










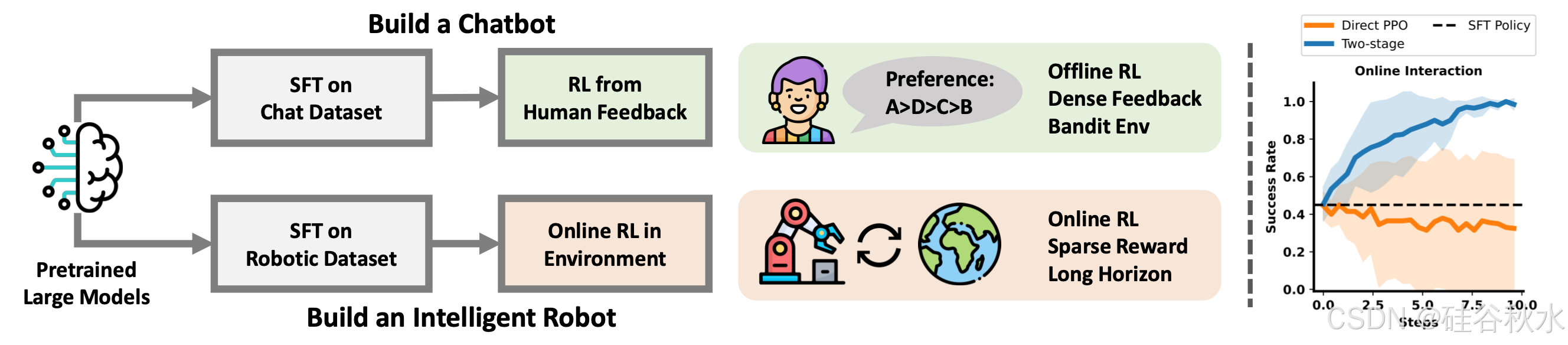
25年1月来自清华、伯克利分校和上海姚期智研究院的论文“mproving Vision-Language-Action Model with Online Reinforcement Learning”。
最近的研究已成功地将大型视觉-语言模型 (VLM) 通过使用专家机器人数据集进行监督微调 (SFT) 集成到低级机器人控制中,从而产生视觉-语言-动作 (VLA) 模型。虽然 VLA 模型功能强大,但如何在与环境交互的过程中改进这些大型模型仍是一个悬而未决的问题。本文探讨如何通过强化学习 (RL) 进一步改进这些 VLA 模型,强化学习是一种常用的大型模型微调技术。然而,直接将在线 RL 应用于大型 VLA 模型存在重大挑战,包括严重影响大型模型性能的训练不稳定性,以及超出大多数本地机器能力的计算负担。为了应对这些挑战, iRe-VLA 框架在强化学习和监督学习之间进行迭代,有效改进 VLA 模型,利用 RL 的探索性优势,同时保持监督学习的稳定性。
VLA 模型的微调通常采用SFT,该方法的优点是稳定性和可规模化。但是,SFT 以来高质量的专家数据集,而这些数据集在机器人领域成本高昂且难以获取。由于分布漂移,监督学习无法完全使 VLA 模型与物理环境对齐。受 RLHF 的启发,尝试使用在线 RL 改进 VLA 模型,使其与物理环境更好地对齐。机器人需要在线探索具有长范围任务和稀疏奖励的任务。之前的研究表明,在线 RL 应用于大型神经网络时训练极其不稳定,并且性能会下降,如图(动机直观图)右侧所示。
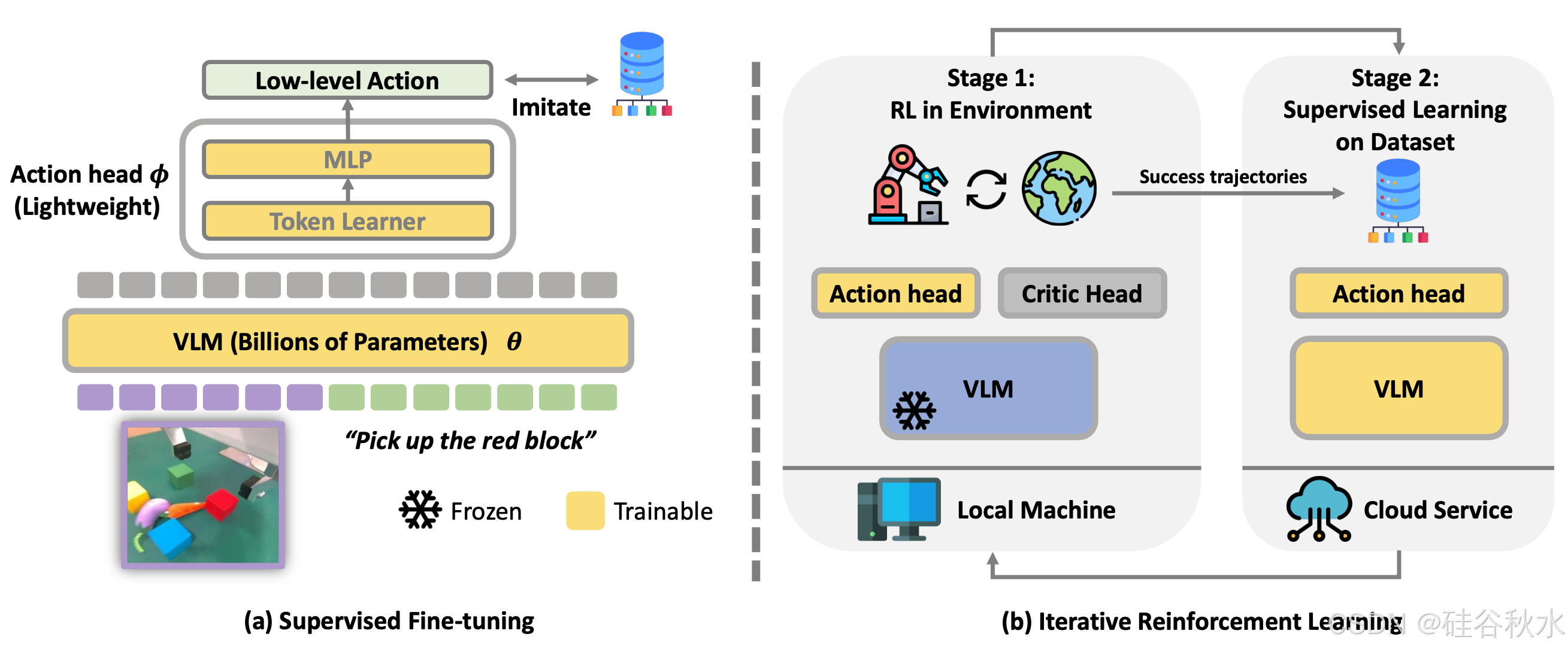
为了稳定 RL 过程并有效增强 VLA 模型,iRe-VLA 方法,在在线 RL 阶段和 SFT 阶段之间 迭代。在 RL 阶段,冻结VLM参数,只训练轻量级的动作头以保持训练稳定性。在随后的 SFT 阶段,对成功的轨迹进行全参微调,以充分利用大型模型的表达能力。根据经验,这种两阶段方法提高 VLA 的性能,稳定训练,并且计算效率更高。
如图所示模型架构:
利用标准的深度 RL 部分观察马尔可夫决策过程 (POMDP) 框架,其中任务可以建模为 M = (S, A, P/T, R, γ, O, P/E)。S 和 A 是任务的状态空间和动作空间,O 是机器人观察,例如视觉图像。P/T : S × A × S → [0, 1] 是状态转换概率函数,R : S × A × S → R 是任务的奖励函数。在机器人任务中,奖励信号总是稀疏的,因此考虑二元奖励,其中如果机器人成功完成任务,则 R = 1,否则 R = 0。P/E : S × O → [0,1] 是观察发射概率。策略 π/θ : O → A 定义由 θ 参数化的动作空间概率分布。参数 θ 的目标是最大化策略 π/θ 的预期回报,其中折扣 γ:
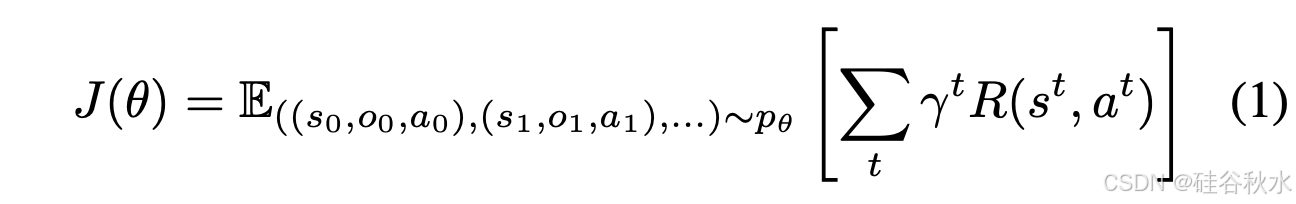
VLA 模型将视觉输入 o 和自由形式语言指令 i 转换为低级机器人动作 a,表示为 O × L → A。该模型包含一个预训练的大型 VLM 和一个轻量级动作头,如图左侧所示。
使用BLIP-2 3B模型作为主干VLM。 由于预训练的VLM在语言空间中输出文本token,因此设计一个动作头来产生低级的控制动作。 这些动作通常包括末端执行器姿态和夹爪状态的变化。 遵循[11, 34]中提出的设计,将VLM的全连接层替换为一个初始化的动作头。
遵循[47]中描述的方法,利用 LoRA 微调 VLM。 可训练参数总数包括 LoRA 参数 θ 和动作头参数ϕ。
训练中,首先对VLA模型进行基于机器人数据集的监督微调(阶段 0),然后迭代进行在线RL(阶段 1)和监督学习(阶段 2)。
阶段 0: 基于专家数据集的监督学习
首先使用专家机器人数据集 D/e={(o/1,l1/,a/1),(o/2,l/2,a/2),…,(o/i,l/i,a/i)} 对 VLA 模型 π/θ 进行标准的监督微调。损失函数为 MSE:
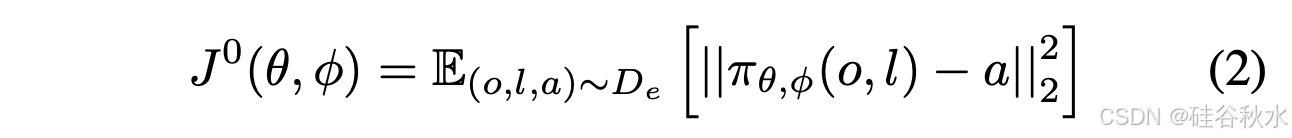
经过监督微调,得到初始的 VLA 模型 π0/θ,φ。π0/θ,φ 的性能与专家数据集 D/e 的规模和质量高度相关。然后开始在线 RL 来改进 π^0/θ,φ。
阶段 1: 使用冻结 VLM 的在线 RL
引入一个与动作头结构相同的批评头,但输出维度设置为1。 为了防止模型崩溃并加速学习过程,在这一阶段冻结 VLM 参数 θ。 因此,只有动作头的参数ϕ被优化:
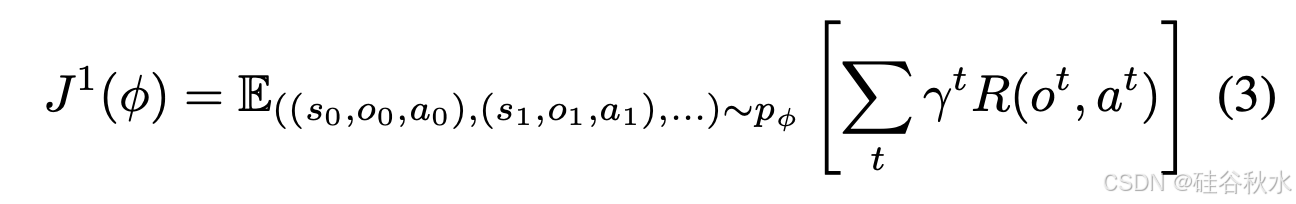
在线 RL 后,机器人可能会发现新的轨迹 x/i 来解决新任务。然后将这些成功的轨迹收集到一个在线数据集 D/RL = D/RL ∪ x/i 中。
阶段 2: 基于专家数据和在线收集数据的监督学习
第一阶段,当智体对新任务进行RL时,它有可能会忘记先前学习的任务。 因此,在第二阶段,使用新收集的在线数据D/RL和原始专家数据集D/e来监督整个模型,以减轻灾难性遗忘[49]。 目标可以写成:
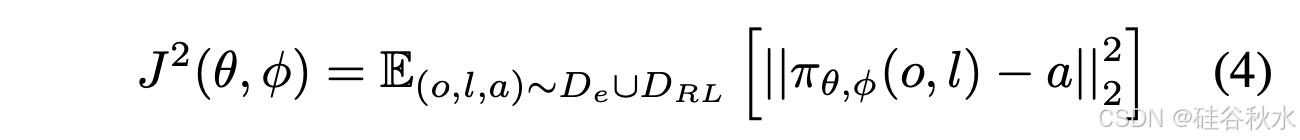
迭代阶段 1 和阶段 2
阶段 1 中的智体探索新任务的新解决方案,而在阶段 2 中,它模仿所有可用的成功轨迹。 通过在阶段 1 和阶段 2 之间交替,大型 VLA 模型逐渐解决更广泛的任务,同时也能防止在已知任务上发生灾难性遗忘。整个流程在如下算法概述。

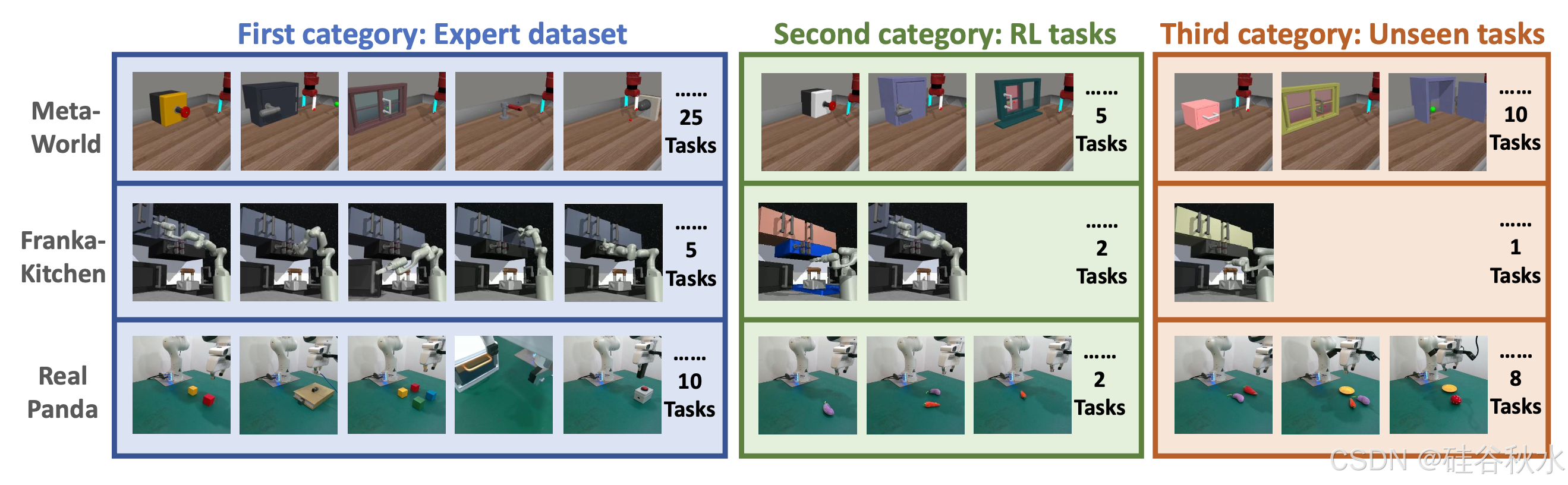
在两个模拟基准 Metaworld 和 FrankaKitchen 以及现实世界的 Panda 操作任务中进行实验,以验证 iRe-VLA 框架的有效性。
实验设置如下。
使用单个文本条件 VLA 模型来解决一个域中的所有任务。每个域都涉及分为三组的任务(如图所示):演示数据集观察的专家任务、通过在线 RL 增强的 RL 训练任务、以及在先前训练中未见过的保留任务。
实世界实验遵循 SERL 中描述的设置,如图所示,这是一个用于真实世界RL的有用软件套件。首先在一个包含 2000 条人类收集的专家数据(涵盖各种任务类别,包括 抓取、放置、按下按钮、电缆布线和打开抽屉的集合上训练一个 VLA模型。
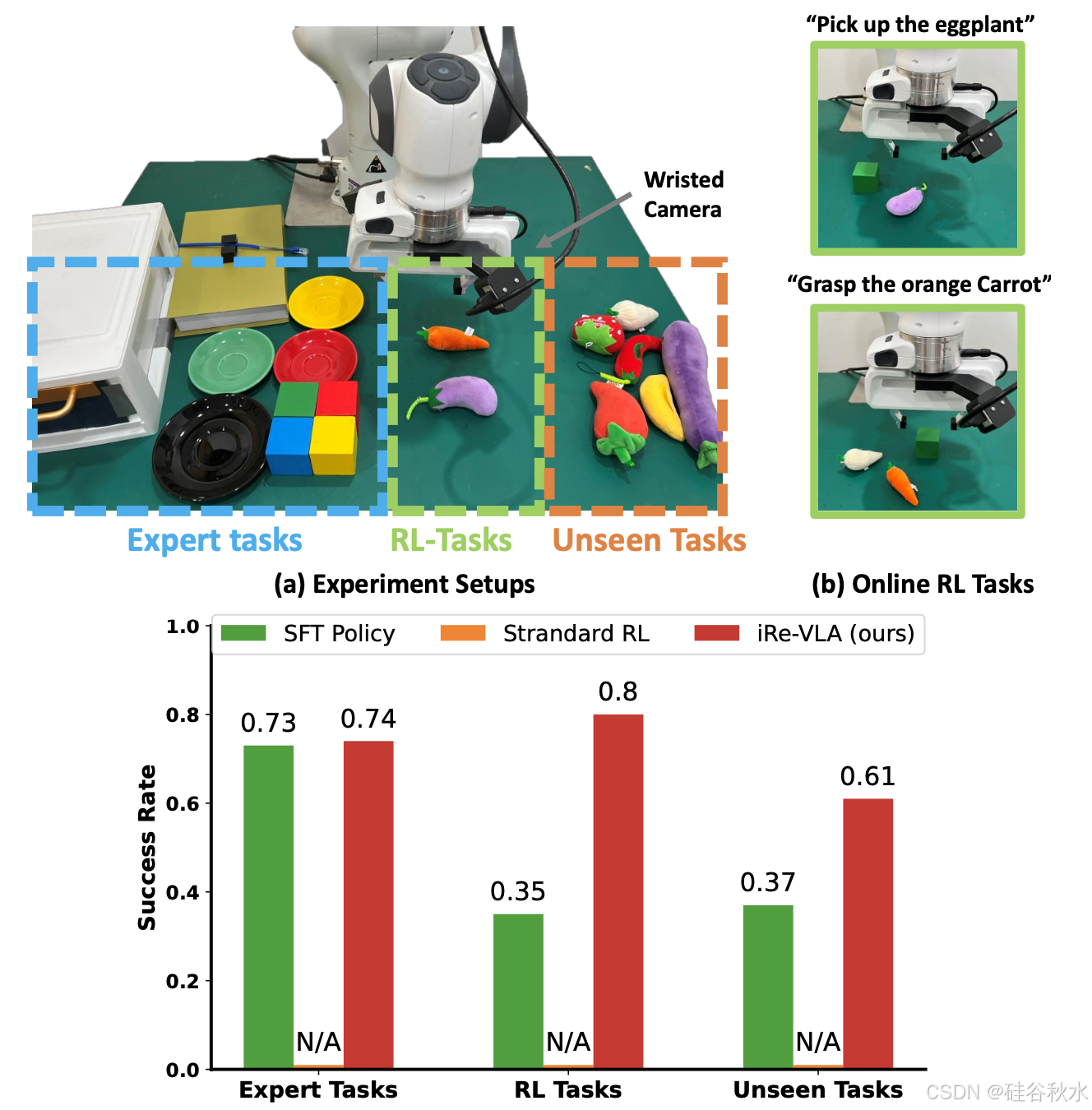
由于VLA模型的泛化能力,学习的VLA模型在未见过目标上显示出确定的成功率。然后采用在线 RL 来进一步提高在未见过目标上的成功率。在 VLA 模型的背景下,实施了一些关键的设计选择,以提高样本效率并确保计算的可负担性。为了提高样本效率,采用 SACfD 算法。具体来说,当引入一项新任务时,最初利用零样本迁移的VLA模型来收集一个包含 20 条成功轨迹的演示缓冲区。在训练过程中,从演示缓冲区和在线缓冲区分别采样50%的转移,如[52]中所述。为了控制计算成本,每个图像观察只由VLM处理一次,并将生成的潜在输出存储在缓冲区中。随后,在该潜在空间中实现 SACfD 算法。

















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









