







前言
就在昨天,智元在AgiBot World「上海AI LAB与AgiBot公司合作推出」的基础上,发布首个通用具身基座模型——智元启元大模型Genie Operator-1,其提出了Vision-Language-Latent-Action (ViLLA) 架构「项目页面:opendrivelab.com/blog/agibot-world/,作者列表见此:48 authors」
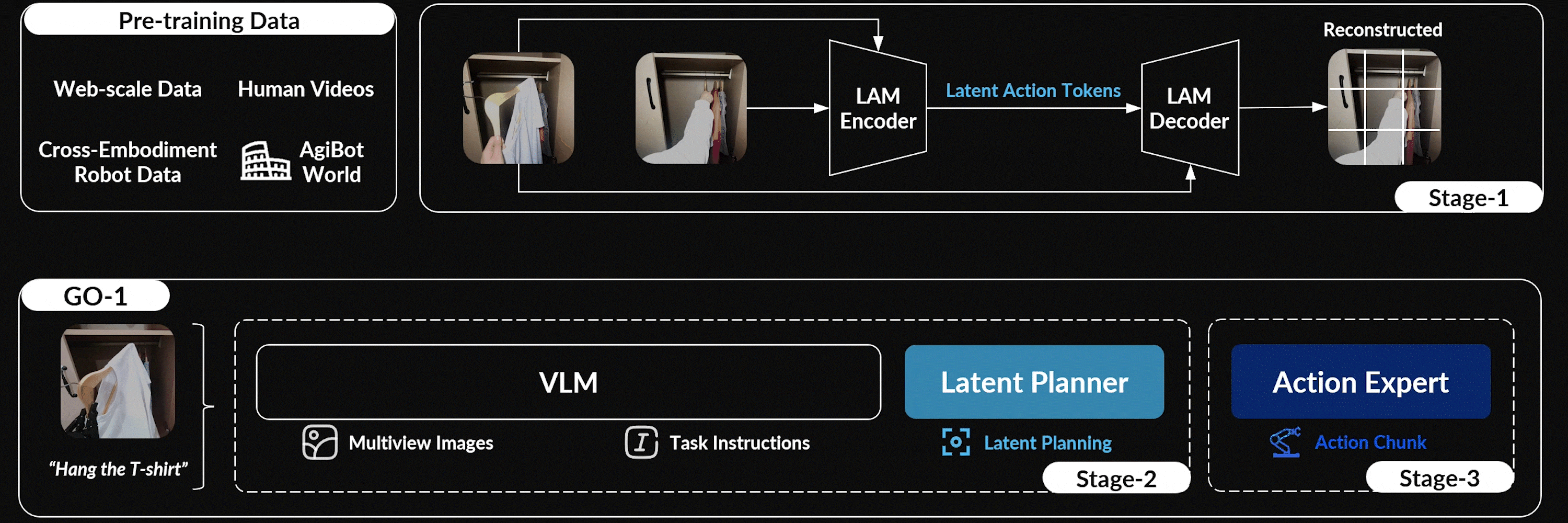
ViLLA 可以预测潜在动作token,从而弥合图像文本输入与动作专家生成的机器人动作之间的差距,该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中
- VLM借助海量互联网图文数据获得通用场景感知和语言理解能力
- MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力
- MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力
本文便来重点解读下这个ViLLA架构,然后在解读ViLLA的过程中看到了其重要参考LAPA,故本文第二部分 解读下LAPA
解读这个LAPA很有意义
- 因为提出ViLLA这个架构的论文《AgiBot World Colosseo: Large-scale Manipulation Platformfor Scalable and Intelligent Embodied Systems》只有8页
因篇幅限制,一些细节在原论文中没法充分阐述清楚,所以我在解读ViLLA的时候,有一些是依据论文上下文做的合理推测——后来通过阅读LAPA、moto等论文时 发现我的那些推测是正确的 比如LAM Encoder的训练细节、潜在规划器的训练细节等等,当然 这几个工作都是有各自的特点,且彼此之间是有不同之处的,对此 本文会强调,读者注意甄别- 让我感慨,自己这两年多下来看了一两百篇论文后对新论文中未透露细节的推测能力,某种程度上不也是机器人想追求的泛化能力么?
深入讲,让机器人完成指定任务或目标的过程中涉及一系列执行动作的定义,即动作轨迹的确定是很关键的,那怎么确定呢
首先,VLM可以做规划
但VLM的问题是其目前做高屋建瓴的顶层规划可以,可对于目前还不是很聪明的机器人而言,这个动作规划暂时还不够细致,使得机器人不太学得好、学得会
咋整,两种办法
- 一种是微调或预训练VLM呗,在VLM的基础上加上动作头(至于头的选择就多种多样了,可以最简单的LSTM,也可以diffusion model、流匹配、DiT),使其可以表达更细致的动作规划,从而成为Robotic VLM,比如23年11月的字节RoboFlamingo:首个开源的VLM机器人操作大模型(微调OpenFlamingo),比如Octo/TinyVLA、π0、CogACT「带下划线的便是做了预训练的」
且后续逐步演变成VLA,除了类似diffusion model作为专门的动作专家预测动作之外,还可以基于下一个token预测技术预测动作token,比如RT-2、OpenVLA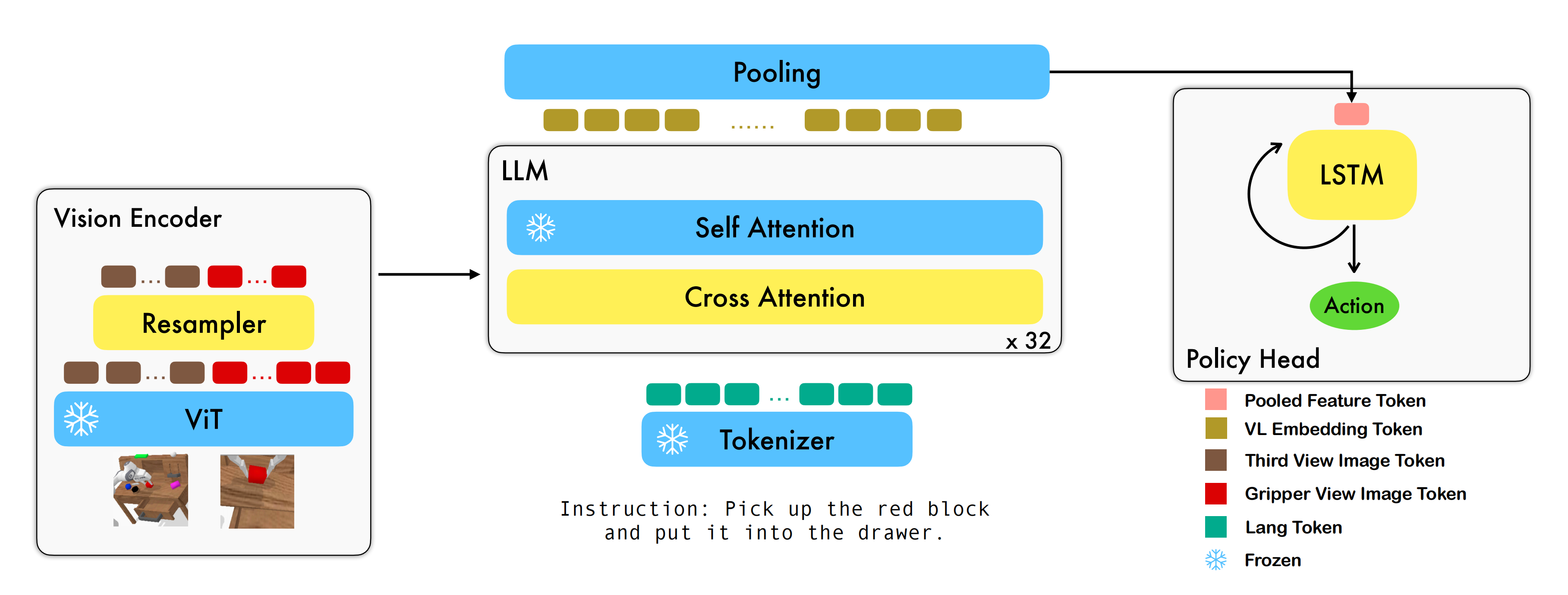
再深入一步,对于微调或预训练VLM而言,一个重要的问题便是训练数据的由来
- 要么基于大量的图像-文本数据和少量的机器人演示数据对训练机器人动作policy
比如RT-1、Palm-e、Rt-2、RoboFlamingo- 要么在大量带有动作标签的多样化跨机器人数据集上训练通用policy模型
比如CrossFormer、OpenVLA、Octo、Open X-Embodiment
上面中带下划线的是做了预训练的,更多细节详见此文《机器人大小脑的融合——从微调VLM到VLM+动作专家的VLA:详解RoboFlamingo、Octo、TinyVLA、DexVLA》,及此文《一次性总结数十个具身模型(2024-2025):从训练数据、动作预测、训练方法到Robotics VLM、VLA(如π0等)》的总结
- 一种是直接提示VLM规划的更细,且则机器人执行动作的过程中加一定的约束,比如李飞飞团队较早之前即23年7月份的VoxPoser(让模型生成动作规划的代码),以及23年11月清华一团队的ViLA(将高层次指令分解为一系列低层次技能)、24年3月的CoPa
详见《让VLM充当机器人大脑——VLM规划下加约束:从SayCan、VoxPoser到ViLA、CoPa、ReKep》
以及李飞飞团队的rekep都是类似的做法「详见此文《ReKep——李飞飞团队提出的让机器人具备空间智能:基于VLM模型GPT-4o和关系关键点约束(含源码解析)》」
对于这类方法,我刚开始看到时 顿觉惊艳..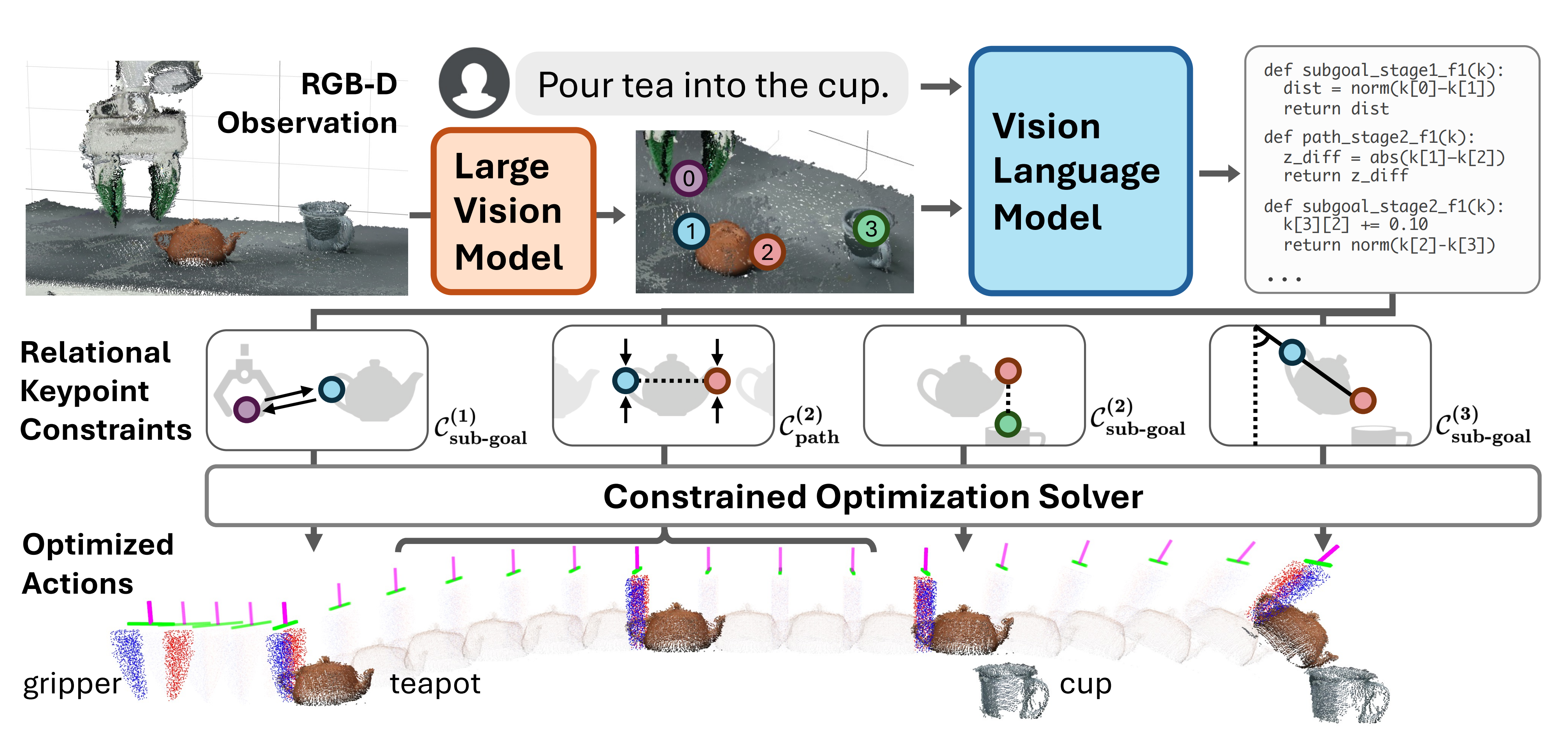
另外一拨人想,互联网上除了大量的图像文本数据外,还有海量的视频数据呀,而且对于很多复杂的场景,视频对精细动作的表达更直观、连续
- 让机器人从人类的视频中学习 这个方向由来已久,详见此文《基于人类视频的模仿学习与VLM推理规划:从DexMV、MimicPlay、SeeDo到人形OKAMI、Harmon(含R3M的详解)》,其中有讲到23年2月份发布的MimicPlay:李飞飞团队和NVIDIA提出的基于人类视频的模仿学习框架
- 其次,还有一系列工作让具身模型利用视频做视频预测或生成
比如字节GR2——在大规模视频数据集上预训练且机器人数据上微调,随后预测动作轨迹和视频(含GR1详解)
再比如,预测与动作扩散器PAD:通过联合去噪同时预测未来图像和动作
那如果想拿视频数据做训练,又有三种模式
- 拿指令-视频做生成式预训练的,比如字节提出来的GR-2,即给定一个指令,要求模型按照指令生成未来的视频——相当于未来一帧一帧的图像,然后与真实视频中的一帧一帧的图像对比、建loss

但不太好的点是,视频生成所需要消耗的算力成本比较大,字节这样的大公司耗得起,规模相对较小的科研团队 便不一定能耗得起了 - 给视频中的一帧帧做动作标注,然后监督微调机器人,使其学会各种复杂场景下细致动作的执行呢?
这里的问题是 机器人想真正学会,需要大量做了动作标注的视频,而这个动作标注 如果完全人工标,成本太大了啊
咋办,可否避免对视频做大量标注这个事情 - 而本文提到的Genie-24年2月
Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first generative interactive environment trained in an unsupervised manner from unlabelled Internet video)的基础世界模型
其训练数据集包含超过200000小时公开可用的互联网游戏视频,尽管没有动作或文本注释的训练(没有任何动作标签数据),但可以通过学习到的潜在动作空间逐帧进行控制
(Our approach, Genie, is trained from a large dataset of over 200,000 hours of publicly available Internet gaming videos and, despite training without action or text annotations, is controllable on a frame-by-frame basis via a learned latent action space)
详见此文《Google发布Genie硬杠Sora(含Genie 2):通过大量无监督视频训练最终生成可交互虚拟世界》
以及LAPA-24年10月、Moto-24年12月、ViLLA-25年3月便是基于大量无监督的视频数据 做训练
第一部分 ViLLA架构:Vision-Language-Latent-Action
1.1 百万级规模的AgiBot World简介、训练数据组成、硬件详情
1.1.1 AgiBot World Colosseo:包含数据、模型的大规模机器人操作平台
上海人工智能实验室与AgiBot公司合作推出的AgiBot World Colosseo,是一个全栈式大规模机器人学习平台,旨在推动可扩展和智能化的体感系统中的双手操作研究
他们建造了一个总面积达4000平方米的设施,涵盖五个主要领域——家庭、零售、工业、餐厅和办公室环境——专用于在真实的日常场景中进行高保真数据收集
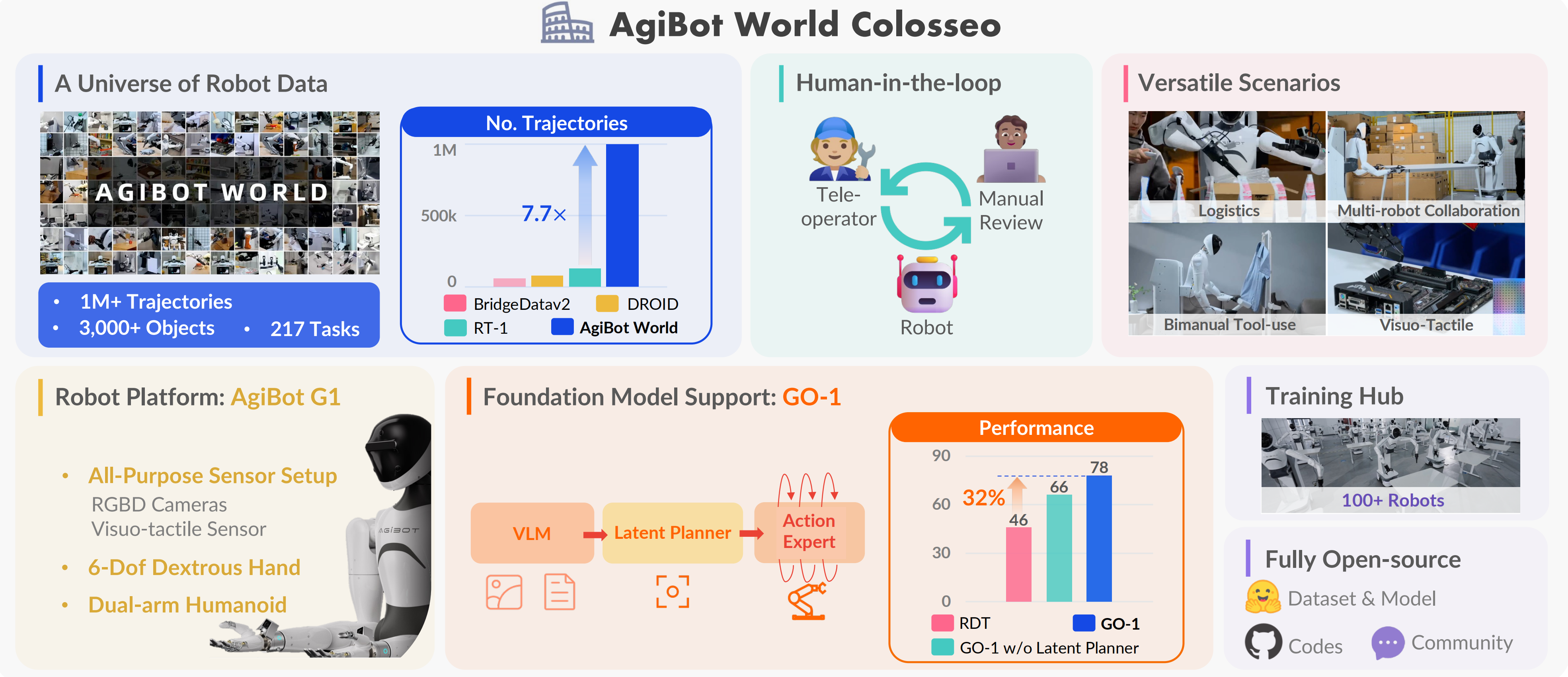
- AgiBot World从100个真实机器人收集了超过100万条轨迹「上一个广为流传的百万级规模的还是Open X数据集,详见此文《Google视觉机器人超级汇总:从RT、PaLM-E、RT-2到RT-X、RT-H(含Open X-Embodiment数据集详解)》的第四部分」,提供了前所未有的多样性和复杂性。它涵盖了超过100个现实场景,解决了诸如细粒度操作、工具使用和多机器人协同合作等具有挑战性的任务
- 硬件配置包括配备全身控制的移动底盘类人机器人(双7自由度手臂,腰部可调节)、6自由度的灵巧手、视觉触觉传感器,支持丰富的多模态数据收集
每个实验步骤都经过精心设计,包含多个摄像机视角、深度信息、摄像机校准以及针对整体任务和每个单独子步骤的语言标注 - 他们称,即使仅使用他们数据集的一小部分——相当于OXE数据量的1/10的小时数——预训练策略的泛化能力提升了18%
且为了解决以往机器人基础模型过度依赖于领域内机器人数据集的局限性,他们提出了Genie Operator-1(GO-1),一种新颖的通用策略,它利用潜在动作表示来实现从异构数据中学习,并高效地将通用视觉语言模型(VLM)与机器人序列决策相结合
通过对网络规模数据的统一预训练,从人类视频到高质量的机器人数据集,GO-1实现了卓越的泛化性和灵活性,优于先前的通用策略如RDT [10]以及不带潜在动作规划器的变体
1.1.2 policy训练的数据来源
如博客内其他文章所述,也如这篇论文所述
- 一些先前的研究仅使用网络规模的视频来辅助政策学习,因为动作标注机器人数据集的规模有限 [21], [22], [23]
- 另一条研究方向是使用大规模的、端到端的模型,这些模型通过机器人数据规模的扩展在机器人轨迹上训练 [4], [24], [14], [25],例如
RDT [10] 使用扩散变换器,最初在异构多机器人数据集上进行预训练,并在超过6k的双臂轨迹上进行微调,展示了在多样化来源上预训练的优势
这个LAPA是一种无需真实机器人动作标签即可对机器人基础模型进行无监督预训练的方法,它是ViLLA的最重要的参考——某种程度上,我认为ViLLA的提出便是受此LAPA及相关工作Moto的启发,下文的第二部分、第三部分会分别介绍下
他们通过将网络规模的知识转移到机器人控制领域,且通过适配具有潜在动作的视觉语言模型(VLMs),利用人类视频和机器人数据进行可扩展的训练
如下图图2所示,数据收集会话可以大致分为三个阶段
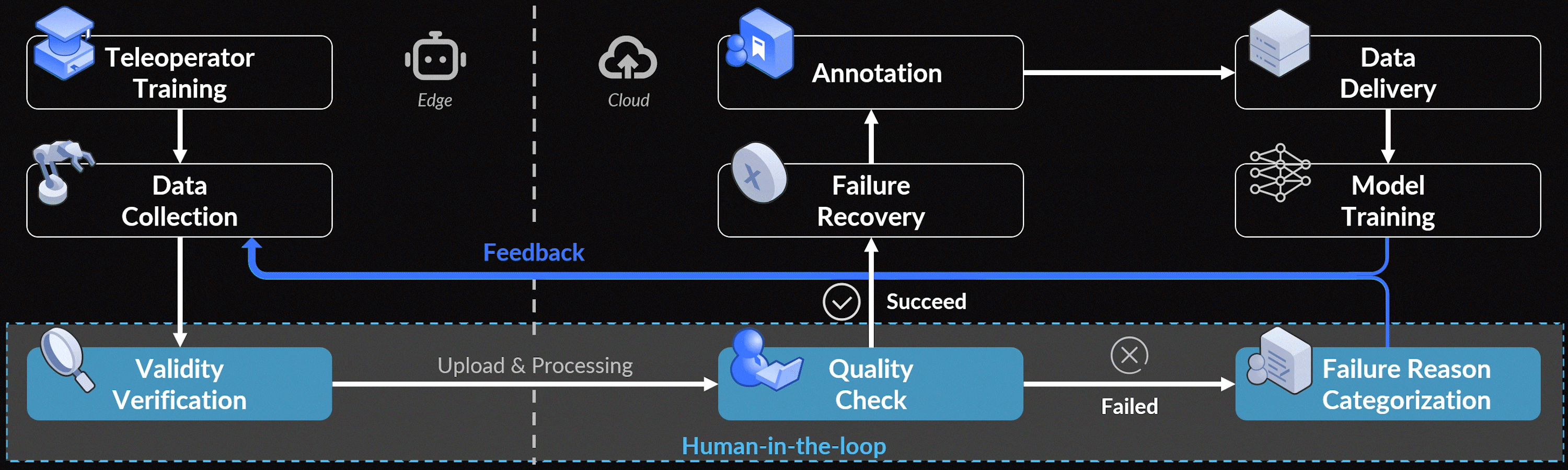
- 在正式开始数据收集之前,首先进行初步的数据获取,以验证每项任务的可行性并建立相应的收集标准
- 在可行性验证和收集标准审查之后,熟练的远程操作员安排初始场景并根据已建立的标准正式开始数据收集。所有数据都在本地进行初步有效性验证
例如验证是否存在缺失帧,一旦确认数据完整,就会上传到云端进行下一阶段,否则不传云端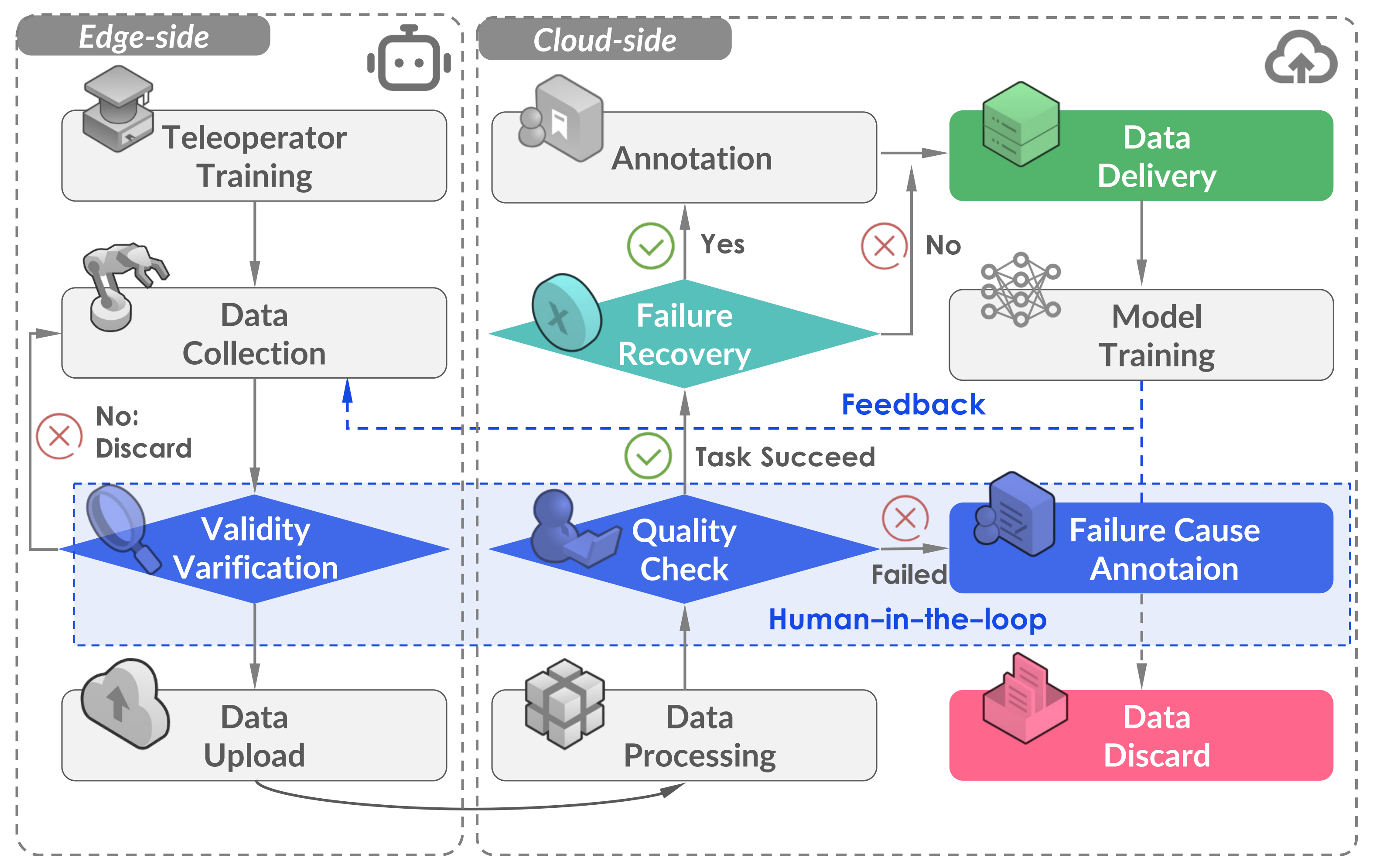
- 在后处理过程中,数据标注员将验证每个片段是否符合第一阶段制定的采集标准,并提供语言标注
此外,他们还做了两项保持措施
一项是故障恢复
- 在数据收集过程中,远程操作员可能偶尔会犯错误,例如在操作机械臂时不小心掉落物体。然而,他们通常能够从这些错误中恢复过来,并成功完成任务,而无需对设置进行完全重新配置。与其丢弃这些轨迹,他们保留它们并手动注释每个失败原因和时间戳。这些轨迹称为故障恢复数据,约占数据集的百分之一
- 他们认为它们对于实现政策对齐[28]和故障反思[29]至关重要,这对于推进下一代机器人基础模型至关重要
另一项是人类参与
- 在从数据注释者收集反馈的同时,采用了一种人类参与的方法来评估和改进数据质量。此过程包括收集一小部分演示、训练一个策略以及部署生成的策略以评估数据可用性的迭代循环
- 根据策略的性能,迭代地优化数据收集管道以解决发现的差距或低效。例如,在实际部署期间,模型在动作开始时表现出较长的停顿,这与数据注释者反馈中指出的收集数据中的不一致过渡和过多空闲时间一致
作为回应,他们修改了数据收集协议并引入了后处理步骤以消除空闲帧,从而提高了数据集对策略学习的整体实用性。这种基于反馈的方法确保了数据质量的持续改进
1.1.3 硬件详情
- 末端执行器是模块化的,可以根据任务需求使用标准夹持器或6自由度灵巧手。对于需要触觉反馈的任务,使用配备视觉触觉传感器的夹持器
- 机器人配备了八个摄像头:一个RGB-D摄像头和三个用于前视的鱼眼摄像头,安装在每个末端执行器上的RGB-D或鱼眼摄像头,以及两个后置的鱼眼摄像头
从而方便获取图像观测和本体感知状态(包括关节和末端执行器位置)以30 Hz的控制频率记录 - 他们采用了两种遥操作系统:VR头戴设备控制和全身动作捕捉控制
1.2 视觉-语言-潜在动作ViLLA框架:三阶段训练
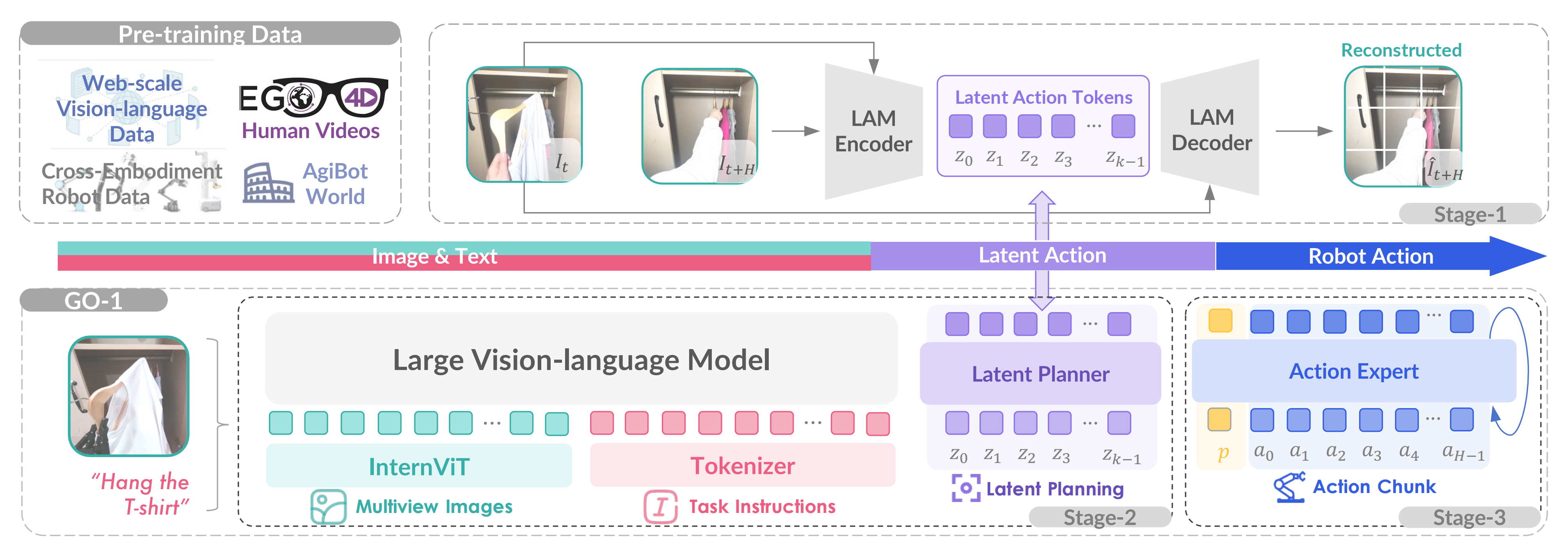
他们为了有效利用高质量的AgiBot World数据集并增强策略的泛化能力,他们于近期25年3月份,提出了一个分层的视觉-语言-潜在动作ViLLA框架,其具有三个训练阶段,如下图图4所示
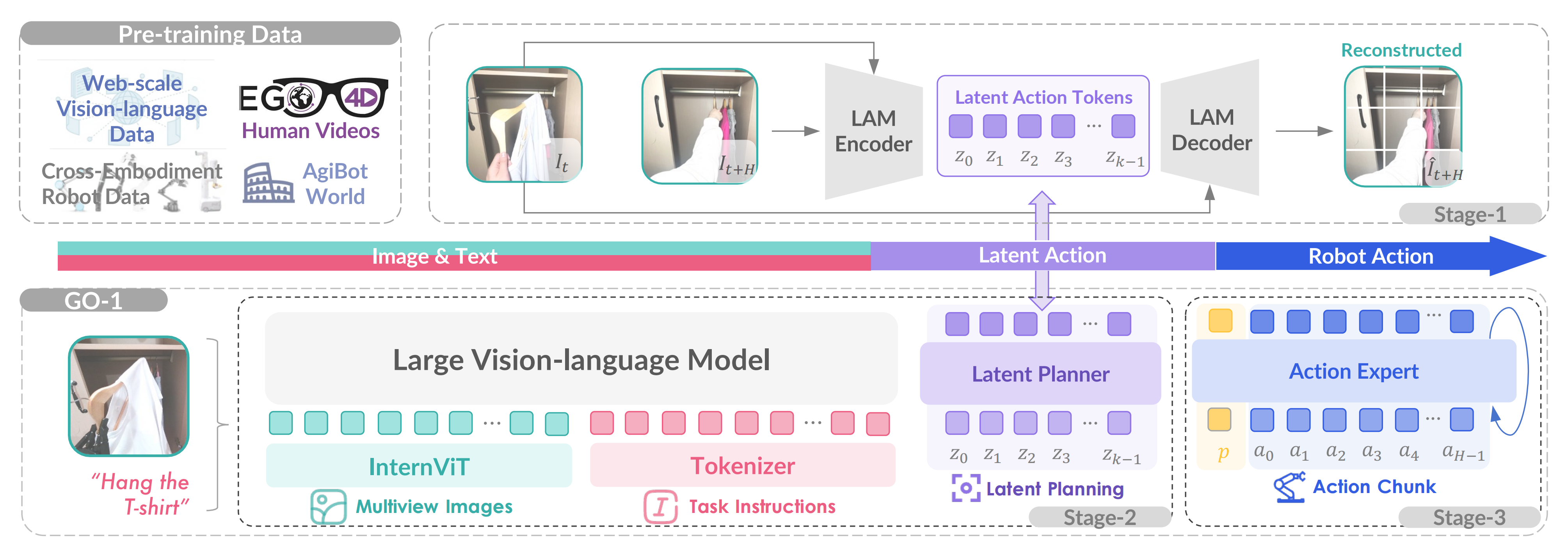
与基于视觉-语言条件的视觉-语言-动作(VLA)模型相比,ViLLA模型在生成后续机器人控制动作的条件下预测潜在动作token
- 在阶段1中,他们通过在互联网规模的异构数据上训练一个编码器-解码器的潜在动作模型LAM,将连续的图像投影到一个潜在动作空间中
这使得潜在动作可以作为中间表示,弥合通用图像-文本输入与机器人动作之间的差距 - 在阶段2中,这些潜在动作作为潜在规划器的伪标签,促进了与可不依赖于实体的长时间规划,并利用了预训练的VLM的泛化能力
In Stage 2, these latent actions act as pseudo-labels for the latent planner, facilitating embodiment-agnosticlong-horizon planning and leveraging the generalizability ofthe pre-trained VLM. - 最后,在阶段3中,引入了动作专家,并将其与潜在规划器联合训练,以支持灵巧操作的学习
1.2.1 潜在动作模型:从视频中提取背后的潜在动作信息
尽管在收集多样化的机器人演示方面取得了相当大的进展,但与网络规模的数据集相比,带有动作标签的机器人数据量仍然有限
为了通过引入缺乏动作标签的网络规模人类视频和跨设备的机器人数据来扩大训练数据池,他们在阶段1中使用潜在动作[30]来建模连续帧的逆动力学。这种方法使得能够将来自异构数据源的现实世界动力学转移到通用的操控知识中
如下图所示,潜在动作模型LAM从网络规模的视频数据(例如,来自Ego4D的人类视频)中学习通用动作表示,并将其量化为离散的潜在动作token——Latent Action Tokens。潜在规划器Latent Planner通过潜在动作预测进行时间推理,弥合了图像-文本输入与由动作专家生成的机器人动作之间的差距
为了从视频帧中提取潜在动作,潜在动作模型围绕基于
- 逆动力学模型的编码器
编码器采用了基于Bruce 等人[30,即Google的Genie] 提出的因果时间掩码的时空transformer[31,注意是时空transformer,因为涉及到对不同时刻下图像帧的编码]
相当于LAM Encoder针对初始帧和结束帧
推测背后的潜在动作token序列
- 基于前向动力学模型的解码器
而解码器是一个空间transformer,其输入为初始帧,其中k 设置为4
相当于LAM Decoder基于初始帧
最终,咱们只需要在真实的之间建损失函数即可,即可训练LAM Encoder对潜在动作token序列的准确性
那如何判断是否准呢,简单:如果基于「初始帧 + 预测的潜在动作序列」预测的
我觉得这个idea确实挺绝的,面对没有动作标记的海量视频,通过如上的训练,便可以把视频开始帧与结束帧之间的动作token序列预测出来(即是经过怎样的一些动作,从开始帧到的结束帧),而这个动作token序列便是我们想要的动作标记,毕竟这个动作标记如果模型没法标,便只能人类去标,但人类标的成本、代价太大了啊..
下文还会继续阐述LAPA,到时你会有更深刻的体会
构建潜在动作token使用VQ-VAE 目标[32,如果对VAE或VQ-VAE的原理不太熟悉,详见此文《图像生成发展起源:从VAE、扩散模型DDPM、DDIM到DETR、ViT、Swin transformer》] 进行量化,其codebook的大小为|C|
实话讲,我一开始没注意到上面提到的参考文献30——Google的Genie,直到下文解读LAPA时,才注意到原来上面的参考文献30,说的就是Google的Genie——详见此文《Google发布Genie硬杠Sora(含Genie 2):通过大量无监督视频训练最终生成可交互虚拟世界》
- 首先,编码器将所有先前的帧
以及下一帧
作为输入,并输出相应的一组连续的潜在动作
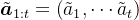
First, an encoder takes as inputs all previous frames 𝒙1:𝑡 = (𝑥1, · · · 𝑥𝑡) as well as the next frame 𝑥𝑡+1, and outputs a corresponding set of continuous latent actions ˜𝒂1:𝑡 = (˜𝑎1, · · · ˜𝑎𝑡).
- 然后,解码器将所有先前的帧
作为输入,并预测下一帧
A decoder then takes all previous frames and latent actions as input and predicts the next frame 𝑥ˆ𝑡+1
是不和ViLLA中阶段一的潜在动作模型基本一样

1.2.2 潜在规划器:预测潜在动作token序列
为了建立场景和对象理解及一般推理能力的坚实基础,ViLLA 模型利用了在大规模网络视觉语言数据上预训练的视觉语言模型,并结合了一个潜在规划器,以便在潜在动作空间中进行与实体无关的规划「the ViLLA model harnesses a VLM pre-trained on web-scale vision-language data and incorporates a latent planner for embodiment-agnostic planning within the latent action space」
具体而言,他们使用
- InternVL2.5-2B [33]作为VLM主干网络,因为它具有强大的迁移学习能力。且2B的参数规模在他们的初步实验中以及先前的研究[10],[26]中已被证明对机器人任务有效
- 多视角图像观察首先通过InternViT编码,然后投射到语言空间中
潜在规划器由24层transformer层组成,这些层能够通过VLM主干网络进行逐层条件设置,并具有完整的双向注意力
The latent planner consists of 24 transformer layers, which enable layer-by-layer conditioning from the VLM backbonewith full bidirectional attention
具体来说,给定在时间步下的多视角输入图像
——通常来自头部、左手腕和右手腕,以及描述正在进行任务的语言指令
,潜在规划器Latent Planner预测潜在动作token:
监督则由基于头部视角的LAM 编码器生成:
相当于潜在规划器Latent Planner预测潜在动作token的ground truth便是基于头部视角的LAM 编码器生成的
——
如此,在阶段1的监督数据下,让Latent Planner对潜在动作token序列的预测越来越准,最终Latent Planner完成训练后,便可以针对新的observation和新的语言指令l 给出潜在动作token序列,然后机器人的动作专家便可以基于此潜在动作token语料 生成动作
这,是不是很像图像生成「图像生成的原理详见此文《AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion(含ControlNet详解)》」
由于潜在动作空间的规模比OpenVLA [4] 中使用的离散化低级动作小了几个数量级,这种方法还促进了通用VLM 高效地适配到机器人策略中
1.2.3 动作专家
为了实现高频率和灵巧的操作,第3阶段集成了一个动作专家,该专家利用扩散目标来建模低级动作的连续分布[34]
尽管动作专家与潜在规划器共享相同的架构框架,但它们的目标有所不同:
- 潜在规划器通过掩码语言建模生成离散的潜在动作token
别忘了,上面说过的,潜在规划器由24层transformer层组成,这些层能够通过VLM主干网络进行逐层条件设置,并具有完整的双向注意力 - 而动作专家通过迭代去噪过程回归低级动作
这两个专家模块都分层依赖于前面的模块,包括动作专家自身,确保了在双专家系统中的一致集成和信息流
动作专家解码低级动作块,由表示,其中
,使用自身状态
在
时间步长间隔内:
在推理过程中,VLM、潜在规划器和动作专家在通用策略GO-1 中协同结合,该策略首先预测k 个潜在动作token,然后调整去噪过程以生成最终控制信号
// 待更
第二部分 LAPA:Latent Action Pretraining from Videos
2.1 LAPA的提出背景与相关工作(24年10月)
2.1.1 LAPA无需真实机器人动作标签即可对机器人进行无监督预训练
24年10月,来自1韩国科学技术研究院、2华盛顿大学、3微软研究院、4英伟达、5艾伦人工智能研究所的研究者们提出了LAPA
- 其对应的论文为:Latent Action Pretraining from Videos
其对应的作者为:Seonghyeon Ye1∗†、Joel Jang2∗‡
Byeongguk Jeon1、Sejune Joo1、Jianwei Yang3、Baolin Peng3、Ajay Mandlekar4
Reuben Tan3、Yu-Wei Chao4、Bill Yuchen Lin5、Lars Liden3
Kimin Lee1§、Jianfeng Gao3§、Luke Zettlemoyer2§、Dieter Fox2,4§、Minjoon Seo1§ - 其对应的项目页面为:latentactionpretraining.github.io/,其对应的GitHub为:github.com/LatentActionPretraining/LAPA
他们为何提出这个LAPA呢,或者是基于什么样的考虑呢
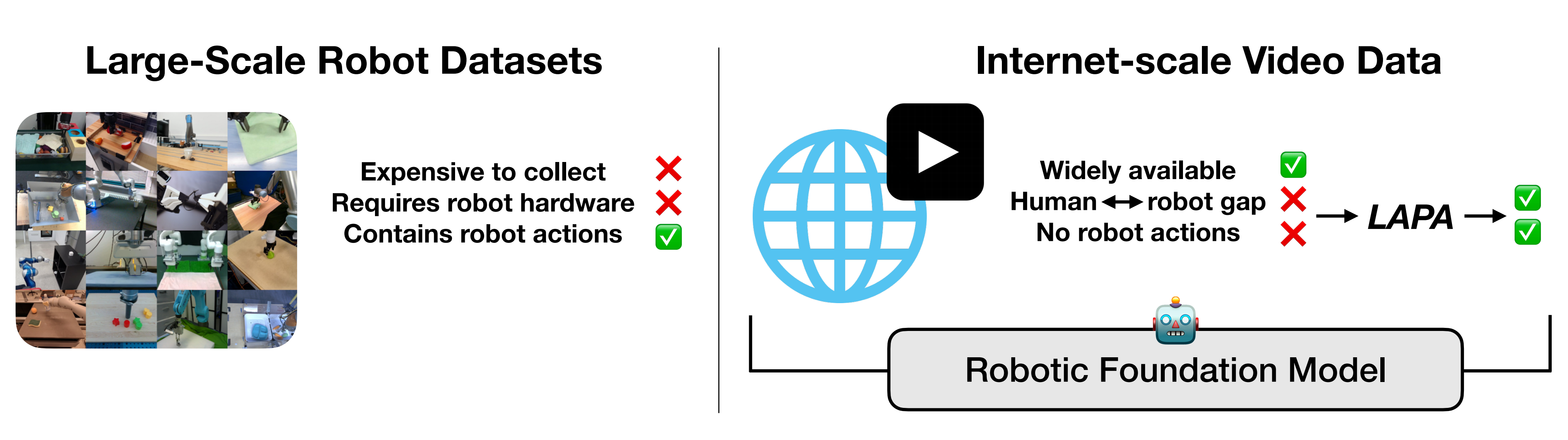
通过此文《基于人类视频的模仿学习与VLM推理规划:从DexMV、MimicPlay、SeeDo到人形OKAMI、Harmon(含R3M的详解)》可知,机器人训练数据的来源之一便是大规模的互联网数据,然从互联网视频数据中学习面临两个主要挑战:
- 首先,网络上的许多原始数据缺乏明确的动作标签
- 其次,来自网络的数据分布与典型机器人系统的化身和环境存在根本性的不同(McCarthy 等,2024)
故他们提出了通用动作模型的潜在动作预训练(LAPA),一种无需真实机器人动作标签即可对机器人基础模型进行无监督预训练的方法,如下图图1所示
LAPA 有两个预训练阶段,之后是一个微调阶段,用于将潜在动作映射到真实的机器人动作
- 在第一个预训练阶段,使用基于 VQ-VAE 的目标 (Van Den Oord 等人),2017)学习原始图像帧之间的quantized潜在动作
类似于用于语言建模的字节对编码(Sennrich 等,2016),这可以看作是在不需要预定义动作先验(例如,末端执行器位置、关节位置)的情况下学习tokenize atomic actions - 在第二阶段,通过预训练的VLM来预测基于视频观察和任务描述的第一阶段derived的潜在动作,从而进行行为克隆
In the second stage, we perform behavior cloning by pretraining a Vision-Language Model to predict latent actions derived from the first stage based on video observations and task descriptions - 最后,在一个小型机器人操作数据集上对模型进行微调,该数据集包含机器人动作,以学习从潜在动作到机器人动作的映射
Finally, we fine-tune the model on a small-scale robot manipulation dataset with robot actionsto learn the mapping from the latent actions to robot actions
在这项工作中,他们将提出的方法和生成的视觉语言动作模型(VLA)统称为LAPA,其效果超越了OpenVLA——该模型是在包含真实动作的多样化数据集上训练的,以及优于在Bridgev2——一个最大的开源机器人数据集之一上预训练的模型
2.1.2 相关工作:LAPA即有受到Google Genie工作的启发
而LAPA论文在相关工作中也确实提到了Google的这个Genie
- GENIE(Bruce 等, 2024)将用户输入(真实动作)映射到潜在空间,使生成模型能够创建交互环境
而LAPA也采用了类似的潜在动作模型,但将其应用于标注无动作数据,以训练一个单一的 VLA 来解决机器人任务 - 同样,Edwards 等(2018)和 Schmidt &Jiang(2024)使用潜在动作来预训练和微调视频游戏(Cobbe 等, 2019)的策略
相比之下,LAPA专注于从真实的人类运动中学习潜在动作,以应对更复杂、连续的机器人任务。不像其他通过将真实动作转换为潜在动作来捕捉更好的多模态性和任务语义的工作(Lynch 等, 2020;Jiang 等, 2023;Lee 等, 2024;Mete 等, 2024),LAPA直接从观测中推导潜在动作,而不是从真实动作中
而在写本文的过程中,一投资人和我说,那24年12月香港大学、腾讯公司和UC Berkeley联合发布的Moto呢,好问题啊!下文第三部分 会继续阐述这个Moto
2.2 LAPA:用于通用动作模型的潜在动作预训练
LAPA 分为两个阶段:潜在动作量化和潜在预训练
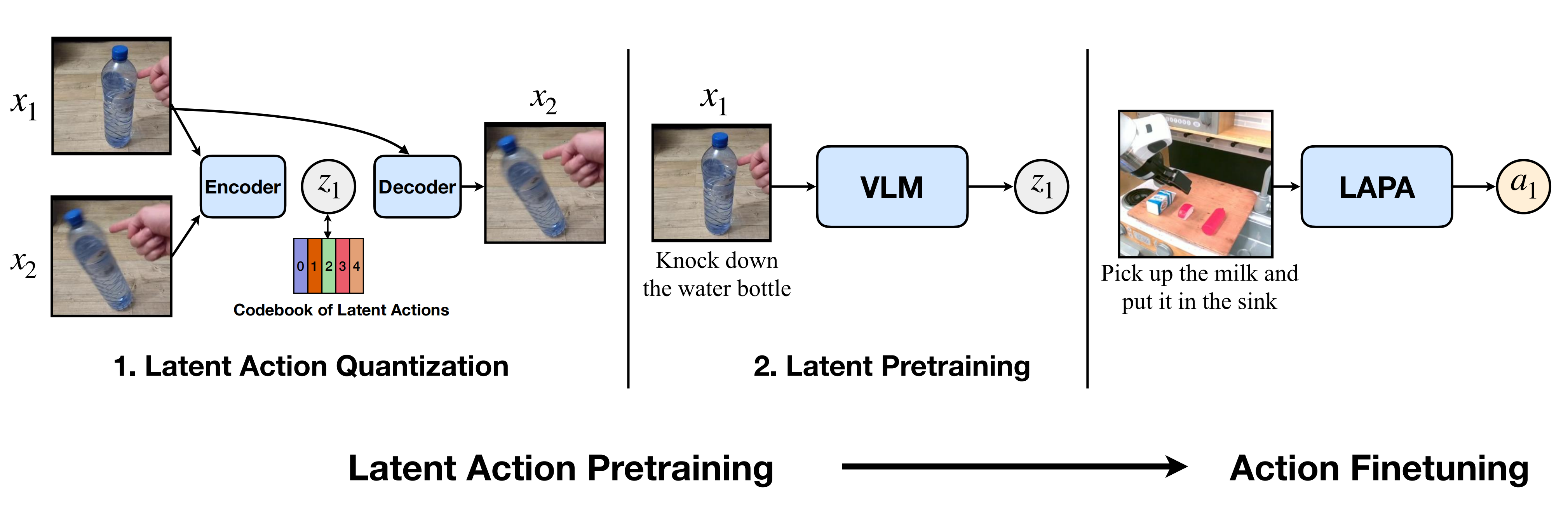
- 首先,使用基于 VQ-VAE 的目标函数来捕获视频中连续帧之间离散化的潜在增量信息
- 接下来,预训练的VLM被训练为在给定当前图像和语言指令的情况下,预测由潜在动作量化模型的编码器指定的潜在动作
Next, a pretrained VLM is trained to predict the latent action designated by the encoder of the Latent Action Quantization model, given the current image and the languageinstruction.
在潜在预训练之后,再在少量带有真实动作标签的轨迹上对 VLA 模型进行微调,以将潜在空间映射到实际动作空间
2.2.1 潜在动作量化
为了以完全无监督的方式学习潜在动作,LAPA根据Bruce 等人(2024,即Google的 Genie,下图即genie论文中的示意图)的方法并进行了一些修改,训练了一个潜在动作量化模型

- 他们的潜在动作量化模型是一个编码器-解码器架构,其中编码器接收视频中固定窗口大小H 的当前帧
和未来帧
,并输出潜在动作
「当然,上面Google Genie的示意图中,其用的
- 解码器被训练用来接收潜在动作
和
与Bruce 等人(2024)不同,LAPA使用交叉注意力对 给定的
进行关注,而不是additive嵌入,这在经验上更有助于捕获更具语义意义的潜在动作
且LAPA的量化模型是C-ViViT tokenizer(Villegas 等人,2023)的一种变体,其中编码器包括空间和时间transformer,而解码器仅包含空间transformer,因为LAPA的编码器模型仅使用两帧图像作为输入,所以需要用到时间transformer
如下图图13所示,LAPA使用了来自Villegas等人(2022)的C-ViViT 模型架构来复现GENIE(Bruce 等人,2024)的潜在动作模型。在潜在模型训练之后,将
用作
的潜在动作标签。编码器可以被视为逆动力学模型,而解码器可以被视为世界模型
此外,和上面介绍的ViLLA一样(当然,大概率上是ViLLA借鉴的LAPA,而非反过来),LAPA的潜在动作量化训练模型基于VQ-VAE目标(van den Oord等人,2017)
VQ-VAE目标使得潜在动作可以是离散的token——codebooks,从而使VLMs容易预测
。即潜在动作使用来自|C| codebooks词汇空间的序列表示
- 为了避免在VQ-VAE中常见的梯度坍缩现象,LAPA采用了NSVQ(Vali & Bäckström,2022),它将矢量量化误差替换为原始误差与归一化噪声矢量的乘积
- 且还在早期训练阶段应用了NSVQ的codebooks替换技术,以最大化codebooks的利用率
We utilize the encoder of our latent action quantization model as an inverse dynamics model in the next stage of LAPA
and the decoder for generating neural-based closed-loop rollouts - 与之前的工作(Bruce等人,2024;Valevski等人,2024)不同
LAPA 同时训练了一个通过潜在预训练生成这些潜在动作的策略模型 即编码器Encoder——可以被视为逆动力学模型,和一个从潜在动作生成轨迹的世界模型 即解码器Decoder
LAPA trains both a world model thatgenerates rollouts from the latent actions and a policy model that produces these latent actionsthrough Latent Pretraining
2.2.2 潜在预训练:给定视频初始帧和语言指令,让VLM预测潜在动作
- 在上一节,已经明确:LAPA使用潜在动作量化模型的编码器作为逆动力学模型,在给定
在这一节,LAPA对一个视频片段的语言指令和当前图像
且 - 默认情况下,只冻结视觉编码器,并在训练期间解冻语言模型。由于潜在预训练不依赖于真实动作,它使得使用任何类型的与语言指令配对的原始视频成为可能
此外,与传统的机器人动作粒度(例如末端执行器位置、关节位置、关节力矩等)相比,LAPA的方法不需要任何先验知识——即动作层次/粒度是通过端到端的方式学习的,仅通过优化,从而以最佳方式捕获给定视频数据集中连续观察之间的“差异”
2.2.3 动作微调
经过预训练以预测潜在动作的可变长度动作序列VLAs无法直接在真实世界的机器人上执行,因为潜在动作并非实际的末端执行器动作增量或关节动作
此点,类似上文第一部分的ViLLA
为了将潜在动作映射到实际的机器人动作,LAPA在包含真实动作(末端执行器增量)的少量标注轨迹上微调LAPA。对于动作预测,LAPA对机器人的每个维度的连续动作空间进行离散化,以便每个区间分配的数据点数量相等,参考Kim等人(2024)和Brohan等人(2023)
他们丢弃潜在动作头(一个单层MLP)并用一个新的动作头替换它以生成真实动作。与潜在预训练一样,LAPA冻结视觉编码器并解冻底层语言模型的所有参数
2.3 LAPA的效果表现
LAPA 的优势不仅体现在下游任务性能上,还包括预训练效率
- 在预训练 LAPA(Open-X),即表现最佳的模型时,我们使用了 8 块 H100 GPU 运行了 34 小时,批量大小为 128(总计272 H100 小时)
相比之下,OPENVLA 的预训练总共需要 21,500 A100 小时,批量大小为2048。尽管 LAPA 的预训练效率提高了约 30-40 倍,但其性能仍然优于 OPENVLA6
LAPA作者认为这种效率来源于两个因素:
(1)使用大型世界模型(Liu等人,2024)作为主干视觉语言模型(VLM),
以及(2)LAPA的粗粒度动作相较于传统的动作预训练。首先,在LWM预训练期间的训练目标包括生成下一个状态,这对应于视频中的下一帧
LAPA假设这一目标使模型能够隐式理解视频中的高层次动作 - 值得注意的是,使用LWM作为主干的ACTIONVLA(Bridge)和使用Prismatic作为主干的OPENVLA(Bridge)是在相同数据和目标上进行训练的
然而,ACTIONVLA在显著更少的训练周期(3个周期)内就达到了最佳性能(就动作标记准确性而言),而OPENVLA需要30个周期
其次,LAPA的动作空间比OPENVLA小得多(84 vs.2567),使得学习从感知与语言到动作生成的问题变得更容易。对于所有LAPA模型(BridgeV2、Open-X、人类视频),他们观察到单个训练周期就足以达到最佳性能
// 待更
第三部分 Moto:自回归方式预测未来视频片段的潜在运动token轨迹
3.1 Moto的提出背景与相关工作(24年12月)
3.1.1 Moto的提出背景
一直以来,机器人技术一直受到动作标注数据高成本的限制
鉴于交互丰富的视频数据的丰富性[3, 57],来自香港大学、腾讯、UC伯克利的研究者们联合提出Moto:试图利用视频数据的自回归预训练来改进机器人学习
且有效的机器人自回归应优先考虑与运动相关的知识,这与低级机器人动作密切相关,而与硬件无关,从而通过微调将学习到的运动转移到实际的机器人动作中
简言之,Moto通过潜在运动Tokenizer将视频内容转换为潜在运动token序列,其对应的论文为《Moto: Latent Motion Token as the Bridging Language for Robot Manipulation》,其项目页面地址为:chenyi99.github.io/moto,其GitHub地址为:github.com/TencentARC/Moto
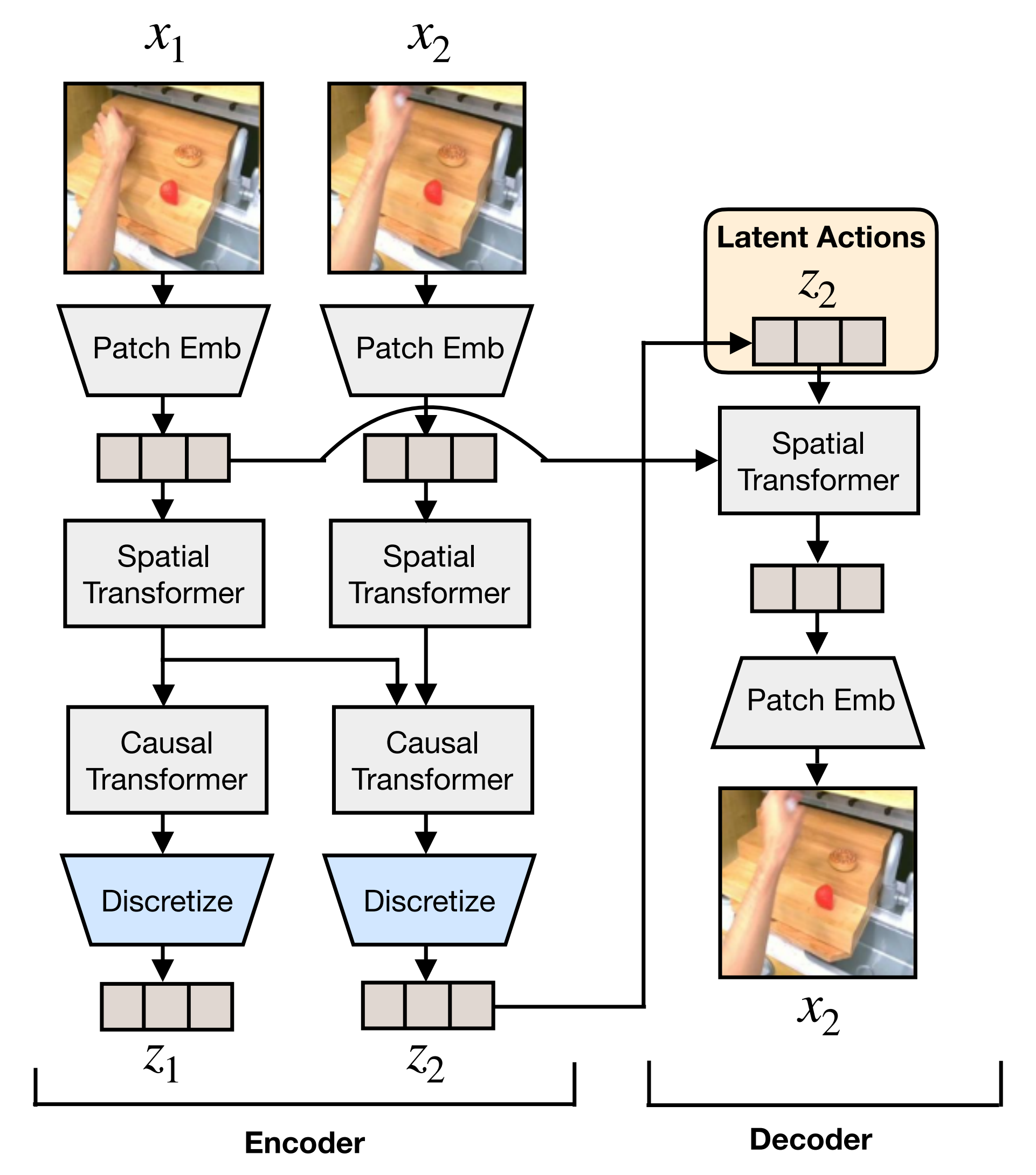
具体而言,它利用潜在运动token作为桥接“语言”,以无监督的方式建模视频帧之间的视觉运动。如下图图1所示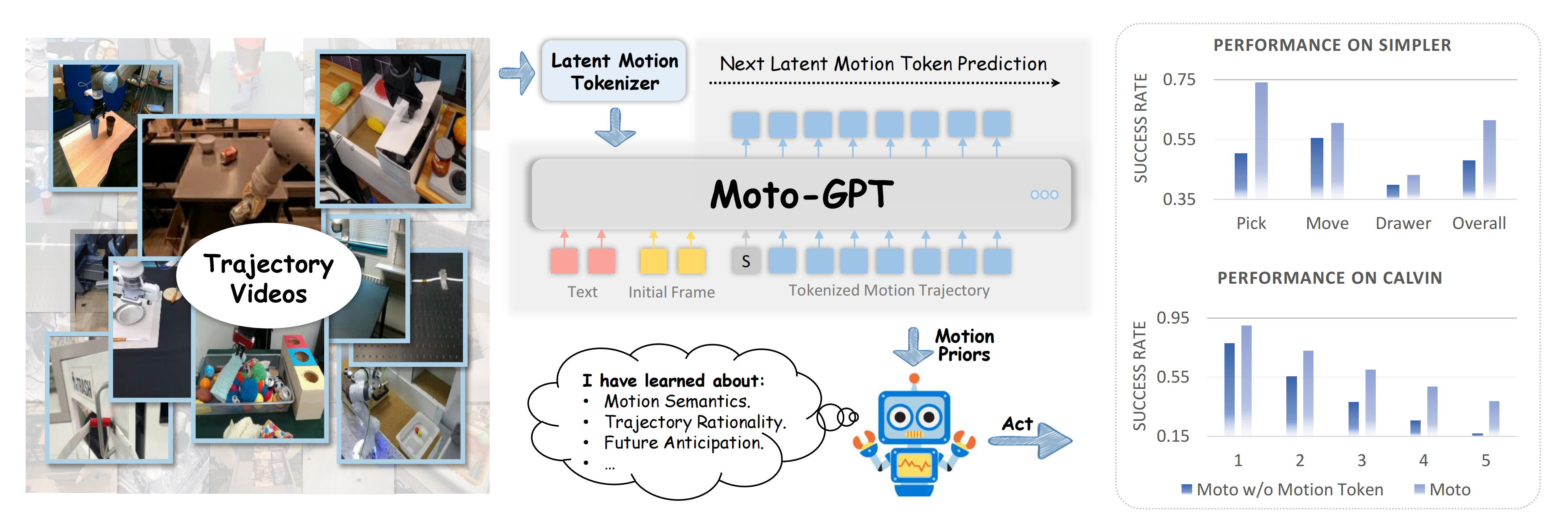
- 首先训练一个离散的潜在运动Tokenizer来生成紧凑的潜在运动token,这些token在无需外部监督的情况下捕捉视频帧之间的动态
具体来说,如下图图2所示
Tokenizer被训练为有效捕捉视频帧之间的变化,这些变化通常源于运动
一旦Tokenizer被训练好,就可以获取视频片段中每两个连续帧的潜在运动token,并将它们串联成一个序列以表示运动轨迹 - 然后,使用基于GPT的架构对Moto-GPT进行预训练,以预测下一个潜在运动token,从视频中吸收运动先验知识
即Moto-GPT通过基于初始帧和相应的语言指令预测下一个token来对这些序列进行预训练——使模型无需动作标注即可学习有用的运动先验知识
在这个预训练阶段之后,Moto-GPT能够通过自回归地预测潜在运动token生成合理的轨迹 - 这些学习到的先验知识随后通过协同微调策略,转移到增强机器人操作任务中
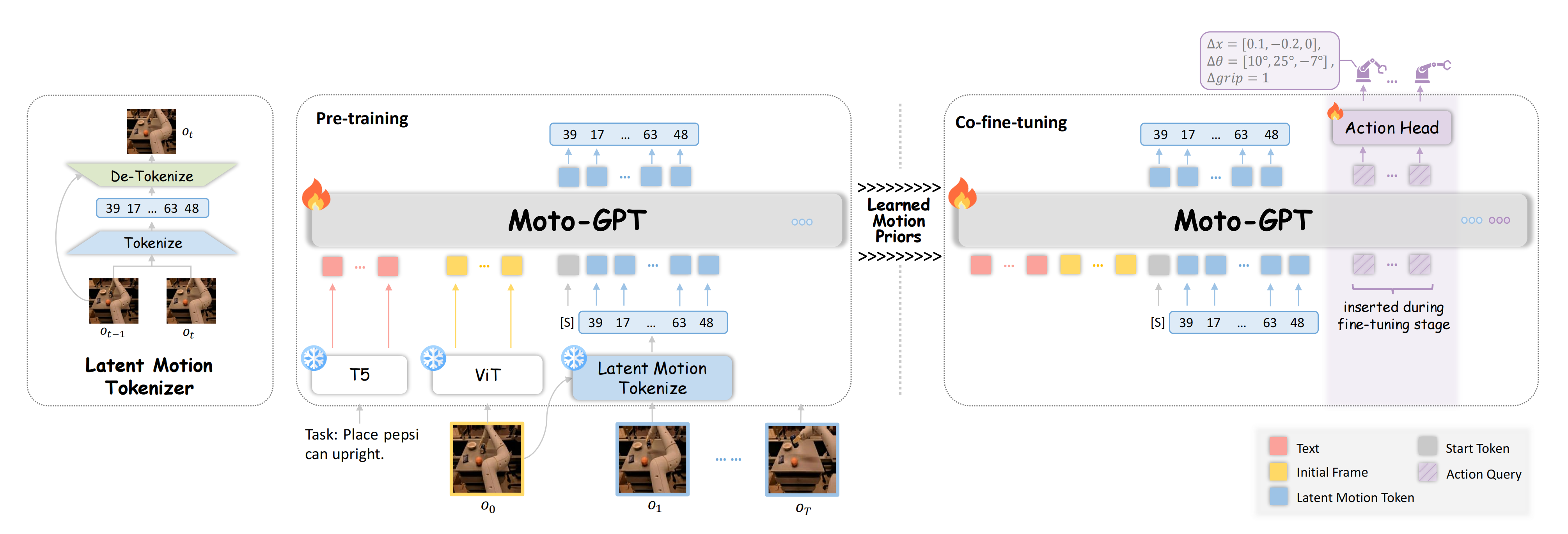
即为了使Moto-GPT适应下游的机器人操作任务,作者在每个时间步将动作查询token与潜在运动token chunk串联起来,以在带有动作标签的机器人数据上进行协同微调
To adapt Moto-GPT for downstream robot manipulation tasks, we concatenate action query tokens with latent mo-tion token chunk at each time step for co-fine-tuning on action-labeled robot data.
动作查询token由一个可学习模块处理以预测低级动作,而运动token使用原始的下一个token预测机制进行微调。这种协同微调策略有效地转移了学习到的抽象意图到机器人动作中
The action query tokens are pro-cessed by a learnable module to predict low-level actions,while the motion tokens are fine-tuned using the originalnext-token prediction mechanism.
3.1.2 相关工作:与genie、LAPA的相同与不同之处
且同样的,moto论文中也提到了Google的genie,以及上文第二部分介绍过的LAPA,而Moto与LAPA(包括Igor)的不同之处在于,moto预训练了一个端到端的策略模型,以自回归方式预测未来视频片段的潜在运动token轨迹
3.2 moto的方法论
Moto利用自回归生成预训练技术对潜在运动token序列进行训练,从视频中学习运动先验知识,随后在带有动作标签的数据上进行共同微调以用于机器人控制
如下图图2所示
Moto包括三个阶段:
- 潜在运动Tokenizer的无监督训练
- 生成模型Moto-GPT的预训练
- 用于机器人动作策略的共同微调
3.2.1 潜在运动分词器
潜在运动分词器,如下图图3所示
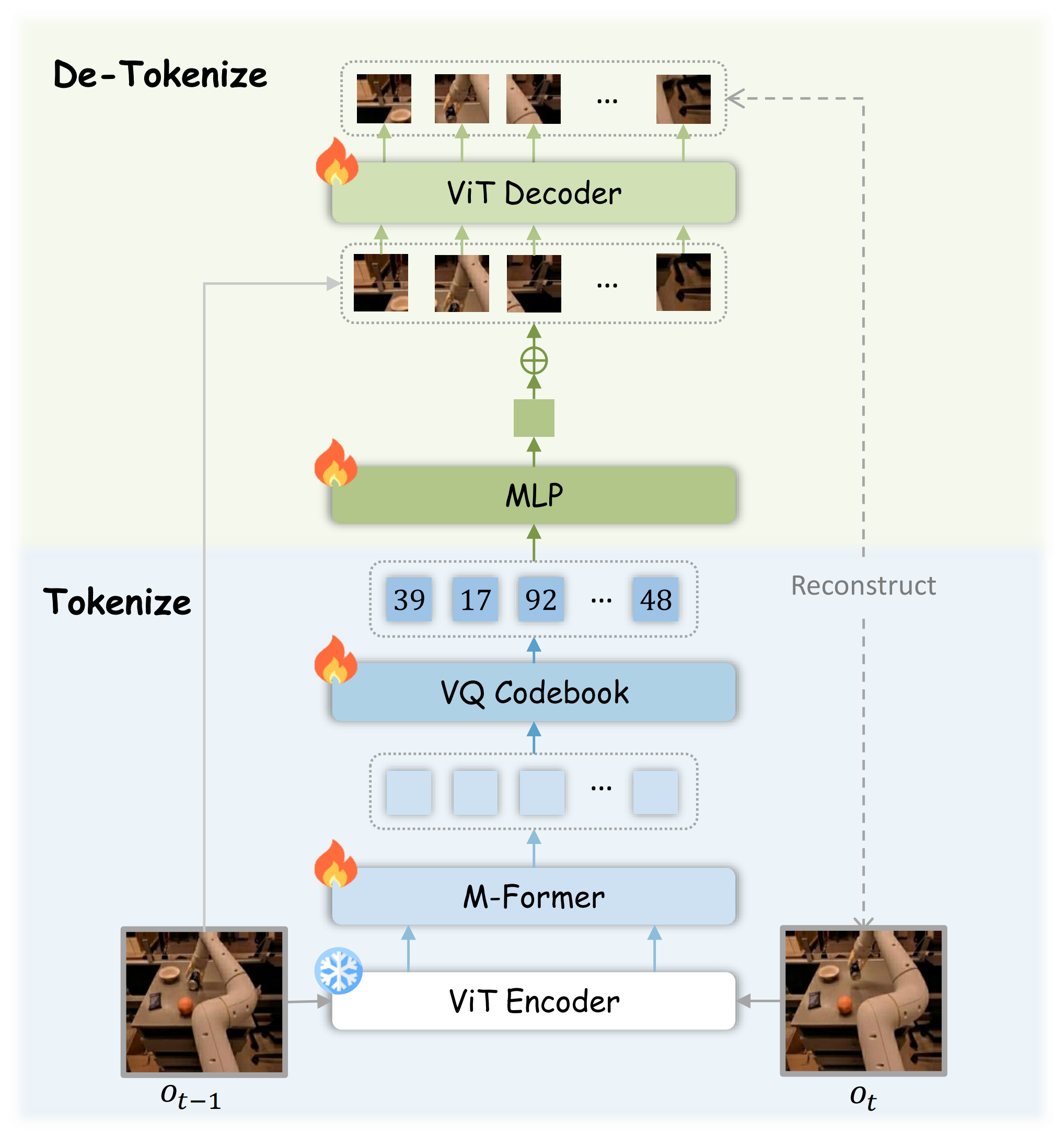
通过无监督的方式学习一种潜在的“语言”,以捕捉连续视频帧之间的主要视觉运动。其架构遵循用于运动分词和去分词的标准自动编码器设计
- 具体而言,其使用一个M-Former,这是一种多层Transformer,通过使用冻结的预训练ViT 编码器[24] 从当前帧
和前一帧
的最后一层patch 特征中提取运动特征
将8 个可学习的query嵌入与这些patch 特征连接作为M-Former 的额外输入,其中query通过自注意力层进行交互
employs an M-Former, a multi-layer transformer that ex-tracts motion features from the last-layer patch features of the current frame ot and the preceding frame ot−1 using a frozen pre-trained ViT encoder [24]. We concatenate 8 learnable query embeddings with these patch features as ad-ditional input to the M-Former, where the queries interactthrough self-attention layers - 然后,输出的query特征通过一个具有128 词汇量大小的VQ codebook处理,以生成离散的潜在运动token
The output query features arethen processed by a VQ codebook with a vocabulary size of128 to produce discrete latent motion tokens. - 对于de-tokenizatio,使用一个解码器进行图像重建,该解码器接收线性嵌入的
的像素值
一个MLP将潜在运动token的量化嵌入连接起来,投影到一个紧凑的嵌入(1 个token)中,该嵌入添加到每个输入patch嵌入中
此条件嵌入在编码器和解码器之间起到信息瓶颈的作用,使ViT解码器能够捕获帧之间的细微变化并准确地将
潜在运动Tokenizer的组件通过标准的VQ-VAE目标[51]联合优化,其中包括重建损失、向量量化损失和承诺损失。且特别使用从ViT解码器输出的像素值和的真实像素值之间的MSE损失作为重建损失
一旦训练完成,潜在运动Tokenizer会被冻结,以通过“双帧”Tokenizer生成统一的序列运动表示。此外,通过初始观察和指定的潜在运动token,解码器可以作为“模拟器”运行以生成用于可视化环境变化的轨迹
3.2.2 运动token自回归预训练
通过潜在运动Tokenizer,Moto-GPT 能够从视频中学习多样的视觉运动,使用潜在运动token作为桥接语言
如下图图2 所示
Moto-GPT 通过下一运动token预测目标进行预训练
- 对于一个视频片段
,作者为每对连续帧提取一组潜在运动token,并按时间顺序将它们串联形成一个序列。Moto-GPT 使用一种GPT 风格的transformer对这些运动token轨迹进行自回归
- 此外,他们将指令中的文本特征和初始视频帧的视觉特征作为输入提示预置
预训练目标是在给定语言指令和初始视频帧的情况下,最大化真实潜在运动token序列出现的可能性
其中分别是来自冻结的预训练T5 [47] 和ViT[24] 模型的文本和视觉特征,
表示当前token
之前的潜在运动token,
表示可训练模型参数
这里,,其中
是连续帧之间运动的token数量,
是视频长度
3.2.3 用于机器人操作的协同微调
在预训练之后,Moto-GPT 可以通过基于语言指令和初始观测生成潜在运动token来预测未来的轨迹
这一过程类似于对真实机器人策略推断,如果将潜在运动token的codebook看作是一个抽象的动作空间。然而,在实现精确的机器人控制方面仍存在差距
为了解决这个问题,在微调阶段,作者在 Moto-GPT 的输入中引入了特殊的动作查询token,从而通过一个灵活的动作头生成真实的机器人动作,如图 2 右侧部分所示
- 具体而言,在每个时间步,潜在运动token块之后添加了N 个查询token,其中 N 对应于两帧视频之间发生的机器人动作的数量。微调阶段总体上遵循与预训练相同的因果掩码机制
- 然而,潜在运动token不会关注新插入的动作查询token,以保持与预训练设置的一致性。此外,随机屏蔽了从动作查询token到潜在运动token的 50% 的注意力,从而在减少对真实条件依赖的同时实现知识转移
此外,为提高推理效率,通过使用填充token作为潜在动作token的占位符,阻止动作查询token与这些占位符之间的注意力,从而向 Moto 发出直接查询以获取实际动作,而无需生成潜在动作token
一个基于MLP 的动作头将每个动作查询token的输出隐藏状态投影到真实的机器人动作空间中
作者对连续动作组件(例如位置(∆x) 和旋转(∆θ) 位移)应用Smooth-L1 损失,对于二元分量,比如夹爪的开/合状态(∆grip),应用二元交叉熵(BCE)损失
总动作损失 定义为
且保留了用于潜在运动token预测的训练目标,以确保Moto-GPT保留从视频中学习到的运动先验
因此,微调阶段的总体损失函数为
3.3 数据集、模型对比
3.3.1 预训练数据集与微调数据集
作者使用了Open-X-Embodiment [52] 的一个子集来训练Latent Motion Tokenizer,并预训练Moto-GPT,该数据集包含了来自各种实体的109k真实世界轨迹视[5,10,14,37,39,41,45,49,53,60,61]
在微调Moto-GPT时,作者使用了RT-1 Robot Action数据集[5]中的73k带有动作标签的专家轨迹
3.3.2 一系列基准测试:与RT-2/Octo/OpenVLA/RoboFlamingo的对比实验
在SIMPLER基准测试中,作者比较了Moto-GPT 使用了4个代表性模型,这些模型通过Open-X-Embodiment 数据集进行预训练:
- RT-1-X[5]使用了一个transformer主干网络来输出经过tokenized的动作,并通过 FiLM EfficientNet 融合「语言以及6张历史图像」转换为token输入
- RT-2-X[62] 将预训练的大型视觉语言模型 (VLM)PaLI-X (55B) [11] 转换为机器人策略,通过将tokenized的动作转换为文本token
- Octo-Base[42] 使用一种Transformer架构来处理语言和图像token,并使用基于扩散的动作头来生成动作
- OpenVLA[28] 基于预训练的 Prismatic-7B [26] VLM主干网络,用于机器人动作预测
在 CALVIN 基准测试中,以下是利用预训练策略来提高机器人操作性能的基线模型:
- SuSIE[4] 预训练了一个图像编辑模型来生成目标图像,该图像被输入到低级策略中进行动作预测
- RoboFlamingo[32] 是一个机器人策略模型,改编自OpenFlamingo[2],这是一个在大量视觉-语言语料库上预训练的大型视觉语言模型(VLM)
- GR-1[54] 预训练一个GPT风格的Transformer,用于直接预测每个输入观测对应的单步未来观测的像素值
- MT-R3M[54] 是GR-1的一种变体,它利用预训练的机器人视觉编码器R3M[43]来编码观测图像
此外,作者还研究了以下Moto-GPT的变体作为可选基线:
- Moto-没有运动token
与Moto-GPT共享相同的主干,但从头开始在动作标记的机器人数据上训练,而没有潜在的运动token - Moto-IML经历了与Moto-GPT相同的预训练阶段。它在输入序列中保留了潜在的运动token,但在微调阶段忽略了下一个运动token预测损失
- Moto-DM以与Moto-GPT相同的方式进行预训练,但在微调阶段完全丢弃了输入序列中的潜在运动token
3.4 训练细节
3.4.1 潜在运动Tokenizer
潜在运动分词器Tokenizer的可训练模块的实现细节总结在表1 中
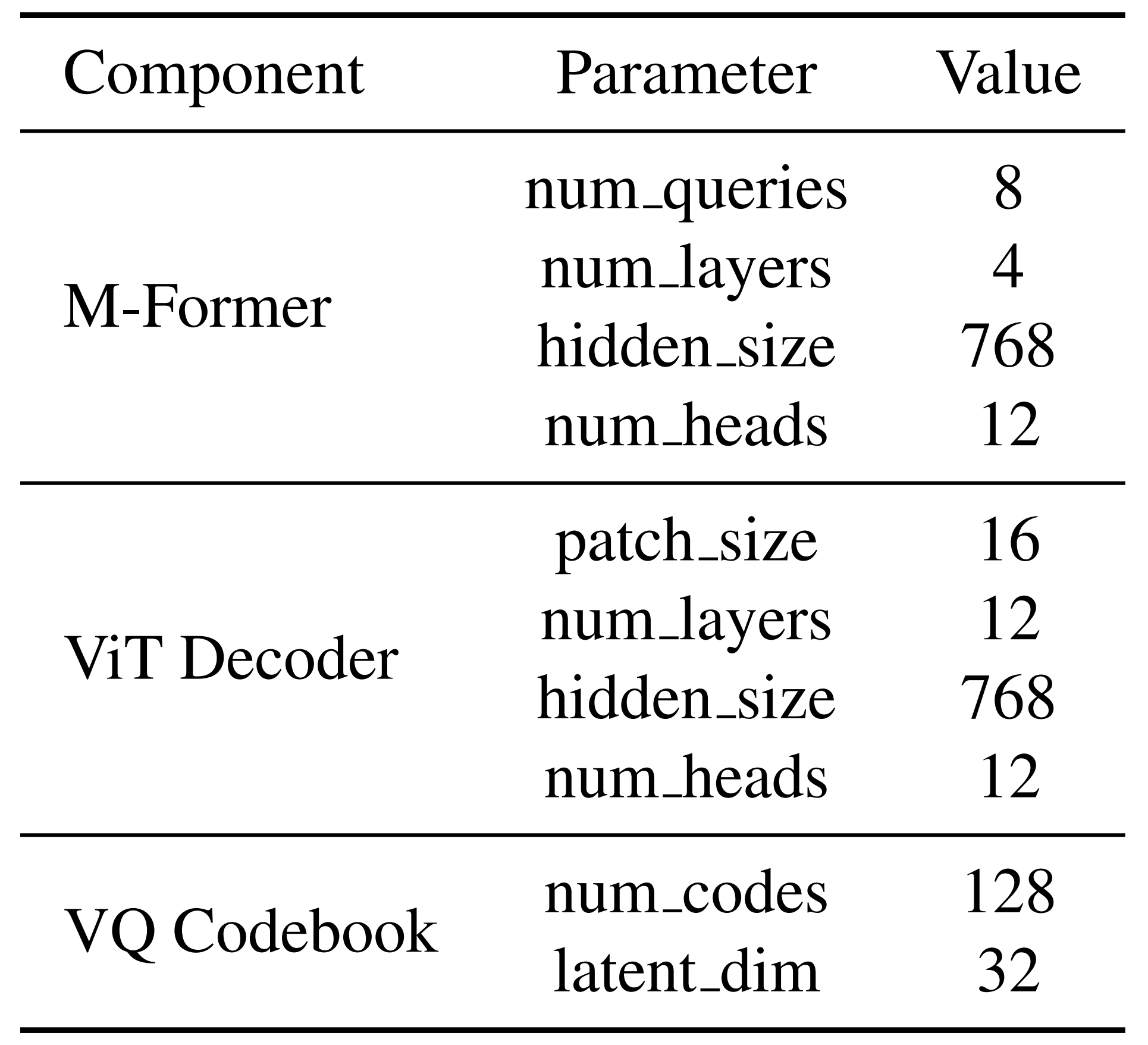
- 且使用表2 中列出的超参数
在4个A100-40G GPU 上训练该模型。为了促进潜在运动token的学习,作者对训练数据集中的原始视频进行下采样,确保帧间的视觉运动足够明显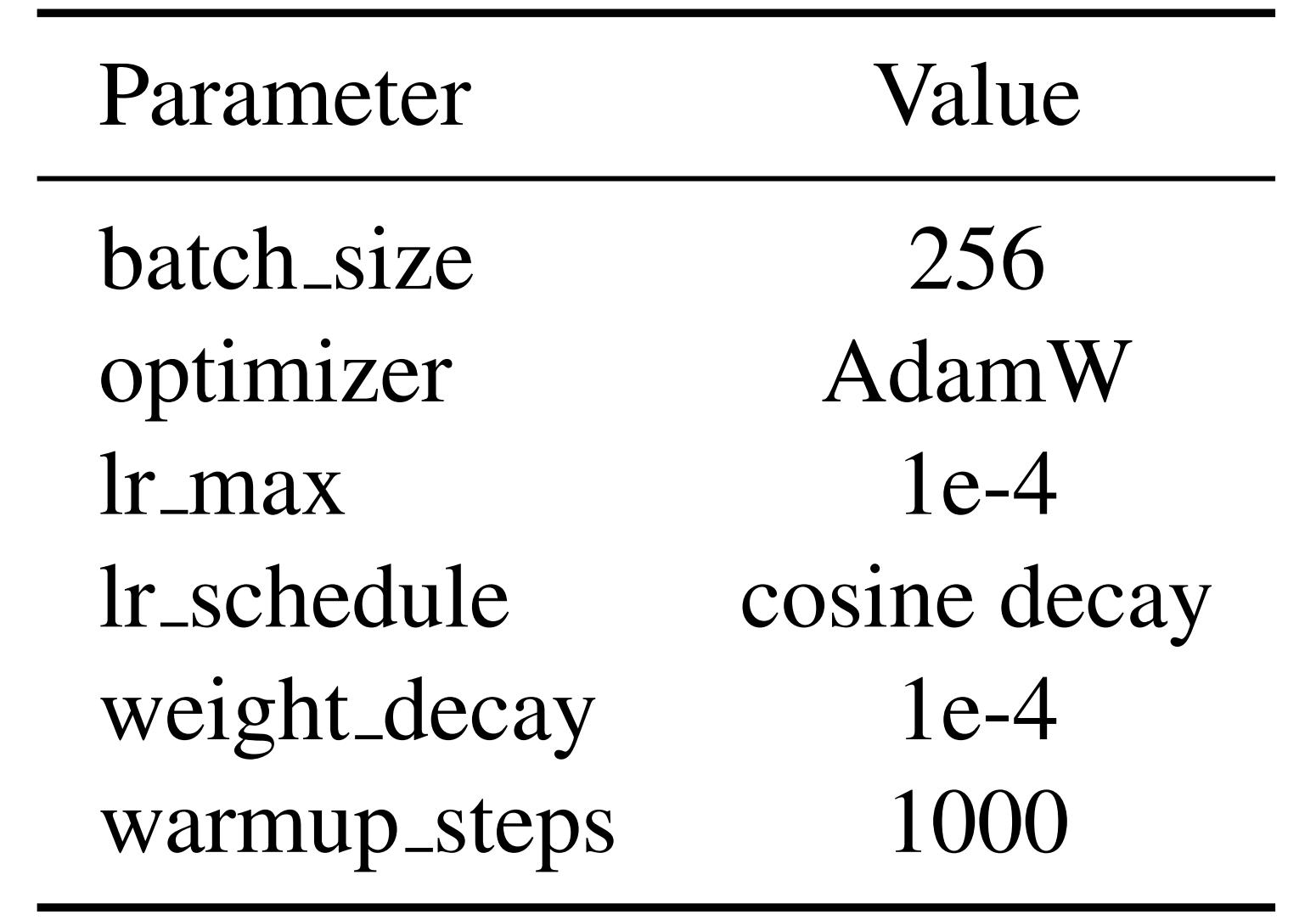
- 具体来说
3.4.2 Moto-GPT的训练细节
对于Moto-GPT而言,其中动作头仅在微调阶段包含
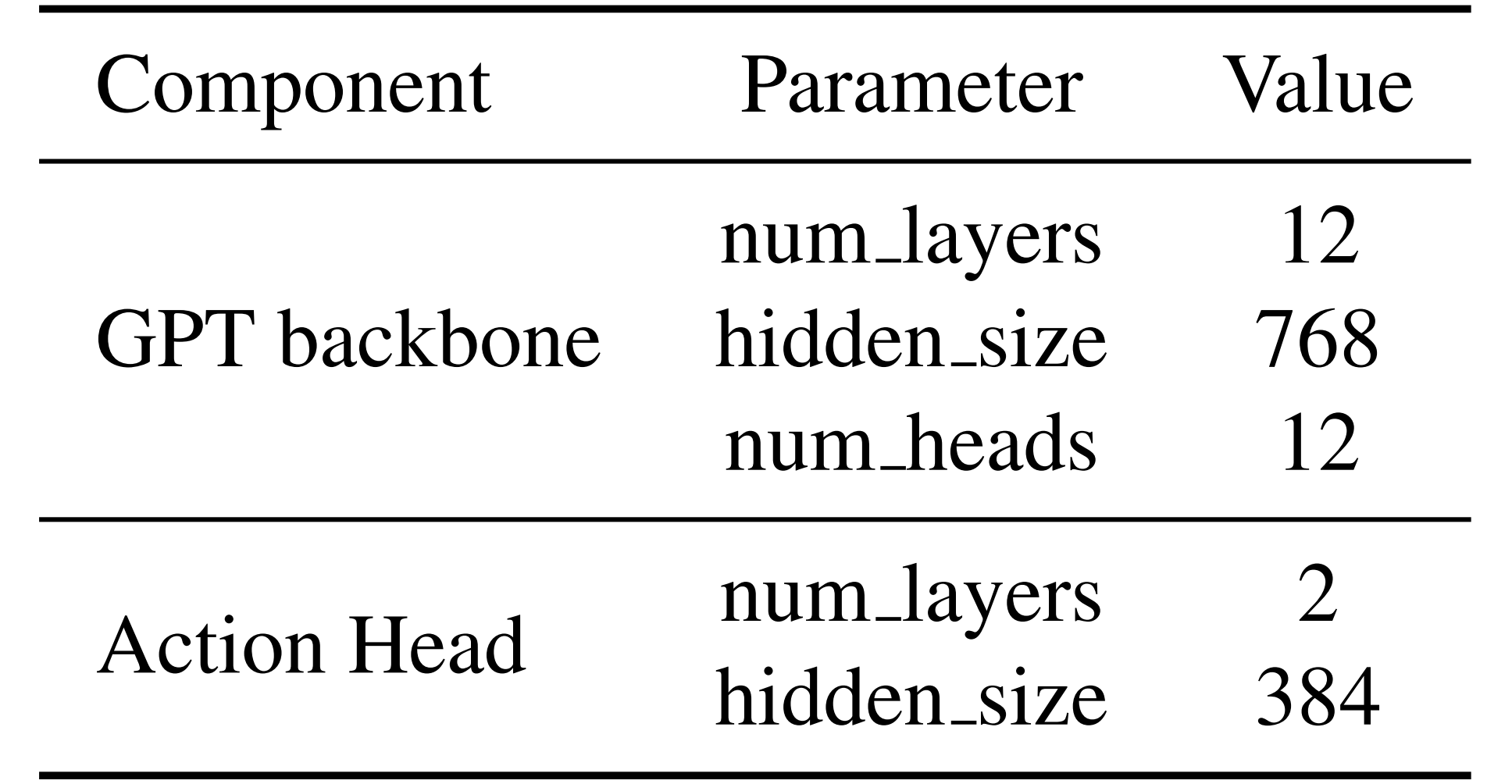
Moto-GPT处理最长为三帧的视频,且在预训练和微调阶段应用的视频下采样率与训练潜在运动Tokenizer时使用的采样率一致
在对不同基准进行微调时,Moto-GPT的动作数量在每个时间步插入潜在运动token之后的查询token数量有所不同
- 具体来说,对于SIMPLER基准,插入三个动作查询token,而对于CALVIN基准,插入五个
- 在预训练阶段,Moto-GPT使用八块A100-40G GPU进行10轮训练,相关的超参数列在表4中
微调阶段的超参数与预训练阶段一致,仅在训练轮数上有所不同
另,他们在RT1-Robot-Action数据集上对Moto-GPT进行三轮微调,在CALVIN数据集上进行18轮微调,使用四块A100-40G GPU
// 待更


















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











