






点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
2025年机器人具身智能领域,一场“多模态与自主学习”的融合革命正悄然爆发!ICLR、RSS、ICRA、CVPR等顶会集中收录8篇重磅文献,清一色聚焦视觉-语言-动作(VLA)模型与强化学习(RL)的融合,直指机器人落地的核心痛点——如何在真实场景中更聪明地决策、更精准地执行任务?
想知道这些顶会研究具体提出了哪些创新方案?不同文章在技术细节、应用场景上又有哪些独特突破?接下来,我们将逐一拆解这 8 篇文献的核心亮点,带您读懂 VLA+RL 如何重塑机器人智能!
更多干货和最新内容欢迎加入我们的具身社区,一起交流。

GRAPE: Generalizing Robot Policy via Preference Alignment (ICLR 2025)
论文链接:https://openreview.net/pdf?id=XnwyFD1Fvw&utm_source=chatgpt.com
作者单位:北卡罗来纳大学教堂山分校、华盛顿大学、芝加哥大学
一句话汇总核心思路:通过轨迹级 VLA 对齐、任务阶段分解及灵活时空约束的偏好建模,解决了 VLA 模型泛化差与目标适应性弱的问题。
解决了哪些问题?有哪些提升?
当前视觉语言动作(VLA)模型虽在机器人任务中取得进展,但存在显著局限:一是完全依赖行为克隆,导致对未见任务的泛化能力较差;二是需通过微调复制专家在不同设置下的演示,既引入分布偏差,又限制了模型对效率、安全性、任务完成度等不同操作目标的适应性,难以满足多样化机器人操作需求。
为弥补上述差距,研究提出名为 GRAPE(通过偏好对齐来泛化机器人策略)的方案:首先,在轨迹水平上对 VLA 模型进行对齐,通过隐含建模成功与失败试验的奖励,提升模型对不同任务的推广能力;其次,将复杂操作任务拆解为独立阶段,并借助大型视觉语言模型提出的关键点,通过可定制的时空约束自动引导偏好建模,且这些约束具备灵活性,可根据安全、效率、任务成功等不同目标调整。
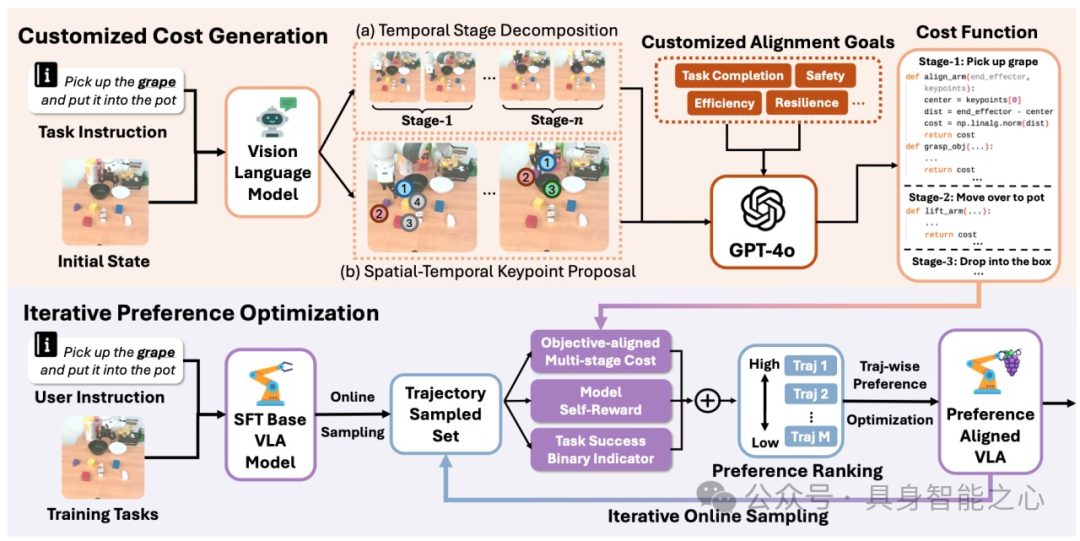
图1|GRAPE首先使用VLM将操作任务(上)分解为时间阶段,并确定每个子任务的关键空间点。给定用户指定的对齐目标,它会提示VLM为每个阶段生成成本函数。在迭代偏好优化过程中(下图),从基本VLA模型中抽取离线轨迹,使用多阶段成本、自我评价和任务成功指标进行评分,并对其进行排序以形成偏好。GRAPE对VLA模型进行迭代优化,直至收敛。
在现实世界与模拟环境的多任务评估中,GRAPE 展现出显著优势:不仅将最先进 VLA 模型的域内操作任务成功率提升51.79%、未见操作任务成功率提升58.20%,还能与多样化目标保持一致 —— 在安全性目标下碰撞率降低37.44%,在效率目标下启动步长减少11.15%,全面优化了机器人操作性能。
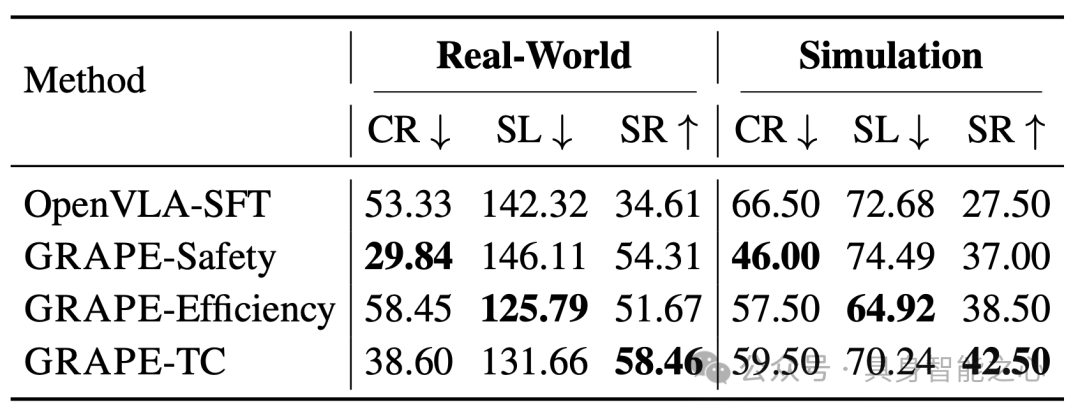
图2|不同目标的结果。GRAPE-Safety、GRAPE-Efficiency、GRAPE-TC是分别以安全、效率、任务完成目标训练的模型。使用碰撞率(CR),步长(SL),成功率(SR)来评估安全性,效率和任务完成能力。

图3|通过安全目标对齐的GRAPE- safety与通过任务完成目标对齐的GRAPE- tc和OpenVLA-SFT的比较。评估他们在安全关键任务上的表现,指令是:拿起白盒,放入黑锅。
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning(2025)
论文链接:https://arxiv.org/abs/2505.18719
项目链接:https://github.com/GuanxingLu/vlarl
作者单位:清华大学、南洋理工大学
一句话汇总核心思路:以轨迹级 RL 表达式建模操作轨迹、微调过程奖励模型应对稀疏奖励,并辅以规模化实施策略,解决 VLA 模型分布外场景失败问题,提升任务性能并显现推理扩展规律迹象。
解决了哪些问题?有哪些提升?
近期高容量视觉语言动作(VLA)模型通过模仿人类示范,在多项机器人操作任务中表现出色,但存在明显短板:其训练依赖访问状态有限的离线数据,导致模型在分布外场景(即训练数据未覆盖的场景)中频繁出现执行失败,无法稳定适配复杂多变的实际操作需求,制约了模型的实用价值。
为突破这一局限,研究提出 VLA-RL 框架(融合在线强化学习的 VLA 优化方案):首先,构建轨迹级强化学习(RL)表达式,将通用机器人操作轨迹转化为多模态多轮对话形式,以此训练自回归 VLA,实现对在线收集数据的有效利用;其次,针对强化学习中的稀疏奖励难题,微调预训练视觉语言模型,使其成为机器人过程奖励模型 —— 该模型基于自动提取的任务片段标注伪奖励标签进行训练,为模型优化提供更密集的反馈;最后,通过课程选择策略、GPU 均衡化的向量化环境、批量解码及评价器预热等策略,保障框架在规模化应用中的稳定性与效率。
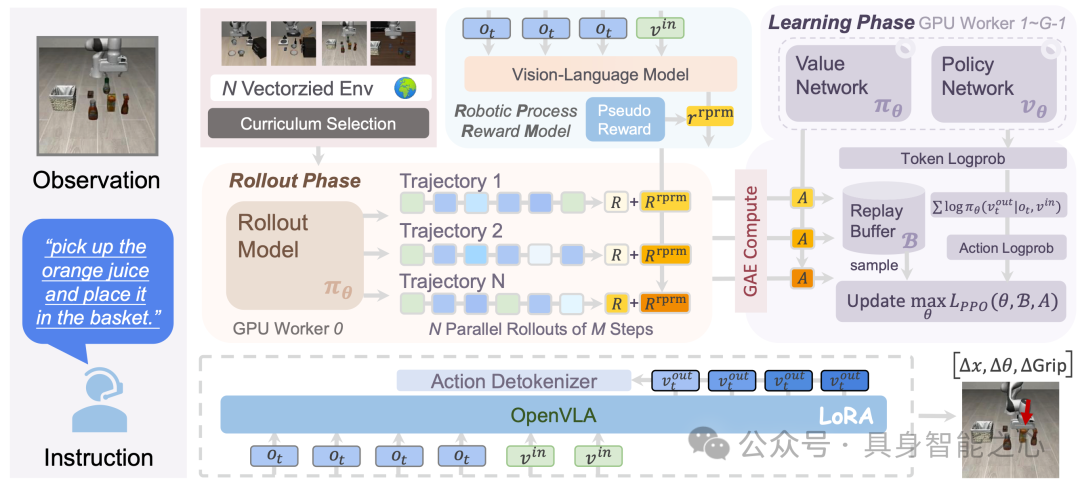
图4|该系统由基于transformer的策略、同质值模型、冻结机器人过程奖励模型和矢量化环境组成。
实验验证显示,VLA-RL 成效显著:在 LIBERO 平台的 40 个挑战性机器人操作任务中,它使 OpenVLA-7B 模型性能较当前最强微调基线提升明显,且能与 πo-FAST 等先进商业模型比肩;更关键的是,测试发现 VLA-RL 可通过测试时间优化进一步增强性能,这一现象为机器人领域存在早期推理扩展规律提供了重要迹象,为后续研究提供了方向参考。
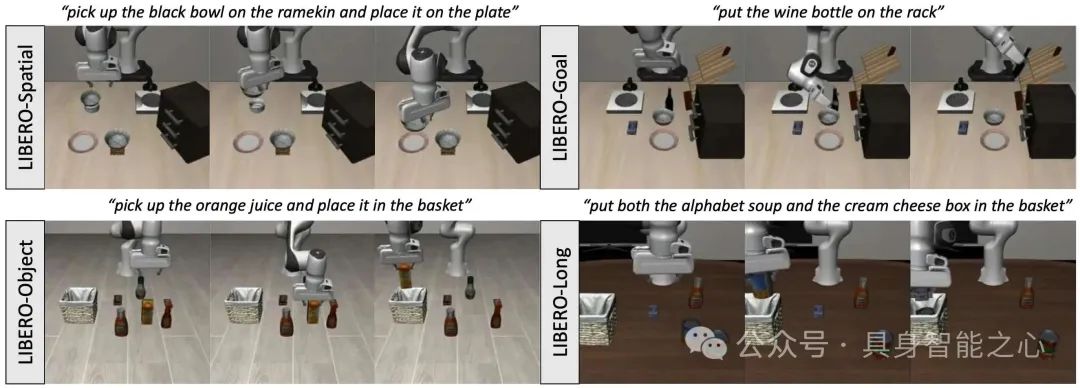
图5|环境和任务。为了进行仿真,我们在一个名为LIBERO的常用机器人操作基准上评估了四个任务套件,这些任务套件专注于不同的挑战。
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations(RSS 2025)
论文链接:https://openreview.net/pdf?id=a6lsCozWyM
项目链接:https://rewind-reward.github.io/
作者单位:南加州大学,亚马逊机器人,(KAIST)金宰哲人工智能学院
一句话汇总核心思路:基于少量演示预训练语言基奖励函数与策略,通过少在线交互的微调适配未见任务,解决传统方法需为新任务单独设计奖励或演示的问题,提升泛化与样本效率。
解决了哪些问题?有哪些提升?
当前机器人学习新操作任务时,标准强化学习(RL)与模仿学习方法存在显著局限:二者均需针对每个新任务,通过人类设计专属奖励函数或提供专门演示来获取专家指导,无法仅依靠语言指令高效适配新任务,且针对新任务的重复训练过程成本高、扩展性差,难以满足大规模、多样化的机器人操作需求。
为突破这一限制,研究推出ReWiND框架,核心思路是通过“预训练+少样本微调”实现语言驱动的任务泛化:首先,基于少量演示数据集完成两项关键预训练——一是训练数据高效的语言基奖励函数,用于对数据集进行奖励标注;二是利用该奖励函数,通过离线RL预训练出语言基策略。针对未见过的任务变体,ReWiND无需重新设计奖励或收集大量演示,仅使用预训练的奖励函数对预训练策略进行微调,且整个微调过程所需的在线交互极少。
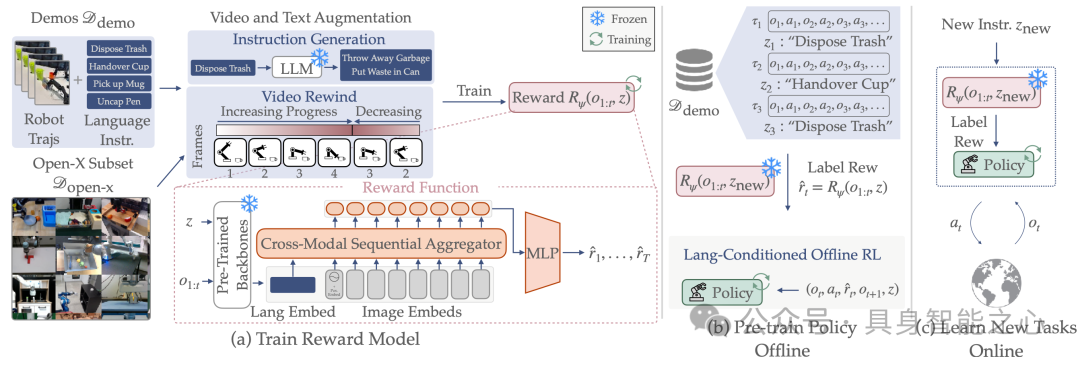
图6|ReWiND包括3个阶段:(1)从有限的目标环境演示中学习奖励函数,然后(2)在演示中使用学习到的奖励对π进行预训练,最后(3)使用奖励函数和预训练策略在线学习新的语言指定任务。
ReWiND在任务泛化与样本效率上展现出显著优势:其奖励模型对未见过任务的泛化能力突出,在奖励泛化和策略一致性指标上,表现比基准方法高出2.4倍;在新任务适应效率上,模拟环境中比基准方法快2倍,真实世界场景下更将预训练双手动策略的性能提升5倍,为实现可扩展的现实世界机器人学习提供了关键技术支撑。
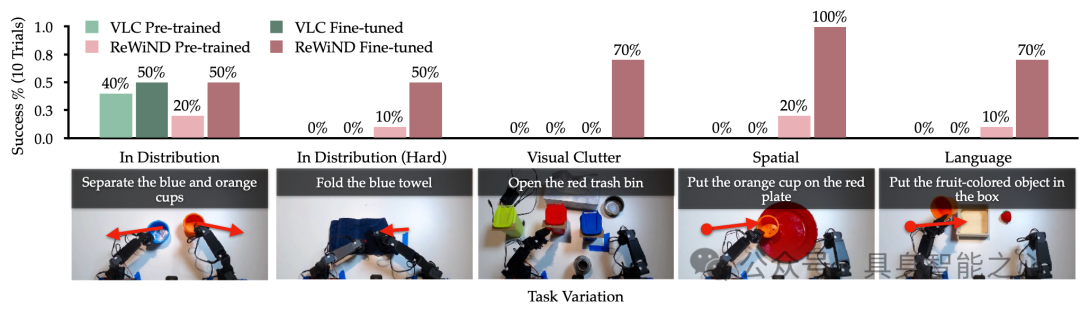
图7|真正的机器人RL。分别在分布任务和视觉、空间和语言泛化任务中展示了Koch双手臂的结果。在所有五个任务中,带ReWiND的在线强化学习将预先训练的策略提高了56%。
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy(RSS 2025)
论文链接:https://www.roboticsproceedings.org/rss21/p019.pdf
项目链接:https://cccedric.github.io/conrft/
作者单位:中国科学院,中国科学院大学人工智能学院
一句话汇总核心思路:采用 “离线(行为克隆 + Q 学习)+ 在线(一致性策略 + 人工干预)” 两阶段强化微调,解决 VLA 模型监督微调不稳定的问题,大幅提升实际操作任务成功率并缩短回合长度。
解决了哪些问题?有哪些提升?
视觉-语言-动作(VLA)模型虽在实际机器人操作中具备显著潜力,但通过监督学习微调时表现难以稳定:核心问题在于训练依赖的演示数据存在局限性,不仅数量有限,且在接触丰富的环境中易出现不一致性,导致模型无法可靠适配实际操作场景,制约了其在真实机器人任务中的应用效果。
为解决上述挑战,研究提出针对VLA模型的强化微调方法ConRFT,采用“离线+在线”两阶段训练模式,并以统一的基于一致性的训练目标贯穿始终:在离线阶段,结合行为克隆与Q学习,从少量演示数据中高效提取策略,同时稳定价值估计,为后续微调奠定基础;在在线阶段,通过一致性策略进一步微调VLA模型,且引入人工干预机制,既保障机器人探索过程的安全性,又提升样本利用效率,避免无效探索消耗。
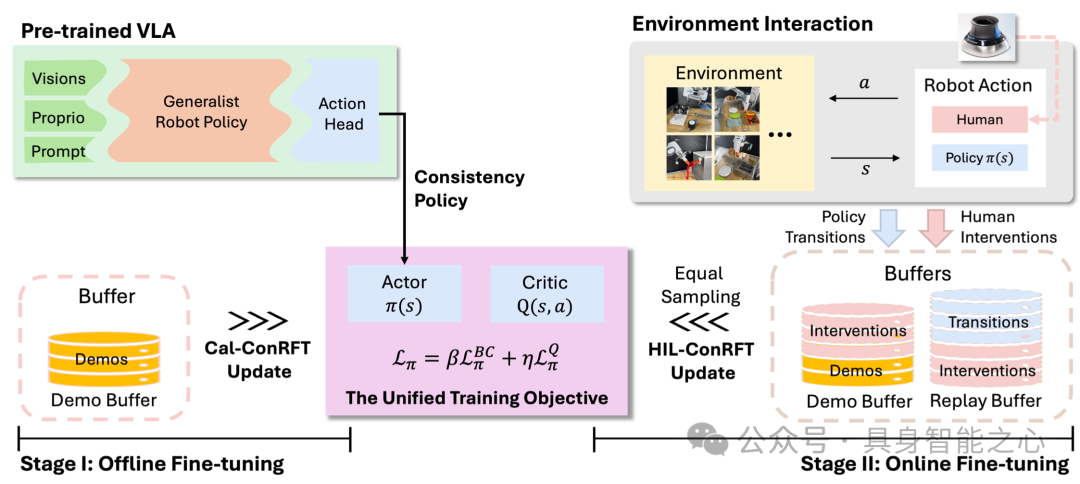
图8|模型包括两个阶段:离线Cal-ConRFT和在线hl - conrft。这两个阶段都使用统一的基于一致性的训练目标。在离线阶段,我们只使用预先收集的演示进行微调。在在线阶段,人类操作员可以通过远程操作工具(例如:SpaceMouse)。我们使用预先收集的演示、政策转换和人为干预来进行微调。
在八项实际操作任务的评估中,ConRFT展现出优异性能:仅需45至90分钟的在线微调时间,模型平均成功率便达到96.3%,较此前监督学习方法提升144%,同时单个回合长度缩短1.9倍。

图9|各种离线和在线微调方法的对比实验结果。具体来说,对于在线微调,HG-DAgger和PA-RL训练从SFT基线开始,HIL-ConRFT训练从Cal-ConRFT基线开始。性能提升是相对于相应的离线结果而言的。对于所有方法,使用相同数量的在线剧集对政策进行培训,并进行人工干预。每个任务在20次试验中报告所有指标。
该成果充分验证了将强化学习与VLA模型结合的价值,为提升VLA模型在实际机器人应用中的性能提供了有效路径。

图10|所有真实世界实验任务的概述。现实世界的任务包括挑选和放置(a)香蕉,(b)勺子,(d)和(f)面包,操作(c)抽屉和(e)烤面包机,组装复杂的物体,如(g)轮椅轮子和(h)中国结。
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning(RSS 2025)
论文链接:https://generalist-distillation.github.io/static/high_performance_generalist.pdf
项目链接:https://generalist-distillation.github.io/
作者单位:加州大学伯克利分校
一句话汇总核心思路:利用强化学习生成高质量训练数据微调机器人通用策略,解决通用策略依赖人类演示数据导致的性能与泛化不足问题,实现成功率提升与专门控制器级性能。
解决了哪些问题?有哪些提升?
当前机器人基础模型虽能开发出适应多任务的通用策略,展现出亮眼的灵活性,但存在关键瓶颈:其性能高度依赖训练数据质量,现有基于人类演示的训练数据难以支撑通用策略在复杂任务中达到更优效果,不仅在精确操作任务中的成功率受限,对新任务的泛化能力也有待提升,无法兼顾基础模型的灵活性与专门控制器的高性能。
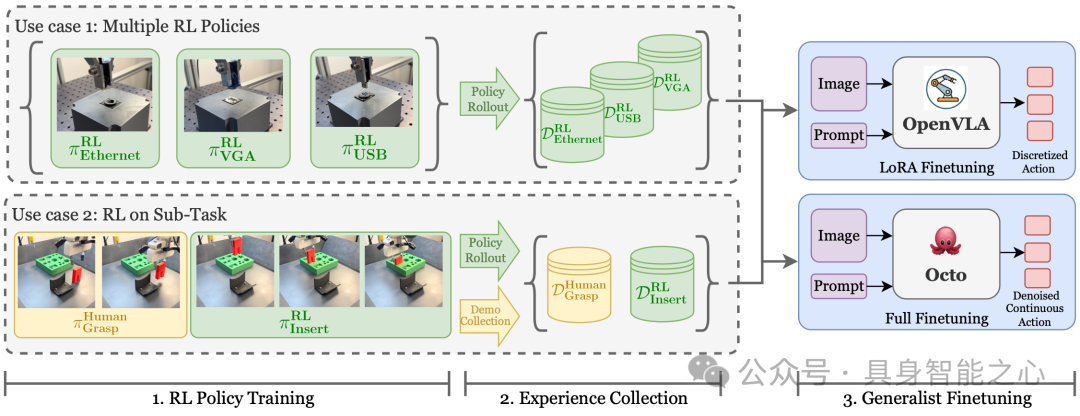
图11|RLDG通过使用专业RL策略进行培训,并使用它们生成高质量的微调数据集,从而改进了OpenVLA和Octo等通才机器人策略。它可以灵活地将针对个别狭窄任务的多个RL策略的知识提炼为单个通才。它还可以应用于长期操作任务中最关键的子任务,提高“瓶颈”的成功率,同时利用人类在任务中足够的部分进行演示.
为突破训练数据质量的限制,研究提出强化学习精简通用策略(RLDG)方法:核心思路是利用强化学习生成高质量训练数据,以此对机器人通用策略进行微调——通过强化学习的优化机制,针对性改善训练数据的动作分布与状态覆盖,避免人类演示数据的局限性,进而提升通用策略在特定任务与新任务中的表现,实现“通用策略灵活性+专门任务高性能”的结合。

图12|用于评估RLDG的任务示例。(A)精确连接器插入包括三个训练对象和四个未见的测试对象,用于评估策略泛化。Pick and Place涉及一个看不见的场景,测试政策对不同背景和物体的视觉稳健性。(C) FMB插入包括将预先抓取的物体插入移动板中,而(D) FMB组装从桌子上的物体开始,包括一个额外的抓取阶段。
在连接器插入、组装等精确操作任务的大量实际实验中,RLDG方法成效显著:基于其强化学习生成数据训练的通用策略,性能持续优于人类演示训练的策略,成功率最高提升40%,且对新任务的泛化能力更强;进一步分析表明,性能提升源于数据优化后的动作分布与改进的状态覆盖。该成果证实,任务特定强化学习与通用策略提炼的结合,为开发更高效、更具能力的机器人操作系统提供了可行路径,可在保留基础模型灵活性的同时,达到专门控制器的性能水平。
TGRPO: Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization(2025)
论文链接:https://arxiv.org/abs/2506.08440
项目链接:https://github.com/hahans/TGRPO
作者单位:吉林大学
一句话汇总核心思路:借鉴 GRPO 并融合步骤与轨迹级优势信号优化组级优势估计,解决 VLA 模型新环境微调依赖 SFT 的局限,生成更稳健高效的操作策略。
解决了哪些问题?有哪些提升?
视觉-语言-动作(VLA)模型虽经大规模数据集预训练后,在多场景、任务及机器人平台上泛化能力较强,但在新环境中需针对特定任务微调,且当前微调几乎完全依赖静态轨迹数据集的监督微调(SFT)方法。该方法存在明显缺陷:无法实现机器人与环境的交互,不能利用实时执行反馈,且性能严重受制于收集轨迹的规模与质量,难以适配动态变化的实际操作需求。
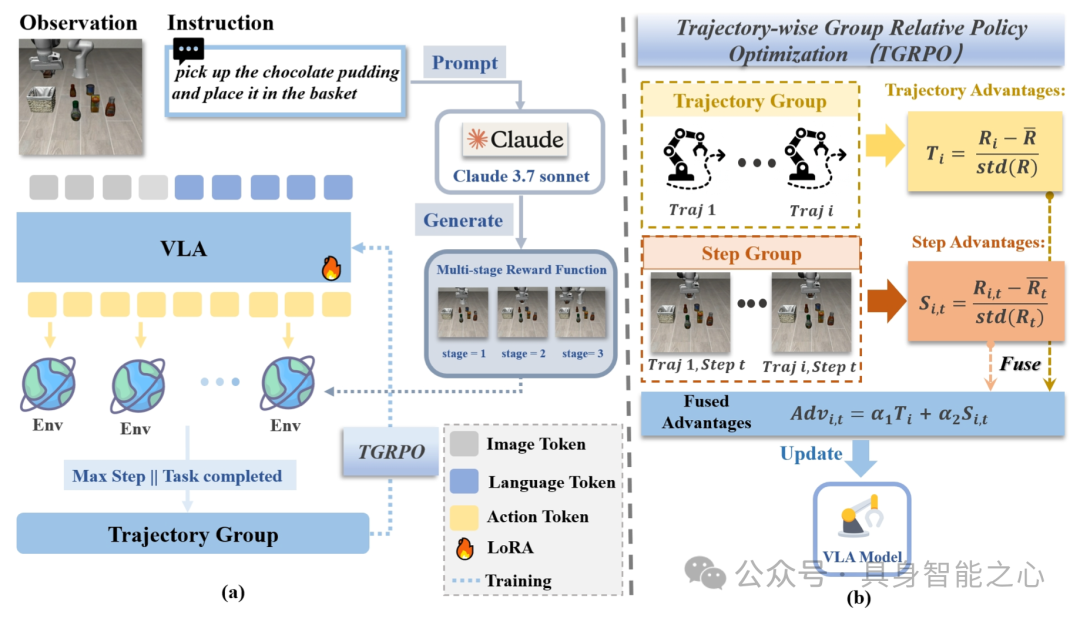
图13|TGRPO概述。(a)我们利用大型语言模型(Claude 3.7 Sonnet)根据任务描述和Libero仿真环境的代码生成多阶段奖励函数。在训练中,对于相同的任务,我们按照统一的任务指令部署多个相同的环境,不断采样动作,直到满足终止条件,从而每个环境获得一条轨迹。(b)在TGRPO中,然后将这些轨迹分组为一组,在其中我们计算轨迹级优势和阶跃级优势。将两种类型的优势融合成一个相对优势度量,用于在线强化学习训练来更新VLA。
为突破SFT方法的局限,研究借鉴GRPO理念,提出轨迹级组相对策略优化(TGRPO)方法——将强化学习(RL)引入VLA在线训练,通过闭环交互使策略直接对齐任务目标。其核心改进在于融合步骤级别与轨迹级别的优势信号,优化GRPO原有的组级优势估计,增强算法对VLA模型在线强化学习训练的适配性,从而提升策略学习的稳健性与效率。
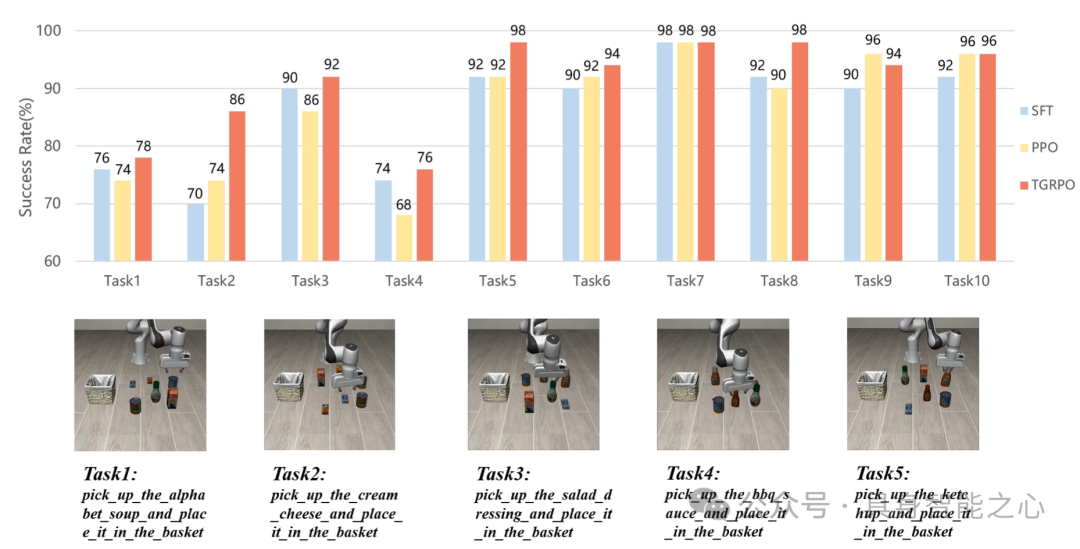
图14|将使用TGRPO训练的OpenVLA与香草SFT和PPO进行了比较,TGRPO在整体性能上优于这些方法。
在基准测试的十个操作任务中,TGRPO表现出显著优势:其性能始终优于各类基线方法,能够在多个测试场景下生成更稳健、高效的操作策略,充分验证了该方法在提升VLA模型微调效果与实际适配能力上的价值。
Improving Vision-Language-Action Model with Online Reinforcement Learning(ICRA 2025)
论文链接:https://arxiv.org/abs/2501.16664
作者单位:清华大学、加州大学伯克利分校、上海奇智研究所
一句话汇总核心思路:通过强化学习与监督学习循环迭代,解决直接用在线 RL 优化 VLA 模型的训练不稳定与计算负担问题,实现模型交互场景下的性能提升。
解决了哪些问题?有哪些提升?
近期研究通过专家机器人数据集的监督微调(SFT),成功将大型视觉语言模型(VLM)整合到低级机器人控制中,形成视觉语言动作(VLA)模型。尽管VLA模型性能强大,但仍存在未解决的关键问题:在与环境交互过程中,如何进一步优化这类大型模型缺乏有效方案。若直接将在线强化学习(RL)——这一大型模型常用的微调技术——应用于VLA模型,会面临两大挑战:一是训练过程极不稳定,严重影响模型性能;二是计算负担过重,超出多数本地机器的计算能力。
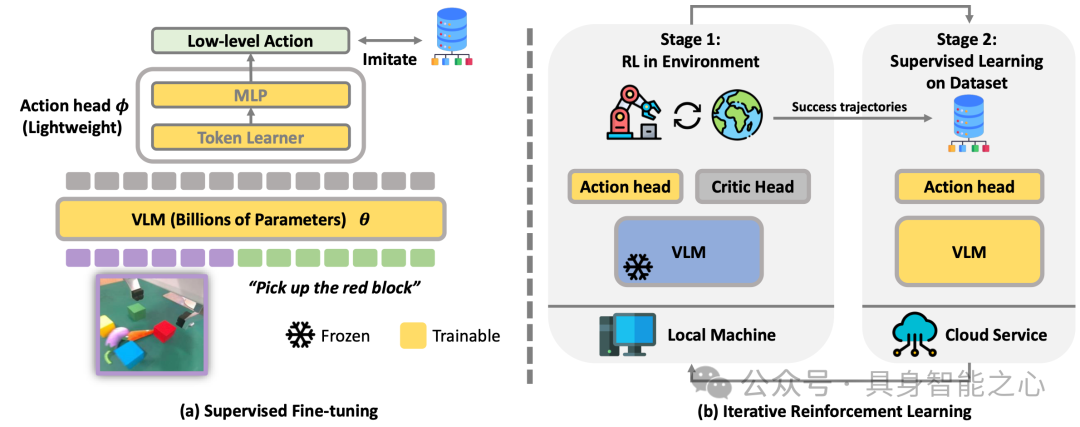
图15|(a)VLA模型包括一个预训练的VLM骨干和轻量级动作头。(b)在微调期间,通过在勘探和SL阶段之间进行迭代,以有效改进VLA模型。VLM在探索阶段被冻结,以稳定训练,在SL阶段可训练,以充分发挥预训练VLM的力量。
为应对上述挑战,研究提出iRe-VLAd框架,核心思路是通过“强化学习与监督学习循环迭代”的模式优化VLA模型:既借助强化学习的探索优势,让模型在与环境交互中挖掘改进空间,又依托监督学习的稳定性,缓解强化学习带来的训练波动问题,从而在保障训练稳定的同时,高效实现VLA模型的性能提升,且降低对硬件计算能力的过度依赖。
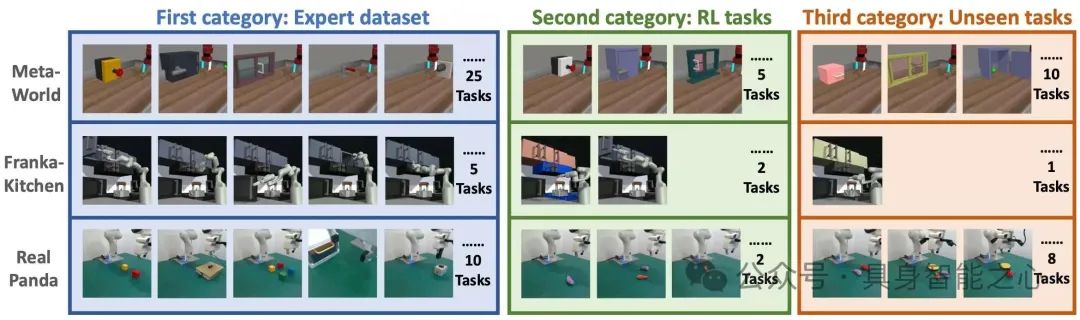
图16|验证领域包括三类:在专家数据集中观察到的任务,利用强化学习的新任务,以及未见过的任务。任务因所需的技能以及物体的形状和外观而异。每个任务中物体的初始位置在每个情节中都是随机的。
在两个模拟基准与一个真实世界操作套件的实验中,iRe-VLAd框架的有效性得到充分验证,证明其能够有效解决直接应用在线强化学习于VLA模型的痛点,为大型VLA模型在交互场景中的性能优化提供了可行路径。
Interactive Post-Training for Vision-Language-Action Models(CVPR 2025)
论文链接:https://arxiv.org/abs/2505.17016
项目链接:https://ariostgx.github.io/ript_vla/
作者单位:德克萨斯大学奥斯汀分校、南开大学
一句话汇总核心思路:基于稀疏二进制成功奖励,通过动态回放采样与留出部分优势估计的算法进行交互式后训练,解决 VLA 模型低数据环境适配难的问题,兼顾兼容性、效率与泛化性。
解决了哪些问题?有哪些提升?
现有视觉-语言-动作(VLA)模型的训练流程存在明显局限:严重依赖离线专家演示数据与监督模仿学习,导致模型在低数据环境下,难以适应新任务与新环境,无法高效应对数据稀缺场景下的性能优化需求,限制了VLA模型的实用范围与适配灵活性。
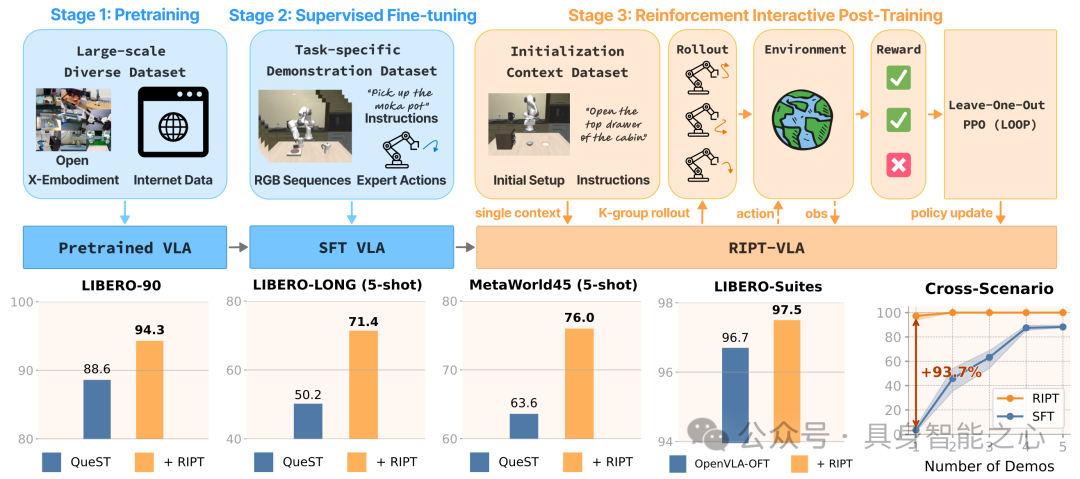
图17|RIPT-VLA概述虽然VLA模型通常使用两个监督阶段进行训练,但我们提出了第三个阶段:VLA的强化交互式后训练。他在不同的基准上设定了最先进的结果。在低数据条件下也表现出显著的改进,通过一次演示将SFT模型从接近失败转变为97%。
为突破低数据环境适配难题,研究推出RIPT-VLA——一种简单可扩展、基于强化学习的交互式后训练模式。其核心设计是仅使用稀疏二进制成功奖励,对预训练VLA模型进行微调;具体通过动态回放采样与留出部分优势估计的稳定策略优化算法,实现高效的交互式后训练,摆脱对大量离线专家数据的依赖。
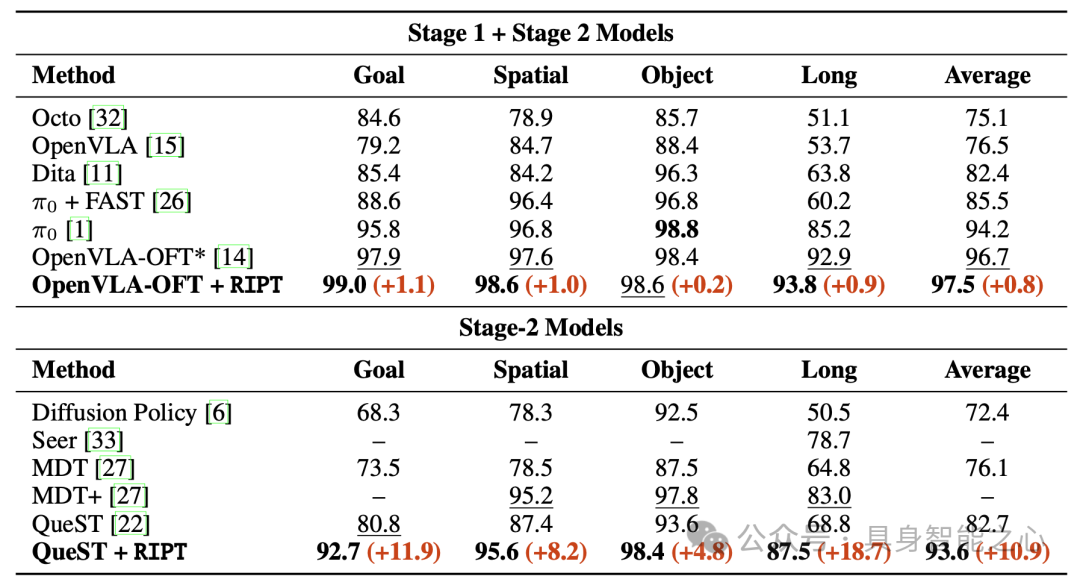
图18|四个LIBERO套件的多任务SR(%)。粗体表示最佳结果,下划线表示次优结果。本算法的改进用红色标记。*:OpenVLA-OFT结果是通过运行每个套件的官方检查点获得的。
RIPT-VLA在兼容性、效率与泛化性上均表现优异:一是适配多种VLA模型,使轻量级QueST模型成功率提升**21.2%,7B参数的OpenVLA-OFT模型成功率达97.5%的新高;二是计算与数据效率突出,仅需1次演示,即可让原本无法实现任务的SFT模型在15次迭代内达到97%**的成功率;三是策略泛化性与鲁棒性强,能在不同任务、场景中稳定发挥,且对初始状态上下文不敏感,证实其是通过最少监督优化已训练VLA模型的实用有效方案。
总结
这8篇研究堪称“机器人智能升级的风向标”,不仅技术方向高度契合,更在解决实际问题上形成强大合力:它们均以VLA模型的多模态理解能力为基石,叠加强化学习的自主优化优势,剑指机器人操控、导航中的策略泛化难、动态环境适应差、多模态信息错位等行业瓶颈;同时聚焦家居家务、工业装配、机械臂操控等高频应用场景,用扎实的实验数据验证方法有效性,部分还开放项目代码,让前沿技术不再“纸上谈兵”。
更多干货和最新内容欢迎加入我们的具身社区,一起交流。


















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









