






作者 | 冯谢星 编辑 | 自动驾驶Daily
原文链接:https://zhuanlan.zhihu.com/p/704847315
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
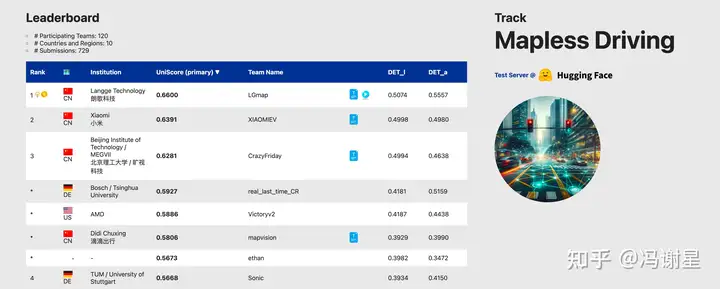
比赛介绍
CVPR 2024 Autonomous Grand Challenge Track Mapless Driving无图智驾赛道的任务是检测车道线和交通元素(红绿灯、道路标牌等),并且推理车道之间、车道与交通要素之间的拓扑关系。在线建立局部高精度地图,从而摆脱自动驾驶对高精地图(HD)的依赖。比赛基于OpenLaneV2数据集进行。
无图自动驾驶和扩城,是2023年各大厂商主要卷的方向。在CVPR 2023自动驾驶挑战赛中,无图自动驾驶包含两个赛道:OpenLane Topology和Online HD Map Construction。今年的比赛相比去年的比赛相比,数据增加了标清地图(SD Map)。因此,今年的方案相比去年方案主要的改进就是将SD Map信息输入模型。
今年比赛的前三名被中国的队伍包揽。
论文解读
#1 LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
今年的冠军LGmap提出三个创新点:首先,提出了对称视图变换(symmetric view transformation, SVT)。克服了前向稀疏特征表示的局限性,利用深度感知和SD Map先验信息的。其次,提出了层级时序融合(hierarchical temporal fusion, HTF)。它利用局部和全局的时序信息,有利于为构建具有高稳定性的远距离的HD Map。最后,提出了一种新的人行横道重采样方法。简化的人行道表示方法加快模型收敛性能。
Diagram
论文的框架图如下图:
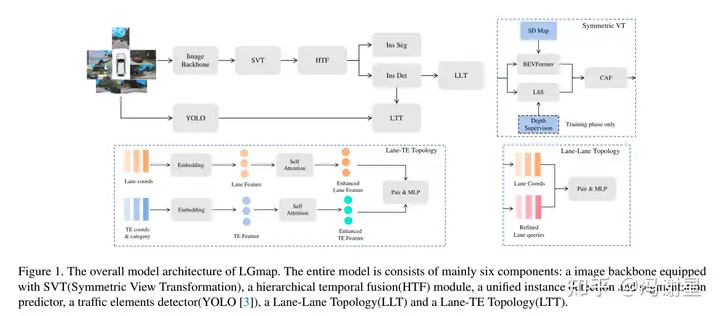
Encoder
输入图片首先经过Image Backbone,提取特征,得到PV(perspective view)特征。经过论文提出的SVT,转为BEV特征。所谓SVT,就是同时使用前向投影方法Lift-Splat-Shoot(LSS)和反向投影方法BEVFormer进行特征转换。LSS部分,使用激光雷达点云提供的深度作为监督。在BEVFormer部分,在SD map的polyline采样固定数量的点,编码成sinusoidal embedding,与图像特征进行cross attention,应该是跟SMERF方法一致。LSS和BEVFormer得到的BEV特征用channel attention模块进行融合。
Decoder
有两个并行的decoder,分别是instance-wise detection decoder和segmentation decoder。instance-wise detection decoder负责输出待检测的目标。segmentation decoder起辅助作用,加快收敛。
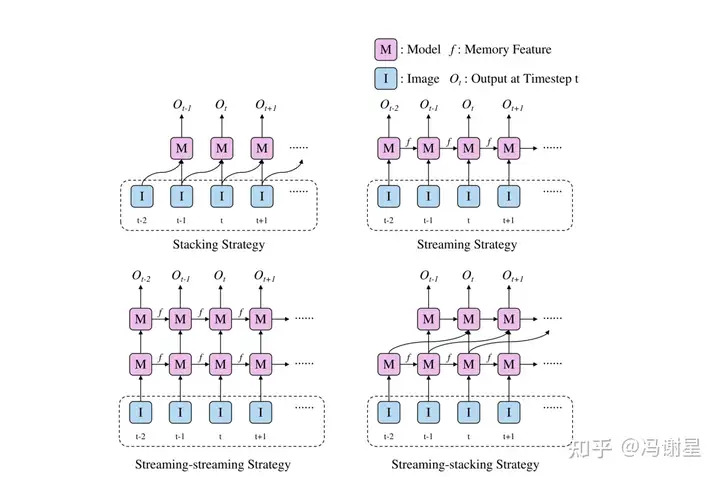
Temporal fusion
论文考虑时序信息,提升远距离建图的准确性。提出HTF,实际是将streaming和stacking结合的方式。所谓streaming是指RNN的范式,将信息通过memory进行传递;而stacking就是直接将信息拼接。作者提出了streaming-streaming和streaming-stacking两种方式供选择。
Loss
总共考虑了4个loss。第一,跟随MapTR,point2point loss和edge direction loss;第二,跟随MapTRv2,segmentation loss和depth prediction loss;第三,BEV instance segmentation loss;第四,跟随GeMap,geometric 3D loss。
Area
针对人行横道,MapTR是是采用20个点均匀间隔采样。本文则是受到Machmap的启发,首先用采样4个顶点,然后再用每条边都为6个点的均匀采样。这样本文比MapTR的采样点简单很多,以20个点为例,MapTR有40种等效排列,而本文只有8中等效排列。这样可以加速收敛速度。

Traffic elements
采用YOLOv8和YOLOv9,检测交通元素,在OpenLaneV2,就包括红绿灯和道路标牌。
Lane-Lane topology
跟随TopoMLP,将已经输出的centerline坐标经过MLP再变成embedding,与经过训练的refined query结合,再经过MLP,输出车道线之间连接关系的二分类结果。
Lane-Traffic topology
本文的这部分是和检测模型分离的。Lane-Traffic topology模型是用lane segments的和traffic elements的真值训的。lane segments和traffic elements过embedding层得到特征,再经过self attention,得到加强特征,再过MLP进行二分类。
Ablation Study
Encoder部分,增加LSS仅提高了0.5%,作用不大。BEVFormer是主力。
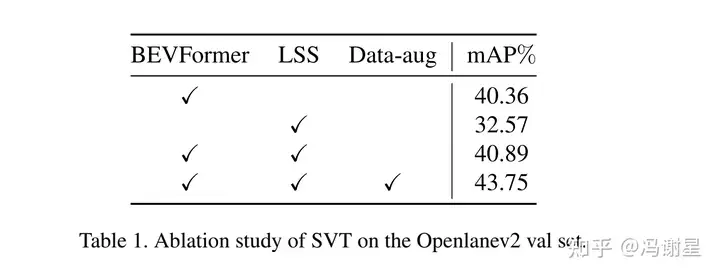
时序融合模块,使用Streaming-Stacking模块,比Streaming高0.5%。Streaming比baseline高3%,主力是Streaming。

用新的人行横道编码方式,可有提高约1%。

#2 Leveraging SD Map to Assist the OpenLane Topology
本文设计了一种紧凑的transformer-based结构,用于SD map encoding and integration,充分利用SD map已经包含的基础道路拓扑结构。此外,提出一种动态位置编码(dynamic positional embedding)机制,提升decoding performance。
Model Architecture
论文没有给出总体框架图。总体框架属于常规的套路。
首先,经过图像backbone得到PV feature,再经过BEVFormer得到BEV feature。其次,基于BEV feature,建立一个SD map encoder来提取SD map的特征。接下来,过lane decoder以及,得到lane的检测结果。最后,接上 topology模型,topology模型是decoupled的。
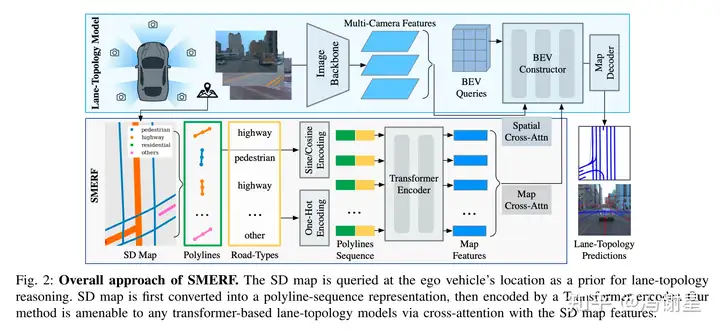
SD Map Encoder
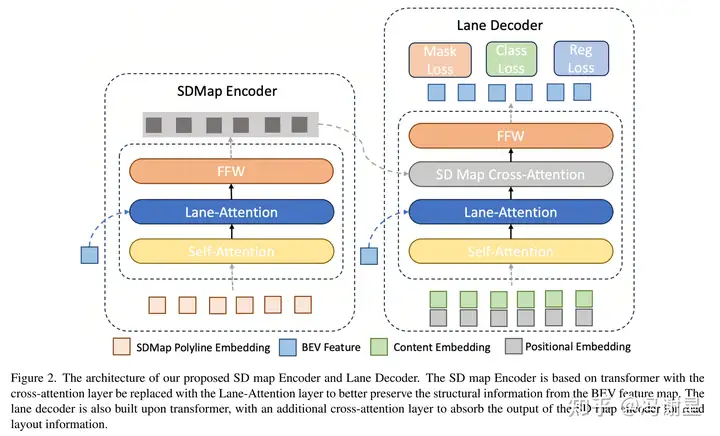
首先对SD map进行编码,方法跟LGmap基本上一致。针对SD map里面的M条polylines,每条polyline均匀取N个点。对这些点进行sinusoidal embeddings:
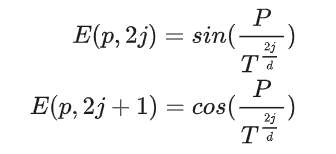
其中p(,)表示polyline上采样点坐标,j表示维度的索引, d表示编码维度,T表示temperature scale。此外,一个one-hot向量 K用于编码polyline类型。最后,所有的采样点的positional embedding(就是上面公式的sinusoidal embeddings)和polyline的类别embedding拼接起来,得到N * d+K维度的SD map polyline编码。先接一个linear layer,将维度转为,再输入transformer。
在SDMap Encoder里,先做一次self attention,再做一次cross attention,k, v是BEV features。这里选择用LaneSegNet提出的Lane Attention操作。
Lane Decoder
Content embedding和positional embedding作为query输入Lane Decoder,先进行一个self attention,再接一个Lane Attention与BEV features进行交互,再接一个cross attention跟SD map embedding进行交互。
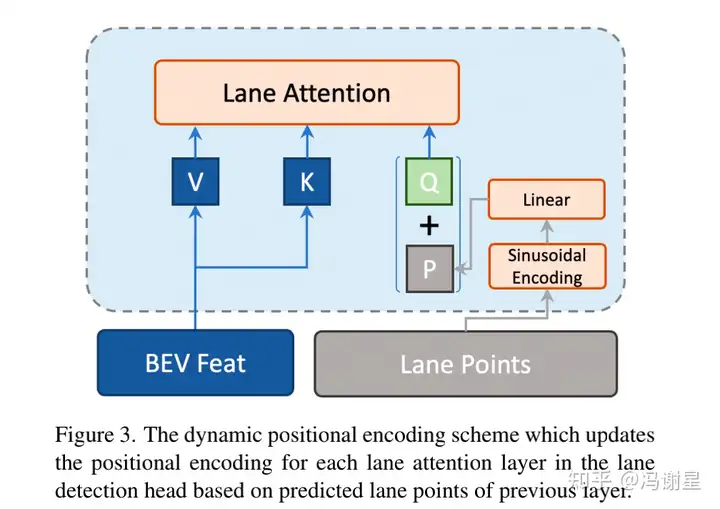
论文提出给Lane Attention动态位置编码。方法是在上一个decoder结束后,得到N个lane points坐标,将其进行sinusoidal编码,得到N * d维度的向量,再过linear layer变换成维的向量。作为位置编码加到query里。
Topology Prediction
与LGmap类似,论文也将topology prediction和detection任务分离了。论文说的原因是因为样本不平衡,positive(associated elements)和negative(non-associated elements)极度不平衡。
将detection模型输出的结果,输入MLP,进行二分类预测。在lane-lane topology中,考虑lane的起点和终点的距离。在lane-traffic topology,用traffic element的bbox和front view摄像机外参进行编码。
#3 UniHDMap: Unified Lane Elements Detection for Topology HD Map Construction
第三名是去年的冠军团队,也就是TopoMLP的作者团队。今年提出了一套unified detection framework,检测车道线,人行横道和道路边界,其中融入了SD map信息。和去年一样,traffic elements还是用YOLOv8检测,topology prediction还是用MLP。
Diagram
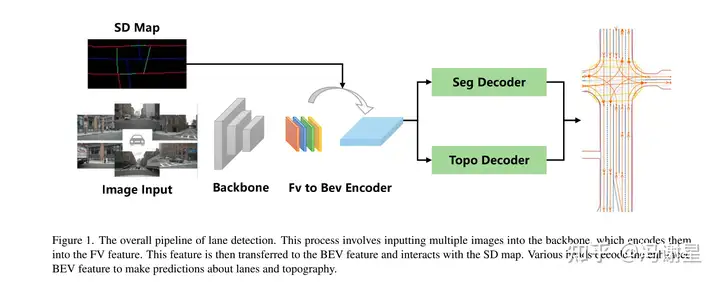
BEV Feature Extraction
跟第二名的方案基本一样,都是SMERF的特征提取框架,把SD map的信息融入。
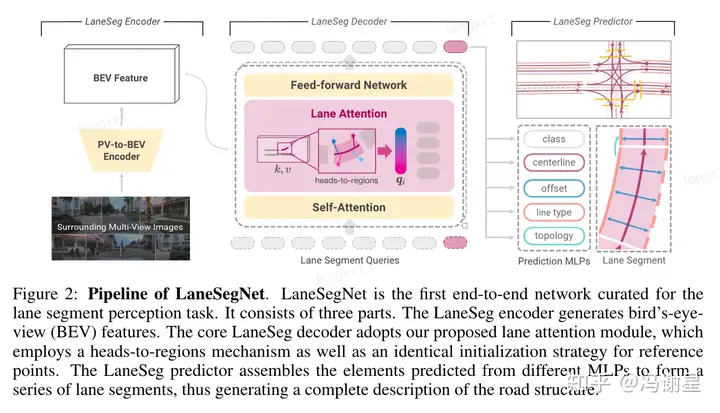
Lane and Area Detection
直接采用了LaneSegNet的detection部分。
Traffic Detection和Topology Prediction都跟去年的TopoMLP方法一样。之后会专门写一篇TopoMLP的解读文章。
#6 MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
论文引入了SD map encoder的pre-training,提高模型的几何编码能力。利用YOLOX来提高traffic element detection。另外,对area detection,引入LDTR和辅助任务,提高精度。
Diagram

SD Map Encoding
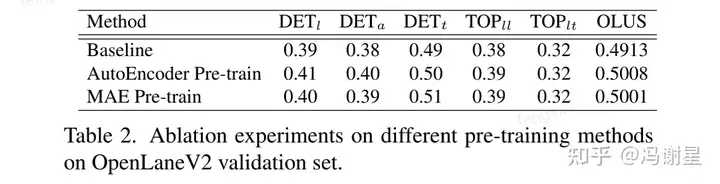
Encoder的框架跟随SMERF。为了增强SD Map Encoder几何结构的编码能力,论文提出了对其进行预训练。使用AutoEncoder进行预训练,将feature sinusoidal embedding作为ground truth。在encoder后加一个轻量化的decoder,进行预测。用L2 loss进行监督。涨点大概在2%左右。
Area Detection
跟随MapTR得方式进行检测。但是,论文认为MapTR采用keypoint的方式进行编码,降低了instance的整体性。因此,受到LDTR得启发,采用anchor-chain的编码方式。
Traffic Detection和Topology Prediction跟前面的论文基本一致。
总结
CVPR 2024无图智驾赛道榜单前几名的模型框架基本一致。相比去年,也没有颠覆性的创新,主要改进在于以下几点:
引入了SD Map作为信息输入,采用SMERF提出的框架将其融入到transformer encoding里;
引入时序信息,预测提高远处的建图精度,提出采用streaming-stacking的方式;
对Area Detection的编码方式,提出了一些改进,更好地适应Area这个instance的特性;
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









