






作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【深度估计】技术交流群
后台回复【深度估计综述】获取单目、双目深度估计等近5年内所有综述!
Paper: https://arxiv.org/pdf/2302.01334.pdf
Code: https://github.com/ucaszyp/STEPS
导读
自监督深度估计可以提高自动驾驶车辆的三维感知能力,从而引起了人们的广泛关注。然而,它本质上依赖于光度一致性假设(两帧之间同一个点或者patch的光度(在这里指灰度值,RGB)几乎不会有变化),这在夜间几乎不成立。虽然学术界已经提出了各种有监督的夜间图像增强方法,但它们在具有挑战性的驾驶场景中的泛化性能并不令人满意。
为此,本文提出了第一种联合学习夜间图像增强器和深度估计器的方法,两个任务均为无监督训练。论文使用一种新提出的不确定像素掩模(mask)策略紧密地耦合两个自监督任务。此外,观察到夜间图像不仅受到曝光不足的区域,而且还受到过度曝光区域的影响。通过对光照图像分布拟合桥形曲线,两个区域被抑制,因此可以自然的桥接两个任务。
最后,通过在两个主流的数据集(nuScenes和RobotCar)上进行广泛的实验,充分表明了所提方法的优异性,从而达成新 SOTA。此外,为了缓解现有数据集的稀疏标签的问题,本文还开源了一个新的基于CARLA的夜景增强数据集。
研究背景
深度估计是三维场景理解的重要组成部分。基于图像的深度估计由于硬件成本低而引起了机器人社区的广泛关注。在基于学习的深度估计方法中,使用图像序列的自监督范式非常吸引人,因为它们不需要成对的RGB-D数据,并且泛化能力较强。目前,在KITTI、Cityscapes和DDAD数据集上的自监督深度估计的性能已经可以与有监督方法相媲美。然而,这些研究都集中在白天的图像序列,其中输入数据质量都是良好的,且光度一致性假设普遍成立。自动驾驶车辆需要在夜间稳定运行,不过,光度一致性假设在这种具有挑战性的场景中很难成立。
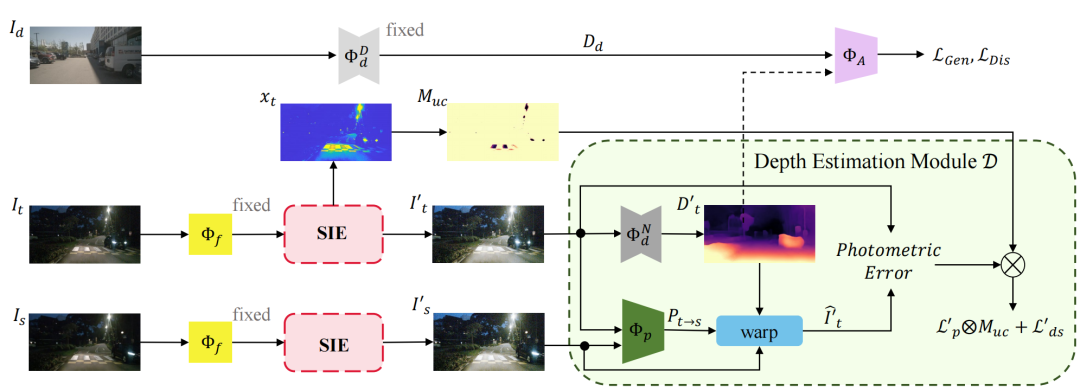
一个很自然的想法是利用夜景图像增强技术来提高输入图像的质量。但是有监督的夜间图像增强器本质上受到数据集偏差的限制,因为现有的成对昼夜数据集中于室内场景,而为动态道路场景构建这些成对数据集几乎是不可能的。
为此,本文提出了第一个以自监督的方式联合学习一个夜景增强器和一个单视图深度估计器的学习框架,如上图所示。由于这两个模块可以在没有任何ground truth 的情况下协同实现一个共同的目标,因此所提方法能够显著优于之前的SOTA方法RNW,如上图所示。
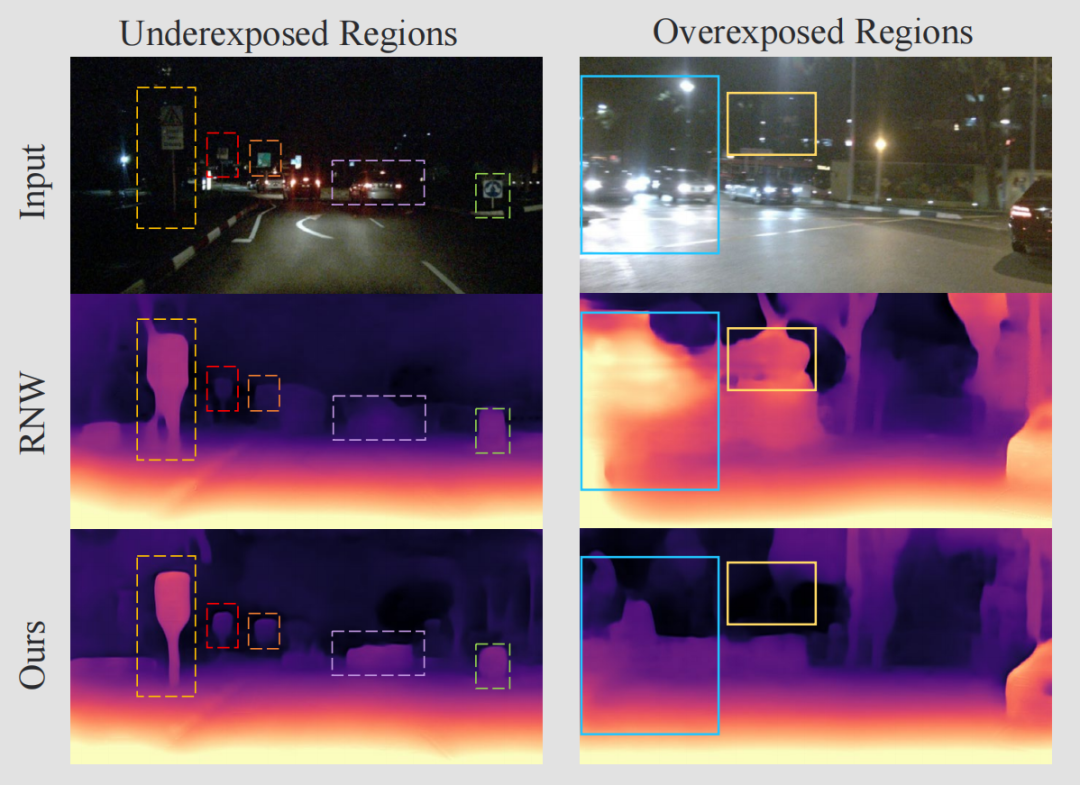
深入研究这个框架,我们还能发现一个有趣但容易被忽视的事实:夜间图像不仅受到曝光不足区域的影响,而且还受到过度曝光区域的影响,可统称为异常区域(unexpected regions)。两者都会导致一些细节信息的丢失,并阻止模型通过局部上下文线索估计准确的深度。此外,过度曝光的区域往往与汽车的运动有关(例如,汽车灯),这也违反了光度一致性原则。
通过观察图像增强的中间产物-增强比(或者说光照分量),可以发现异常区域例如曝光不足的区域需要更高的比例,反之亦然。这一观察结果促使作者设计一个建立在比率之上的不确定性地图,以抑制异常区域。为此,文本使用桥形模型紧密地连接深度估计和图像增强,进行soft mask。除此之外,论文还引入了一个预先训练过的去噪模块来进一步提高图像的信噪比。
此外,本文发现,由于激光雷达数据的限制,在评估过程中不能覆盖所有感兴趣的区域,现有的夜间驾驶数据集只有稀疏的ground truth。遵循将模拟环境中的知识转移到现实世界的想法,论文借助自动驾驶研究的模拟器CARLA。然而,渲染图像和真实世界图像之间的巨大领域差距无法直接使用模拟数据。因此,作者提出了CARLA-EPE,一个基于CARLA的图像真实性增强的夜间数据集。其利用最先进的图像真实增强网络EPE将渲染图像的风格转移到逼真的风格,从而产生一个具有密集的ground truth深度的逼真夜间数据集。从实验结果来看,论文的新数据集的任务比其他任务更具挑战性,这给该领域带来了有意义的新挑战。
贡献
本文提出了第一个联合学习夜间图像增强和深度估计的方法,而不使用任何ground truth。
论文发现自监督夜间图像增强器中的照明分量可以用于识别异常区域(unexpected regions),并提出了一个soft auto-masking的桥接模型。
提供了一个新的真实增强夜间数据集与密集的深度ground truth。
所提方法在公共基准测试中实现了SOTA的性能。
方法
Self-supervised Nighttime Depth Estimation
给定一幅图像,基于学习的深度估计的目标是通过可训练网络来预测深度图。
由于获取逐像素的深度真值获取成本很高,自监督学习迅速发展,其利用运动的连续帧预测单帧深度,其关键思想是根据几何约束,从源帧重构目标帧。 即将学习问题定义为一种新视图合成问题,通过训练一个神经网络来从另一幅图像的视角来预测目标图像。具体来说,给定一个已知的相机内参矩阵,预测的目标帧的深度图,以及通过一个可训练网络:得到的源帧和目标帧之间的相对姿态,目标帧中的每个点都可以投影到的源帧上。
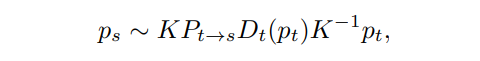
其中,表示齐次。知道了对应关系,通过线性插值,得到目标帧上每个点对应的源帧位置上的值,再将对应的值逐像素赋值到新的预测的上。
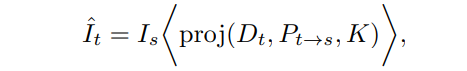
是可微双线性插值,是投影运算。训练可以表示为目标帧与重建帧之间的光度误差最小化。论文将和损失合并为光度损失,定义为:
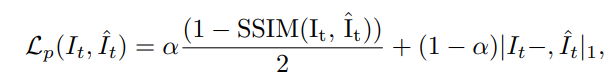
实验设置α = 0.85。此外,最小化上式只能强制执行一个必要条件,而不是充分条件。因此,论文通过加强预测的深度图的平滑性来避免深度模糊,即:
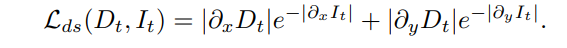
由于夜间图像质量较差,按照上面的训练方法只能提供带噪声的梯度。为了缓解这种情况,论文引入了一个预训练的日间深度估计模型,然后通过对抗性训练指导夜间模型训练。论文建立了一个夜间深度估计网络作为生成器,目的是使其预测与难以区分,是一个预先训练和固定的日间深度估计网络的输出。基于patch-gan的鉴别器是一个可训练的区分和的网络。和通过最小化基于gan的损失函数进行训练,其公式为:

其中和是白天和夜间训练图像的数量,和。
Joint Training Framework
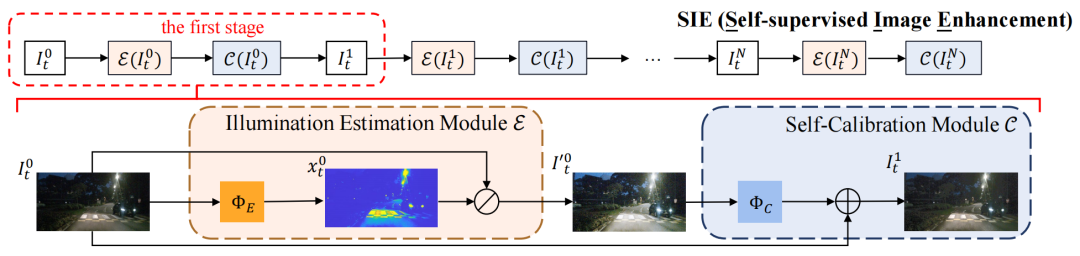
如前所述,夜间图像增强可以提高输入图像的质量,以帮助进行深度估计。但是有监督的夜间图像增强子在本质上受到数据集偏差的限制。因此,论文提出了一个以自监督的方式联合训练深度估计和图像增强(SIE)的框架,如上图所示。
根据Retinex理论,给定一个弱光图像,通过可以得到增强图像,其中是光照度图,这是图像增强中最重要的部分。一个不准确的光照估计可能会导致过度增强的结果。为了提高性能稳定性和减少计算负担,论文采用SCI[1]的自校准模块结构进行级联照明学习,如上图所示。增强过程是由:
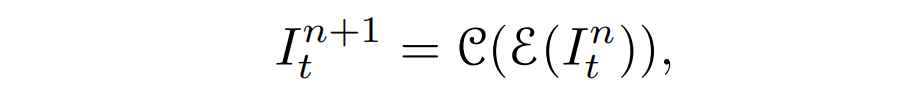
其中,为阶段,和分别表示光照估计和校准模块。对于阶段n,和分别表示为:
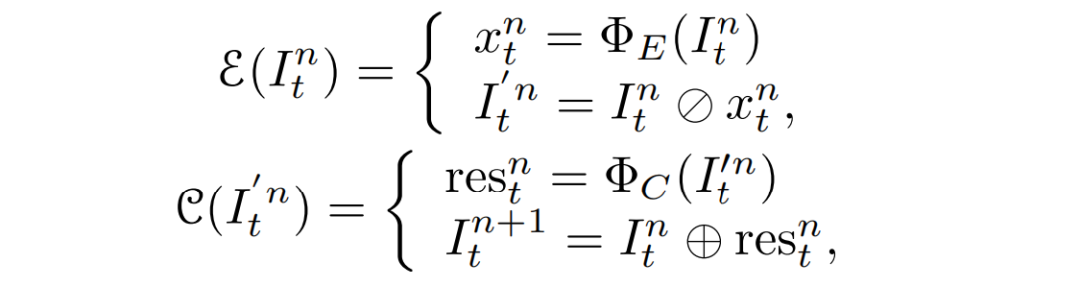
其中,和分别为估计光照和生成校准的残差图的可训练网络。和在每个阶段中共享相同的参数。该校准模块重新生成一个伪夜间图像,使SIE可以应用于几个阶段,通过经验校准可以带来更快的收敛速度和更好的增强效果。增强损失包含保真度和平滑度损失,公式为:
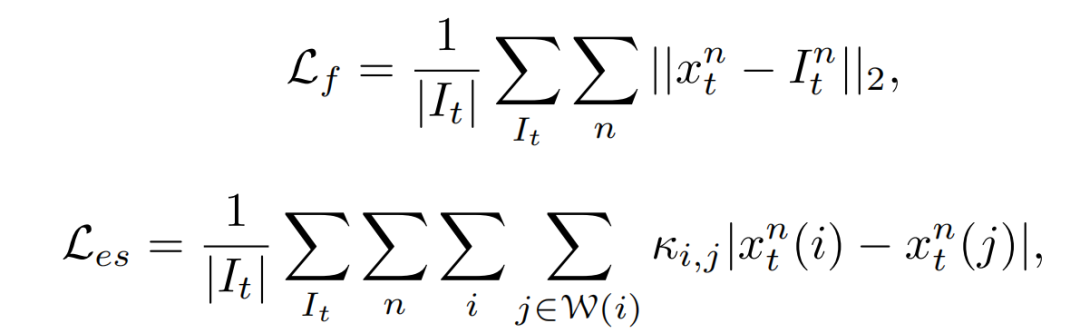
其中κ是一个高斯核的权值,是一个以i为中心的5×5窗口,表示x在i处的像素值。保真度损失的思想是,对于夜间图像,估计光照和每个阶段输入的像素一致性。平滑损失是一个一致性正则化损失。
增强后的夜间图输入自监督深度估计模块中进行联合训练。
Statistics-Based Pixel-wise Uncertainty Mask
夜间的图像通常包含过度曝光或曝光不足的区域,其中重要的细节将会丢失。它极大地阻碍了模型通过局部上下文线索来预测准确的深度。此外,过曝的区域往往与汽车的运动有关(例如,汽车灯),这也违反了光照一致性假设。因此,论文需要设计一种特定的机制来绕过这些区域。Monodepth2的成功表明,掩码策略是一种简单而有效的方法来过滤出不符合光度一致性假设的区域。
论文使用了一个图像增强模块SIE。它可以预测一个光照图来确定每个像素的颜色的增强比。该比例在曝光不足的区域往往较大,而在过暴的区域则较小。论文定义了一个不确定性映射,它对异常区域置信度低,对正常区域置信度高。是建立在光照图之上的,被表述为:

其中,和是用来滤波光照合理区域的基于统计量的边界,和是衰减系数。直观地看,这个函数就像一个如下图所示的桥。
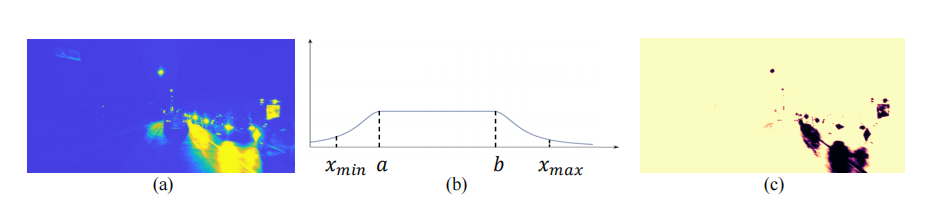
Image Denoising
图像去噪是夜间深度估计的另一个有用的组成部分,因为传感器在夜景中捕获的低光图像包含更多的噪声。特别是在弱光图像增强后,噪声不可避免地被放大。它可能会影响训练,因为它进一步破坏了相邻帧之间的照明一致性。论文使用一个在SIDD 数据集上预先训练过的网络AP-BSN模型进行去噪。为了减少训练负担,在训练过程中固定了去噪网络AP-BSN的参数。
Full Pipeline
综上所述,对于SIE模块,总损失为:
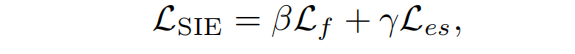
对于深度估计模块,总损失$L_{DE}为:
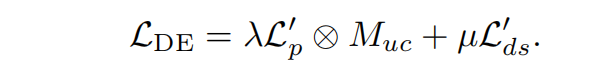
整个pipeline的总损失被定义为:
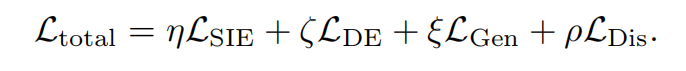
实验
数据集
CARLA-EPE
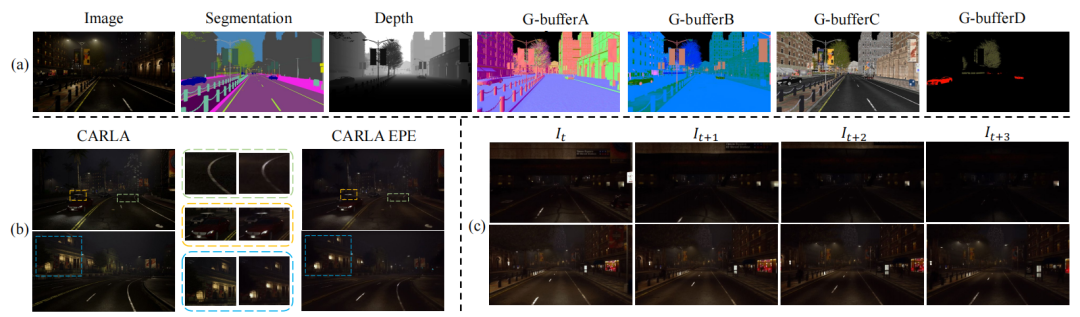
现有的道路场景深度估计数据集利用激光雷达获取地面真实深度,只能生成稀疏深度图,需要较高的成本。稀疏的ground truth可能不能揭示深度估计方法的整体性能。虽然RGB图像和相应的密集深度图可以很容易地针对性地在仿真器中采集(如CARLA),但仿真图像和真实图像之间的域差距极大地影响了训练模型在真实场景中的泛化。因此,论文提出了一个基于CARLA和图像逼真增强(EPE)网络的夜间深度估计数据集,可以提供密集的深度ground truth和逼真图像。具体过程如下:
使用CARLA捕获渲染图像以及中间渲染缓冲((G-buffers),其中包含几何、材料和运动信息,如上图a所示。
找到生成数据集和DarkZurich之间的匹配,由DANNet预测的语义标签
训练了EPE网络,将生成图像风格迁移到DarkZurich的现实风格上。
结果
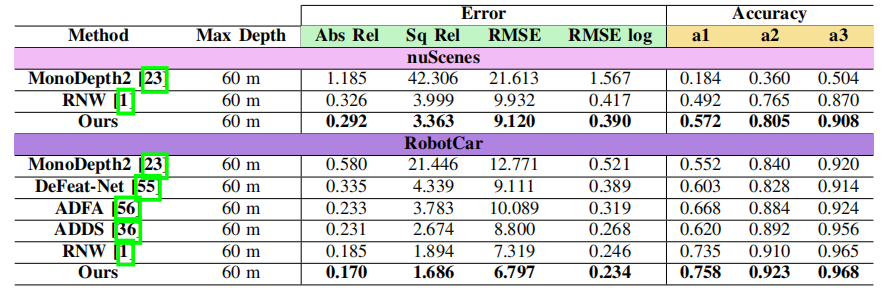
上表显示在nuScenes和RobotCar数据集上,本文与MonoDepth2,DeFeat-Net,ADFA,ADDS和RNW的对比结果。总的来说,论文的方法在两个数据集上的所有指标取得了SOTA。
对nuScenes数据集的改进更有研究意义,因为过曝和曝光不足的区域在其场景中普遍存在,而且图像更嘈杂。这与论文的方法的理论预期很一致。

上图显示论文的方法可以在异常区域预测更合理的深度,并捕捉到夜间图像中小物体或移动物体(如灯柱和汽车)的正确边界。此外,模型在一块2080Ti上达到25FPS的推理速度。
消融实验
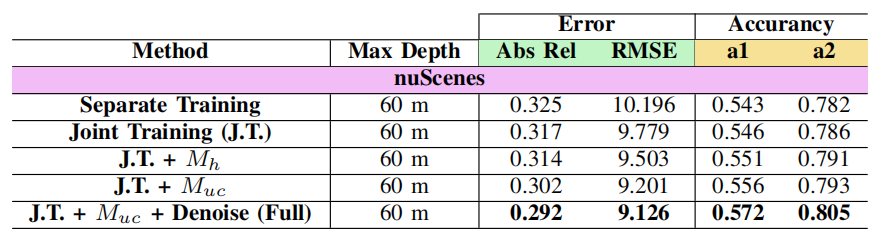
上图是各个组件的消融实验结果。
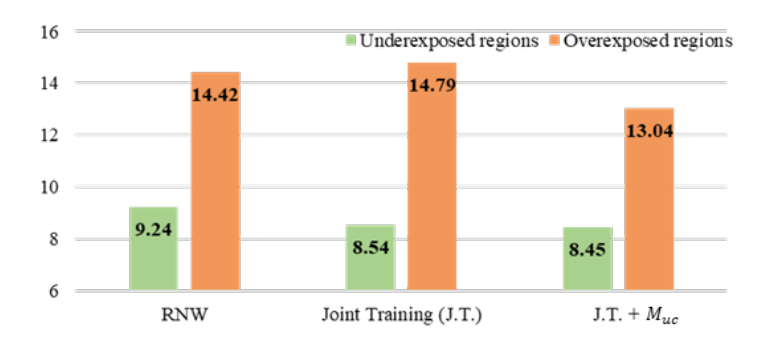
上图显示了掩码策略在过暴区域的有效性。
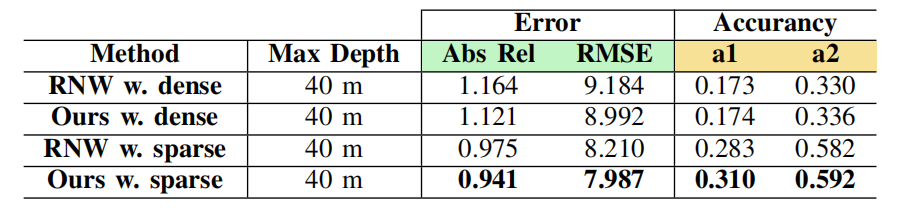
上图显示了带有密集ground truth的CARLA-EPE数据集的有效性。
总结
本文提出了一个自监督框架来联合学习图像增强和深度估计,通过找到一个有效的图像增强的中间产物(光照图)以生成一个像素级掩模来抑制过曝和欠曝区域。受益于这些改进,所提方法在公共夜间深度估计 Benchmark上取得了新 SOTA。此外,论文还开源了一个新的带有密集深度标签的夜间数据集。代码已开源,欢迎大家尝试!
References
[1]
Toward fast, flexible, and robust low-light image enhancement: https://arxiv.org/abs/2204.10137
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









