






作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【SLAM】技术交流群
后台回复【SLAM综述】获取视觉SLAM、激光SLAM、RGBD-SLAM等多篇综述!


Paper: https://arxiv.org/pdf/2109.03462.pdf
Paper: https://lamor.fer.hr/images/50036607/2022-cvisic-calib-ras.pdf
序言
SOFT2是KITTI里程计数据集benchmark的SOTA方案,超过长期霸榜的V-LOAM。接下来我们分三篇文章介绍下该工作。
导读
这篇论文的主要研究内容是对KITTI双目数据集进行重新标定,以提高里程计精度。KITTI数据集是一个广受欢迎的机器人和自动驾驶数据集,该数据集由德国卡尔斯鲁厄理工学院收集和发布。论文对KITTI里程计数据集中相机的标定结果进行了重新评估,发现存在一些问题,并使用新的标定方法重新标定了相机。通过相关实验,研究人员证明了新的标定方法既可以得到较低的重投影误差,也可以显著提高里程计精度。
作者进行了相关实验,针对三种不同的视觉里程计算法:SOFT2,ORB-SLAM2和VISO2,使用KITTI的kitti metric(一种针对室外自动驾驶里程计精度的评价指标,即相对位姿误差)进行评估。结合本论文提出的新的标定方法,可以显著提高三种里程计的精度。此外,作者提出的SOFT2结合本文提出的标定方法在KITTI排行榜上达到了SOTA,平移误差为0.53%,旋转误差为0.0009度/米,甚至超过了基于3D激光的里程计。
研究背景
移动机器人和车辆的自主操作需要处理来自不同传感器组合的信号。这些传感器组合可能包括图像传感器,如彩色、灰度、鱼眼或热成像相机;测距传感器,如声纳、雷达和激光以及主观传感器,如惯性导航系统与GNSS相结合。为了使这些传感器正常工作,需要进行精确的外参标定,即确定所有传感器与机器人或车辆框架之间的相对姿态。
与测距传感器不同,单个图像相机采用小孔成像原理,成像过程中会丢失深度信息,缺失的深度可以通过增加一个或多个相机进行利用三角测量的原理进行立体重建来得到。在这种情况下,精确的相机之间的标定就是必须的,因为它会直接影响估计深度的精度。这些深度信息后来可以被各种算法,如视觉里程计和SLAM。
常见的标定方法是张氏标定方法,该方法基于针孔相机模型,可以标定相机的内参,不同镜头的畸变参数,也可以标定双目相机之间的外参。标定通常使用已知的pattern比如棋盘格,因为它便于检测显著特征,比如角点。并通过已知的内角距离(每个格子的宽度)还可以解决尺度模糊。重投影误差,即图像中检测到角点和重建的3D空间点再投影的到图像上的点之间的距离度量,可以作为标定方法的优化度量。为了达到最佳的结果,角点需要具有亚像素精度,因此角点检测在标定算法中起着重要作用。作者认为现有的角点检测方法精度不够高。
近年来一系列视觉里程计和SLAM的公开数据集不断提出,用来评估不同的算法。例如KITTI,Málaga Ubran,EuRoc等等。无论什么数据都需要进行标定。其中KITTI数据集既提供相机的标定参数,同时也提供了标定数据供研究者自己进行标定。因此,自2012年起,KITTI数据集一直作为自动驾驶的里程计和SLAM的benchmark。
贡献
本文提出了一种新的KITTI相机标定方法。不是直接检测角点,而是通过RANSAC检测线段,然后通过线段的交点以亚像素精度计算精确的角点位置。重投影误差比其他方法和OpenCV中的方法更小。
本文测试了三种不同的视觉里程计:SOFT2、ORB-SLAM2和VISO2。这三种方法使用本文提出的标定方法进行标定后都显示出更高的精度。SOFT2与结合该标定方法成为目前KITTI benchmark上的SOTA。
方法
默认的KITTI标定方法
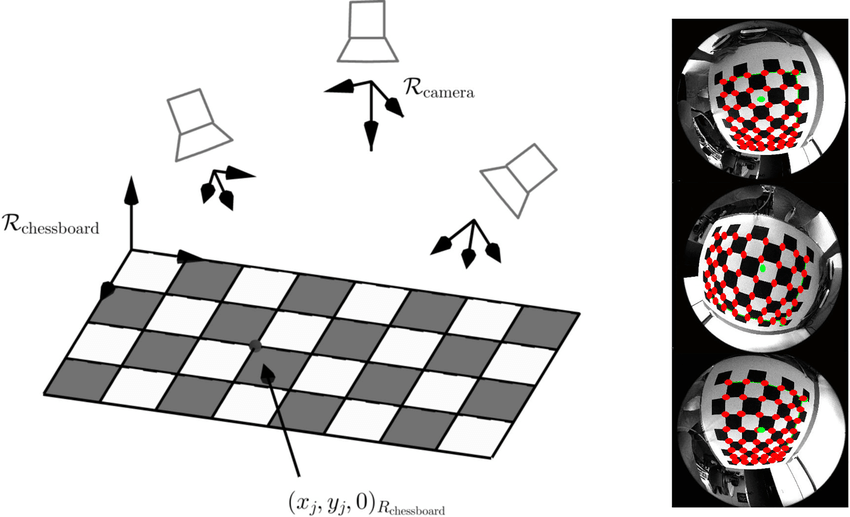

如上图所示,传统的相机标定方法是对用一个标定板拍摄多张图像进行标定,标定板具有已知尺寸的图案,如棋盘格。图像应该在不同的方向和距离上拍摄板,并且板姿态的多样性越大,对相机模型的优化约束就越大。
而KITTI的标定是用多个标定板,每个拍摄单张图像进行标定,这对于大量数据的重复标定来说非常方便(不需要反复移动相机)但它也有几个缺点:
为了视角中包含12块板,板相对于相机距离较远,信噪比低。不如近距单块板,因为它占据大部分图像,能够获得高信噪比的约束。
距离远导致所有的正方形相对较小,并且板方向有偏差(所有板都向图像中心倾斜),导致角点位置不确定性更高。
图像大部分没有被棋盘格覆盖,整张图容易被标准的标定方法的precheck给滤除(不好进行标定采集有效性判断)


KITTI的标定使用的是常见的径向-切向畸变模型,现有的方法[1]使用模板匹配的方法定位角点。首先定义了两种角点模板,一种用于和坐标轴平行的角点(上图a),另一种用于旋转45°的角点(上图b),使用一类角点原型4个滤波器核(角点模板)进行图像卷积,再通过非极大值抑制过滤一些噪声点。根据实践经验可以发现,这两种简单的原型对于由透视变换引起的较大范围的变形的角点检测来说,已经足够。本质上,任何检测方法都可以使用,只要它能够检测到棋盘格所有的角点
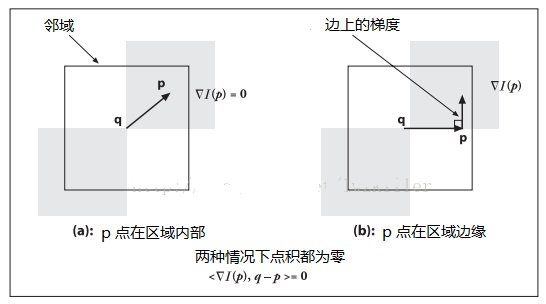
但是标定参数对角点位置的变化非常敏感,在优化过程之前拥有准确的角点位置是至关重要的,因此角点位置需要进行亚像素细化。KITTI的亚像素细化基于一个简单的思想:如上图所示,在角位置(下式的),其相邻像素的图像梯度应该近似与正交,从而的得到一个最小二乘优化问题: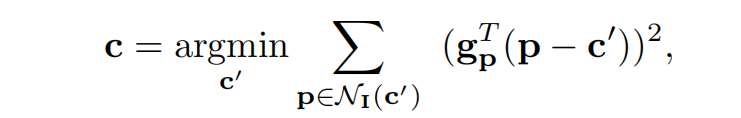 求解得到:
求解得到: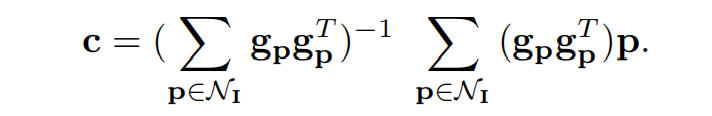
KITTI直接调用的是libcbdetect和opencv来求解这个优化问题。但是在实际标定过程中,很难达到最佳的效果。原因可能有几个:
光线的非漫反射性质导致某些板存在过曝(白色的格子显的比黑色格子大),同时也导致角点的对角边不在同一条直线上
所有标定板都离相机比较远,导致格子很小,边长只有6-20个像素,这会导致邻域的信噪比降低。这就限制了亚像素角点检测的准确性,自然也限制了标定的精度。
本文方法
在本节中,我们提出了我们的新的双目对齐标定方法。与默认的KITTI方法和OpenCV的方法相比,重投影误差更小。我们首先描述如何检测角点和位置亚像素细化,然后是匹配和优化棋盘格位置。最后,使用网格搜索对24个标定参数中的4个进行细化,以获得最终值,以提高三种测试的视觉里程计算法的精度。
角点检测及优化
与默认的KIITI检测方式直接检测角点不同,本文通过检测边的交点来定义角点。
检测边缘。通过一个鲁棒的Canny算子进行边缘检测。将图像转换为浮点数形式,减少图像损失,用5×5像素的高斯滤波器对图像进行平滑,用Sobel算子进行卷积,产生水平和垂直方向的图像导数。由此,可以确定边缘的梯度和方向。由此,可以确定边缘的梯度和方向,得到梯度图像
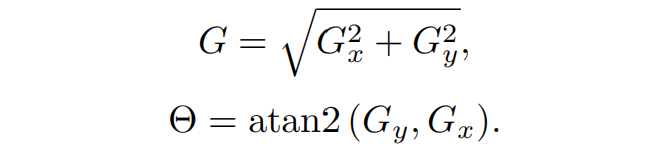
边滤波和分类。梯度图像先经过一个绝对值抑制然后再经过非极大值抑制进行过滤,滤波以后。滤波以后的得到的边根据梯度方向划分边的类别: 水平正、水平负、垂直正和垂直负, 正负指的是对应边方向的是从黑块指向白块还是白块指向黑块。检测效果如下图所示:

初始角点。寻找不同的四种类型的边的末端连接来得到交点作为检测到的角点。为了减少离群值的数量,只连接长度相似的段,在创建到相邻段的连接图后,对板进行重建。
角点精细化。每个角点由两条线的交点得到,为了进一步细化交点,对上面直接连接线段端点的方式进行改进。对两个水平方向的线段进行拟合得到水平方向的线,对两个垂直方向上的线段进行拟合得到垂直方向的线,对于每条线,使用RANSAC程序来抑制异常值:如果原来的线段点到该线的距离都低于阈值,并且梯度方向在一定的角度公差内垂直于拟合直线,则作为内点。计算两条线方程后,精确的角点位置被计算为这两条线的交点。

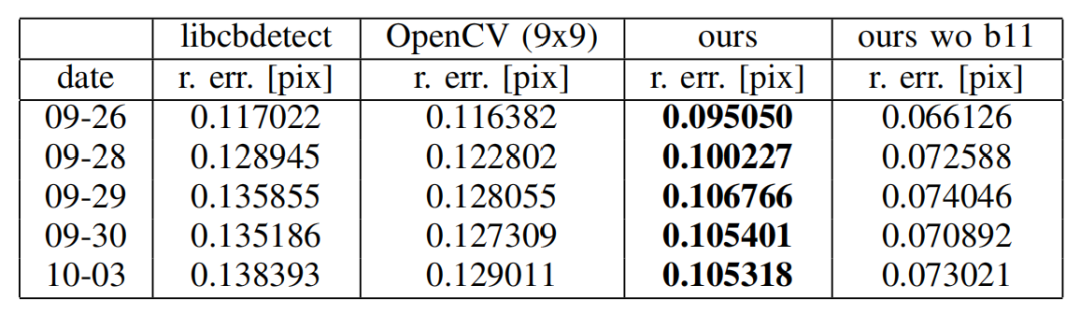
上图显示了本文提出的线交点方法和libcbdetect方法的重投影误差向量得到对比结果。其中红色向量代表重投影误差。libcbdetect检测比所提出的线交点的噪声更大,所提方法具有非常均匀的网格和最小的噪声。
上表显示了所提出的方法比libcbdetect检测和OpenCV的方法具有更小的重投影误差。剩余的约0.1像素的重投影误差是系统误差造成的,不能用更精确的角检测来解决。例如,板11(上图右边倒数第二块)因为比较长而被扭曲,并靠在墙上。因此,在现实中它不是一个平面,将一个平面模型拟合会引入比其他板大得多的误差。作为参考,我们还在上表的最后一列中去除该板进行测试,结果重投影误差显著降低。我们认为剩余的重投影误差来自于径向切向畸变模型与真实透镜的畸变函数之间的差异。
标定板匹配解码和优化
此处就是棋盘格解码,计算内外参的过程:
每个相机产生总共 9 个内参(fx , fy , cu , cv , k 1 , k 2 , k 3 , k 4 , k 5 ),即焦距,主点和镜头畸变参数,以及每个相机的6个外部参
我们使用接近默认 KITTI 标定结果的值初始化焦距,同时将主点和畸变参数设置为零。通过棋盘格初始坐标到图像检测角点的单应性来初始化外参。最后,使用 Levenberg-Marquard 算法最小化重投影误差来优化。
标定参数细化
前面的方法是我们获得了更加准确的标定结果,但结果仍然低于预期。考虑到这一点,我们决定细化24个标定参数的中的4个(左相机焦距、主点和基线距离),因为实验证明标定板的设置并没有为这四个参数带来强烈的约束。
我们通过将参数固定为某个特定来进行灵敏度分析(固定该参数对于结果的影响),然后进行标定优化:
左相机焦距和主点
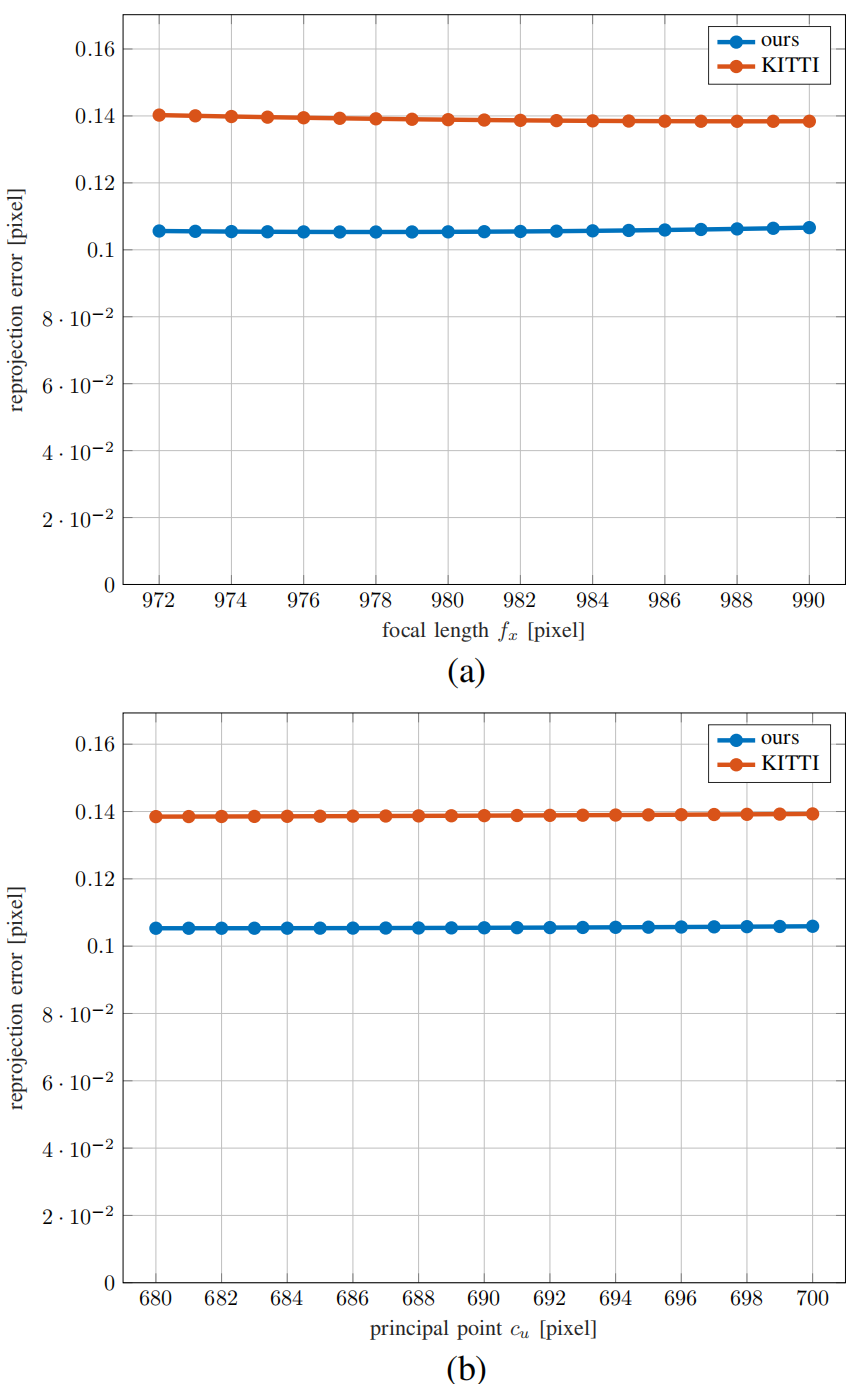
参数在初始最小值附近采样,左右各一个像素步长,实验证明,虽然焦距和主点的变化显着影响测距精度,但对重投影误差的影响却很小,如上图所示。重投影误差曲线相对于焦距和主点几乎是平坦的。距离最小点10像素的值的误差略小于0.001像素,低于我们估计的系统噪声约0.03像素。我们的结论是,所提供的标定板配置没有充分约束标定以准确估计所有参数。因此需要改变目标函数,找到最优的焦距和主点参数:
在初始最小值周围改用网格搜索,仍然在校准过程中固定探测值。
搜索时获得的标定参数,求解里程计训练序列的旋转误差进行评估,并在距初始值10个像素的邻域内找到最佳参数。在最小化旋转误差的同时,使用网格搜索获得三个参数,即左相机的和 。。
基线距离
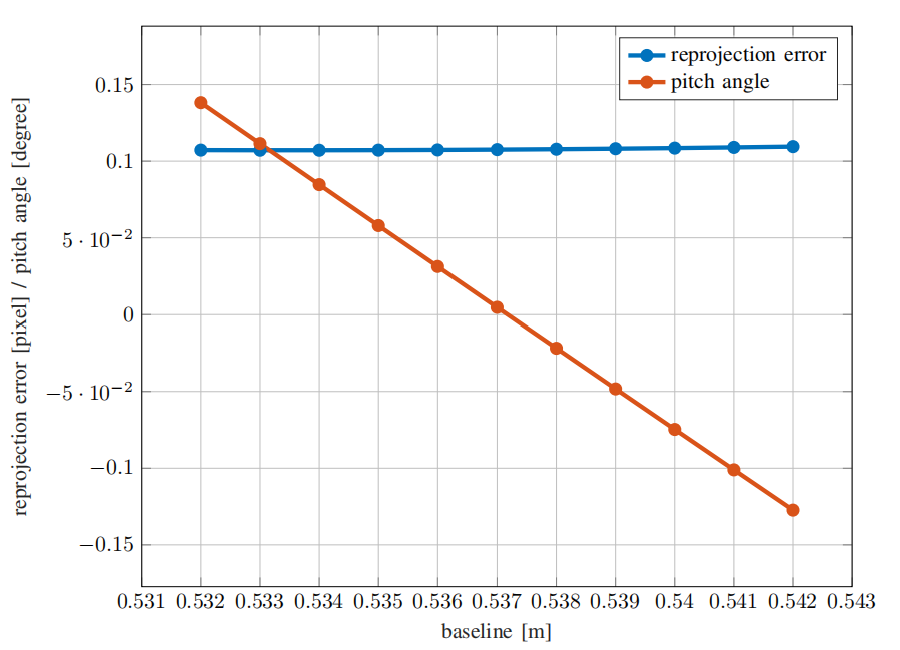
同前面细化三个参数一样,将基线固定为某个特定值进行灵敏度分析。在基线和相机之间的相对角度之间有很强的相关性。强制基线到不同的值会导致相机围绕y轴的俯仰角发生变化,但是可以保持几乎相同的重投影误差,如上图所示。因此,精确的基线很难用里程计来评估,因为轨迹的尺度也可能取决于俯仰角。
最后,通过网格搜索,细化了总共4个参数:左相机的和 以及基线。
实验
我们证明了所获得的标定参数在三种不同的视觉里程计上的有效性:SOFT2,ORB-SLAM2和VISO2
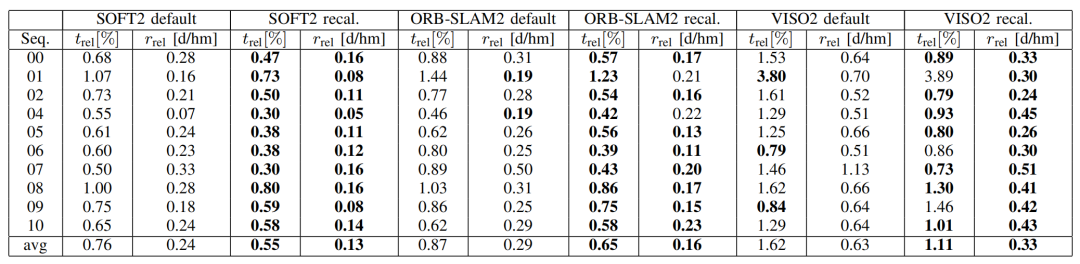
我们对比了KIITI默认的标定方法和本文提出的标定方法在10个KITTI数据集序列上的效果,每个里程计算法在大多数轨迹上都显示出显着改善,平均平移误差改善了 30%,旋转误差改善了50%。
总结
在本文中,我们提出了一种新的KITTI数据集相机标定方法。该方法基于线段检测的亚像素角点检测,通过板匹配和参数细化进行最终参数估计,最终结果优于默认的libcbdetect和OpenCV的标定方法。我们在三种方法不同的视觉里程计算法,即SOFT2、ORB2和SLAM2上测试了新的标定参数,这三种算法都显示出了更好的精度。最后,通过所提出的方法,我们的SOFT2在官方的KITTIbenchmark上获得了SOTA,具有0.53%的平移误差和0.0009 deg/m的旋转误差,甚至优于基于3D激光的里程计。虽然我们的目标是一个特定的数据集,但我们相信这些结果具有普适性,而且KITTI可能在未来几年仍将是一个参考数据集。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









