






作者 | 智元机器人
点击下方卡片,关注“具身智能之心”公众号
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
导 言
智元发布首个通用具身基座模型——智元启元大模型(Genie Operator-1),它开创性地提出了Vision-Language-Latent-Action (ViLLA) 架构,该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力,三者环环相扣,实现了可以利用人类视频学习,完成小样本快速泛化,降低了具身智能门槛,并成功部署到智元多款机器人本体,持续进化,将具身智能推上了一个新台阶。
研究论文:
https://agibot-world.com/blog/agibot_go1.pdf
2024年底,智元推出了 AgiBot World,包含超过100万条轨迹、涵盖217个任务、涉及五大场景的大规模高质量真机数据集。基于AgiBot World,智元今天正式发布智元通用具身基座大模型 Genie Operator-1(GO-1)。
01
GO-1:VLA进化到ViLLA
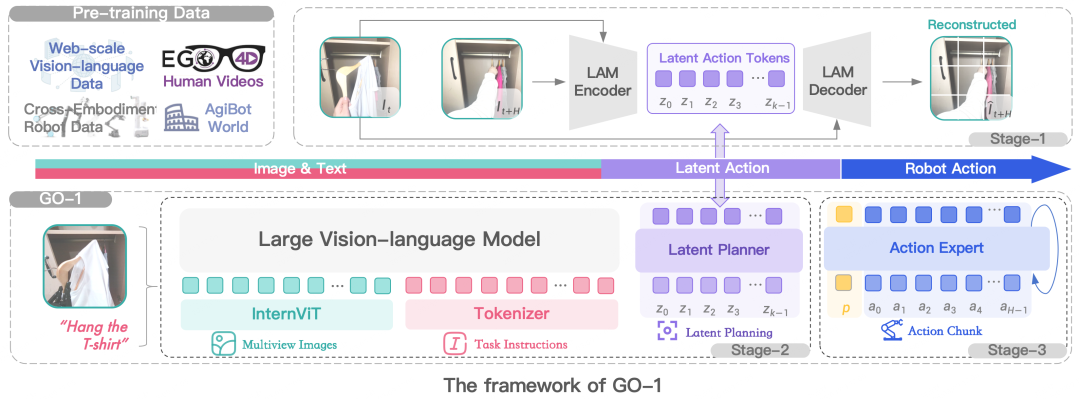
为了有效利用高质量的AgiBot World数据集以及互联网大规模异构视频数据,增强策略的泛化能力,智元提出了 Vision-Language-Latent-Action (ViLLA) 这一创新性架构。GO-1作为首个通用具身基座大模型,基于ViLLA构建。与Vision-Language-Action (VLA) 架构相比,ViLLA 通过预测Latent Action Tokens(隐式动作标记),弥合图像-文本输入与机器人执行动作之间的鸿沟。在真实世界的灵巧操作和长时任务方面表现卓越,远远超过了已有的开源SOTA模型。
ViLLA架构是由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力。在推理时,VLM、Latent Planner和Action Expert三者协同工作:
VLM 采用InternVL-2B,接收多视角视觉图片、力觉信号、语言输入等多模态信息,进行通用的场景感知和指令理解;
Latent Planner是MoE中的一组专家,基于VLM的中间层输出预测Latent Action Tokens作为CoP(Chain of Planning,规划链),进行通用的动作理解和规划;
Action Expert是MoE中的另外一组专家,基于VLM的中间层输出以及Latent Action Tokens,生成最终的精细动作序列;
下面展开介绍下MoE里2个关键的组成Latent Planner和Action Expert:

混合专家一:
Latent Planner(隐式规划器)
尽管AgiBot World 数据集已经是全球最大的机器人真机示教数据集,但这样高质量带动作标签的真机数据量仍然有限,远少于互联网规模的数据集。为此,我们采用Latent Actions(隐式动作)来建模当前帧和历史帧之间的隐式变化,然后通过Latent Planner预测这些Latent Actions,从而将异构数据源中真实世界的动作知识转移到通用操作任务中。
Latent Action Model(LAM,隐式动作模型)主要用于获取当前帧和历史帧之间Latent Actions的Groundtruth(真值),它由编码器和解码器组成。其中:
编码器采用Spatial-temporal Transformer,并使用Causal Temporal Masks(时序因果掩码)。
解码器采用Spatial Transformer,以初始帧和离散化的Latent Action Tokens作为输入。
Latent Action Tokens通过VQ-VAE的方式进行量化处理。
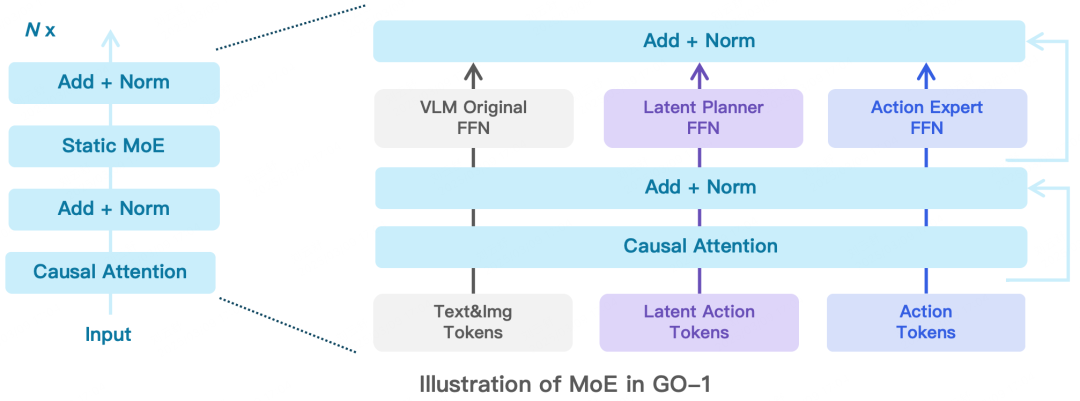
Latent Planner负责预测这些离散的Latent Action Tokens,它与VLM 主干网络共享相同的 Transformer 结构,但使用了两套独立的FFN(前馈神经网络)和Q/K/V/O(查询、键、值、输出)投影矩阵。Latent Planner这组专家会逐层结合 VLM 输出的中间信息,通过Cross Entropy Loss(交叉熵损失)进行监督训练。

混合专家二:
Action Expert(动作专家)
为了实现 High-frequency(高频率)且 Dexterous(灵活)的操控,我们引入Action Expert,其采用Diffusion Model作为目标函数来建模低层级动作的连续分布。
Action Expert结构设计上与Latent Planner类似,也是与 VLM 主干网络共享相同的 Transformer 结构,但使用两套独立的FFN和Q/K/V/O投影矩阵,它通过Denoising Process(去噪过程)逐步回归动作序列。
Action Expert与VLM、Latent Planner分层结合,确保信息流的一致性与协同优化。

实验效果
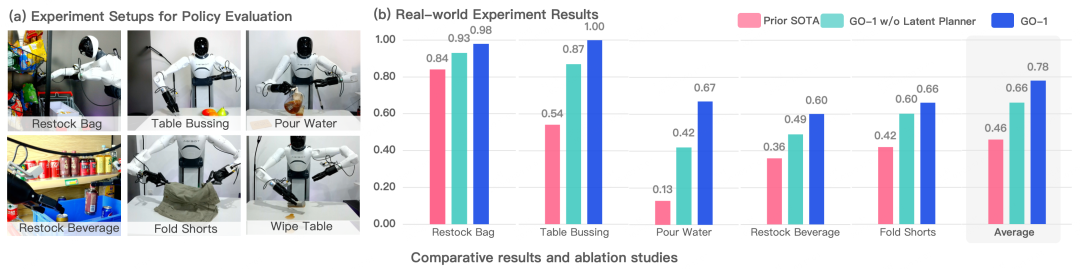
通过Vision-Language-Latent-Action (ViLLA) 创新性架构,我们在五种不同复杂度任务上测试 GO-1,相比已有的最优模型,GO-1成功率大幅领先,平均成功率提高了32%(46%->78%)。其中 “Pour Water”(倒水)、“Table Bussing”(清理桌面) 和 “Restock Beverage”(补充饮料) 任务表现尤为突出。此外我们还单独验证了ViLLA 架构中Latent Planner的作用,可以看到增加Latent Planner可以提升12%的成功率(66%->78%)。
02
GO-1:具身智能的全面创新
GO-1大模型借助人类和多种机器人数据,让机器人获得了革命性的学习能力,可泛化应用到各类的环境和物品中,快速适应新任务、学习新技能。同时,它还支持部署到不同的机器人本体,高效地完成落地,并在实际的使用中持续不断地快速进化。
这一系列的特点可以归纳为4个方面:
人类视频学习:GO-1大模型可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解,更好地为人类服务。
小样本快速泛化:GO-1大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低。
一脑多形:GO-1大模型是通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体,群体升智。
持续进化:GO-1大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。
智元通用具身基座大模型GO-1的推出,标志着具身智能向通用化、开放化、智能化方向快速迈进:
从单一任务到多种任务:机器人能够在不同场景中执行多种任务,而不需要针对每个新任务重新训练。
从封闭环境到开放世界:机器人不再局限于实验室,而是可以适应多变的真实世界环境。
从预设程序到指令泛化:机器人能够理解自然语言指令,并根据语义进行组合推理,而不再局限于预设程序。
GO-1大模型将加速具身智能的普及,机器人将从依赖特定任务的工具,向着具备通用智能的自主体发展,在商业、工业、家庭等多领域发挥更大的作用,通向更加通用全能的智能未来。

【具身智能之心】技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1000人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、强化学习全栈学习路线、具身智能感知学习路线、具身智能交互学习路线、视觉语言导航学习路线、触觉感知学习路线、多模态大模型学理解学习路线、多模态大模型学生成学习路线、大模型与机器人应用、机械臂抓取位姿估计学习路线、机械臂的策略学习路线、双足与四足机器人开源方案、具身智能与大模型部署等方向,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









