






作者 | 黄浴 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/32390018002
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『大模型思维链』技术交流群
本文只做学术分享,如有侵权,联系删文
25年3月来自休斯敦 Rice U 的论文“Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models”。
大语言模型 (LLM) 在复杂任务中表现出卓越的能力。大型推理模型 (LRM)(例如 OpenAI o1 和 DeepSeek-R1)的最新进展通过利用监督微调 (SFT) 和强化学习 (RL) 技术来增强思维链 (CoT) 推理,进一步提高了数学和编程等系统 2 推理领域的性能。然而,虽然较长的 CoT 推理序列可以提高性能,但它们也会因冗长和冗余的输出而引入大量计算开销,这被称为“过度思考现象”。
高效推理旨在优化推理长度,同时保留推理能力,可提供实际好处,例如降低计算成本和提高对实际应用的响应能力。尽管高效推理具有潜力,但仍处于研究的早期阶段。
本文是一个结构化综述,系统地调查和探索当前在 LLM 中实现高效推理的进展。总体而言,依托 LLM 的内在机制,将现有工作分为几个关键方向:(1)基于模型的高效推理,考虑将全-长度推理模型优化为更简洁的推理模型或直接训练高效推理模型;(2)基于推理输出的高效推理,旨在在推理过程中动态减少推理步骤和长度;(3)基于输入提示的高效推理,旨在根据输入提示的属性(例如难度或长度控制)来提高推理效率。此外,介绍使用高效数据训练推理模型的方法,探索小型语言模型的推理能力,并讨论评估方法和基准测试。
大语言模型 (LLM) 已成为极为强大的 AI 工具,在自然语言理解和复杂推理方面展现出先进的能力。最近,专注于推理的 LLM(也称为大型推理模型 (LRM) [91])的出现,例如 OpenAI o1 [61] 和 DeepSeek-R1 [31],显著提高了它们在 System-2 推理领域 [8, 44](包括数学 [16, 35] 和编程 [7, 17])中的性能。这些模型从基础预训练模型(例如 LLaMA [30, 80]、Qwen [95])和下一个 token 预测训练 [23] 演变而来,利用思维链 (CoT) [86] 提示在得出最终答案之前生成明确的、逐步的推理序列,大大提高它们在推理密集型任务中的有效性。
LLM 中的推理能力通常是通过监督微调 (SFT) 和强化学习 (RL) 来开发的,这可以促进迭代和系统性的问题解决能力。具体来说,OpenAI o1 [61] 训练流水线可能将 SFT 和 RL 与蒙特卡洛树搜索 (MCTS) [71] 和处理奖励模型 (PRM) [47] 结合起来。DeepSeek-R1 最初使用 SFT 和由 RL 训练的 DeepSeek-R1-Zero 生成的长 CoT 推理数据进行微调,然后通过基于规则的奖励函数通过 RL 进一步完善。
然而,虽然长 CoT 推理显著提高了推理能力和准确性,但引入类似 CoT 的机制(例如,自洽性 [84]、思维树 [96]、激励 RL [31])也会导致输出响应过长,从而导致大量的计算开销和思考时间。例如,在向 OpenAI-o1、DeepSeek-R1 和 QwQ-32B-Preview 询问“2 加 3 的答案是多少?”[10] 时,就会出现“过度思考问题”。此类模型的推理序列有时会跨越数千个 tokens,其中许多是冗余的,对得出正确答案没有实质性贡献。这种冗长直接增加了推理成本和延迟,限制了推理模型在计算敏感的现实应用中的实际使用,包括实时自动驾驶系统、交互式助手、机器人控制和在线搜索引擎。
高效推理,特别是缩短推理长度,具有显著的好处,例如降低成本和增强实际部署中的推理能力。最近,许多研究 [32、33、54、56、98] 试图开发更简洁的推理路径,使高效推理成为一个突出且快速发展的研究领域。
如图所示:一个开发 LLM 高效推理的流水线
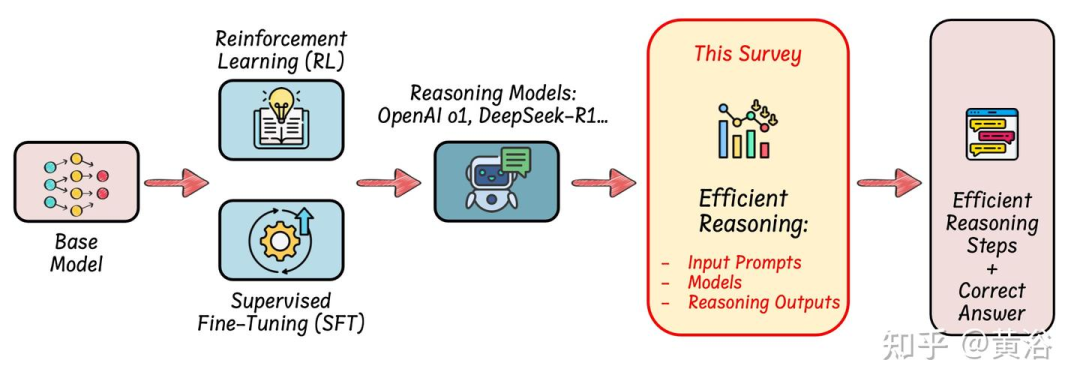
如图所示,现有的高效推理工作分为以下几个主要方向:(1)基于模型的高效推理,包括将全-长度推理模型优化为更简洁的推理模型或直接微调模型以实现高效推理;(2)基于推理输出的高效推理,在推理过程中动态减少推理步骤和输出长度;(3)基于输入提示的高效推理,通过利用提示属性(如提示引导长度或提示难度)来提高推理效率。与 LLM 中模型压缩技术的定义正交,例如量化 [27, 48] 或 kv-缓存压缩 [52, 103],它们专注于压缩模型大小并实现轻量级推理,LLM 中的高效推理强调通过优化推理长度和减少思考步骤来实现智能和简洁的推理。
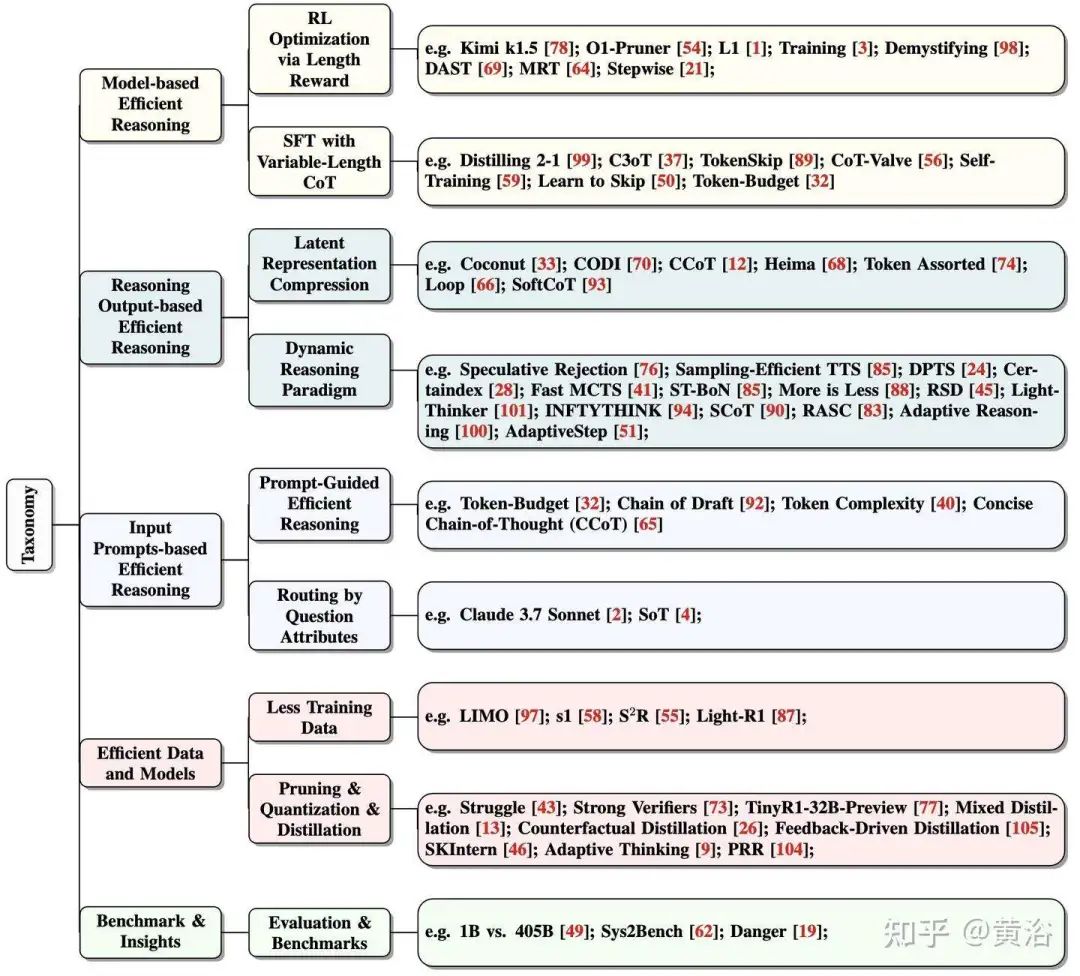
本文综述对各种方法的分类如下图所示:基于模型的高效推理,包括长度奖励的 RL 优化和可变长度 CoT 的 SFT;(2)基于推理输出的高效推理,包括潜表征压缩和动态推理范式;(3)基于输入提示的高效推理,包括提示-引导的高效推理和问题属性的路由方法;(4)高效数据和模型,包括少训练数据和裁剪、量化&蒸馏;(5)基准和视角,即评估。
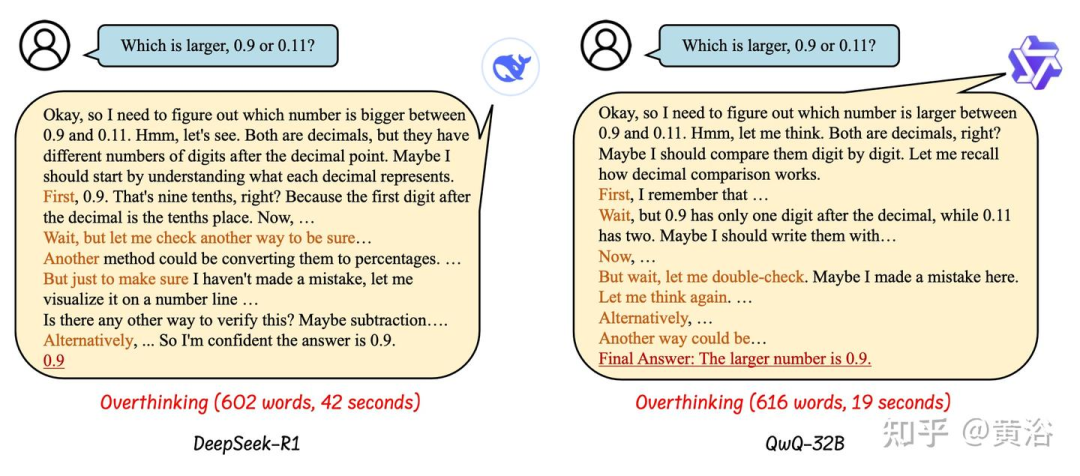
长 CoT 推理中的“过度思考现象” [10,78] 是指 LLM 生成过于详细或不必要复杂的推理步骤,从而损害其解决问题的效率的现象。具体而言,一些现代推理 LLM(尤其是一些具有推理能力的较小参数规模模型)往往会产生冗长的推理或多余的中间步骤,使得它们无法在用户定义的 token 预算用完之前提供答案,甚至更糟:由于冗长的推理步骤引入错误或降低逻辑清晰度而提供不正确的答案。
如图展示过度思考的例子。虽然过度思考 CoT 推理在其初始步骤中产生正确的答案,但其生成的推理步骤通常包括多个多余的中间步骤,从而导致不必要的复杂性和清晰度降低。考虑到与 LLM 解码阶段相关的极端资源成本(例如,OpenAI o1 每生成 100 万个 token 的成本为 60 美元),这是非常不受欢迎的行为;不言而喻,如果扩展推理生成导致错误答案,情况会更糟。相比之下,步骤更少的高效思考可以获得正确答案,这凸显了减少过度思考 token 的额外预算的可能性。
注:高效推理的挑战之所以被认为意义重大,是因为具有推理能力模型的预训练配方通常明确鼓励模型生成扩展推理步骤以追求正确答案。例如,当 DeepSeek-R1-Zero 训练时间更长时,其响应长度和基准性能都会增加 [31];观察这两种趋势通常被认为是成功推理支持训练配方的代表。因此,想要在推理时实现推理效率,在设计上就是违背模型的某些预训练目标,因此需要进行不凡的考虑。这项工作旨在总结不同的思维流派及其示范方法,以实现拥有高效而有能力推理模型这一具有挑战性但有益的目标。
基于模型的高效推理
从模型角度来看,这类工作侧重于对 LLM 进行微调,以提高其简洁高效推理的内在能力。
具有长度奖励设计的 RL
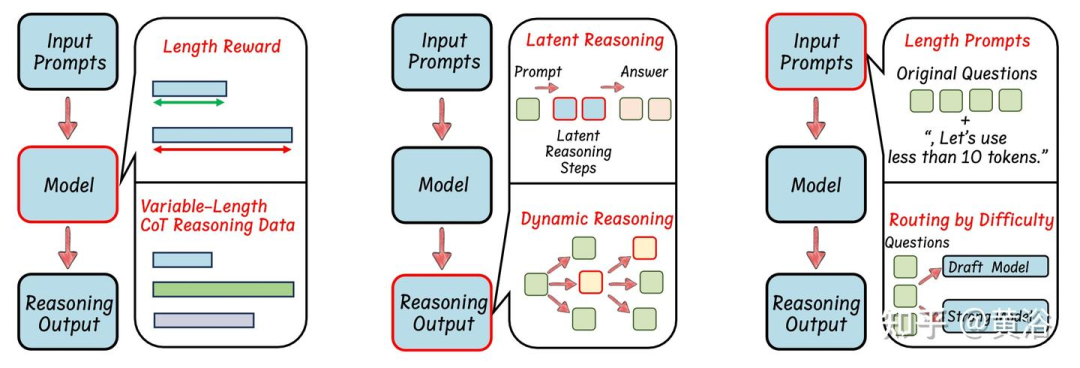
大多数推理模型都是使用基于 RL 的方法进行训练的(例如,DeepSeek-R1 [31]、DeepSeek-R1-Zero [31]、OpenAI o1 [61]、QwQ-32B-Preview [79]),这些方法侧重于准确性奖励和格式奖励 [31]。为了提高推理长度效率,一些研究提出将长度奖励整合到 RL 框架中,从而有效缩短推理过程(如图所示)。原则上,长度奖励会为简短、正确的答案分配更高的分数,同时惩罚冗长或不正确的答案,从而优化推理路径的长度。

现有的工作利用传统的 RL 优化技术结合显式的基于长度奖励来控制 CoT 推理的长度。下表显示一些详细的长度奖励。
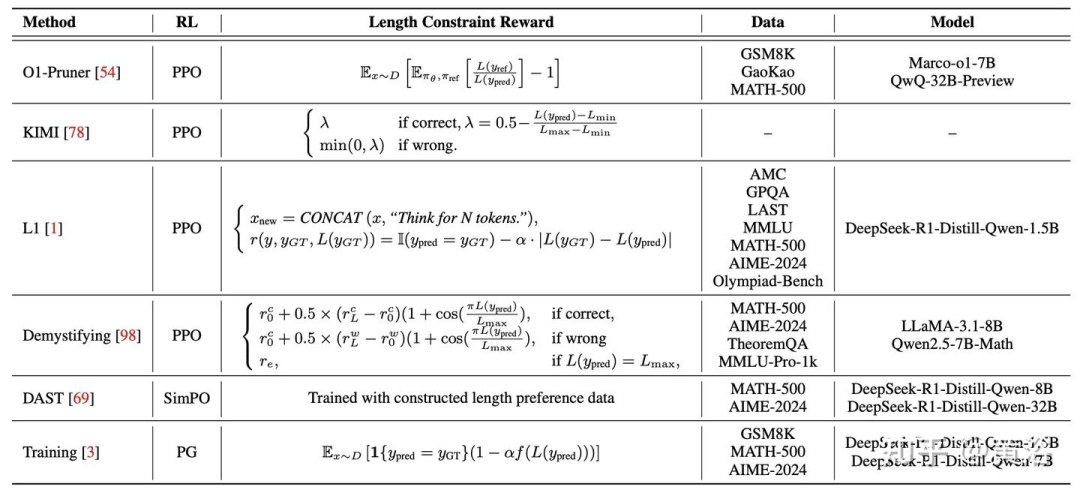
这些基于 RL 的方法可以缓解具有推理能力的 LLM 中的过度思考,其中过度思考是指不必要地延长推理过程,导致推理时间更长并超出计算预算。通过实现与 LLM 原始推理能力的几乎无损对齐,这些预算高效的 RL 策略使资源受限场景中推理 LLM 的部署变得民主化。
带有可变长度 CoT 数据的 SFT
使用可变长度 CoT 数据对 LLM 进行微调是提高推理效率的有效方法。如图所示,这一系列工作通常涉及:(1)通过各种方法构建可变长度 CoT 推理数据集,以及(2)将 SFT 与收集的推理模型数据结合使用,使 LLM 能够学习封装有效知识的紧凑推理链。注:这种方法不仅限于 RL 训练的推理模型;它还可以通过注入高效的推理能力来直接增强推理模型,类似于蒸馏推理模型中使用的能力。(例如,DeepSeek-R1-Distill-Qwen [31])。
下表是 CoT 长度控制中不同策略优化方法的比较:

构建可变长度 CoT 推理数据集。可变长度 CoT 推理数据集是指可以指导 LLM 获得正确答案的长/短推理步骤的数据集。现有的研究通常通过向预训练的推理模型提出问题来收集长 CoT 数据。基于长 CoT 数据,关键挑战是:如何收集短 CoT 数据?总体而言,可变长度 CoT 推理数据集可以通过后推理或推理过程中创建。在下表中列出一些详细方法。
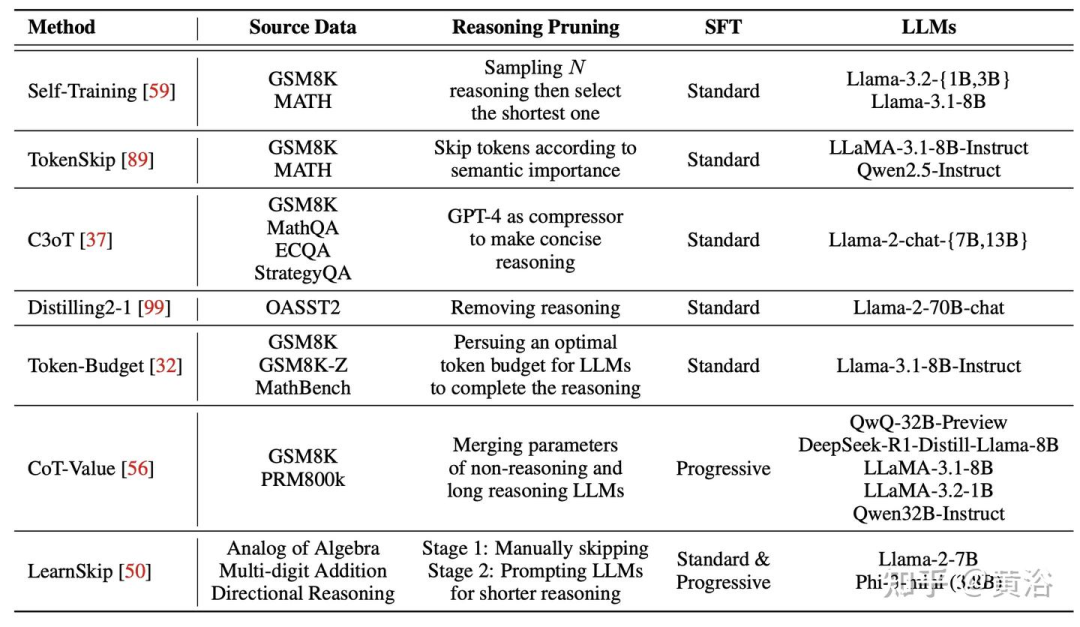
微调方法。在收集可变长度的 CoT 数据后,现有的研究通过多种方式对 LLM 进行微调以实现高效推理,其中包括标准微调(例如,参数高效微调,如 LoRA [36] 或全微调)和渐进微调。
基于推理输出的高效推理
从输出中推理步骤的角度来看,这类工作侧重于修改输出范式,以增强 LLM 简洁高效推理的能力。
将推理步骤压缩为更少的潜表示
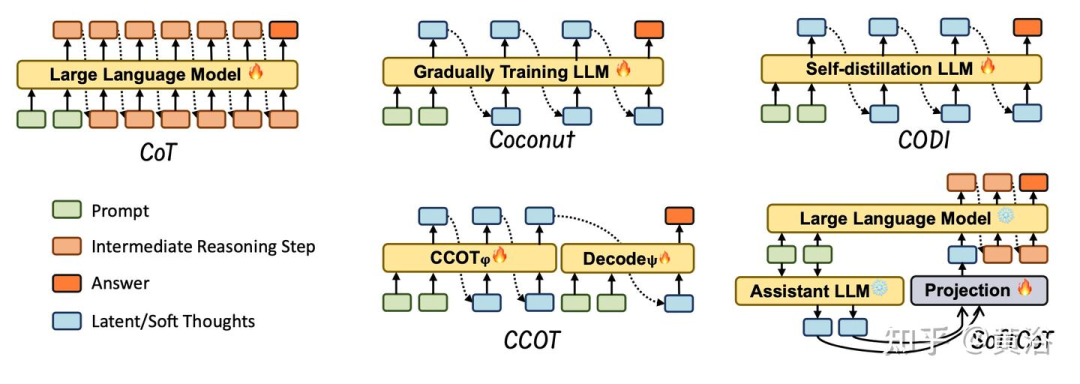
虽然标准 CoT 方法通过明确编写推理步骤来提高 LLM 性能,但最近的研究 [22] 表明,只需添加中间“思考”token,甚至添加毫无意义的填充符(例如“......”)[63],也可以提高性能。[29] 通过在隐空间中反复扩展而不是冗长的文本来扩展更深层次的推理。这些发现强调,好处往往在于更多的隐藏计算,而不是纯粹的文本分解。基于潜在推理可以让 LLM 更高效、更灵活地推理,使用更少(或没有)显式文本中间步骤的见解,几种新方法侧重于用更紧凑的潜表示压缩或替换显式 CoT。
总体而言,这些方法可分为两类:使用潜表示训练 LLM 进行推理或使用辅助模型。如图显示其中一些方法的可视化比较。
推理过程中的动态推理范式
现有研究侧重于修改推理范式以实现更高效的推理。推理过程中的关键是选择适当的标准来指导推理策略。当前的无训练方法使用各种标准探索动态推理,例如奖励引导、基于置信度和基于一致性的选择性推理。此外,基于总结的动态推理方法,在训练过程中内在地整合 LLM 的输出总结范式。
通过显式标准进行动态推理。使用 RL [31] 进行训练-时间扩展可以显著增强 LLM 的推理能力。然而,它需要大量的计算资源来扩大模型训练,这使得它的成本过高 [31]。作为一种替代方案,研究人员探索测试-时间推理,也称为测试-时间扩展 [72]。测试-时间扩展不是依靠训练来学习 CoT 推理步骤,而是利用各种推理策略,使模型能够对复杂问题“思考更长远和更广泛”。这种方法通过增加推理期间分配的计算资源,持续提高需要推理的具有挑战性数学和代码问题性能 [5, 72]。
测试-时间扩展,利用各种推理策略来生成更长、更高质量的 CoT 响应。有几种方法可以扩大推理范围。(1)N 中最佳采样 [76, 85] 涉及为给定提示生成多个响应,扩大搜索空间以识别更好的解决方案。生成后,使用多数投票来选择最佳响应,其中选择最常出现的响应;或通过奖励模型,根据预定义的标准评估响应质量。这种方法已被证明可以显著增强 LLM 的推理能力 [5]。(2)基于波束搜索 [5, 24, 28],它与 N 中最佳不同,它将生成分为多个步骤。波束搜索不是一次性生成整个响应,而是在每一步使用过程奖励模型(PRM) [81] 选择最有希望的中间输出,同时丢弃较少的最优输出。这样可以更细粒度地优化响应生成和评估。 (3) 蒙特卡洛树搜索 (MCTS) [41],其中并行探索多个解决方案路径。 MCTS 沿着解决方案树的不同分支生成部分响应,对其进行评估,并将奖励值反向传播到较早的节点。 然后,该模型选择具有最高累积奖励的分支,与传统的波束搜索相比,确保了更精细的选择过程。
虽然测试-时间扩展可以显着减少训练时间扩展开销 [5],但生成的大量响应仍然使推理在计算上很昂贵。 为了解决这个问题,最近的研究一直在探索优化测试-时间扩展的方法。
基于总结的动态推理。一些现有方法选择通过训练 LLM 总结中间思维步骤来优化推理效率。LightThinker [101] 建议训练 LLM 学习何时以及如何压缩中间推理步骤。LightThinker 不会存储长思维链,而是将冗长的推理压缩为紧凑的“要点(gist)token”,以减少内存和计算成本。实现这种总结范式需要一个稀疏模式的注意掩码,确保模型只关注必要的压缩表示。InftyThink [94] 引入一种迭代推理方法,该方法可以实现本质上无限的推理链,同时保持很强的准确性,而不会超过上下文窗口限制。它通过迭代地生成一个想法、总结它并丢弃以前的想法和总结,只保留最新的总结来实现这一点。此外,InftyThink 提供一种将现有推理数据集转换为迭代格式的技术,以便在该范式下训练模型。
基于输入提示的高效推理
从输入提示和问题的角度来看,这类工作侧重于根据输入提示的特点强制长度约束或路由 LLM,以实现简洁高效的推理。
提示引导的高效推理
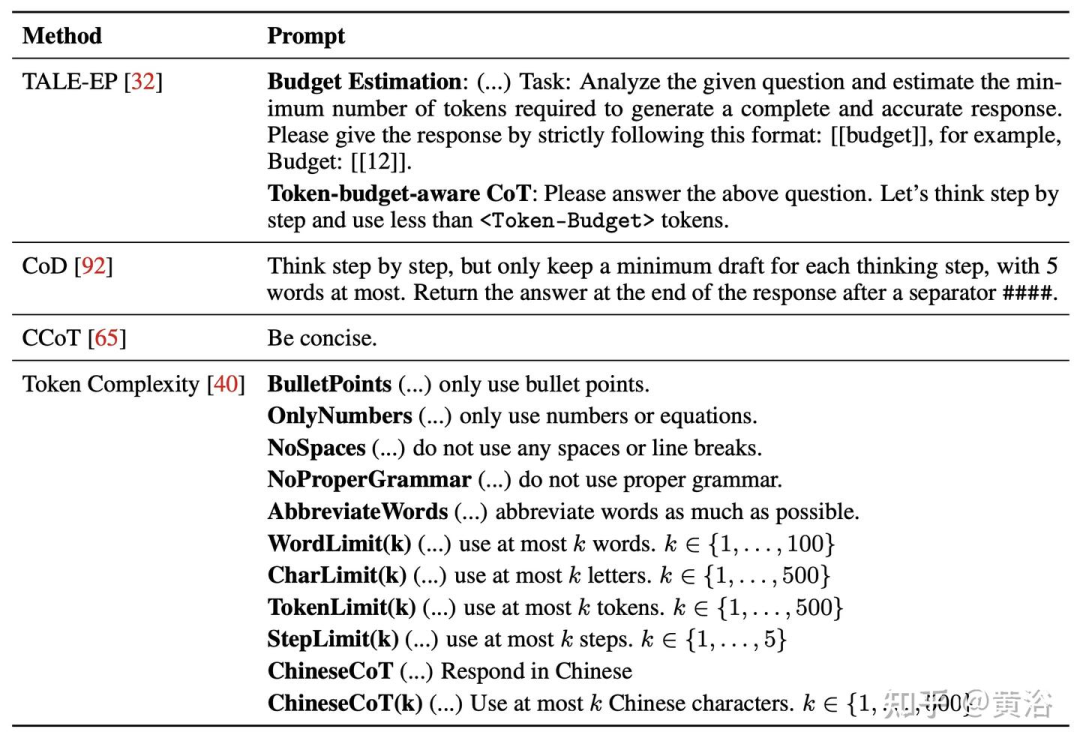
提示引导的高效推理明确指示 LLM 生成更少的推理步骤,可以成为提高推理模型效率的一种直接而高效的方法。如表所示,不同的方法提出不同的提示,以确保模型的简洁推理输出。
提示属性驱动的推理路由
用户提供的提示范围从简单到困难。高效推理的路由策略根据查询的复杂性和不确定性动态确定语言模型如何处理查询。理想情况下,推理模型可以自动将较简单的查询,分配给速度更快但推理能力较弱的 LLM,同时将较复杂的查询,定向到速度较慢但推理能力较强的 LLM。
通过高效的训练数据和模型压缩提高推理能力
使用更少的数据训练推理模型
提高推理模型的效率不仅需要优化模型架构,还需要优化用于训练的数据。最近的研究表明,仔细选择、构建和利用训练数据可以显著减少数据需求,同时保持甚至提高推理性能。虽然所有方法都侧重于高效的数据选择,但它们在定义和利用效率方面有所不同。
通过蒸馏和模型压缩实现小型语言模型的推理能力
LLM 已在各种复杂任务中展现出卓越的推理能力,这得益于它们对各种数据集的广泛训练。然而,它们对计算和内存的大量需求对在资源受限的环境(如边缘设备、移动应用程序和实时系统)中的部署提出了挑战。在效率、成本或延迟是主要考虑因素的情况下,小型语言模型 (SLM) 提供了一种可行的替代方案。SLM 在严格的资源限制下仍然运行时保持强大推理能力的能力,对于扩大 AI 驱动的推理系统的可访问性和实用性至关重要。为了实现这一目标,探索两类主要方法:蒸馏和模型压缩。
评估和基准
最近的研究引入基准和评估框架,以系统地评估 LLM 的推理能力。随着 LLM 在执行复杂推理任务的能力方面不断进步,对严格、标准化的评估指标和框架的需求变得越来越重要。
Sys2Bench。[62] 开发 Sys2Bench,这是一个全面的套件,旨在评估五个推理类别的 LLM,包括算术、逻辑、常识、算法和规划任务。该基准包含 11 个不同的数据集,涵盖各种推理任务。它包括用于算术问题的 GSM8K 和 AQuA、用于常识推理的 StrategyQA 和 HotPotQA、用于逻辑推理的 ProntoQA、用于算法任务的 Game of 24 和 Bin Packing,以及用于规划任务的 BlocksWorld、Rubik’s Cube、TripPlan 和 Calendar Plan。
评估过度思考。[19] 引入一个框架来系统地分析 LLM 中的“过度思考”,其中模型倾向于扩展内部推理而不是必要的环境交互。通过检查智体任务中的 4,018 条轨迹,该研究发现诸如分析瘫痪、流氓行为和过早脱离等模式。[19] 还提出了一种“过度思考分数”,并表明分数越高,任务绩效越差之间存在很强的相关性。缓解策略(例如选择过度思考分数较低的解决方案)可以将性能提高 30%,同时将计算开销降低 43%。
计算最佳测试-时间扩展 (TTS)。 [49] 研究 TTS 策略对 LLM 性能的影响,重点研究策略模型、过程奖励模型和问题难度如何影响 TTS 的有效性。他们的研究结果表明,计算最优的 TTS 策略高度依赖于这些因素。
这里也推荐下自动驾驶之心的多模态大模型课程,课程从通用多模态大模型,到大模型微调,最终在聚焦在端到端自动驾驶多模态大模型,基本上面试的东西课程里面都有介绍。目前已经结课,课程大纲如下:

扫码学习课程!

自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









