






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | Xu Liu
编辑 | 自动驾驶之心
SLAM应服务于实际任务
机器人系统为了自主执行要求苛刻的任务(例如森林清查管理、果园产量估算、基础设施检查),必须不仅理解环境的几何结构,还要从语义层面感知环境。这需要构建和维护一个语义上有意义的环境表示,编码可操作的信息(例如,森林中的木材体积和健康状况,基础设施中的腐蚀情况,自然灾害中的幸存者位置)。这种表示必须在存储上高效,以便机器人能够在大规模任务中维护,并且必须允许高效优化以用于SLAM。
传统SLAM方法在几何感知方面提供了出色的精度,但在支持大规模任务方面往往不足,特别是在用于多异构机器人实时自主操作时。面临的挑战包括:
管理与长时间跨度SLAM相关的高计算负载
大几何地图的高存储需求
处理回环闭合和大规模地图合并操作
不同机器人平台和传感器模式之间的通用性,结果地图中缺乏执行语义上有意义任务所需的语义信息。

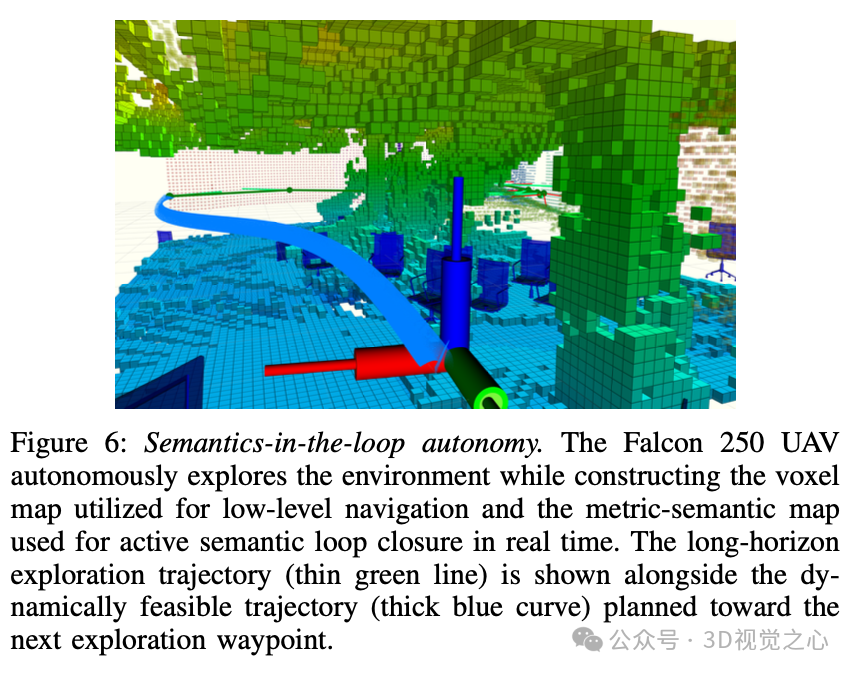
SlideSLAM[1]是一种用于自主导航和探索的多机器人去中心化度量语义SLAM系统。使用包含三个抽象层次的分层度量语义地图对环境进行建模:高层次、中层次和低层次,如图2、图3和图6所示。
高层次抽象存储一个稀疏的地标地图,显式地建模物体,可用于任务规划和长时间跨度的SLAM
中层次抽象维护一个可选的累积分割点云地图,按需激活以提供详细的语义信息
低层次抽象是一个用于导航和避障的短时体素地图

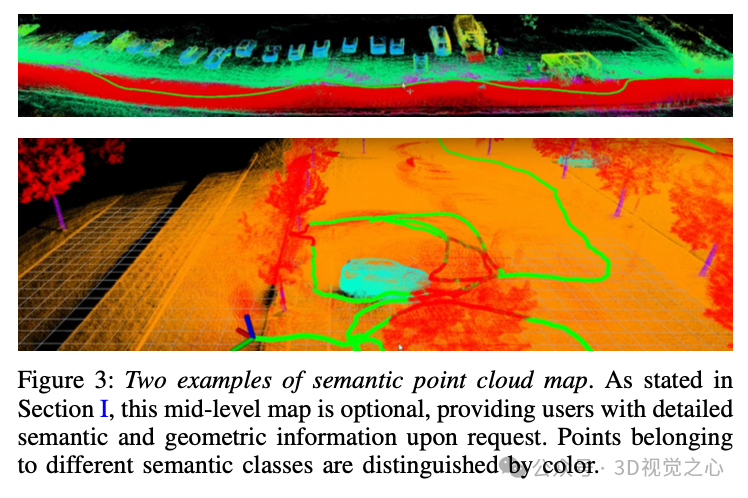
高层次物体级别的地图表示提供了多种优势,例如:
规避了原始点云或图像在大规模任务中的不可行性和高计算及内存需求,特别是对于受限于尺寸、重量和功率(SWaP)的机器人团队
轻量表示确保了即使在有限通信带宽下,机器人间的信息共享也是可行的。再者,这种表示结合语义驱动的地点识别和回环闭合算法,使得高效检测机器人间的回环闭合成为可能
为机器人提供了一个直接且直观的表示,使其能够完成高层次语义上有意义的任务,例如主动探索以搜索和减少感兴趣物体的不确定性。
与基于密集几何特征的传统方法相比,我们的表示避免了频繁边缘化变量导致的信息丢失,使我们能够在更大范围内跟踪可操作信息。
SlideSLAM项目链接:https://xurobotics.github.io/slideslam/, 主要贡献如下:
算法:开发了一个实时去中心化度量语义SLAM框架,支持多种类型的空中和地面机器人,配备了LiDAR或RGBD传感器。该框架的特点包括:(a)利用稀疏且轻量的物体级语义地图进行地图合并的语义驱动的地点识别算法,(b)即使在间歇性通信条件下也能促进信息共享的去中心化多机器人协作模块。
系统集成:在异构机器人团队中集成并部署了所提出的框架,展示了其在各种室内和室外环境中启用语义环内自主导航和探索的能力。该系统实时运行,利用有限的机载计算和内存资源。
实验:进行了大量的真实世界实验,并提供了详尽的实证结果和分析,突出了系统的效率、准确性和鲁棒性。
度量语义SLAM
方法概述
与传统的仅几何方法(如点云配准)不同,本方法利用几何和语义信息来找到不同机器人估计的地图的共同组成部分,然后使用自身和其他机器人所做的测量来细化这些估计。以时间t的k和j两对机器人为例来说明这个想法,尽管这一论点可以很容易地推广到同时与更多机器人进行交互。它解决了如下的最大似然状态估计问题。对于每个机器人,考虑消息。首先,通过对和执行机器人间回环闭合检测来确定机器人和在时间之前共同观察到的地图。回环闭合模块的输出会估计参考框架中机器人和机器人之间的相对变换。特别是参考框架中具有坐标p的点在机器人j的参考框架中具有坐标。然后使用此变换来确定机器人地图中的哪些地标对应于机器人地图中存在的地标。此后,机器人和的轨迹与地图中的物体模型集合一起优化。
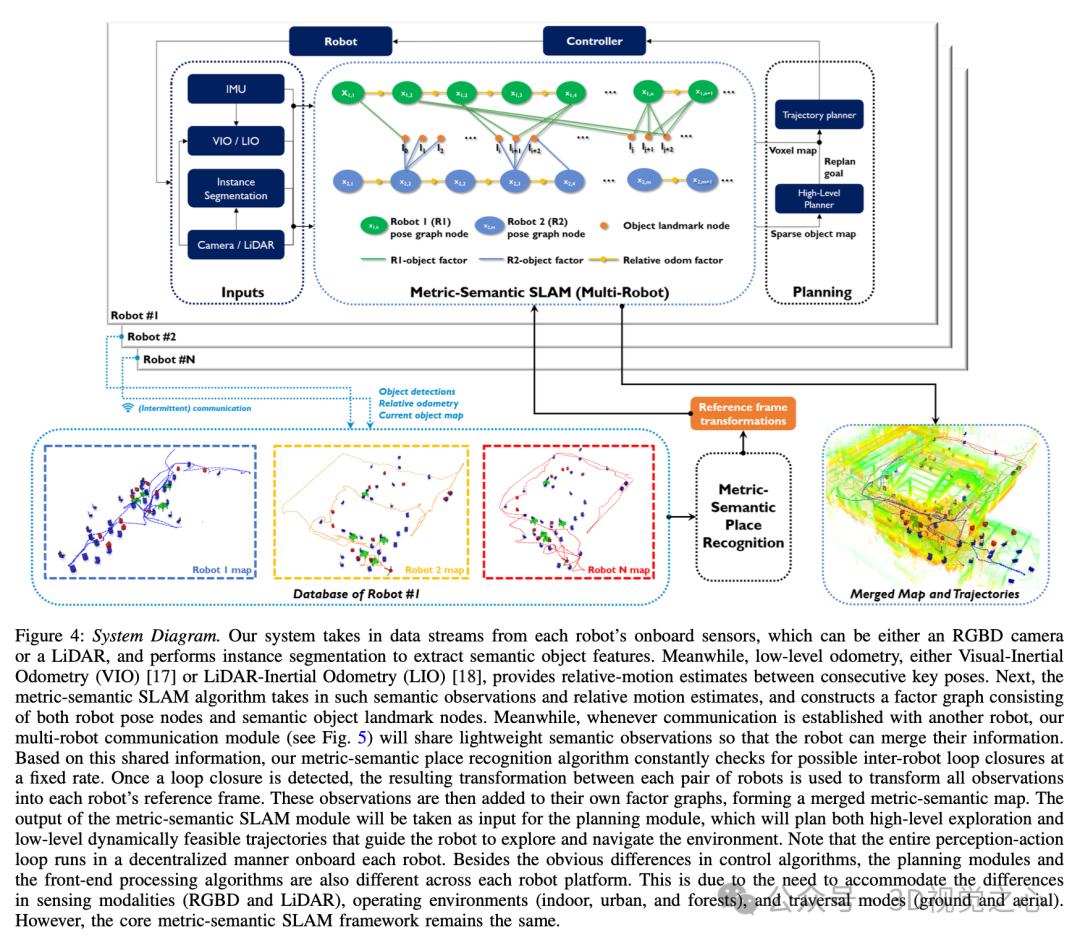
地图表示
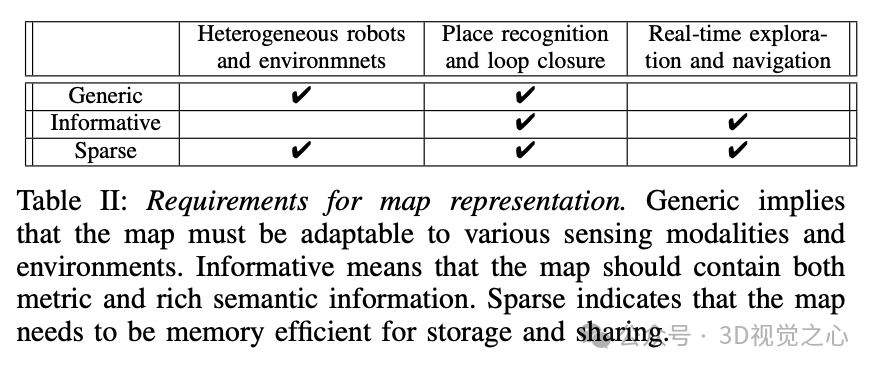
本方法需要支持异构机器人团队,其中机器人可能携带不同的传感器,在不同的环境中操作,并通过间歇性通信共享信息。此外,地图表示需要适应不同的传感器模式(如深度摄像机和LiDAR)和环境中的物体。为了支持多机器人操作并允许在有限的通信带宽下共享信息,我们需要地图表示是稀疏的。为了启用高效和准确的地点识别和回环闭合,地图表示还需要包含丰富的语义信息,以便机器人在感知混淆的条件下能够区分不同的语义对象。最后,为了实现高效、大规模和实时的自主探索,地图表示必须是稀疏且信息丰富的。
物体检测
框架前端负责处理来自不同传感器的原始数据并将其转换为物体级观测。这一过程分为三个部分:
从不同传感器的观测中进行语义分割
跟踪实例以从不同视角积累几何细节,并获得对错误检测的鲁棒性
根据物体的类别选择并拟合长方体、圆柱体或椭圆体模型。
对于LiDAR,处理始于RangeNet++深度语义分割模型。该模型在范围图上进行分割,这是点云的球面投影。与在点云等3D数据结构上进行推理相比,这种操作大大减少了推理时间,使得在受限平台上进行实时推理成为可能。一旦提取出物体实例,这些物体将在多个LiDAR扫描中使用匈牙利算法进行跟踪。跨时间和不同视角跟踪实例可确保物体的几何形状稳定,并最小化误报,这对于度量语义建图是必要的。最后,该算法还通过跟踪和积累移动物体的点云来增强对移动物体的鲁棒性。一个移动物体的累积实例在与其实际尺寸相比时显得较长,这样的物体可以通过简单地应用尺寸阈值来过滤掉。
对于RGBD传感器,使用类似的管道,除了使用YOLOv8在RGB图像上进行物体检测并利用深度信息反投影到点云中。一旦获得稳健的语义实例,根据物体的类型,会考虑并拟合一个形状模型。比如,汽车使用长方体模型,树干和灯杆使用圆柱体模型,而那些不能正确分类为长方体或圆柱体的不规则形状物体使用椭圆体模型。
使用物体模型进行因子图优化
当到达新的物体检测时,首先检查是否可以将其与地图中的现有物体地标关联。在首次观测到物体时,我们将初始化一个物体地标。之后,一旦将新的物体模型与现有物体地标关联,我们就使用观测地标匹配来形成因子图中的因子。一个有效的物体检测地标关联需要满足两个标准:
它们具有相同的语义标签
它们的距离和模型差异在一定阈值内。
形成这些因子的一个关键步骤是定义物体和机器人姿态图顶点之间的约束关系(即图的边)。这意味着需要定义将相对里程计和物体模型观测转换为因子的测量模型。将机器人姿态的矩阵形式记为表示为,其中是旋转分量,是平移分量。
1) 长方体因子
将长方体物体模型的状态向量定义为:,其中是旋转向量,是平移向量,是尺寸。
首先基于其状态向量恢复长方体的SE(3)姿态,并使用将其从参考框架变换到身体框架。
长方体物体的误差函数如下:
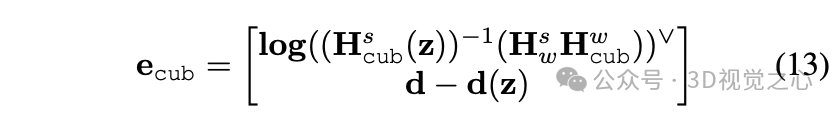
其中,为vee算子,将SE(3)变换矩阵映射为6 × 1向量,log为对数映射,是对应的测量值。
2) 圆柱体因子
将圆柱体物体模型的状态向量定义为:,其中是轴射线的起点,是轴射线的方向,是半径。
计算圆柱体物体的期望测量值和实际测量值和。定义圆柱体物体的误差函数为:
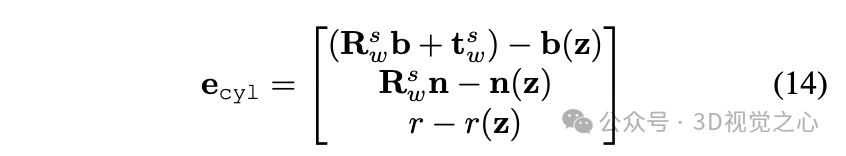
其中,是对应的测量值。
3) 椭圆体因子
所有未关联为圆柱体或长方体形状的物体均表示为椭圆体地标。注意,椭圆体模型简化为只有两个维度(即横截面为圆形)且方向已知。对于每个椭圆体物体,状态向量为:,其中表示质心的3D位置,表示半径和高度。
给定期望的椭圆体地标模型和实际测量值,其由距离-方位测量值以及尺寸测量值组成,测量误差如下:
令表示转换到身体框架中的地标,椭圆体物体的测量误差为:
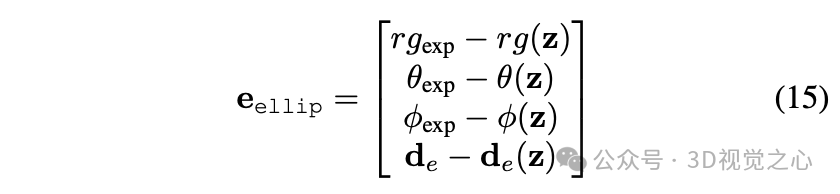
4) 里程计因子
机器人的状态在时间表示为,包含SE(3)姿态。对于每个关键姿态,使用来自VIO或LIO的低级里程计读数计算相对运动,具体取决于机器人携带的传感器。特别是,这被计算为。因子图将此相对运动作为一个里程计因子。这种方法通过不直接使用低级里程计作为姿态先验来减轻通常与低级里程计系统相关的累积漂移。相反,利用里程计估计在空间和时间上相邻的连续关键姿态之间插值,其中低级里程计的精度提供了可靠的测量。
使用上述定义的测量模型将观测值转换为因子图,因子图包含机器人姿态节点和物体地标节点及其之间的因子。我们实现了自定义的长方体和圆柱体因子,使其兼容GTSAM因子图优化库。此外,使用GTSAM的内置相对SE3姿态测量模型用于里程计因子和用于椭圆体物体地标的距离-方位测量模型。
地点识别和回环闭合
用于地图合并的语义驱动地点识别算法在算法1中进行了介绍。该算法从同一机器人(即历史地图和当前地图的回环闭合)或一对不同机器人的语义(子)地图对中获取一对地图。它检查是否找到有效的回环闭合,并输出这两张地图的参考框架之间的相对变换。

该算法的主要组件是数据关联,即找到在基于物体的地标地图中共同存在的一组地标。SampleTransform(R, u)通过在X、Y和偏航维度上离散化搜索空间来生成样本,使用用户指定的范围R和分辨率u(不同维度的分辨率不同)。范围R应不小于单个机器人积累的漂移或多个机器人相对起始位置的差异。外层循环(第3行至第10行)遍历所有可能的X和Y位置以及偏航角样本。内层循环(第5行至第8行)使用采样的变换对第一个子地图进行刚体变换,并通过对该变换后的子地图与第二个子地图之间有效物体模型匹配的数量求和来评估匹配得分。这通过以下步骤完成。首先,SelectPair(M1, M2)选择来自两张地图的一对物体以评估该对是否为有效匹配。TransformObject(b, x, y, yaw)基于参数x、y和偏航对物体b应用刚体变换。类似于第IV-D节中的数据关联,有效的物体模型匹配必须具有相同的语义标签(由ClsEq(a, b)函数检查),并且它们的距离和模型差异在给定阈值内。ModelDiff函数比较两个物体模型之间的差异,该差异定义为欧几里得距离和尺寸差异的加权和。图7展示了两个室外地图的物体匹配过程的可视化结果。

之后,最小二乘优化(即SolveLeastSquare(bestMatch)函数)输出这两张参考框架之间精炼的相对姿态估计。注意,我们仅使用X、Y、Z和偏航角的估计值。这是因为滚动和俯仰角可以从IMU直接观测到,其估计值随时间漂移很小。此优化旨在最小化数据关联步骤中找到的匹配地标对之间的欧几里得距离。
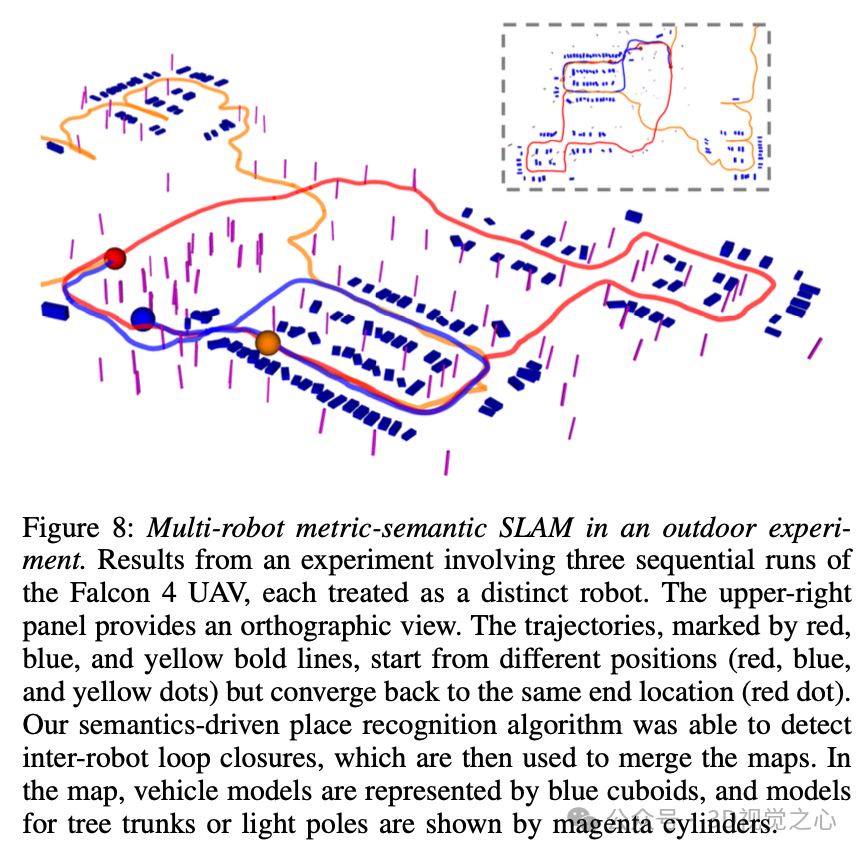
这种直接而有效的算法可用于找到机器人内部和机器人间的回环闭合。然而,它们的实现略有不同。对于机器人内部的回环闭合,输入是与关键姿态相关的观测地标和围绕候选回环闭合姿态的子地图。由于观测地标位于机器人的机体框架中,这些地标的姿态将在输入算法1之前首先使用来自里程计的滚动和俯仰角进行补偿。机器人间回环闭合的输入是来自两个机器人的两个重力对齐的基于物体的地标地图。重叠百分比阈值也用于过滤可能的错误回环闭合。由于使用了信息丰富且稀疏的语义物体地标,该方法在各种环境和不同的传感器模式下被证明是有效的。图8展示了一个例子。
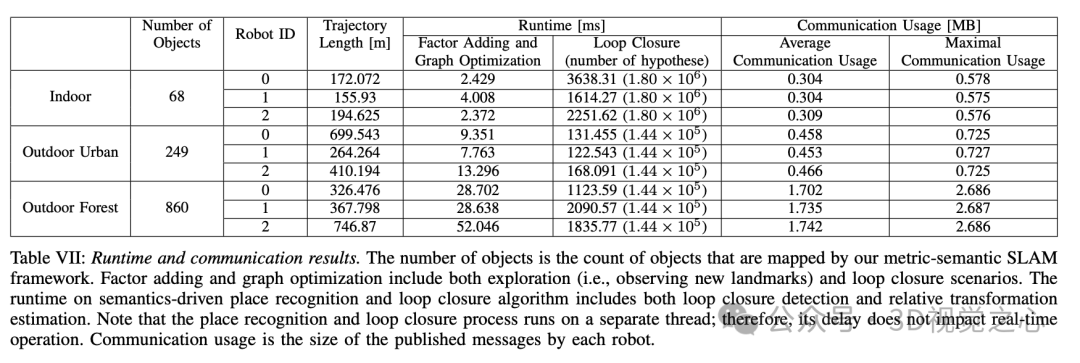
结果和分析




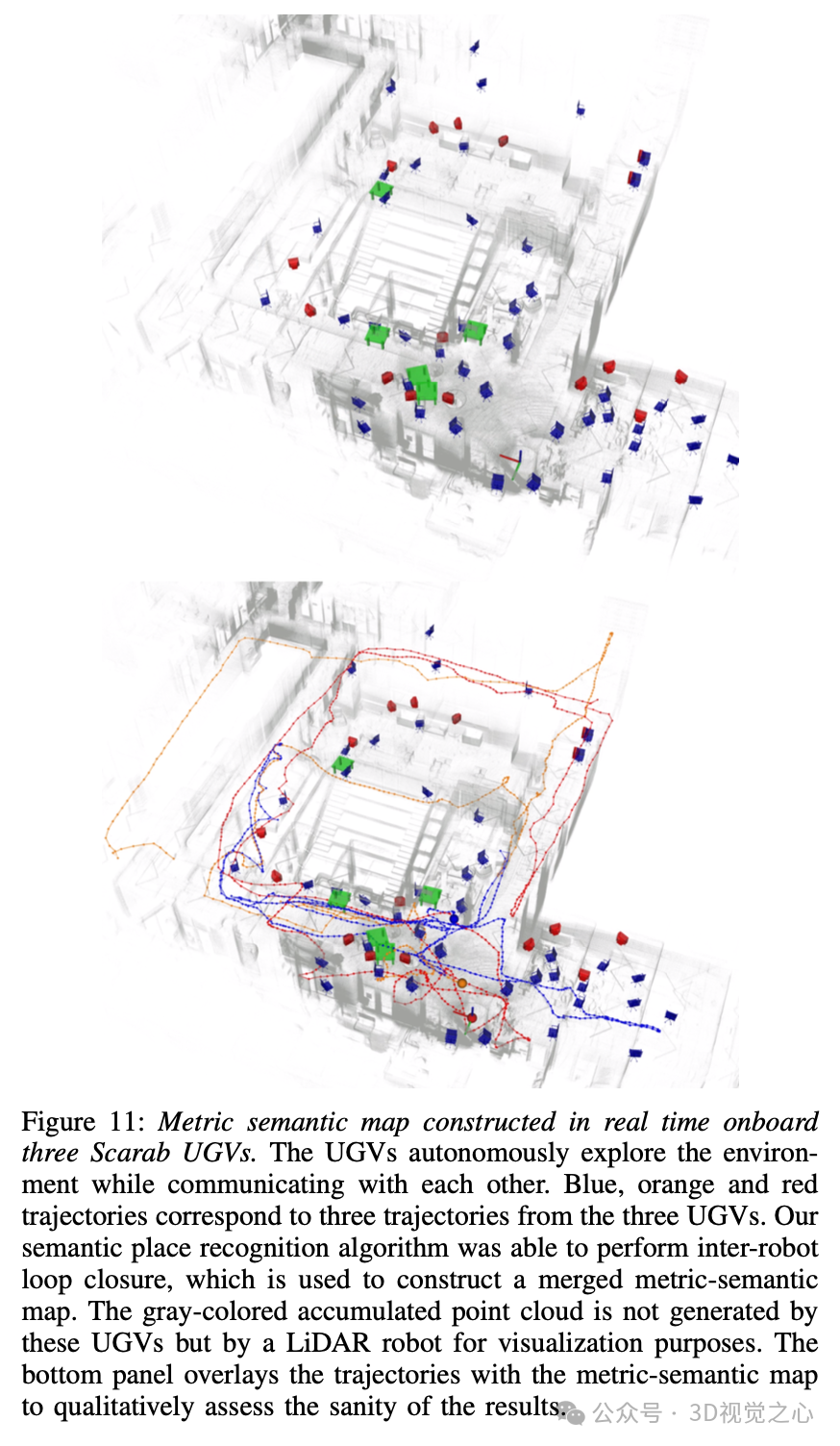
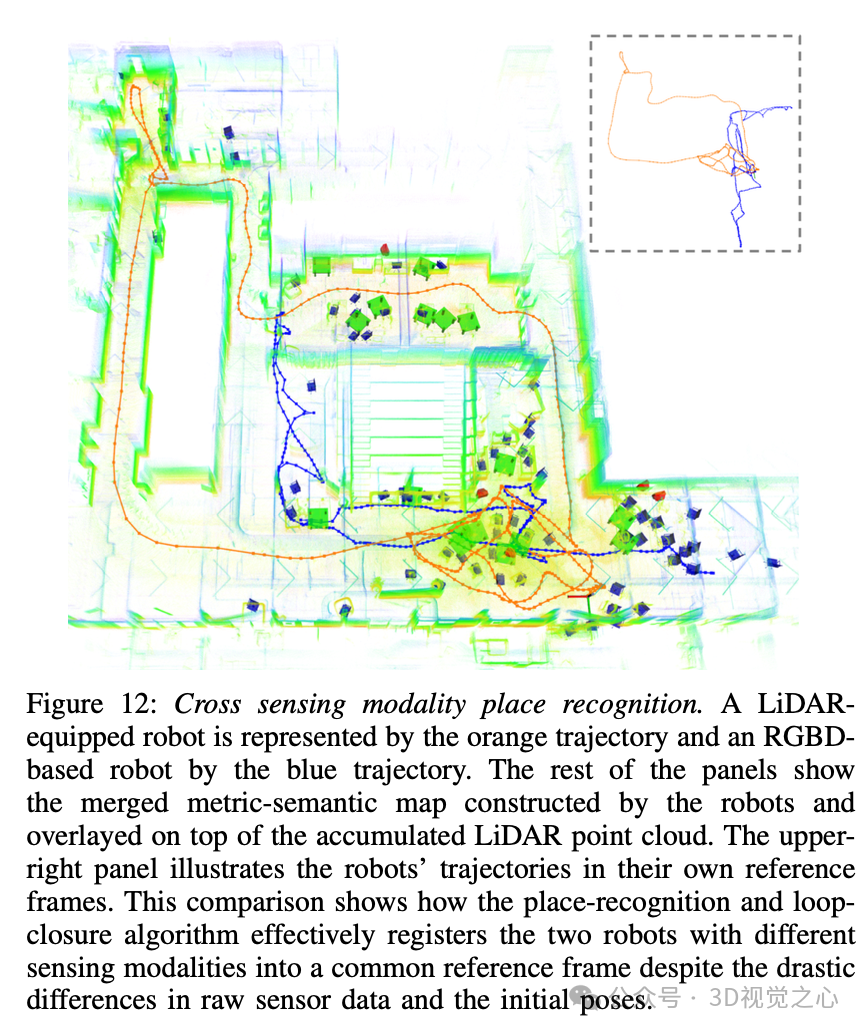
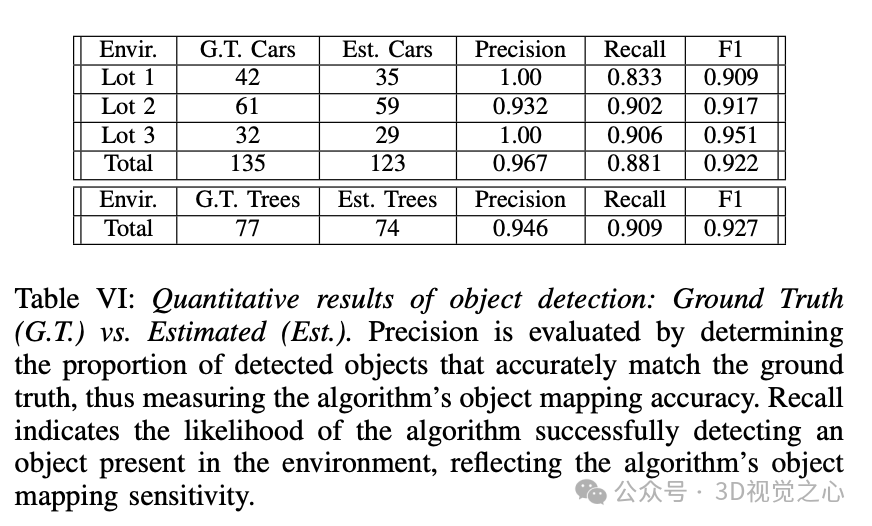

总结与限制
SlideSLAM是一种新的度量语义SLAM框架,能支持异构机器人团队在没有GPS的情况下进行去中心化的自主导航和探索:
提出了一种稀疏且轻量的物体级别语义地图表示,结合了高层次语义地图的信息性和视点不变性,实现了高效的语义驱动回环检测和地图合并
通过在三种类型的机器人上进行实验,证明了该框架的有效性、精度和鲁棒性。
局限性:
参数敏感性:语义驱动的地点识别算法需要手动设置最小重叠百分比阈值,这对回环闭合检测性能影响显著。采用两阶段方法可能有助于提高回环闭合的准确性和稳健性。
计算时间:随着假设数量增加,特别是在高地标密度环境中,计算时间急剧增加。未来可能需要开发更高效的算法,以便在假设数量增加时有效修剪假设。
信息丢失:在将传感器数据抽象为稀疏语义地标过程中不可避免地会丢失一些信息。在物体检测较少的场景中,基于语义的地点识别和回环闭合算法的可靠性降低。这在重复物体密集的室内环境中特别具有挑战性。
感知混淆:当子地图中仅检测到少量物体时,将它们与整个物体地图关联可能会产生感知混淆。为应对这一问题,可以采用主动回环闭合策略,选择高质量的回环闭合候选,避免在感知混淆位置进行回环闭合。
参考
[1] SlideSLAM: Sparse, Lightweight, Decentralized Metric-Semantic SLAM for Multi-Robot Navigation
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 3128
3128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









