






作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
导读
受 Inception 的启发,本文作者提出将大 Kernel 的 Depth-Wise 卷积沿 channel 维度分解为四个并行分支。本文提出了 IncepitonNeXt,InceptionNeXt-T 的训练吞吐量比 ConvNeXt-T 高1.6倍,在 ImageNet-1K 上的 top-1 精度提高了 0.2%。
本文目录
1 InceptionNeXt: 当 Inception 遇上 ConvNeXt
(来自 NUS, Sea AI Lab)
1 InceptionNeXt 论文解读
1.1 背景和动机
1.2 MetaNeXt 架构
1.3 Inception Depthwise Convolution
1.4 InceptionNeXt 模型
1.5 实验结果
太长不看版
受 Vision Transformer 长距离依赖关系建模能力的启发,最近一些视觉模型开始上大 Kernel 的 Depth-Wise 卷积,比如一篇出色的工作 ConvNeXt。虽然这种 Depth-Wise 的算子只消耗少量的 FLOPs,但由于高昂的内存访问成本 (memory access cost),在高性能的计算设备上会损害模型的效率。举例来说,ConvNeXt-T 和 ResNet-50 的 FLOPs 相似,但是在 A100 GPU 上进行全精度训练时,只能达到 60% 的吞吐量。
针对这个问题,一种提高速度的方法是减小 Kernel 的大小,但是会导致显著的性能下降。目前还不清楚如何在保持基于大 Kernel 的 CNN 模型性能的同时加速。
为了解决这个问题,受 Inception 的启发,本文作者提出将大 Kernel 的 Depth-Wise 卷积沿 channel 维度分解为四个并行分支,即小的矩形卷积核:两个正交的带状卷积核和一个恒等映射。通过这种新的 Inception Depth-Wise 卷积,作者构建了一系列网络,称为 IncepitonNeXt,这些网络不仅具有高吞吐量,而且还保持了具有竞争力的性能。例如,InceptionNeXt-T 的训练吞吐量比 ConvNeXt-T 高1.6倍,在 ImageNet-1K 上的 top-1 精度提高了 0.2%。
本文的目标不是扩大卷积核。相反,本文以效率为目标,在保持相当的性能的前提下,以简单和速度友好的方式分解大卷积核。
1 InceptionNeXt: 当 Inception 遇上 ConvNeXt
论文名称:InceptionNeXt: When Inception Meets ConvNeXt
论文地址:
https://arxiv.org/pdf/2303.16900.pdf
1.1 背景和动机
回顾深度学习的历史,卷积神经网络 (CNN) 无疑是计算机视觉中最受欢迎的模型。2012年,AlexNet 在 ImageNet 竞赛中获胜,开启了 CNN 在深度学习特别是计算机视觉领域的新时代。从那时起,众多的 CNN 已经成为潮流的引领者,如 Network In Network,VGG,Inception Nets,ResNe(X)t,DenseNet 等。
受 Transformer 在 NLP 中成就的影响,研究人员尝试将其模块或块集成到视觉 CNN 模型里面,比如 Non-local Neural Networks 和 DETR。此外,Image GPT (iGPT)[1]受语言生成预训练的启发,将像素视为 token,并采用纯Transformer 进行视觉自监督学习。然而,由于将像素视为 token 导致的计算成本太高,iGPT 处理高分辨率图像的能力也受限。
ViT 开创性地解决了这个问题,通过将图片 Patch 视为 token,并提出了一个简单的 patch embedding 模块来生成 input 的 Embedding。ViT 利用一个纯 Transformer 模型作为图像分类的 Backbone,在经过了大规模监督图像预训练后得到了惊人的表现。而且,ViT 进一步点燃了 Transformer 在计算机视觉中的应用热情。许多 ViT 变体,如 DeiT 和 Swin,在多种视觉任务中取得了显著的性能。类 ViT 模型优于传统 CNN 的性能 (Swin-T 81.2% ImageNet-1K v.s.ResNet-50 76.1% ImageNet-1K) 使得许多研究者相信 Transformer 最终将取代 CNN 并统治计算机视觉领域。
CNN 是时候反击了!通过引入 DeiT 和 Swin 中先进的训练技术,ResNet strikes back 这个工作表明,ResNet-50 的性能可以提高 2.3%,达到 78.4%。此外,ConvNeXt 表明,使用像 GELU 激活函数这样的现代模块和类似于注意力窗口大小的大 Kernel,CNN 模型在各种设置和任务中可以稳定地优于 Swin Transformer。ConvNeXt 为代表的现代 CNN 模型中,共同的关键特征是接受野较大,且使用了 Depthwise Convolution 获得。
尽管 Depthwise Convolution 的 FLOPs 很小,但是它实际上是一个“昂贵的”运算符,因为它带来了很高的内存访问成本 (memory access cost),这个问题使它成为了计算密集型设备的瓶颈。如下图1所示,尽管 FLOPs 相似,但是 Kernel Size 为 7×7 大小的 ConvNeXt-T 比 3×3 的 ConvNeXt-T 慢1.4倍,比 ResNet-50 慢1.8倍。如果强行把 Kernel Size 减掉,会导致性能下降。比如与 ConvNeXt-T/k7 相比,ConvNeXt-T/k3 在 ImageNet-1K 数据集上的 top-1 精度下降了 0.6%。
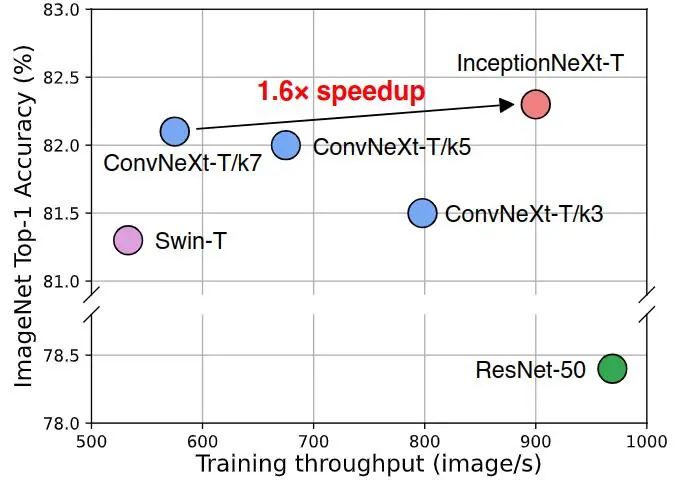
目前还不清楚如何在保持大 Kernel CNN 性能的同时加速它们。本文最初的发现表明,并不是所有的输入通道都需要经历计算成本高昂的 Depth-wise Convolution 运算。因此,作者提出保留部分信道不变,只对部分信道进行深度卷积运算。首先对大核进行分解,分成几组小的卷积核。1/3 的通道以 3×3 为核,1/3 的通道以 1×k 为核,剩下的 1/3 的通道以 k×1 为核。这个新的简单,廉价的运算符称为 Inception Depthwise Convolution,基于它构建的模型 InceptionNeXt 在精度和速度之间实现了更好的平衡。比如 InceptionNeXt-T 获得了比 ConvNeXt-T 更高的精度,同时享受了类似于 ResNet-50 的1.6倍训练吞吐量提升。
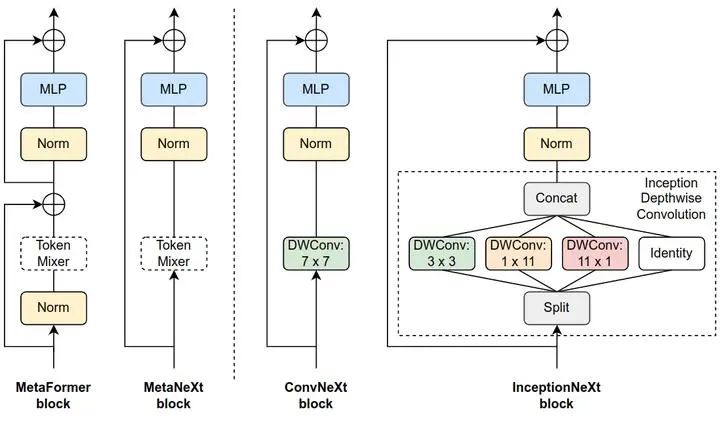
1.2 MetaNeXt 架构
MetaNeXt 是一种对于 ConvNeXt 的抽象架构。在一个 MetaNeXt Block 中,输入 首先这样操作:

式中,,分别代表 Batch size,通道数,高和宽。然后以上的输出进行归一化操作:

经过归一化后,将得到的特征输入到由两个全连接层组成的 MLP 模块中,两层之间夹有 GELU 激活函数,与 Transformer 中的 FFN 相同。两个全连接层也可以通过 1×1 卷积实现。同时采用 Short-cut 连接:

和 MetaFormer 对比
如上图2所示,可以发现 MetaNeXt 块与 MetaFormer 块共享类似的模块,例如 token mixer 和 MLP。然而,这两种模型之间的关键区别在于 Shortcut 的数量。MetaNeXt 是一种单残差的架构,而 MetaFormer 是一种双残差的架构。从这个角度来看,MetaNeXt 块可以看作是把 MetaFormer 的两个 Sub-Block 进行合并,以简化整体架构。因此,与 MetaFormer 相比,MetaNeXt 体系结构的速度更快。但是,这种更简单的设计有一个限制,即:MetaNeXt 中的 token mixer 不能太复杂,比如把 ConvNeXt 中的 Depthwise Convolution 换成 Attention 以后,作者发现精度掉到了 3.9%。
1.3 Inception Depthwise Convolution
针对传统的大 Kernel Depthwise Convolution 阻碍模型速度的问题, 本文提出了 Inception Depthwise Convolution。Inception 这个模型利用了小 Kernel (如 和大 Kernel (如 5×5) 的几 个分支。同样地, Inception Depthwise Convolution 采用了 作为基本分支之一, 但避免了大 的矩形 Kernel, 因为它们的实际速度较慢。大的 矩形 Kernel 被分解为 和 。
对于输入 , 首先沿着 channel 的维度分为 4 个 group:
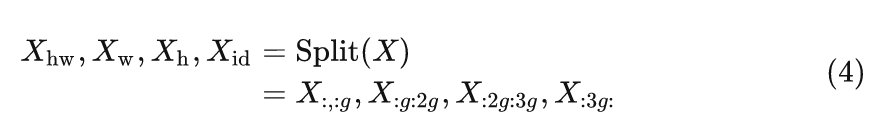
然后,这4个特征分别通过4个不同的算子:
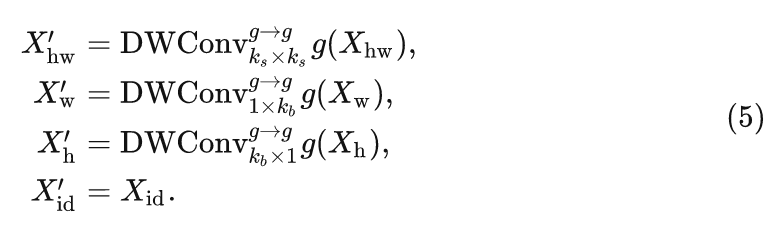
其中, 表示默认设置为3的小矩形 Kernel 大小, 表示默认设置为11的大 Kernel 大小。最后, 每个分支的输出被拼接起来:
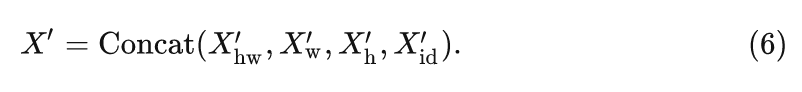
以上过程的 PyTorch 伪代码如下:
import torch.nn as nn
class InceptionDWConv2d(nn.Module):
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=11, branch_ratio=1/8):
super().__init__()
gc = int(in_channels * branch_ratio) # channel number of a convolution branch
self.dwconv_hw = nn.Conv2d(gc, gc, square_kernel_size, padding=square_kernel_size//2, groups=gc)
self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size//2), groups=gc)
self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size//2, 0), groups=gc)
self.split_indexes = (gc, gc, gc, in_channels - 3 * gc)
def forward(self, x):
# B, C, H, W = x.shape
x_hw, x_w, x_h, x_id = torch.split(x, self.split_indexes, dim=1)
return torch.cat(
(self.dwconv_hw(x_hw),
self.dwconv_w(x_w),
self.dwconv_h(x_h),
x_id),
dim=1)Inception Depthwise Convolution 和其他几种算子的计算复杂度比较如下图3所示。可以看出,比普通卷积的效率要高得多。

1.4 InceptionNeXt 模型
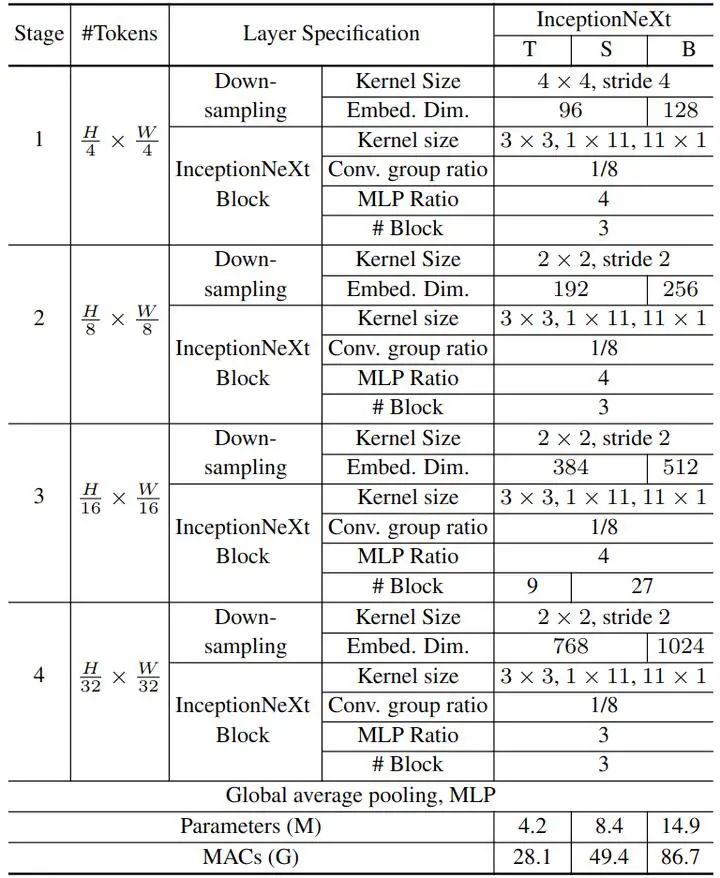
基于 InceptionNeXt Block,作者构建了一系列 InceptionNeXt 模型。与 ResNet 和 ConvNeXt 类似,InceptionNeXt 也采用了4 Stage 的模型框架。InceptionNeXt 采用 Batch Normalization,因为强调推理速度。与 ConvNeXt 的另一个不同之处在于,InceptionNeXt 在 Stage 4 的 MLP 模块中使用的 Expansion Ratio 为3,并将保存的参数移动到分类器中,这可以帮助减少一些计算量。不同大小的 InceptionNeXt 模型的参数配置如下图4所示。
1.5 实验结果
ImageNet-1K 图像分类
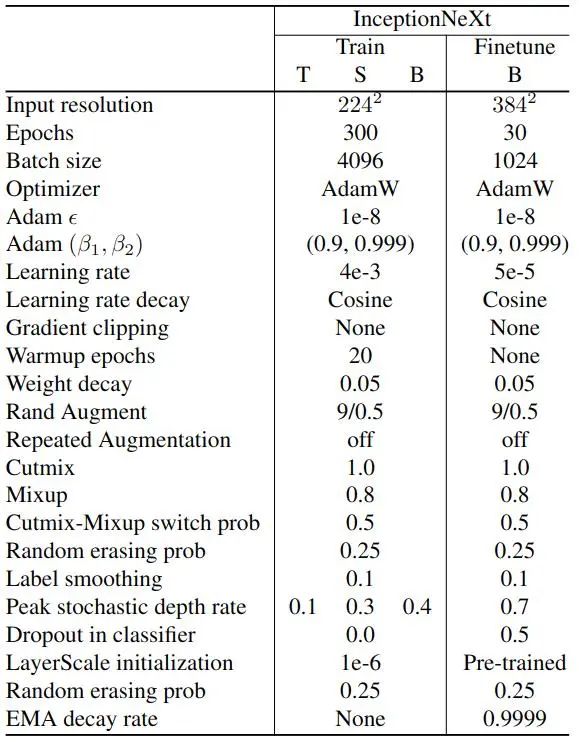
评价视觉基础模型的重要指标之一是 ImageNet-1K 直接训练的图像分类结果。InceptionNeXt 使用的超参数如下图5所示,实验结果如图6所示。数据增强的方式依然包括:random resized crop, horizontal flip, RandAugment, Mixup, CutMix, Random Erasing 和 color jitter。正则化的方式依然包括:label smoothing, stochastic depth, 和 weight decay。

作者将 InceptionNeXt 与各种最先进的模型进行比较,包括基于注意力的模型和基于卷积的模型。从图6中可以看出,InceptionNeXt 不仅具有较高的竞争性能,而且具有较高的速度。例如,InceptionNeXt-T 不仅比 ConvNeXtT 高出 0.2%,而且训练/推理吞吐量也比 ConvNeXts 高 1.6×/1.2×,与 ResNet-50 相似。也就是说,InceptionNeXt-T 既享有 ResNet-50 的速度,又享有 ConvNeXt-T 的精度。
同样作者也遵循 ConvNeXt 的做法做了一些直筒架构的模型,实验结果如下图7所示。实验结果如下图7所示。可以看到,在直筒形状的架构下,InceptionNeXt 也可以表现得很好,证明了 InceptionNeXt 在不同的框架之间表现出良好的泛化性能。值得注意的是,把 ConvNeXt 中的 Depthwise Convolution 换成 Attention 以后,得到的 MetaNeXt-Attn 无法训练收敛,仅达到 3.9% 的精度。这个结果表明,与 MetaFormer 中的 token mixer 不同,MetaNeXt 中的令牌混合器不能太复杂。

ADK20K 语义分割
作者使用 ImageNet-1K 预训练的权重,使用 UperNet 作为分割头,使用 AdamW 优化器训练模型,学习率为 6e-5,Batch Size 大小为16,迭代次数为 160K。使用 Semantic FPN 作为分割头,Batch Size 大小为32,迭代次数为 40K。实验结果如图8和图9所示。
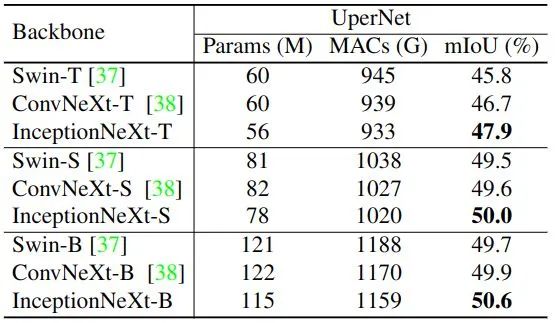
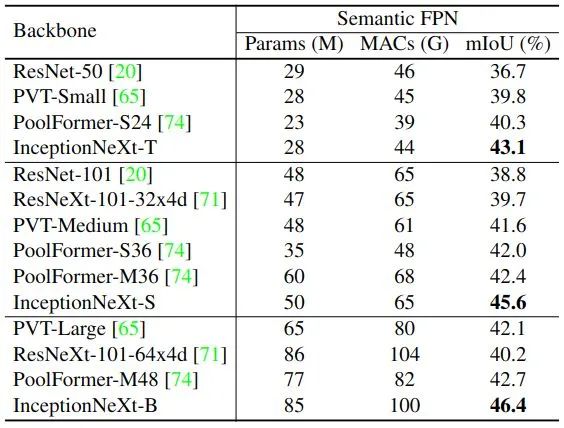
对于以 UperNet 为分割头的实验结果,可以看出,在不同的模型尺寸下,InceptionNeXt 的性能始终优于 Swin 和ConvNeXt。对于以 Semantic FPN 为分割头的实验结果,可以看出,在不同的模型尺寸下,InceptionNeXt 的性能始终优于 PVT 和 PoolFormer。这些结果表明,InceptionNeXt 对于密集预测任务也有很高的潜力。
总结
本文认为在一个卷积视觉模型中,并不是所有的输入通道都需要经历计算成本高昂的 Depth-wise Convolution 运算。因此,作者提出保留部分信道不变,只对部分信道进行深度卷积运算。首先对大核进行分解,分成几组晓得卷积核。1/3 的通道以 3×3 为核,1/3 的通道以 1×k 为核,剩下的 1/3 的通道以 k×1 为核。这个新的方式称为 Inception Depthwise Convolution,基于它构建的模型 InceptionNeXt 在精度和速度之间实现了更好的平衡。比如 InceptionNeXt-T 获得了比 ConvNeXt-T 更高的精度,同时享受了类似于 ResNet-50 的1.6倍训练吞吐量提升。
参考
^Generative Pretraining From Pixels
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









