






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享南大&南理工等团队ECCV2024的工作Text2LiDAR!本文探索了一种文本引导激光雷达点云生成的Transformer框架,在KITTI-360和nuScenes数据集上取得了优异的无条件生成和文本引导生成点云结果。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Yang Wu等
编辑 | 自动驾驶之心
论文题目:《Text2LiDAR: Text-guided LiDAR Point Cloud Generation via Equirectangular Transformer》
论文地址:https://arxiv.org/pdf/2407.19628
代码地址:https://github.com/wuyang98/Text2LiDAR
一句话概括
本文探索了一种文本引导激光雷达点云生成的Transformer框架,以序列到序列的方式,利用等距圆柱投影注意力机制在KITTI-360和nuScenes数据集上取得了优异的无条件生成和文本引导生成点云结果。
摘要
复杂的交通环境和多变的天气条件使得激光雷达数据的收集既昂贵又困难。实现高质量、可控的激光雷达数据生成十分有必要,而对文本控制的激光雷达点云生成的研究仍然不足。为此,本文提出了Text2LiDAR,这是第一个高效、多样化且可通过文本控制的激光雷达数据生成框架。为了提升文本控制生成性能,本文构建了nuLiDARtext,它为850个场景中的34,149个激光雷达点云提供了多样化的文本描述符。在KITTI-360和nuScenes数据集上的实验展示了本文方法的优越性。
背景
1.为什么需要生成激光雷达数据?
激光雷达点云可以提供准确的3D结构信息和距离信息,这使得激光雷达成为诸多无人自主任务必备的传感器,如自动驾驶、遥感测绘、场景探索等。然而激光雷达点云数据的采集却十分不易,昂贵的设备和人工开销令人望而却步,同时,特定场景的点云数据采集窗口期十分短暂,甚至存在着安全风险,这都使激光雷达点云数据的获取相较于其他模态更为困难。也因此,利用生成模型进行高保真的激光雷达点云数据生成十分有意义,有望缓解激光雷达点云数据获取困难的问题。
2. 本领域中激光雷达点云数据怎么表示?

3. 实现文本引导生成激光雷达点云主要面临两项挑战
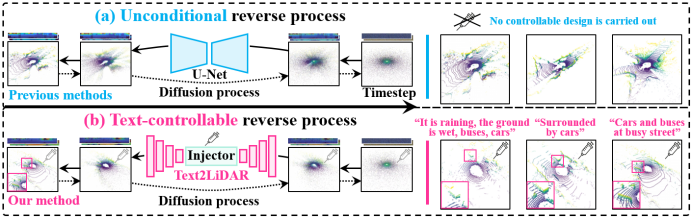
(1)目前本领域没有专门为等距圆柱投影图像和文本设计的生成框架。与目标级别的点云不同,户外的激光雷达点云更加的不规则和稀疏。在涉及到自动驾驶场景的激光雷达点云处理时,相关工作[1,2,3]往往会将激光雷达点云投影为等距圆柱投影图像以缓解激光雷达点云的不规则性和稀疏性。在此基础上,Nakashima等人[4,5]将真实数据中的激光点的缺失现象纳入考虑,并设计了GAN网络来生成数据。为了进一步提升生成数据的真实性,如图1(a)所示,LiDARGen[6]和R2DM[7]设计了以U-Net去噪结构的扩散模型,然而在卷积方框中提取特征的方式破坏了等距圆柱投影图像的环形结构,稀释了像素间的关联。同时,卷积框架的可拓展性有限,在适配来自不同模态的控制型号时,很不方便且效率低下。此外,一些现有的方法也忽视了等距矩形投影图像中的高频信息与点云目标结构之间的对应关系。这些都促使我们去探索一个统一的可控生成结构,使其能与等距矩形投影图像和多模态信号兼容。
(3)现有的数据集没有提供高质量的文本-激光雷达点云数据对[8, 9, 10, 11]。高质量的文本描述词不仅需要描述激光雷达点云中存在的目标,更需要描述天气、光照、环境结构等关键信息,这些辅助信息的利用可以明显的提升点云生成的质量,如图1(b)所示,这些信息共同构成了一帧相对完善的自动驾驶场景的激光雷达点云数据。如何构建高质量的文本-单帧激光雷达点云数据也是一个需要解决的问题。
方法

为了解决以上提到的两项挑战,我们提出了Text2LiDAR,这是一个Transformer结构,可以更好地适配等距圆柱投影图像的环状特性,保持任意像素点之间的关联性。得益于序列到序列的特征处理方式,Text2LiDAR可以很便捷地增删多模态控制型号。此外,本文构建的nuLiDARtext在nuScenes的基础上为激光雷达点云提供了丰富且合理的文本描述词,可以更好地促进文本控制的激光雷达点云生成。
如图2所示,我们的Text2LiDAR具体计算流程如下:
首先,我们对正常激光雷达点云添加噪声得到了扰动的雷达点云(Perturbed LiDAR)输入,然后将其送进等距圆柱投影Transformer中进行无条件的噪声预测或在文本信息引导下的噪声预测,经过处理后的输出特征再送入频率调制器(Frequnency Modulator)用于自适应频率调制,最后输出就得到了预测噪声(predicted noise)。在数据生成时,我们可以通过对纯噪声的逐步去噪得到了我们最后生成的雷达点云图。
接下来,我们分别介绍流程中关键的四个组成部分:
1. 等距圆柱投影Transformer (Equirectangular Transformer Network)

在此部分本文设计了如图3所示的等距圆柱投影注意力(EA)适配等距圆柱投影图像。首先,本文利用自注意力适应等距圆柱投影无边界的特性。其次,本文利用傅里叶特征,并将高度角和方位角扩展为二的幂的频率分量。这保留了3D先验,同时放大了邻近位置之间的差异,有助于模型更好地学习。接着,本文使用相互重叠的展开方式,将输入序列在不同阶段切割成不同尺度,强化局部建模,这个过程可以表述为:

在解码部分,本文设计了反向等距圆柱投影注意力(REA)进行上采样,允许持续捕捉全局到局部的关系。为了更好地恢复对象细节,本文引入了编码阶段的特征。同时,为了增强嵌入对模型的引导,本文在每个上采样阶段使用设计好的控制信号嵌入注入器(CEI)来提供控制。通过四个阶段的上采样,本文可以将标记序列上采样到高分辨率,与输入尺寸相匹配。
这个过程可以写成:
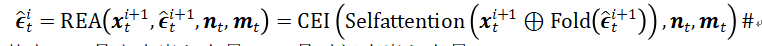
其中,是文本嵌入向量,是时间步嵌入向量。
2. 控制信号注入器(Control-signal Embedding Injector)


3. 频率调制器(Frequency Modulator)
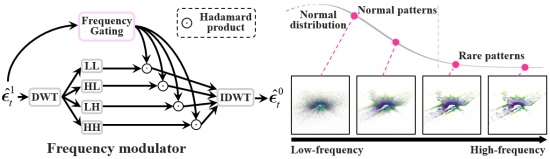
扩散模型总是倾向于首先恢复低频信息,然后逐渐恢复高频信息,本文设计了一个频率调制器(FM),允许模型自适应地专注于高频信息。其过程主要包含离散小波变换(DWT)、由卷积组成的频率门控函数(FG)和逆离散小波变换(IDWT),可以描述为:
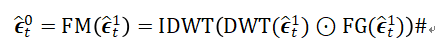
4. 构建nuLiDARtext

nuScenes数据集中的文本描述旨在描述短时间内的场景,并没有特别为激光雷达数据配对。为了节省资源和成本,本文在现有的nuScenes数据集上构建了适用于单帧激光雷达点云生成的文本描述词,描述词的出现频次如图6所示,通过提供路况、光照、天气等更全面的描述词,文本才能更准确地描述出一帧自动驾驶场景的激光雷达点云数据,从而引导更符合实际的数据生成。
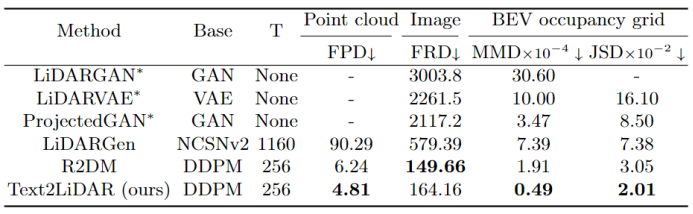
实验结果
在无条件生成时,本文方法与当前领先的方法就行了对比,展现了优异的性能:
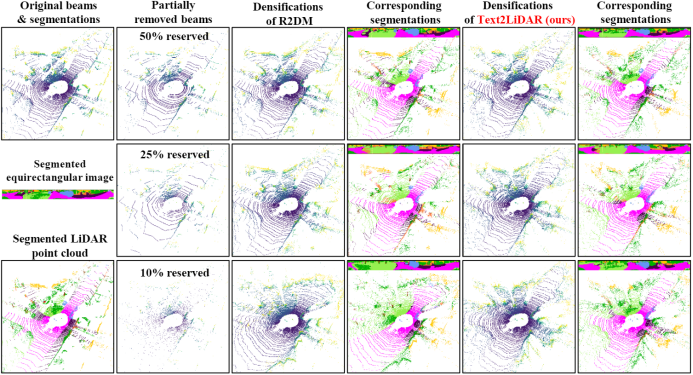
本文方法在激光雷达点云稠密化任务上也能取得不错的效果,针对远处的小目标的补全效果更佳:
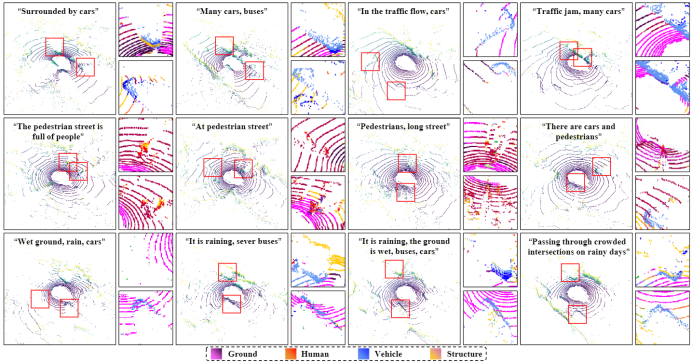
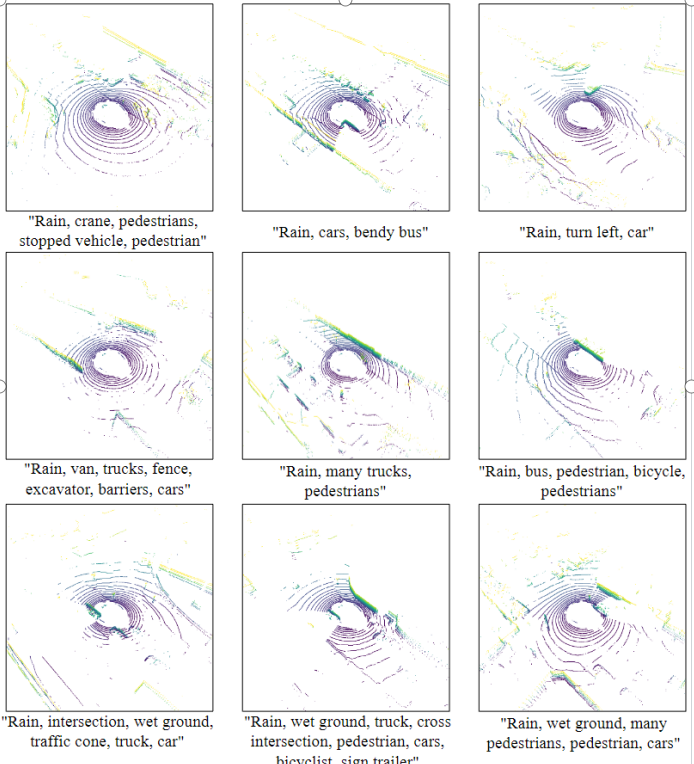
在文本控制激光雷达点云生成时,也有有趣的结果,除了对大目标和小目标有一定的区分能力,本文方法可以很好地生成受天气影响时的针对性数据,例如雨天激光雷达光束随着距离增加逐步丢失的特性得到了很好地体现,在图9中对雨天数据生成进行了更多展示。
参考文献:
[1] Chai et al. To the point: Efficient 3d object detection in the range image with
graph convolution kernels. CVPR 2021.
[2] Meyer et al. Lasernet: An efficient probabilistic 3d object detector for autonomous driving. CVPR 2019.
[3] Milioto et al. Rangenet++: Fast and accurate lidar semantic segmentation. IROS 2019.
[4] Nakashima et al. Generative range imaging for learning scene priors of 3d lidar data. WACV 2023.
[5] Nakashima et al. Learning to drop points for lidar scan synthesis. IROS 2021.
[6] Zyrianov et al. Learning to generate realistic lidar point clouds. ECCV 2022.
[7] Nakashima et al. Lidar data synthesis with denoising diffusion probabilistic models. arXiv 2309.09256.
[8] Liao et al. A novel dataset and benchmarks for urban scene understanding in 2d and 3d. TPAMI 2022.
[9] Caesar et al. Nuscenes: A multimodal dataset for autonomous driving. CVPR 2022.
[10] Behley et al. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. ICCV 2019.
[11] Geiger et al. Vision meets robotics: The kitti dataset. IJRR 2013.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









