






作者 | 自动驾驶专栏 编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群

论文链接:https://arxiv.org/ftp/arxiv/papers/2304/2304.05530.pdf

摘要

本文介绍了SceneCalib:自动驾驶中相机和激光雷达的自动无目标标定。在很多3D感知任务中,精确的相机到激光雷达标定是传感器数据融合的基础。在本文中,我们提出了SceneCalib,它是一种在包含多个相机和激光雷达传感器的系统中同时自标定外参和内参的新方法。现有的方法通常需要专门设计的标定目标和人工操作,或者它们仅试图求解标定参数的子集。我们使用一种全自动方法解决这些问题,该方法不需要相机图像和激光雷达点云之间的明确对应关系,从而对很多室外环境具有鲁棒性。此外,整个系统通过明确的跨相机约束进行联合标定,以确保相机到相机和相机到激光雷达的外参是一致的。

主要贡献

本文的贡献总结如下:
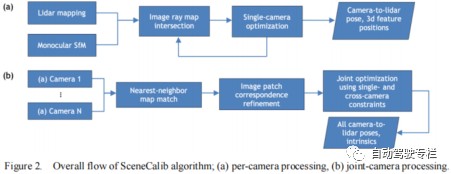
1)本文提出了SceneCalib,其可以在多相机和单激光雷达系统中联合标定所有的外参和相机内参;
2)本文方法仅依赖于图像匹配关系,而不需要获取对应的场景点的先验知识;
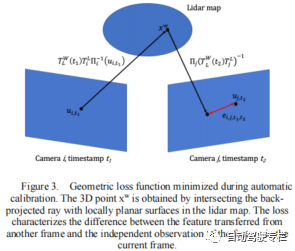
3)本文提出了可靠的方法来寻找跨相机图像之间的对应关系,并且最小化图像特征之间的纯几何损失函数,其将结构估计限制在从激光雷达点云中获取的表面上。

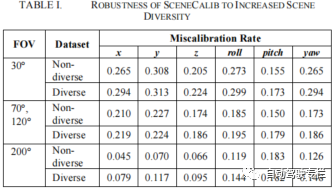
论文图片和表格




总结

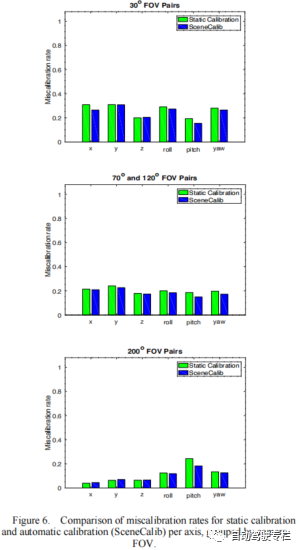
本文提出了一种全自动、无目标的标定算法,用于标定自动驾驶中多个不同特性的相机和激光雷达传感器。该标定算法可以标定相机到激光雷达的外参、相机内参,并且明确约束了相机到相机的位姿变换,同时通过激光雷达提供的高质量3D信息来约束结构估计。我们已经证明,该算法完全不需要人工干预(因此具有高度可扩展性),实现了与手动标定相当的标定质量,并且对各种场景均是鲁棒的。虽然在低光照和恶劣天气条件下很难直接标定,但是未来工作的主要领域是要探索特征检测模块。通过具有在这类条件下提取更多图像特征的能力,可以潜在地显著提高算法的鲁棒性。
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









