






作者 | 不理不理 编辑 | 极市平台
原文链接:https://zhuanlan.zhihu.com/p/699254132
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
近期在研究大模型推理加速框架 VLLM 源码的过程中,对 Pytorch 的显存占用和分配机制十分感兴趣,因此花了一些时间研究和测试。写作本文,既是笔记,也是分享。
1. 前言
1.1 设备及版本
操作系统:Ubuntu 22.04
驱动版本:535.161.08
GPU:A800-SXM4-80GB
CUDA:12.1
Pytorch:2.3.0
Python:3.10.6
得益于社区的不懈努力,PyTorch 的显存管理机制一直在不断优化。尽管不同版本的显存管理机制在核心思路上保持一致,但在细节上可能会略有差异。本文关于显存管理机制的内容基于 Pytorch 2.3.0 版本,文章的最后也提供了显存管理机制部分结论的复现代码,如想验证,请安装 2.3.0 版本的 Pytorch。
1.2 符号约定
在计算机中:
1 Byte = 1 B = 8 Bits
1 KB = 1024 B
1 MB = 1024 KB = 1024 x 1024 B
Bool 型变量占用 1 B
Fp16 和 Bf16 型变量占用 2 B
Fp32 型变量占用 4 B
在下文中, 如无指定, 那么单位默认为 B, 比如 10MB−512 即为 10MB−512 B 。
2. 显存管理机制
GPU 作为一种通用的数据处理设备,为了满足更广泛客户的需求且保证更小的维护成本,其 API 在设计的时候比较开放,尽管 CUDA 生态中也有高阶 API,但并没有针对某个深度学习框架做设计优化,其中显存的精细管理留给上层的深度学习框架去完成。
cudaMalloc(CUDA API)是从 GPU 申请显存最常用的方式,给定指针和数据大小即可进行 API 调用,其调用有着不小的时间开销,且是 stream 内的同步操作。当深度学习框架使用的数据非常零碎且数量多时,需要反复调用 cudaMalloc,该行为会直接影响程序的整体性能,因此深度学习框架的显存管理机制在设计时要尽量降低 cudaMalloc 的调用频次。
PyTorch 框架基于 CUDA API 实现了一套显存管理逻辑/机制,可更好地满足框架的日常使用需求,相比原生的 CUDA API 可做到管理细化、使用相对高效,其采用动态申请与二次分配的设计思路:
动态申请:在使用的时候根据用量实时地向 GPU 发出请求,最大优点是不会占用过量的显存,方便多人同时使用一个设备(与之相对的是 TensorFlow 早期版本在启动前就把 GPU 上的大部分显存都申请到,然后再去分配使用)
二次分配:将显存的申请与使用进行分离,即显存申请后会进行二次分配。显存管理机制会先通过 cudaMalloc 向 GPU 申请一个显存块 Segment,然后从 Segment 分离出子块 Block,我们使用的是分离后的 Block 显存,而不直接使用 Segment
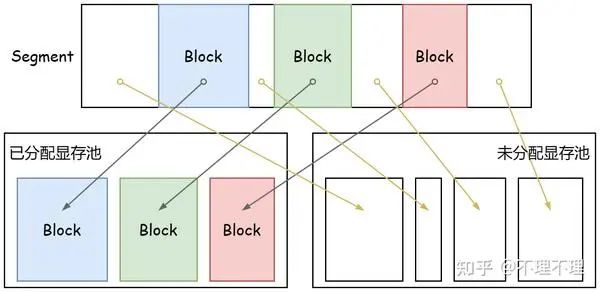
2.1 显存申请
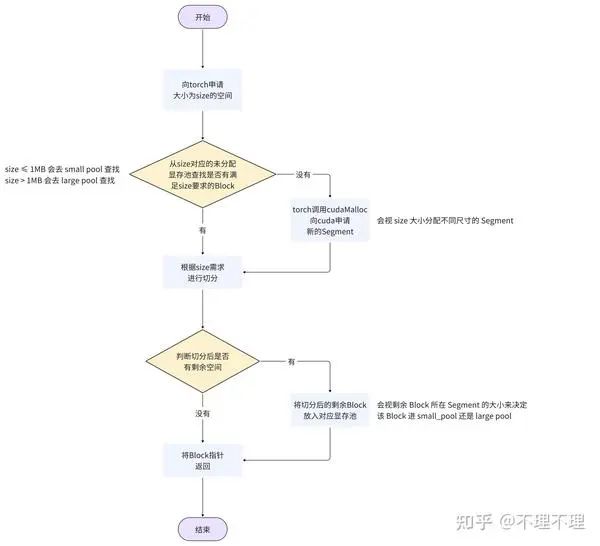
向 PyTorch 申请显存(在 GPU 中创建 tensor)大体符合如下逻辑:
显存管理机制会依据未分配 Block 所在 Segment 的大小,将未分配的 Block 划入 large pool(Segment > 2MB)或 small pool(Segment ≤ 2MB)。
用户创建 tensor 申请显存时,会先从 tensor size 对应未分配显存的 pool 中查找是否有满足 size 要求的 Block,如果没有才会向 GPU 申请新的 Segment 显存块。
2.1.1 Reserved Memory——Segment
首先观察【显存申请流程图】中第一个黄色三角形的右侧部分,即当前未分配显存的池子中没有满足 tensor size 要求的 Block。在这种情况下,显存管理机制需要向 GPU 申请一个新的 Segment,Segment 的大小视 tensor size 决定:
tensor_size : 申请一个 大小的 Segment
tensor_size 申请一个 大小的 Segment
tensor_size : 申请一个 大小的 Segment
tensor_size : 申请一个大小为 整数倍且刚好 tensor size 的 Segment
相关复现代码见 5.1 节。
2.1.2 Large Pool 和 Small Pool
不管是已分配的 Blocks、未分配的 Blocks,还是 Segments,都有其对应的 large pool 和 small pool。其中,我们需要特别关注未分配 Blocks 所属的 pool,因为这直接关系到创建 tensor 所需的空间是从已有的未分配 Blocks 中再分配,还是新申请 Segment 空间。
对于 Segment 而言:
若 Segment 属于 2.1.1 中的第一种,则该 Segment 会被划分到 reserved memory 的 small pool
若 Segment 属于 2.1.1 中的后三种,则该 Segment 会被划分到 reserved memory 的 large pool
对于 Segment 中未分配的 Block 而言:
若该 Block 所属的 Segment 属于 2.1.1 中的第一种,则该 Block 会被划分到未分配显存的 small pool
若该 Block 所属的 Segment 属于 2.1.1 中的后三种,则该 Block 会被划分到未分配显存的 large pool
回到【显存申请流程图】中的第一个黄色三角形,当用户申请显存(创建 tensor)时,显存管理机制会视 tensor size 的大小,来决定到底从未分配显存的 small pool 还是 large pool 寻找满足 size 要求的 Block:
如果 tensor_size ,显存管理机制会从未分配显存的 small pool 中查找
如果 tensor_size , 显存管理机制会从未分配显存的 large pool 中查找
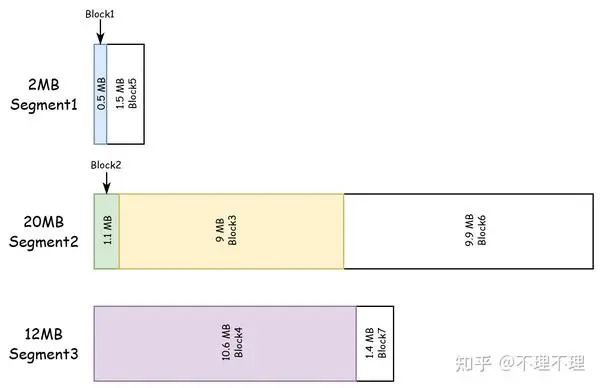
| small pool | large pool | |
|---|---|---|
| Segments | Segment1 | Segment2, Segment3 |
| 已分配 Blocks | Block1 | Block2, Block3, Block4 |
| 未分配 Blocks | Block5 | Block6, Block7 |
比如显存管理器当前有且仅有一个 2MB 的 Segment,已分配了 0.5MB,还剩 1.5MB,用户此时需要创建一个 1.1MB 的 tensor,那么显存管理器不会从这 1.5MB 的未分配 Block 中划分一部分空间给 tensor,而是额外申请一个 20MB 的 Segment 再进行分配。
只有从 tensor size 对应未分配显存的 pool 中未找到满足 size 要求的 Block,才会走流程图中第一个黄色三角形的右侧,申请新的 Segment(2.1.1 节)。
相关复现代码见 5.3 节。
2.1.3 Requested Size 和 Allocated Size
观察【显存申请流程图】中的第二个黄色三角形,针对用户某尺寸 tensor 的创建需求,显存管理机制依据 2.1.2 节中的逻辑已从对应的 pool 中找到了满足 size 要求的 Block,此时需要对该 Block 进行分配及切分。在 Pytorch 2.3.0 版本的显存管理机制中,实际分配给 tensor 的空间可能会略大于 tensor size(rounding 机制)。这一点需要借助阅读 Pytorch 的 C++ 源码或者调用显存管理的高阶 API (3.1.4 节)才好发现,在本文早前版本的理解中也一度以为这一现象来源于 Pytorch API 的精度限制。
这里我们先看 Block 属于 small pool 的情况(Block 此时最大不会超过 2MB; tensor_size ) :
若 tensor_size , 则被分配显存的大小与 tensor size一致
若 tensor_size , 则被分配显存的大小为 (tensor_size
比如创建一个 size 为 511 的 tensor,实际分配的显存为 512;创建一个 size 为 512 的 tensor,实际分配的显存也为 512;创建一个 size 为 513 的 tensor,实际分配的显存为 1024。
再看 Block 属于 large pool 的情况(Block 此时一定 ; tensor_size ),假设 Block 为 iMB:
若 tensor_size ,, 则被分配显存的大小为
若 tensor_size (tensor_size , 则被分配显存的大小与 tensor size 一致
若 tensor_size (tensor_size ), 则被分配显存的大小为 (tensor_size
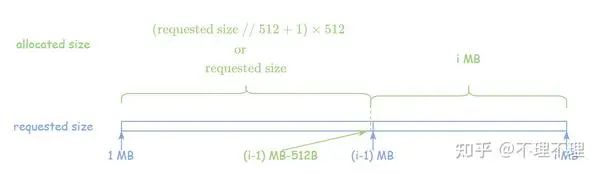
比如 Segment 剩余 1.3 MB,用户此时创建了一个 1.1MB 的 tensor,显存管理机制则会为该 tensor 分配 1.3MB 空间。
值得注意的是,尽管分配给 tensor 的空间略大于 tensor size,但这多出来的空间无法被继续分配,因为在显存管理机制看来,tensor 占据的显存大小并非是 tensor size(requested size),而是 allocated size。
我猜这样设计的目的是为了减少显存碎片,同时降低显存管理的复杂度。比如我们创建一个 11MB 的 tensor,此时 Pytorch 会帮我们申请一个 12MB 的 Segment。从理论上说,该 Segment 在分配后仍有 1MB 的空间等待继续分配,但如果显存管理机制将这 1MB 空间继续分配给其他 ≤1MB 的 tensor,那么在后续某个时刻当这 11MB 的 tensor 被删除,显存管理机制想要回收该 Segment 时,会由于该 Segment 被某些极小(相对 Segment 而言)tensor 部分占据而无法释放(显存释放见 2.2)。
相关复现代码见 5.2 节。
2.2 显存释放
tensor 被删除后,该 tensor 对应的 Block 空间会归还给 Pytorch 显存管理器,显存管理器实际上依旧占据着这块空间,等待将其分配给其他 tensor。

只有手动调用torch.cuda.empty_cache()才有可能释放这些 Blocks 空间。具体来说,当执行torch.cuda.empty_cache()时,显存管理器会调用 cudaFree API 将那些完全未分配的 Segment 真正归还给 GPU,而那些部分分配的 Segment 则不会得到释放。
3. 显存占用分析方法
在介绍几种常见的显存占用分析方法前,先简单介绍一下 CUDA Context(https://discuss.pytorch.org/t/how-do-i-create-torch-tensor-without-any-wasted-storage-space-baggage/131134)。当程序首次执行与 CUDA 相关的操作时,会不可避免地在 GPU 中占用一定量的显存,这部分显存占用被称为 CUDA Context。可以理解为这是当前程序使用 GPU 需要支付的一次性费用,每创建一个使用 CUDA 的进程都会在显存中占据一份 CUDA Context。
CUDA Context 的大小随操作系统、CUDA 版本、GPU 设备、Pytorch 版本的变化而变化,您可以通过如下示例程序测试 CUDA Context 的显存占用:
>>> import torch
>>> temp = torch.tensor(2., dtype=torch.float16, device='cuda')从 2.1 节的流程图可以看出,由于 temp tensor 理论占用 2 个字节,而显存管理机制实际会分配 2MB 的 Segment,因此在我设备上 CUDA Context 的实际占用约为 414MB = 416MB - 2MB。

3.1 PyTorch API
https://pytorch.org/docs/stable/cuda.html%23memory-management
3.1.1 查看当前进程的显存占用
Pytorch 提供了一些 API 供调用者评估当前进程的显存占用,您只需在想要了解显存占用的地方调用以下函数(单位为字节):
torch.cuda.memory_allocated(device):已分配 Blocks 所占据的显存总量(简写 ma)torch.cuda.max_memory_allocated(device):从运行开始 ma 的峰值(简写 mma)torch.cuda.memory_reserved(device):已缓存 Segments 所占据的显存总量(简写 mr)torch.cuda.max_memory_reserved(device):从运行开始 mr 的峰值(简写 mmr)
值得注意的是,上述函数:
仅限当前进程,无法洞悉使用同一设备的其他进程的显存占用
不包含 CUDA Context 部分的显存占用
Block 的显存占用量是 allocated size,而不是 requested size,参考 2.1.3 节
示例程序及解读如下:
创建 a tensor:显存管理器申请了一个 2MB 的 Segment1,然后将一半空间分配给了 Blocka
创建 b tensor:显存管理器又申请了一个 12MB 的 Segment2,并将全部空间分配给了 Blockb
del a:Blocka 所在空间被显存管理器回收,Segment1 此时处于完全未分配状态,等待显存管理器的后续分配torch.cuda.empty_cache():Segment1 完全未分配,该空间得以释放;Segment2 被 Blockb 占用,不满足释放条件
import torch
def record():
ma = torch.cuda.memory_allocated()
mma = torch.cuda.max_memory_allocated()
mr = torch.cuda.memory_reserved()
mmr = torch.cuda.max_memory_reserved()
print(f"ma:{ma / 2 ** 20} MB mma:{mma / 2 ** 20} MB mr:{mr / 2 ** 20} MB mmr:{mmr / 2 ** 20} MB")
a = torch.randn(1024*512, dtype=torch.float16, device='cuda') # 1MB
record() # ma:1.0 MB mma:1.0 MB mr:2.0 MB mmr:2.0 MB
b = torch.randn(1024*1024*6, dtype=torch.float16, device='cuda') # 12MB
record() # ma:13.0 MB mma:13.0 MB mr:14.0 MB mmr:14.0 MB
del a
record() # ma:12.0 MB mma:13.0 MB mr:14.0 MB mmr:14.0 MB
torch.cuda.empty_cache()
record() # ma:12.0 MB mma:13.0 MB mr:12.0 MB mmr:14.0 MB3.1.2 查看各进程的显存占用
torch.cuda.list_gpu_processes(device)可以分析指定设备上各个进程的显存占用,其中每个进程的占用数值都是该进程 CUDA Context 和 Segments 占用的总和。
# print(torch.cuda.list_gpu_processes())
# GPU:0
# process 3008253 uses 1162.000 MB GPU memory
# process 1747547 uses 9084.000 MB GPU memory3.1.3 查看指定设备的剩余可用显存
torch.cuda.mem_get_info(device)提供了一个独特的视角,它不局限于进程,而是揭示指定设备在当前时刻的剩余可用显存量。大语言模型部署框架 VLLM 就在其源码中使用该方法评估指定 GPU 的剩余可用显存,用于预划分整块 KV Cache 空间,减少显存碎片。
调用该函数会返回两个数值,以字节为单位:
第一个数值是指定 GPU 当前时刻的剩余显存量,该数值大致是由 总显存 减去 使用该设备的所有进程的 CUDA Context 和 Segments 占用后得到
第二个数值是指定 GPU 的总显存
3.1.4 高阶 API
torch.cuda.memory_stats(device)是 Pytorch 官方提供的一个高阶 API,供用户查看当前进程更精细化的一些显存占用情况。使用起来比较繁琐且不直观,如果不是研究目的,一般情况下不推荐使用。
https://pytorch.org/docs/stable/generated/torch.cuda.memory_stats.html%23torch.cuda.memory_stats
For more advanced users, we offer more comprehensive memory benchmarking via
[memory_stats()](https://link.zhihu.com/?target=https%3A//pytorch.org/docs/stable/generated/torch.cuda.memory_stats.html%23torch.cuda.memory_stats). We also offer the capability to capture a complete snapshot of the memory allocator state via[memory_snapshot()](https://link.zhihu.com/?target=https%3A//pytorch.org/docs/stable/generated/torch.cuda.memory_snapshot.html%23torch.cuda.memory_snapshot), which can help you understand the underlying allocation patterns produced by your code.
3.2 Snapshot
Snapshot(https://pytorch.org/docs/main/torch_cuda_memory.html%23understanding-cuda-memory-usage) 是 PyTorch 2.1 及以上版本提供的一种自动化显存分析工具。在代码的开始和结束处添加指定语句然后运行代码,PyTorch 会自动记录 CUDA allocator 的显存消耗、显存的 Python/C++ 调用堆栈和调用过程中的时间线,最后将这些数据保存并生成 .pickle 文件,将文件拖入网页(https://pytorch.org/memory_viz)即可查看显存占用。
torch.cuda.memory._record_memory_history() # 开始记录
run_your_code() # 训练或推理代码
torch.cuda.memory._dump_snapshot("my_snapshot.pickle") # 保存文件
torch.cuda.memory._record_memory_history(enabled=None) # 终止记录Snapshot 同样只关注当前进程,而且无法关注到 CUDA Context 部分的显存占用。它从三个不同的视图记录程序的显存占用情况,分别是:
Active Memory Timeline
Allocator State History
Active Cached Segment Timeline
3.2.1 Active Memory Timeline
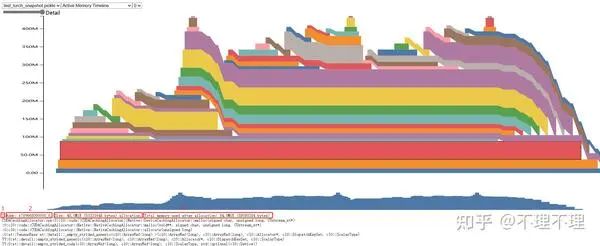
横轴是程序执行的时间轴,纵轴是已申请的显存(参考 2.1.3 节 requested size),而 3.1.1 中torch.cuda.memory_allocated(device)评估的是已分配的显存总量(参考 2.1.3 节 allocated size)。色块起点表示 tensor 的分配,终点表示 tensor 的释放,长度代表生命周期,色块的滑坡代表此前有其他 tensor 被释放(这里的释放并非真正意义上的空间释放,参考 2.2 节)。
通过该视图可以查看 tensor 在程序运行过程中的显存占用和生命周期。
从上图中任选一个色块:
红框 1 表示该 tensor 的编号(同一个 tensor 在三个视图中的编号一致)
红框 2 表示该 tensor 的地址
红框 3 表示该 tensor 的 size
红框 4 表示在色块起点时刻显存管理器已申请的显存总量(区别于 3.2.3 已缓存的显存总量)
3.2.2 Allocator State History
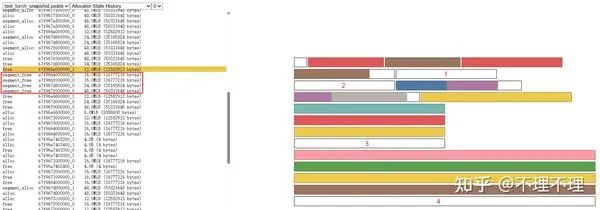
上图右侧是某一时刻 Segment 和 tensor 的分配情况,白框是 Segment,色块是 tensor。
上图左侧记录着 Segment 和 tensor 随时间的申请、分配、释放历史,左侧第一列表示动作,第二列表示 Segment 或 tensor 的地址,第三列表示显存大小:
segment_alloc:显存管理器此时调用 cudaMalloc 从 GPU 申请一个新的 Segment 缓存块
alloc:显存管理器从 Segment 中划出一块空间给 tensor
free:表示 tensor 的释放(将 tensor 所在空间归还给显存管理器,参考 2.2 节)
segment_free:表明程序此时调用了
torch.cuda.empty_cache(),显存管理器会将一些完全未分配的 Segment 释放
通过该视图可以查看程序运行过程中 Segment 和 tensor 的申请、分配、释放历史。
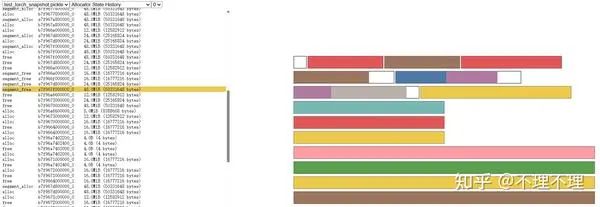
在上图右侧的左上角,有一个 2MB 大小的 Segment 在torch.cuda.empty_cache()调用后看起来并没有得到释放,这是因为该 Segment 其实并非为空,而是分配了一个 8KB 大小的 tensor。
3.2.3 Active Cached Segment Timeline
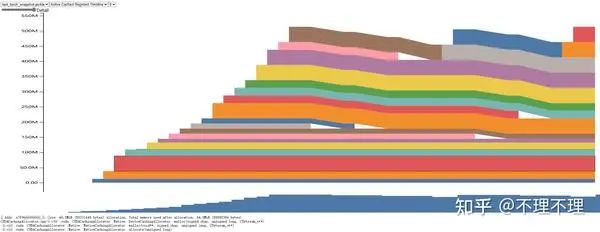
类似 3.2.1 的 Active Memory Timeline 图,横轴是程序执行的时间轴,纵轴是已缓存的显存(torch.cuda.memory_reserved(device)),色块是 Segment(3.2.1 中的色块是 tensor)。
通过该视图可以直观地查看各 Segment 的生命周期,以及是由哪些操作触发了 Segment 的创建。 如果不是用户主动调用torch.cuda.empty_cache(),Segment 一般不会释放。
3.3 nvidia-smi
通过在终端运行watch \-n i nvidia-smi指令,nvidia 驱动可以每隔 i 秒显示一次各 GPU 的显存占用情况。但由于内部刷新频率的限制,该指令没法实时、高频地反馈显存占用。
此外,该指令反馈的显存占用数值 由使用该设备的所有进程的 CUDA Context 和 Segments 占用构成,就算忽略每个进程 CUDA Context 部分的显存占用,Segments 部分的占用数值也并不能直接反映程序实际的显存占用。
3.4 总结
3.1.1 中的前两个 API 聚焦 allocated memory,关注程序执行过程中实际的显存分配量;而 Snapshot 中的前两个视图则突出 requested memory,忽略 Pytorch 显存管理中的 rounding 机制,适合研究目的;至于nvidia-smi,如果只是为了查看显存余量,并且对刷新频率没有太高要求的话,用起来还是蛮方便的。
4. 示例代码
这是一个简易全连接网络的训练代码,这份代码同时使用到了 3.1 和 3.2 节中提到的部分分析方法,并且对每个操作运行前后的显存变化进行了断言(assert),您可以将这份代码运行所生成的 .pickle 文件拖入网页(https://pytorch.org/memory_viz)进行显存分析,如果暂时运行不了这份代码,我也在下面给出了运行结果。
我会在下一篇文章中,结合 Pytorch 计算图分析这份代码在训练过程中各个环节的显存占用,同时给出深度学习模型常规训练时的显存变化规律。
import torch
# hyperparameters which you can change
batch_size = 1024
h0 = 1536
h1 = 2048
h2 = 3072
h3 = 4096
# some variables associated with recording
ma, mma, mr, mmr = 0, 0, 0, 0
ma_gap = 0
num_bytes_fp32, num_bytes_long = 4, 8
# tensor size
INPUT_BYTES = batch_size * h0 * num_bytes_fp32
A1_BYTES = batch_size * h1 * num_bytes_fp32
A2_BYTES = batch_size * h2 * num_bytes_fp32
A3_BYTES = batch_size * h3 * num_bytes_fp32
LOG_SOFTMAX_A3_BYTES = A3_BYTES
LABELS_BYTES = batch_size * num_bytes_long
LAYER1_BYTES = LAYER1_GRAD_BYTES = h0 * h1 * num_bytes_fp32
LAYER2_BYTES = LAYER2_GRAD_BYTES = h1 * h2 * num_bytes_fp32
LAYER3_BYTES = LAYER3_GRAD_BYTES = h2 * h3 * num_bytes_fp32
# since the existence of requested memory and allocated memory, so to demonstrate let's make following assertions
assert INPUT_BYTES % 512 == 0
assert A1_BYTES % 512 == 0
assert A2_BYTES % 512 == 0
assert A3_BYTES % 512 == 0
assert LOG_SOFTMAX_A3_BYTES % 512 == 0
assert LABELS_BYTES % 512 == 0
assert LAYER1_BYTES % 512 == 0
assert LAYER2_BYTES % 512 == 0
assert LAYER3_BYTES % 512 == 0
def sep(num):
# for example: 1000000 -> 1,000,000
return "{:,}".format(num).rjust(14)
def my_assert(num1, num2):
assert num1 == num2, print(sep(num1), sep(num2))
def record(s):
# 1. update these global variables
# 2. print cuda memory allocated and reserved at this moment
# 3. automatic compute ma_gap between current ma and last ma
global ma, mma, mr, mmr, ma_gap
pre_ma, pre_mma, pre_mr, pre_mmr = ma, mma, mr, mmr
ma = torch.cuda.memory_allocated()
mma = torch.cuda.max_memory_allocated()
mr = torch.cuda.memory_reserved()
mmr = torch.cuda.max_memory_reserved()
ma_gap = ma - pre_ma
print(f"\n\n================================================================================{s.center(50)}================================================================================")
print(f"[MA]:{sep(ma)} ={sep(pre_ma)} +{sep(ma_gap)} [MMA]:{sep(mma)} ={sep(pre_mma)} +{sep(mma-pre_mma)} [MR]:{sep(mr)} ={sep(pre_mr)} +{sep(mr-pre_mr)} [MMR]:{sep(mmr)} ={sep(pre_mmr)} +{sep(mmr-pre_mmr)}")
class MyNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer1 = torch.nn.Linear(h0, h1, bias=False) # parameter number: h0 x h1
self.layer2 = torch.nn.Linear(h1, h2, bias=False) # parameter number: h1 x h2
self.layer3 = torch.nn.Linear(h2, h3, bias=False) # parameter number: h2 x h3
def forward(self, x, epoch):
record(f"Epoch {epoch} Before Forward")
a1 = self.layer1(x)
record(f"Epoch {epoch} After layer1")
if epoch == 1:
my_assert(ma_gap, A1_BYTES + 8519680) # 8519680 / 1024 / 1024 = 8.125 MB
else:
my_assert(ma_gap, A1_BYTES)
a2 = self.layer2(a1)
record(f"Epoch {epoch} After layer2")
my_assert(ma_gap, A2_BYTES)
a3 = self.layer3(a2)
record(f"Epoch {epoch} After layer3")
my_assert(ma_gap, A3_BYTES)
return a3
def train(epochs):
record("Before Init Model")
model = MyNet().cuda()
record("After Init Model")
my_assert(ma_gap, LAYER1_BYTES + LAYER2_BYTES + LAYER3_BYTES)
record("Before Construct Data")
input = torch.randn(batch_size, h0, dtype=torch.float32).cuda()
labels = torch.empty(batch_size, dtype=torch.long, device='cuda').random_(h3)
record("After Construct Data")
my_assert(ma_gap, INPUT_BYTES + LABELS_BYTES)
record("Before Init Optimizer")
optimizer = torch.optim.AdamW(model.parameters(), lr=0.005)
record("After Init Optimizer")
my_assert(ma_gap, 0)
for epoch in range(1, epochs + 1):
record(f"Epoch {epoch} Before Optimizer Zero Grad")
optimizer.zero_grad() # for param in model.parameters(): param.grad = None
record(f"Epoch {epoch} After Optimizer Zero Grad")
if epoch == 1:
my_assert(ma_gap, 0)
else:
my_assert(ma_gap, -(LAYER1_GRAD_BYTES + LAYER2_GRAD_BYTES + LAYER3_GRAD_BYTES))
a3 = model(input, epoch)
record(f"Epoch {epoch} Before Compute Loss")
loss = torch.nn.CrossEntropyLoss()(a3, labels) # CrossEntropyLoss = LogSoftmax + NLLLoss
record(f"Epoch {epoch} After Compute Loss")
record(f"Epoch {epoch} Before Backward")
loss.backward()
record(f"Epoch {epoch} After Backward")
if epoch == 1:
my_assert(ma_gap, LAYER1_GRAD_BYTES + LAYER2_GRAD_BYTES + LAYER3_GRAD_BYTES - A1_BYTES - A2_BYTES - LOG_SOFTMAX_A3_BYTES + 8519680 - 512) # 512 是一些零碎变量
else:
my_assert(ma_gap, LAYER1_GRAD_BYTES + LAYER2_GRAD_BYTES + LAYER3_GRAD_BYTES - A1_BYTES - A2_BYTES - LOG_SOFTMAX_A3_BYTES - 512)
record(f"Epoch {epoch} Before Optimizer Step")
optimizer.step()
record(f"Epoch {epoch} After Optimizer Step")
if epoch == 1:
my_assert(ma_gap, (LAYER1_GRAD_BYTES + LAYER2_GRAD_BYTES + LAYER3_GRAD_BYTES) * 2) # 梯度的一阶矩和二阶矩
else:
my_assert(ma_gap, 0)
torch.cuda.empty_cache()
if __name__ == "__main__":
torch.cuda.memory._record_memory_history(max_entries=8000)
train(epochs=3)
torch.cuda.memory._dump_snapshot("test_torch_snapshot.pickle")
torch.cuda.memory._record_memory_history(enabled=None)
# 运行结果:
# ================================================================================ Before Init Model ================================================================================
# [MA]: 0 = 0 + 0 [MMA]: 0 = 0 + 0 [MR]: 0 = 0 + 0 [MMR]: 0 = 0 + 0
#
#
# ================================================================================ After Init Model ================================================================================
# [MA]: 88,080,384 = 0 + 88,080,384 [MMA]: 88,080,384 = 0 + 88,080,384 [MR]: 88,080,384 = 0 + 88,080,384 [MMR]: 88,080,384 = 0 + 88,080,384
#
#
# ================================================================================ Before Construct Data ================================================================================
# [MA]: 88,080,384 = 88,080,384 + 0 [MMA]: 88,080,384 = 88,080,384 + 0 [MR]: 88,080,384 = 88,080,384 + 0 [MMR]: 88,080,384 = 88,080,384 + 0
#
#
# ================================================================================ After Construct Data ================================================================================
# [MA]: 94,380,032 = 88,080,384 + 6,299,648 [MMA]: 94,380,032 = 88,080,384 + 6,299,648 [MR]: 111,149,056 = 88,080,384 + 23,068,672 [MMR]: 111,149,056 = 88,080,384 + 23,068,672
#
#
# ================================================================================ Before Init Optimizer ================================================================================
# [MA]: 94,380,032 = 94,380,032 + 0 [MMA]: 94,380,032 = 94,380,032 + 0 [MR]: 111,149,056 = 111,149,056 + 0 [MMR]: 111,149,056 = 111,149,056 + 0
#
#
# ================================================================================ After Init Optimizer ================================================================================
# [MA]: 94,380,032 = 94,380,032 + 0 [MMA]: 94,380,032 = 94,380,032 + 0 [MR]: 111,149,056 = 111,149,056 + 0 [MMR]: 111,149,056 = 111,149,056 + 0
#
#
# ================================================================================ Epoch 1 Before Optimizer Zero Grad ================================================================================
# [MA]: 94,380,032 = 94,380,032 + 0 [MMA]: 94,380,032 = 94,380,032 + 0 [MR]: 111,149,056 = 111,149,056 + 0 [MMR]: 111,149,056 = 111,149,056 + 0
#
#
# ================================================================================ Epoch 1 After Optimizer Zero Grad ================================================================================
# [MA]: 94,380,032 = 94,380,032 + 0 [MMA]: 94,380,032 = 94,380,032 + 0 [MR]: 111,149,056 = 111,149,056 + 0 [MMR]: 111,149,056 = 111,149,056 + 0
#
#
# ================================================================================ Epoch 1 Before Forward ================================================================================
# [MA]: 94,380,032 = 94,380,032 + 0 [MMA]: 94,380,032 = 94,380,032 + 0 [MR]: 111,149,056 = 111,149,056 + 0 [MMR]: 111,149,056 = 111,149,056 + 0
#
#
# ================================================================================ Epoch 1 After layer1 ================================================================================
# [MA]: 111,288,320 = 94,380,032 + 16,908,288 [MMA]: 111,288,320 = 94,380,032 + 16,908,288 [MR]: 132,120,576 = 111,149,056 + 20,971,520 [MMR]: 132,120,576 = 111,149,056 + 20,971,520
#
#
# ================================================================================ Epoch 1 After layer2 ================================================================================
# [MA]: 123,871,232 = 111,288,320 + 12,582,912 [MMA]: 123,871,232 = 111,288,320 + 12,582,912 [MR]: 144,703,488 = 132,120,576 + 12,582,912 [MMR]: 144,703,488 = 132,120,576 + 12,582,912
#
#
# ================================================================================ Epoch 1 After layer3 ================================================================================
# [MA]: 140,648,448 = 123,871,232 + 16,777,216 [MMA]: 140,648,448 = 123,871,232 + 16,777,216 [MR]: 161,480,704 = 144,703,488 + 16,777,216 [MMR]: 161,480,704 = 144,703,488 + 16,777,216
#
#
# ================================================================================ Epoch 1 Before Compute Loss ================================================================================
# [MA]: 140,648,448 = 140,648,448 + 0 [MMA]: 140,648,448 = 140,648,448 + 0 [MR]: 161,480,704 = 161,480,704 + 0 [MMR]: 161,480,704 = 161,480,704 + 0
#
#
# ================================================================================ Epoch 1 After Compute Loss ================================================================================
# [MA]: 157,426,688 = 140,648,448 + 16,778,240 [MMA]: 157,426,688 = 140,648,448 + 16,778,240 [MR]: 178,257,920 = 161,480,704 + 16,777,216 [MMR]: 178,257,920 = 161,480,704 + 16,777,216
#
#
# ================================================================================ Epoch 1 Before Backward ================================================================================
# [MA]: 157,426,688 = 157,426,688 + 0 [MMA]: 157,426,688 = 157,426,688 + 0 [MR]: 178,257,920 = 178,257,920 + 0 [MMR]: 178,257,920 = 178,257,920 + 0
#
#
# ================================================================================ Epoch 1 After Backward ================================================================================
# [MA]: 216,277,504 = 157,426,688 + 58,850,816 [MMA]: 233,055,232 = 157,426,688 + 75,628,544 [MR]: 287,309,824 = 178,257,920 + 109,051,904 [MMR]: 287,309,824 = 178,257,920 + 109,051,904
#
#
# ================================================================================ Epoch 1 Before Optimizer Step ================================================================================
# [MA]: 216,277,504 = 216,277,504 + 0 [MMA]: 233,055,232 = 233,055,232 + 0 [MR]: 287,309,824 = 287,309,824 + 0 [MMR]: 287,309,824 = 287,309,824 + 0
#
#
# ================================================================================ Epoch 1 After Optimizer Step ================================================================================
# [MA]: 392,438,272 = 216,277,504 + 176,160,768 [MMA]: 480,518,656 = 233,055,232 + 247,463,424 [MR]: 513,802,240 = 287,309,824 + 226,492,416 [MMR]: 513,802,240 = 287,309,824 + 226,492,416
#
#
# ================================================================================ Epoch 2 Before Optimizer Zero Grad ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 513,802,240 + -109,051,904 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After Optimizer Zero Grad ================================================================================
# [MA]: 304,357,888 = 392,438,272 + -88,080,384 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 Before Forward ================================================================================
# [MA]: 304,357,888 = 304,357,888 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After layer1 ================================================================================
# [MA]: 312,746,496 = 304,357,888 + 8,388,608 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After layer2 ================================================================================
# [MA]: 325,329,408 = 312,746,496 + 12,582,912 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After layer3 ================================================================================
# [MA]: 342,106,624 = 325,329,408 + 16,777,216 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 Before Compute Loss ================================================================================
# [MA]: 325,329,408 = 342,106,624 + -16,777,216 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After Compute Loss ================================================================================
# [MA]: 342,107,136 = 325,329,408 + 16,777,728 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 Before Backward ================================================================================
# [MA]: 342,107,136 = 342,107,136 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 404,750,336 = 404,750,336 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After Backward ================================================================================
# [MA]: 392,438,272 = 342,107,136 + 50,331,136 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 455,081,984 = 404,750,336 + 50,331,648 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 Before Optimizer Step ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 455,081,984 = 455,081,984 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 2 After Optimizer Step ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 505,413,632 = 455,081,984 + 50,331,648 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 Before Optimizer Zero Grad ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 505,413,632 + -92,274,688 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After Optimizer Zero Grad ================================================================================
# [MA]: 304,357,888 = 392,438,272 + -88,080,384 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 Before Forward ================================================================================
# [MA]: 304,357,888 = 304,357,888 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After layer1 ================================================================================
# [MA]: 312,746,496 = 304,357,888 + 8,388,608 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After layer2 ================================================================================
# [MA]: 325,329,408 = 312,746,496 + 12,582,912 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After layer3 ================================================================================
# [MA]: 342,106,624 = 325,329,408 + 16,777,216 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 Before Compute Loss ================================================================================
# [MA]: 325,329,408 = 342,106,624 + -16,777,216 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After Compute Loss ================================================================================
# [MA]: 342,107,136 = 325,329,408 + 16,777,728 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 Before Backward ================================================================================
# [MA]: 342,107,136 = 342,107,136 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 413,138,944 = 413,138,944 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After Backward ================================================================================
# [MA]: 392,438,272 = 342,107,136 + 50,331,136 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 463,470,592 = 413,138,944 + 50,331,648 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 Before Optimizer Step ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 463,470,592 = 463,470,592 + 0 [MMR]: 513,802,240 = 513,802,240 + 0
#
#
# ================================================================================ Epoch 3 After Optimizer Step ================================================================================
# [MA]: 392,438,272 = 392,438,272 + 0 [MMA]: 480,518,656 = 480,518,656 + 0 [MR]: 513,802,240 = 463,470,592 + 50,331,648 [MMR]: 513,802,240 = 513,802,240 + 05. 复现代码
在本节中我将通过代码来复现第 2 节中总结的一些关键论断。为此,我实现了一个名为memory_stats()的函数,它是对 PyTorch 显存管理高阶 API 的简单封装:
operation requested memory:执行当前操作实际所需的显存大小
operation allocated memory:执行当前操作实际所分配的 Block 大小
operation reserved memory:执行当前操作所需的 Segment 大小,以及该 Segment 属于 small pool 还是 large pool
total reserved memory:当前所有 Segments 大小的总和,以及每个 pool 各有几个 Segments
total active memory:当前所有已分配 Blocks 大小的总和,以及每个 pool 各有几个已分配 Blocks
total inactive memory:当前所有未分配 Blocks 大小的总和,以及每个 pool 各有几个未分配 Blocks
import torch
r, ma, mr, mr_s, mr_l = 0, 0, 0, 0, 0
def sep(num):
if num % 2 ** 20 == 0:
return f"{num} = {num // 2 ** 20}MB"
else:
return f"{num} ≈ {num / 2 ** 20:.4f}MB"
def memory_stats(device=0):
d = torch.cuda.memory_stats(device)
global r, ma, mr, mr_s, mr_l
last_r, last_ma, last_mr, last_mr_s, last_mr_l = r, ma, mr, mr_s, mr_l
r = d["requested_bytes.all.current"]
ma = d["allocated_bytes.all.current"]
mr = d["reserved_bytes.all.current"]
mr_s, mr_l = d["segment.small_pool.current"], d["segment.large_pool.current"]
mat = d["active_bytes.all.current"]
miat = d["inactive_split_bytes.all.current"]
if mr_s - last_mr_s == 1 and mr_l - last_mr_l == 0:
cur_mr_tag = 'new segment belong to small pool'
elif mr_s - last_mr_s == 0 and mr_l - last_mr_l == 1:
cur_mr_tag = 'new segment belong to large pool'
elif mr_s - last_mr_s == 0 and mr_l - last_mr_l == 0:
cur_mr_tag = 'no new segment'
else:
raise ValueError
mr_tag = f'small_pool({mr_s}) large_pool({mr_l})'
mat_tag = f'small_pool({d["active.small_pool.current"]}) large_pool({d["active.large_pool.current"]})'
miat_tag = f'small_pool({d["inactive_split.small_pool.current"]}) large_pool({d["inactive_split.large_pool.current"]})'
assert mat + miat == mr # 已分配显存 + 未分配显存 = Segments 总和
assert mat == ma
print("")
print(f"operation requested memory : {sep(r-last_r).rjust(20)}")
print(f"operation allocated memory : {sep(ma-last_ma).rjust(20)}")
print(f"operation reserved memory : {sep(mr-last_mr).rjust(20)} {cur_mr_tag}")
print(f"total reserved memory : {sep(mr).rjust(20)} {mr_tag}")
print(f"total active memory : {sep(mat).rjust(20)} {mat_tag}")
print(f"total inactive memory : {sep(miat).rjust(20)} {miat_tag}")5.1 Segment
张量的尺寸可以随意更改,相关结论请回看 2.1.1。
var1 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
print(torch.cuda.memory_reserved())5.2 Requested Size 和 Allocated Size
每次任选一段运行,全部运行总计需要 10 到 20 分钟,相关结论请回看 2.1.3。
# for i in range(1, 1024*1024+1):
# # tensor_size: [1B, 1MB], Segment: 2MB, 相当于从 2MB Block 中分配 tensor
# var = torch.zeros(i, dtype=torch.bool, device='cuda')
# if i % 512 == 0:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == i
# else:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == (i // 512 + 1) * 512, print("cur:", i)
# del var
# for i in range(1024*1024+1, 1024*1024*10-512+1):
# # tensor_size: (1MB, 10MB-512B], Segment: 20MB, 相当于从 20MB Block 中分配 tensor
# var = torch.zeros(i, dtype=torch.bool, device='cuda')
# if i % 512 == 0:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == i
# else:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == (i // 512 + 1) * 512, print("cur:", i)
# del var
# for i in range(1024*1024*10-512+1, 1024*1024*10+1):
# # tensor_size: (10MB-512B, 10MB], Segment: 10MB, 相当于从 10MB Block 中分配 tensor
# var = torch.zeros(i, dtype=torch.bool, device='cuda')
# if i % 512 == 0:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == i
# else:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == (i // 512 + 1) * 512, print("cur:", i)
# del var
# for i in range(1024*1024*10+1, 1024*1024*11-512+1):
# # tensor_size: (10MB, 11MB-512B], Segment: 12MB, 相当于从 12MB Block 中分配 tensor
# var = torch.zeros(i, dtype=torch.bool, device='cuda')
# if i % 512 == 0:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == i
# else:
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == (i // 512 + 1) * 512, print("cur:", i)
# del var
# j = 12 # ≥12的任意偶数
# for i in range(1024*1024*(j-1)-511, 1024*1024*j+1):
# # tensor_size: (11MB-512B, 12MB], Segment: 12MB, 相当于从 12MB Block 中分配 tensor
# var = torch.zeros(i, dtype=torch.bool, device='cuda')
# assert torch.cuda.memory_stats()["allocated_bytes.all.current"] == j * 1024 * 1024
# del var
# var1 = torch.zeros(1024*1024*3, dtype=torch.bool, device='cuda') # 3MB
# memory_stats()
# var2 = torch.zeros(1024*1024*17, dtype=torch.bool, device='cuda') # 17MB
# memory_stats()
# del var1
# memory_stats()
# var3 = torch.zeros(1024*1024*2, dtype=torch.bool, device='cuda') # 2MB
# memory_stats()
# 运行结果:
# operation requested memory : 3145728 = 3MB
# operation allocated memory : 3145728 = 3MB
# operation reserved memory : 20971520 = 20MB new segment belong to large pool
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 3145728 = 3MB small_pool(0) large_pool(1)
# total inactive memory : 17825792 = 17MB small_pool(0) large_pool(1)
#
# operation requested memory : 17825792 = 17MB
# operation allocated memory : 17825792 = 17MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 20971520 = 20MB small_pool(0) large_pool(2)
# total inactive memory : 0 = 0MB small_pool(0) large_pool(0)
#
# operation requested memory : -3145728 = -3MB
# operation allocated memory : -3145728 = -3MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 17825792 = 17MB small_pool(0) large_pool(1)
# total inactive memory : 3145728 = 3MB small_pool(0) large_pool(1)
#
# operation requested memory : 2097152 = 2MB
# operation allocated memory : 3145728 = 3MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 20971520 = 20MB small_pool(0) large_pool(2)
# total inactive memory : 0 = 0MB small_pool(0) large_pool(0)5.3 Large Pool 和 Small Pool
每次任选一段运行,相关结论请回看 2.1.2。
# 示例1
# var1 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# var2 = torch.zeros(2, dtype=torch.bool, device='cuda') # 2B
# memory_stats()
# 运行结果:
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 1048576 = 1MB small_pool(1) large_pool(0)
# total inactive memory : 1048576 = 1MB small_pool(1) large_pool(0)
#
# operation requested memory : 2 ≈ 0.0000MB
# operation allocated memory : 512 ≈ 0.0005MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 1049088 ≈ 1.0005MB small_pool(2) large_pool(0)
# total inactive memory : 1048064 ≈ 0.9995MB small_pool(1) large_pool(0)
# 示例2
# var1 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# var2 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# 运行结果:
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 1048576 = 1MB small_pool(1) large_pool(0)
# total inactive memory : 1048576 = 1MB small_pool(1) large_pool(0)
#
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 2097152 = 2MB small_pool(2) large_pool(0)
# total inactive memory : 0 = 0MB small_pool(0) large_pool(0)
# 示例3
# var1 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# var2 = torch.zeros(1024*1024+2, dtype=torch.bool, device='cuda') # 略大于1MB
# memory_stats()
# 运行结果:
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 1048576 = 1MB small_pool(1) large_pool(0)
# total inactive memory : 1048576 = 1MB small_pool(1) large_pool(0)
#
# operation requested memory : 1048578 ≈ 1.0000MB
# operation allocated memory : 1049088 ≈ 1.0005MB
# operation reserved memory : 20971520 = 20MB new segment belong to large pool
# total reserved memory : 23068672 = 22MB small_pool(1) large_pool(1)
# total active memory : 2097664 ≈ 2.0005MB small_pool(1) large_pool(1)
# total inactive memory : 20971008 ≈ 19.9995MB small_pool(1) large_pool(1)
# 示例4
# var1 = torch.zeros(2, dtype=torch.bool, device='cuda') # 2B
# memory_stats()
# var2 = torch.zeros(1024*1024+2, dtype=torch.bool, device='cuda') # 略大于1MB
# memory_stats()
# 运行结果:
# operation requested memory : 2 ≈ 0.0000MB
# operation allocated memory : 512 ≈ 0.0005MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 2097152 = 2MB small_pool(1) large_pool(0)
# total active memory : 512 ≈ 0.0005MB small_pool(1) large_pool(0)
# total inactive memory : 2096640 ≈ 1.9995MB small_pool(1) large_pool(0)
#
# operation requested memory : 1048578 ≈ 1.0000MB
# operation allocated memory : 1049088 ≈ 1.0005MB
# operation reserved memory : 20971520 = 20MB new segment belong to large pool
# total reserved memory : 23068672 = 22MB small_pool(1) large_pool(1)
# total active memory : 1049600 ≈ 1.0010MB small_pool(1) large_pool(1)
# total inactive memory : 22019072 ≈ 20.9990MB small_pool(1) large_pool(1)
# 示例5
# var1 = torch.zeros(1024*1024*11, dtype=torch.bool, device='cuda') # 11MB
# memory_stats()
# var2 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# 运行结果:
# operation requested memory : 11534336 = 11MB
# operation allocated memory : 12582912 = 12MB
# operation reserved memory : 12582912 = 12MB new segment belong to large pool
# total reserved memory : 12582912 = 12MB small_pool(0) large_pool(1)
# total active memory : 12582912 = 12MB small_pool(0) large_pool(1)
# total inactive memory : 0 = 0MB small_pool(0) large_pool(0)
#
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 14680064 = 14MB small_pool(1) large_pool(1)
# total active memory : 13631488 = 13MB small_pool(1) large_pool(1)
# total inactive memory : 1048576 = 1MB small_pool(1) large_pool(0)
# 示例6
# var1 = torch.zeros(1024*1024*2, dtype=torch.bool, device='cuda') # 2MB
# memory_stats()
# var2 = torch.zeros(1024*1024*17, dtype=torch.bool, device='cuda') # 17MB
# memory_stats()
# var3 = torch.zeros(1024*1024, dtype=torch.bool, device='cuda') # 1MB
# memory_stats()
# 运行结果:
# operation requested memory : 2097152 = 2MB
# operation allocated memory : 2097152 = 2MB
# operation reserved memory : 20971520 = 20MB new segment belong to large pool
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 2097152 = 2MB small_pool(0) large_pool(1)
# total inactive memory : 18874368 = 18MB small_pool(0) large_pool(1)
#
# operation requested memory : 17825792 = 17MB
# operation allocated memory : 18874368 = 18MB
# operation reserved memory : 0 = 0MB no new segment
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 20971520 = 20MB small_pool(0) large_pool(2)
# total inactive memory : 0 = 0MB small_pool(0) large_pool(0)
#
# operation requested memory : 1048576 = 1MB
# operation allocated memory : 1048576 = 1MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 23068672 = 22MB small_pool(1) large_pool(1)
# total active memory : 22020096 = 21MB small_pool(1) large_pool(2)
# total inactive memory : 1048576 = 1MB small_pool(1) large_pool(0)
# 示例7
# var1 = torch.zeros(1024*1024*2, dtype=torch.bool, device='cuda') # 2MB
# memory_stats()
# var2 = torch.zeros(4, dtype=torch.bool, device='cuda') # 4B
# memory_stats()
# 运行结果:
# operation requested memory : 2097152 = 2MB
# operation allocated memory : 2097152 = 2MB
# operation reserved memory : 20971520 = 20MB new segment belong to large pool
# total reserved memory : 20971520 = 20MB small_pool(0) large_pool(1)
# total active memory : 2097152 = 2MB small_pool(0) large_pool(1)
# total inactive memory : 18874368 = 18MB small_pool(0) large_pool(1)
#
# operation requested memory : 4 ≈ 0.0000MB
# operation allocated memory : 512 ≈ 0.0005MB
# operation reserved memory : 2097152 = 2MB new segment belong to small pool
# total reserved memory : 23068672 = 22MB small_pool(1) large_pool(1)
# total active memory : 2097664 ≈ 2.0005MB small_pool(1) large_pool(1)
# total inactive memory : 20971008 ≈ 19.9995MB small_pool(1) large_pool(1)6. 参考
PyTorch显存管理介绍与源码解析(一)(https://zhuanlan.zhihu.com/p/680769942)
PyTorch显存管理介绍与源码解析(二)(https://zhuanlan.zhihu.com/p/681651660)
Connolly:PyTorch显存机制分析(https://zhuanlan.zhihu.com/p/424512257)
Understanding CUDA Memory Usage — PyTorch main documentation(https://pytorch.org/docs/main/torch_cuda_memory.html%23understanding-cuda-memory-usage)
如有错误,欢迎指正 ~
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









