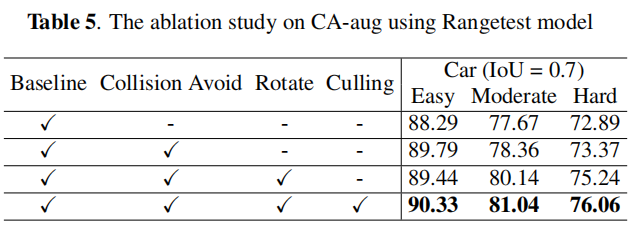
3、实验
4、参考
[1].CONTEXT-AWARE DATA AUGMENTATION FOR LIDAR 3D OBJECT DETECTION.
往期回顾
Radar-LiDAR BEV融合!RaLiBEV:恶劣天气下3D检测的不二之选

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









