







当每个人都在谈论 DeepSeek-R1 在模型推理方面的里程碑时,阿里巴巴的 Qwen 模型却一直被掩盖。尽管没有过多的喧嚣,Qwen 模型凭借其开源特性以及在代理功能方面的独特优势,正悄然崛起。

从一开始,Qwen 模型的研发团队就致力于使其具备工具使用等代理能力,这种前瞻性思维使得 Qwen 模型在人工智能领域展现出了独特的潜力。
本文将深入探讨 Qwen 模型的发展历程,以及其如何通过 Qwen-Agent 框架实现强大的推理能力,与 OpenAI 和 DeepSeek 等先进模型相媲美甚至超越。同时,我们还将聚焦于 Qwen-Agent 框架,解析其如何构建一个成熟的代理生态系统,使 Qwen 模型能够自主规划、调用函数并执行复杂的多步骤任务。
一、Qwen 模型的发展脉络
(一)早期版本:Qwen 1.0 与 Qwen-Chat
2023 年年中,阿里云 Qwen 团队首次开源了 Qwen 1.0 系列,涵盖 1.8B、7B、14B 和 72B 参数的基础大型语言模型(LLM),在多达 3 万亿个多语言数据标记上进行预训练,重点聚焦中文和英文,其上下文窗口高达 32K 个标记,部分早期变体甚至达到 8K。除基础模型外,阿里巴巴还推出了通过监督微调和人类反馈强化学习(RLHF)对齐的 Qwen-Chat 变体。即便在这一早期阶段,Qwen 模型便已展现出广泛技能,涉及对话、内容生成、翻译、编码、数学问题求解等多个领域,且能够初步使用工具或充当代理,这标志着 Qwen 团队在设计之初便将代理行为纳入考量,为其后续发展奠定了坚实基础。
(二)迭代升级:Qwen-1.5、Qwen 2 及其变体

-
Qwen-1.5:2024 年 2 月发布的 Qwen-1.5 在模型规模上进一步拓展,引入 0.5B、4B、32B 乃至 110B 参数模型,并统一支持 32K 上下文长度。在多语言理解、长上下文推理、对齐等通用技能上实现提升的同时,其代理能力在工具使用基准测试中达到与 GPT-4 相当的水平,工具选择与使用准确率超过 95%。
-
Qwen 2:同年 6 月推出的 Qwen 2 继承了前代基于 Transformer 的架构,并将分组查询注意(GQA)应用于所有模型大小,提升模型推理速度并减少内存占用。随后,2024 年 8 月,针对特定任务的 Qwen2-Math、Qwen2-Audio(用于理解和总结音频输入的音频与文本模型)以及 Qwen2-VL 相继问世。其中,Qwen2-VL 作为重要里程碑,引入诸多创新技术,如简单动态分辨率(可处理任意分辨率图像,动态转换为可变数量视觉标记)、多模态旋转位置嵌入(MRoPE,用于在文本、图像和视频等所有模态中更好地对齐位置信息),能够处理长达 20 多分钟的视频,并可集成到手机、机器人等设备上。
(三)应对竞争:Qwen2.5、Qwen2.5-VL、Qwen2.5-Max 及 QwQ-32B
-
Qwen2.5 系列:面对 DeepSeek 等新兴竞争对手的挑战,阿里巴巴于 2024 年 9 月推出 Qwen2.5,包含从 5 亿到 720 亿参数的多款模型,在多达 18 万亿个 token 的大型数据集上预训练,涵盖语言、音频、视觉、编码和数学等多领域应用,支持 29 种以上语言,输入上下文长度达 128K token,输出长度可达 8K token。其中,2025 年 1 月发布的 Qwen2.5-1M 模型更是将上下文处理能力拓展至最多 100 万个 token,处理速度提升 3-7 倍。
-
Qwen2.5-VL:作为 2.5 版本中的亮点,Qwen2.5-VL 在数字环境中充当视觉代理,不仅能描述图像,还能与之交互,根据视觉输入进行“推理和动态指导工具”。它采用原生动态分辨率(用于图像)、动态帧速率训练和绝对时间编码(用于视频),可处理不同尺寸图像和数小时长视频,并在 Qwen2-VL 基础上改进 MRoPE 的时间分量与绝对时间对齐,实现对长视频的有效处理。此外,Qwen2.5-VL 能够控制计算机、手机等设备,完成预订航班、检索天气信息、编辑图像、安装软件扩展等任务,功能与 OpenAI 的 Operator 相似,成为多模态模型领域的一大突破。
-
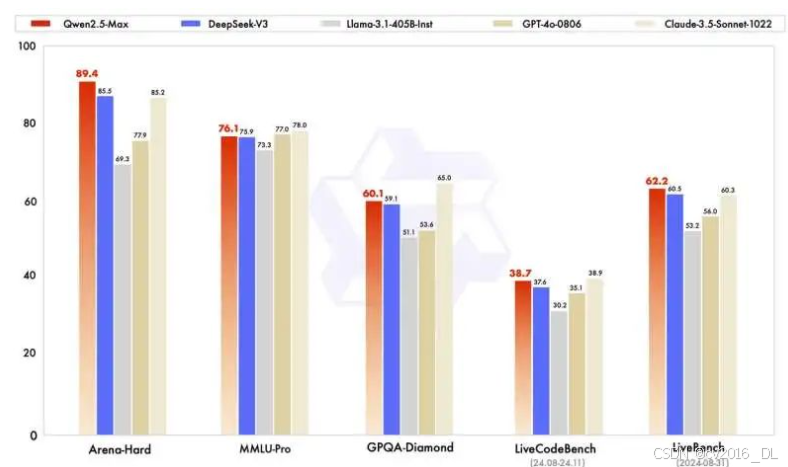
Qwen2.5-Max:Qwen 团队同期开发的 Qwen2.5-Max 是一个大规模混合专家(MoE)模型,在超过 20 万亿个 token 上训练,并通过监督微调(SFT)和人类反馈强化学习(RLHF)进一步完善,性能足以与 DeepSeek-V3、Llama3.1-405B、GPT-4o 和 Claude3.5-Sonnet 等顶级大型模型相媲美甚至超越,彰显了 Qwen 模型在高端模型领域的竞争力。
-
QwQ-32B 推理模型:2024 年 11 月首次亮相的 QwQ-32B 作为增强逻辑推理的实验预览模型,2025 年 3 月初开始发挥重要作用。得益于对强化学习(RL)的有效扩展,仅拥有 320 亿参数的 QwQ-32B 性能可比肩规模大得多(671B 参数,37B 活动参数)的 DeepSeek-R1,且优于较小的 o1-mini,为具备强大推理能力的 AI 代理开辟了新的可能性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









