






作者 | 小锅不能再胖了 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/696512432
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
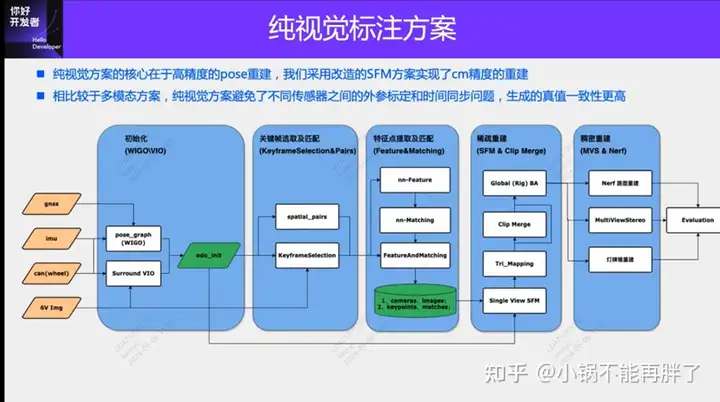
纯视觉的标注方案,主要是利用视觉加上一些GPS、IMU和轮速计传感器的数据进行动静态标注。当然面向量产场景的话,不一定非要是纯视觉,有一些量产的车辆里面,会有像固态雷达(AT128)这样的传感器。如果从量产的角度做数据闭环,把这些传感器都用上,可以有效地解决动态物体的标注问题。但是我们的方案里面,是没有固态雷达的。所以,我们就介绍这种最通用的量产标注方案。
纯视觉的标注方案的核心在于高精度的pose重建。我们采用Structure from motion (SFM) 的pose重建方案,来保证重建精度。但是传统的SFM,尤其是增量式的SFM,效率非常慢,计算复杂度是O(n^4),n是图像的数量。这种重建的效率,对于大规模的数据标注,是没有办法接受的,我们对SFM的方案进行了一些改进。
改进后的clip重建主要分为三个模块:1)利用多传感器的数据,GNSS、IMU和轮速计,构建pose_graph优化,得到初始的pose,这个算法我们称为Wheel-Imu-GNSS-Odometry (WIGO);2)图像进行特征提取和匹配,并直接利用初始化的pose进行三角化,得到初始的3D点;3)最后进行一次全局的BA(Bundle Adjustment)。我们的方案一方面避免了增量式SFM,另一方面不同的clip之间可以实现并行运算,从而大幅度的提升了pose重建的效率,比起现有的增量式的重建,可以实现10到20倍的效率提升。
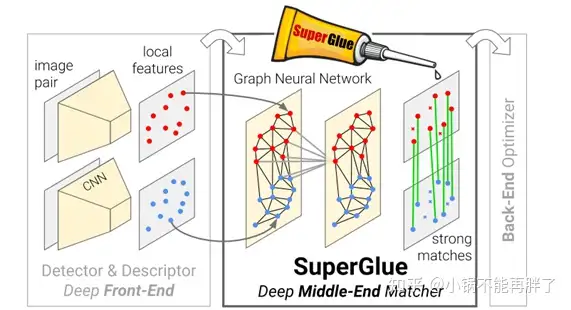
在单次重建的过程中,我们的方案也做了一些优化。例如我们采用了Learning based features(Superpoint和Superglue),一个是特征点,一个是匹配方式,来替代传统的SIFT关键点。用学习NN-Features的优势就在于,一方面可以根据数据驱动的方式去设计规则,满足一些定制化的需求,提升在一些弱纹理以及暗光照的情况下的鲁棒性;另一方面可以提升关键点检测和匹配的效率。我们做了一些对比的实验,在夜晚场景下NN-features的成功率会比SFIT提升大概4倍,从20%提升至80%。
得到单个Clip的重建结果之后,我们会进行多个clips的聚合。与现有的HDmap建图采用矢量结构匹配的方案不同,为了保证聚合的精度,我们采用特征点级别的聚合,也就是通过特征点的匹配进行clip之间的聚合约束。这个操作类似于SLAM中的回环检测,首先采用GPS来确定一些候选的匹配帧;之后,利用特征点以及描述进行图像之间的匹配;最后,结合这些回环约束,构造全局的BA(Bundle Adjustment)并进行优化。目前我们这套方案的精度,RTE指标远超于现在的一些视觉SLAM或者建图方案。
实验:采用colmap cuda版,使用180张图,3848* 2168分辨率,手动设置内参,其余使用默认设置,sparse重建耗时约15min,整个dense重建耗时极长(1-2h)
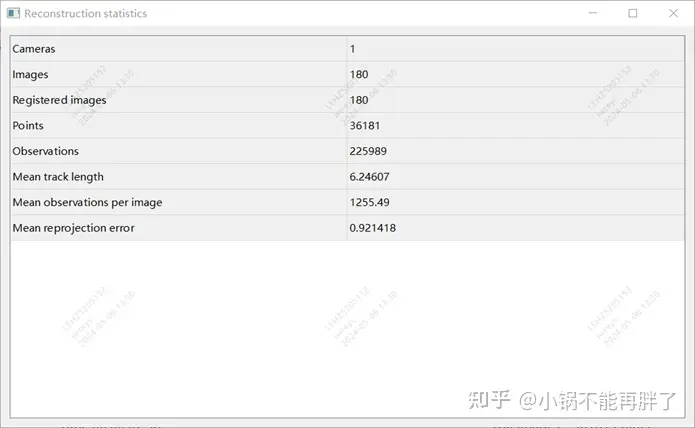
重建结果统计
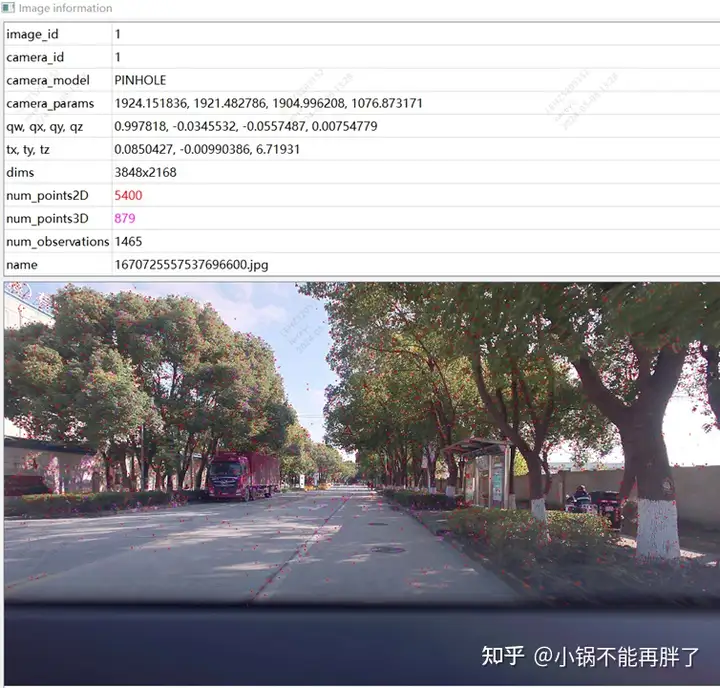
特征点示意图

sparse重建效果

直行路段整体效果

地面锥桶效果

高处限速牌效果

路口斑马线效果
@@@
l 容易不收敛,另外试了一组图像就没有收敛:静止ego过滤,根据自车运动每50-100m形成一个clip;高动态场景动态点滤除、隧道场景位姿
l 利用周视和环视多摄像头:特征点匹配图优化、内外参优化项
l 利用已有的odom
l https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
l pyceres.solve(solver_options, bundle_adjuster.problem, summary)
l 3DGS加速密集重建,否则时间太长无法接受
l
@@@
参考资料:
A Vision-Centric Approach for Static Map Element Annotation
VRSO: Visual-Centric Reconstruction for Static Object Annotation
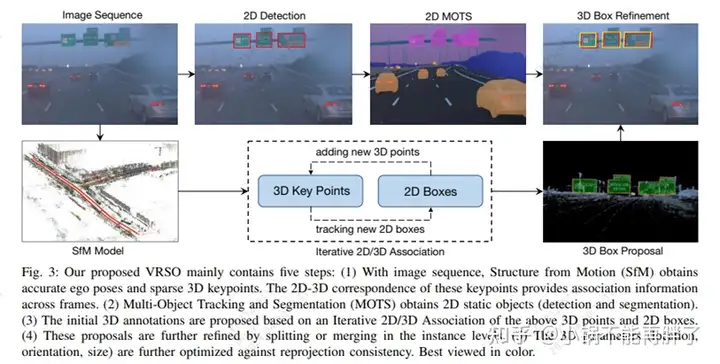
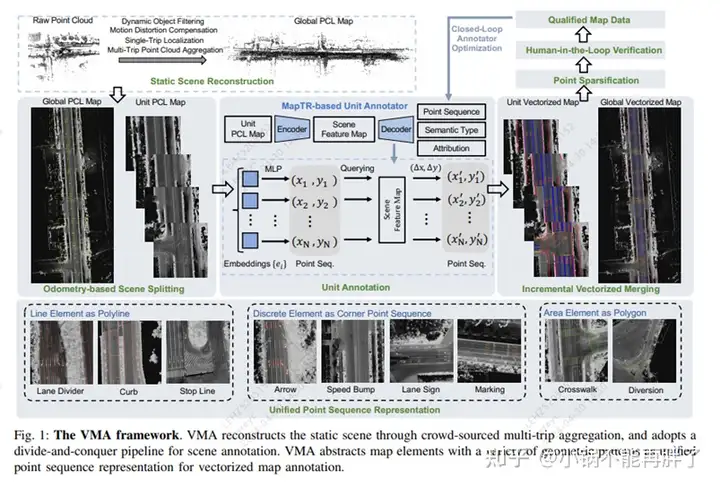
VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene
https://github.com/Xbbei/super-colmap
https://github.com/magicleap/SuperGluePretrainedNetwork
https://zhuanlan.zhihu.com/p/684737645
对于调参人员来说:
(1)为什么colmap如此慢?
如果你的数据是车载数据即forward motion,那么其实local ba 足够,不需要太频繁的global ba(众所周知ba的复杂度是(camera_params+6N+3n)^3,因为每次新加入的图像主要和其周围的地图有关系。所以调整mapper以下参数即可:
i.减少ba_global_max_refinements次数 (5改为1)
ii.增大模型增大到一定比例触发global ba的参数
Mapper.ba_global_images_ratio 、 Mapper.ba_global_points_ratio 、Mapper.ba_global_images_freq
(2)为什么车载数据就跑了两帧程序就终止?如果你的数据质量不佳或者是车载数据,车载数据是比较困难处理的,因为baseline短且图像两边的特征消失的很快,这个时候采用默认参数去跑,通常会出现初始化完后就终止了程序,这个时候就要调小初始最小三角化角度Mapper.init_min_tri_angle(默认16调成5)。
对于研究源码的人员来说,colmap的improved方面数不胜数,离一个可用的状态需要做很多的工作:
(1)关于相机模型的选择,在处理数据的时候,如果相机模型选择简单的,会造成欠拟合,出现blend map之类的现象,如果选择复杂的相机模型就会出现不收敛的情况。
(2)关于匹配方面,colmap中匹配有词汇树匹配方法,但是deep learning的方法已经完全超越BOW,如可以用netvlad、cosplace近几年的方法来替换传统的检索方式。
(3)关于view graph,特征检测和匹配完后,会生成view graph,这时候并不是一股脑就去sfm,view graph 的优化既可以减少冗余,也可以改善整个网形,提升sfm的鲁棒性。
图5.view graph
(4)关于dirft问题,控制点(GCP)/gps约束都可以很好的改善,这个问题已经在三年前colmap课程中讲过,当然在加入外部约束的时候,less is more的约束同时也会增添不少风采,如sift的feature scale 定权可以很明显的降低误差,如图6:
图6.左边是feature sclae和右边没有feature scale
(5)关于colmap 慢的问题,这便是pipeline的问题,采用分组sfm便可解决,整个过程是:view graph 聚类分组-->每个组内 local sfm --> local sfm merge 。做好分组sfm的基本是local sfm 足够的鲁棒。
图7.vismap 11095张鱼眼sfm结果(不同颜色代表分组)
(6)关于colmap 鲁棒性方面,对于forword motion数据,p3p/pnp的效果并不一定好,这个时候采用hybird方式不免是一种明智的做法,流程是:先rotation averaging 然后采用p2p解算pose,具体参见HSfM: Hybrid Structure-from-Motion(崔海楠)的工作。初次之外,也可以在rotation averaging后,利用得到全局rotation 和pnp解算的r进行约束,也就是除了重投影误差,还有图像对之间Rotation的惩罚项。
(7)关于colmap sfm的评判机制/标准,目前所有的论文最终评判sfm的metric都是:track length、重投影误差、3D点个数、每张影响的2D点个数,但是重投影误差是无意义的,即使重投影误差很小,sfm也会出现dirft,因为3D点是源于pose和匹配点,Pose dirft会造成3D点不是"真",那么投影回来误差自然也不会大,所以选择一个合理的metric是值得思考的。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









