







近期,思维链(Chain of Thought)领域出现了一些令人兴奋的研究进展,这些研究通过不同的方法增强了大型语言模型(LLMs)的推理能力:
-
Graph of Thoughts (GoT): Solving Elaborate Problems with Large Language Models
- 论文链接:https://arxiv.org/pdf/2308.09687
- 代码链接:https://github.com/spcl/graph-of-thoughts
- 简介:论文介绍了一种名为“思维图谱”(Graph of Thoughts,简称GoT)的框架,它通过将信息生成建模为任意图来增强大型语言模型的提示能力。在这个框架中,信息单元(即“LLM思考”)被视为顶点,而边对应于这些顶点之间的依赖关系。这种方法允许将任意的LLM思考结合起来,形成协同效应,提取整个思考网络的本质,或使用反馈循环增强思考。研究表明,GoT在不同任务上优于现有技术,例如在排序任务上,与树形思考(Tree of Thoughts,简称ToT)相比,质量提高了62%,同时成本降低了31%以上。

-
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
- 链接:https://arxiv.org/abs/2406.04271
- 简介:论文提出了一种名为“思维缓冲区”(Buffer of Thoughts,简称BoT)的新方法,旨在通过增强准确性、效率和鲁棒性来提升大型语言模型的推理能力。BoT通过存储一系列从各种任务的问题解决过程中提取的高级别思考模板(thought-template),并在每个问题中检索相关的思考模板,通过特定的推理结构进行高效的思考增强。此外,BoT还提出了一个缓冲区管理器(buffer-manager),以动态更新元缓冲区,从而随着解决更多任务,提高缓冲区的容量。

-
Reversal of Thought: Enhancing Large Language Models with Preference-Guided Reverse Reasoning Warm-up
- 链接:https://arxiv.org/abs/2410.12323
- 代码链接:https://github.com/RoT-llm/Reversal-of-Thought
- 简介:论文提出了一种名为“思维反转”(Reversal of Thought,简称RoT)的新框架,旨在通过偏好引导的反向推理热身策略来增强LLMs的逻辑推理能力。RoT利用元认知机制和成对偏好自评估,通过演示生成特定于任务的提示,与通过人类反馈强化学习(RLHF)塑造的LLMs的认知偏好相一致。通过反向推理,RoT使用认知偏好管理器评估知识边界,并通过聚合已知任务的解决方案逻辑和未知任务的风格模板,进一步扩展LLMs的推理能力。

-
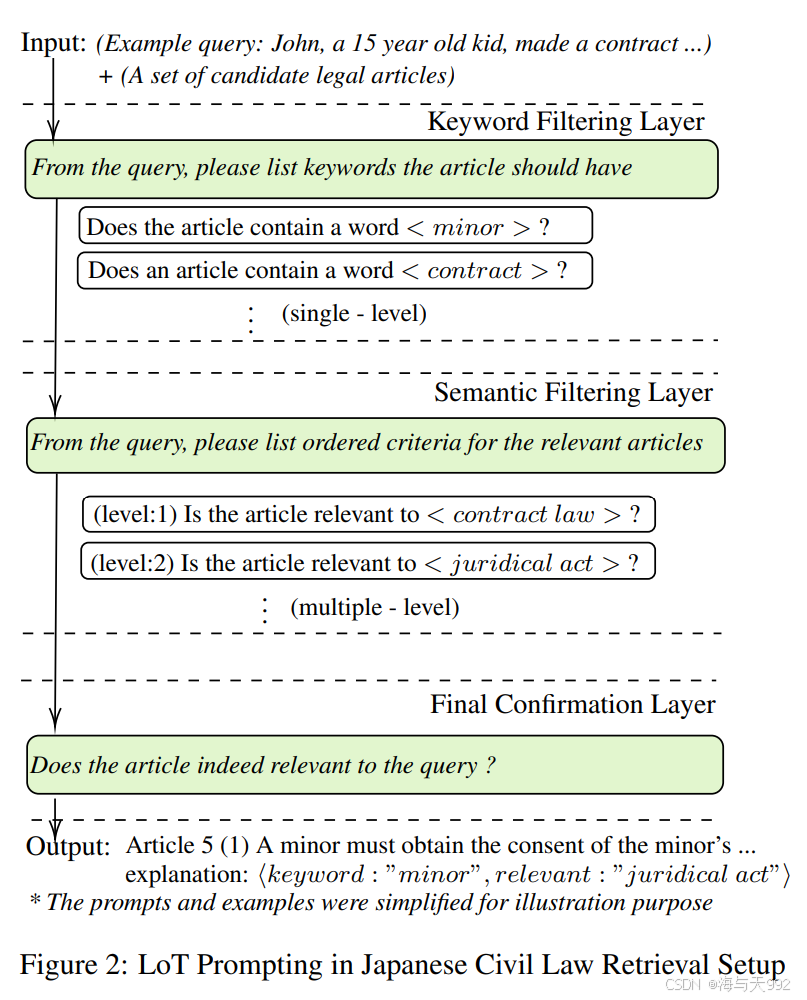
Layer-of-Thoughts Prompting (LoT): Leveraging LLM-Based Retrieval with Constraint Hierarchies
- 链接:https://github.com/RoT-llm/Reversal-of-Thought
- 简介:论文介绍了一种名为“思维层次”(Layer-of-Thoughts Prompting,简称LoT)的新方法,它利用约束层次结构来过滤和优化对给定查询的候选响应。通过整合这些约束,LoT方法实现了一个结构化的检索过程,增强了可解释性和自动化。LoT通过在思维层次中表示推理过程,其中节点(称为思维)表示推理步骤,这些思维被划分为层次,并被归类为层次思维和选项思维,分别处理用户给出的概念步骤和协助寻找解决方案。LoT框架利用层次结构来过滤和排名来自给定语料库的文档,基于查询的相关性得分可以聚合使用多种指标,确保文档排名的高效和有效。


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











