






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | 自动驾驶Daily
编辑 | 自动驾驶之心
“原标题:PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
论文链接:https://arxiv.org/pdf/2405.02811
作者单位:Waymo Research

论文思路:
点云的3D目标检测器通常依赖于基于池化的PointNet [20],将稀疏点编码成类似网格的体素或 pillars。本文识别出常见的PointNet设计引入了一个信息瓶颈,限制了3D目标检测的准确性和可扩展性。为了解决这一限制,本文提出了PVTransformer:一种基于Transformer的点到体素架构用于3D检测。本文的关键思想是用注意力模块替换PointNet的池化操作,从而实现更好的点到体素聚合函数。本文的设计尊重稀疏3D点的置换不变性,同时比基于池化的PointNet更具表现力。实验结果显示,本文的PVTransformer在性能上比最新的3D目标检测器有显著提升。在广泛使用的Waymo Open Dataset上,本文的PVTransformer达到了76.5 mAPH L2的最新水平,超越了之前的SWFormer [27] +1.7 mAPH L2。
主要贡献:
新架构:引入了一种基于注意力的点-体素架构,即PVTransformer,旨在解决PointNet的池化限制问题。
新颖的扩展研究:启动对基于Transformer的3D检测器架构可扩展性的探索。
广泛研究:通过广泛的架构搜索,本文展示了所提出的PVTransformer架构的有效性,其在Waymo Open Dataset上达到了76.5 mAPH L2的最新水平。
网络设计:
在城市环境中的自动驾驶3D目标检测需要处理大量稀疏且无序的点,这些点散布在开放的三维空间中。为了管理点的不规则分布,现有方法将点聚合成二维或三维体素表示 [35],利用PointNet类型的特征编码器 [20] 将点特征聚合到体素中,随后通过主干网络和检测头进行处理。然而,现有的点架构往往被忽视,并因其简约设计而受到限制,即少数几个全连接层后跟一个最大池化层。正如原始论文 [20] 所强调的,PointNet类型模块的关键在于最大池化层,它从无序点中提取信息并作为聚合函数。尽管利用了众多全连接层进行特征提取,但体素内所有点的特征通过一个简单的池化层进行组合。本文观察到,3D目标检测中的普通池化操作引入了信息瓶颈,阻碍了现代3D目标检测器的性能。与图像识别中的标准2D最大池化不同,后者作用于有限的像素集,3D检测器中的点-体素池化层必须聚合大量无序点。例如,在Waymo Open Dataset [26] 中,常见一个0.32m × 0.32m的体素中有超过100个点,这些点被池化成一个单一的体素特征向量。这导致了在池化层之后点特征的显著信息损失。
为了解决基于池化的PointNet架构的局限性,本文引入了PVTransformer,这是一种基于Transformer [29] 的新型注意力点-体素架构,用于3D目标检测。PVTransformer的目标是通过注意力模块端到端学习点到体素的编码函数,以缓解现代3D目标检测器中由于池化操作引入的信息瓶颈。在PVTransformer中,每个体素中的每个点被视为一个token,并使用单个查询向量来查询所有点tokens,从而聚合并编码体素内所有点特征到单一的体素特征向量中。PVTransformer中的基于注意力的聚合模块作为一个集合操作符(set operator),保持了排列不变性,但比最大池化更具表现力。值得注意的是,与其他基于Transformer的点网络如Point Transformer [32] 使用池化来聚合点不同,PVTransformer旨在学习特征聚合函数,而无需依赖启发式的池化操作。
本文在Waymo Open Dataset上评估了PVTransformer,这是目前最大的公开3D点云数据集 [26]。实验结果表明,PVTransformer通过改进点到体素的聚合,显著优于之前基于PointNet的3D目标检测器。此外,PVTransformer使本文能够扩展模型,实现了新的最先进水平:在车辆和行人检测中分别达到了76.1 mAPH L2和85.0/84.7 AP L1。值得注意的是,本文的体素主干网络和损失设计主要基于先前的SWFormer [27],但本文新提出的点到体素Transformer相比基线SWFormer提高了+1.7 mAPH L2。

图1:PVTransformer(PVT)作为一种可扩展的架构。PVTransformer解决了之前基于体素的3D检测器中的池化瓶颈,并展示了相较于扩展PointNet(Scale Point)和体素架构(Scale Voxel)更好的可扩展性。每个点的大小表示模型的Flops。更多细节请参见图4和图5。

图2:PVTransformer架构概述。PVTransformer架构包含点架构和体素架构。其创新之处在于点架构,用一种新颖的Transformer设计替代了PointNet。在点架构中,点被分组到pillars内,每个pillars被视为一个token。在一个体素内,点首先经过自注意力Transformer,然后通过交叉注意力Transformer将点特征聚合为体素特征,详细信息见图3(b)。稀疏的BEV体素特征随后进入体素架构,采用多尺度稀疏窗口Transformer(SWFormer Block)[27]进行编码,并使用CenterNet头进行边界框预测[31]。

图3:PVTransformer中的点到体素聚合。该模块使用Transformer层替代了PointNet的最大池化[20]。
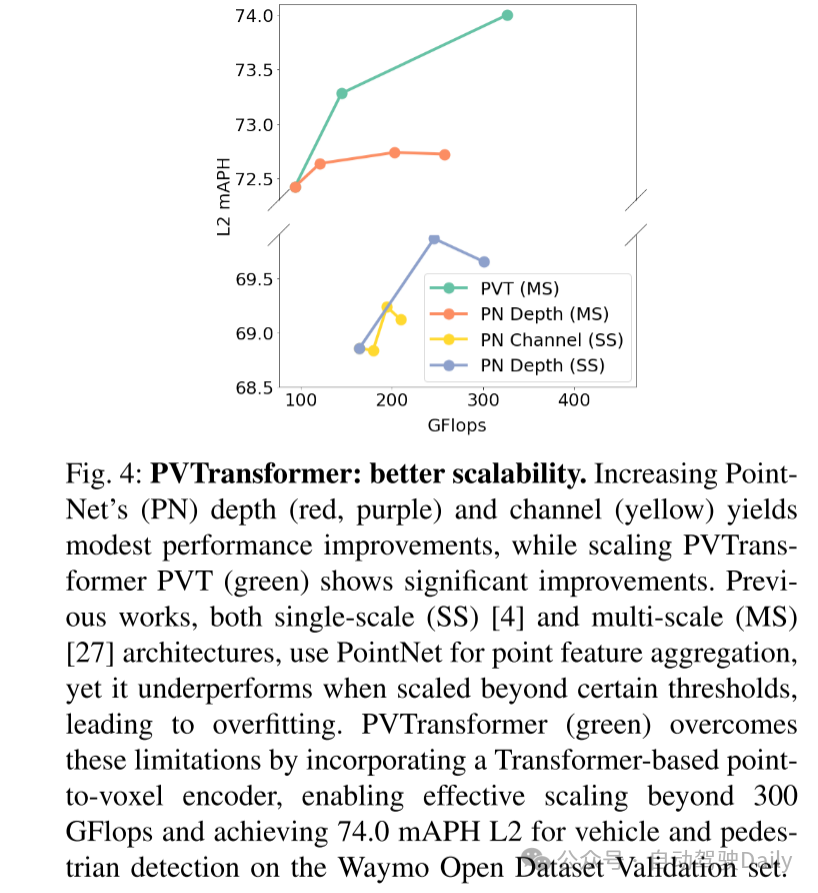
图4:PVTransformer:更好的可扩展性。增加PointNet(PN)的深度(红色,紫色)和通道(黄色)仅带来适度的性能提升,而扩展PVTransformer PVT(绿色)则显示出显著的性能提升。之前的工作中,无论是单尺度(SS)[4]还是多尺度(MS)[27]架构,都使用PointNet进行点特征聚合,但在超过某些阈值时性能不佳,导致过拟合。PVTransformer(绿色)通过引入基于Transformer的点到体素编码器,克服了这些限制,使其能够有效扩展超过 300 GFlops,并在Waymo Open Dataset验证集上实现了车辆和行人检测的74.0 mAPH L2。

图5:当使用PointNet(PN)来聚合点特征时,体素架构的可扩展性有限。右图:使用Transformer来聚合点特征(PVT L)(绿色)显著优于使用PointNet并仅在体素架构中将通道扩展到256(蓝色),在相似的Flops下提高了3.5 mAPH L2。左图:从搜索空间(见表V)中随机采样的体素架构在训练12.8个epoch后的性能表现。本文观察到,使用PointNet扩展体素架构可能导致次优性能。帕累托曲线(红色曲线)显示,将体素架构的通道数从128扩展到192和256会导致过拟合。在Waymo Open Dataset验证集上报告了车辆和行人的mAPH L2。
实验结果:


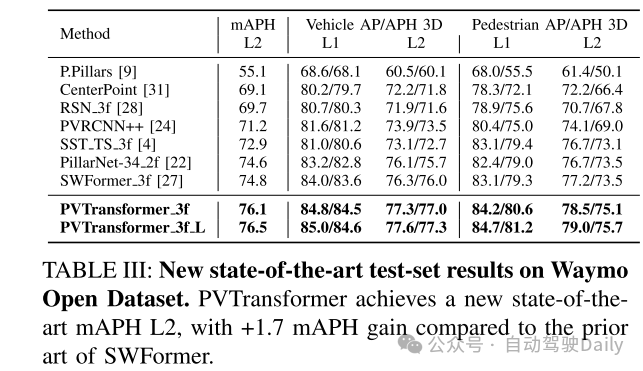



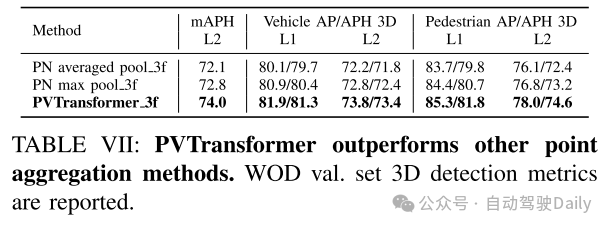
总结:
本文旨在为大规模3D目标检测器实现更好的可扩展性,并发现基于池化的PointNet为现代3D目标检测器引入了信息瓶颈。为了解决这一限制,本文提出了一个新的PVTransformer架构,该架构使用基于注意力机制的Transformer将点特征聚合到体素特征中。本文证明了这种点到体素的Transformer比简单的PointNet池化层更具表现力,因此在性能上远远超过了以往的3D目标检测器。本文的PVTransformer显著优于之前的技术,如SWFormer,并在具有挑战性的Waymo Open Dataset上实现了新的最先进的结果。
引用:
Leng Z, Sun P, He T, et al. PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection[J]. arXiv preprint arXiv:2405.02811, 2024.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 2702
2702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









