






1. Abstract
患者和医生对诊断和治疗干预作出必要的决定。这些行动应在时间限制和不确定的情况下进行或推迟,因为患者的诊断和对治疗的预测反应。这可能会导致认知和判断错误。强化学习是机器学习的一个子领域,它识别一系列动作以增加实现预定目标的概率。强化学习通过在预定义的时间间隔内推荐行动,以及在决策过程中利用复杂输入数据(包括文本、图像和时间数据)的能力,有可能帮助外科手术决策。该算法模仿人类的试错学习过程来计算最佳推荐策略。本文提供了关于强化学习在医学领域的发展和应用所面临的挑战的见解,重点是手术决策。这篇综述的重点是在制定奖励功能方面的挑战,奖励功能描述了电子健康记录的最终目标和患者状态的确定,以及缺乏资源来模拟手术期间和手术后生理状态变化所建议的行动的潜在益处。尽管临床实施需要安全、可互操作、直播的电子健康记录数据供虚拟模型使用,但在手术中开发和验证个性化强化学习模型可以帮助患者和临床医生做出更好的决策,从而有助于改善护理。
2. Introduction
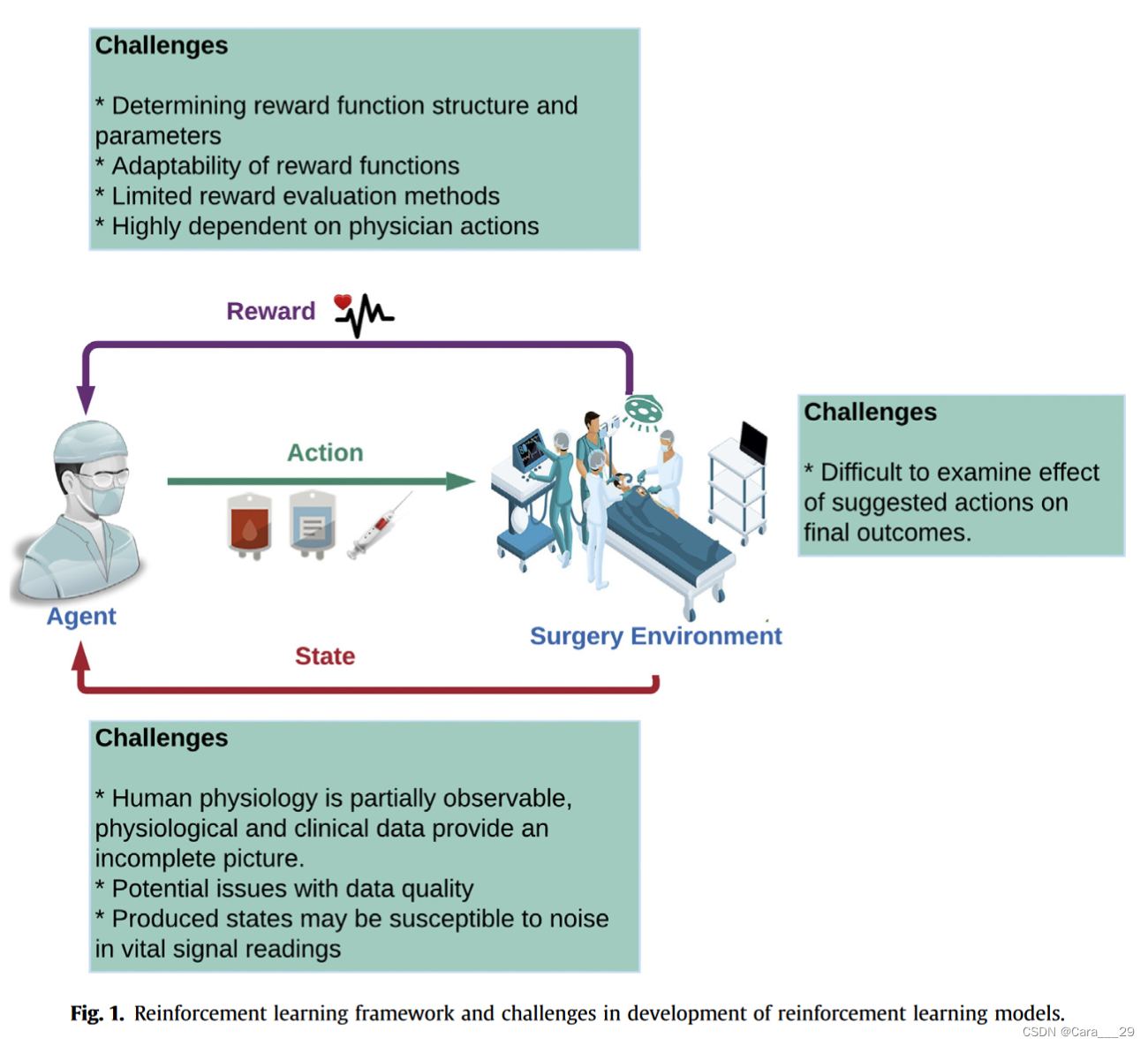
患者和医生对诊断和治疗干预作出必要的决定。这些行动应在时间限制和不确定的情况下进行或推迟,因为患者的诊断和对治疗的预测反应。这可能会导致认知和判断错误。患者的诊断和预测治疗反应的不确定性可能导致认知和判断错误。强化学习是机器学习的一个子领域,它识别一系列动作以增加实现预定目标的概率。强化学习有帮助手术决策的潜力。试错学习方法建议在预定义的时间间隔内采取具体的行动,并在决策过程中利用复杂的输入数据,包括文本、图像和时间数据这篇综述试图描述强化学习在医疗保健,特别是外科领域的发展和应用中的挑战(图1),因为应用本身已经由Yu等人,lottus等人,1和liu等人进行了总结。
3. Reinforcement Learning
强化学习(RL)是机器学习(ML)的一个子领域,它识别一系列动作以增加实现预定目标的概率。它是一种在各种卫生保健领域开发强大解决方案的技术,其中诊断决策或治疗方案通常以连续的决策程序为特征强化学习问题是通过模拟人类学习行为的试错学习过程来解决的。RL代理(算法建议行动的一部分)与环境(从电子健康记录中观察到的患者/手术会话)相互作用,以最大化其行动产生的累积奖励。一般来说,强化学习问题的建模和解决使用马尔可夫决策过程(MDP),以Bellman序列为指导有4个组成部分:(1)表示每个时间步长的环境的状态;(2) agent在每个时间步采取的影响下一个状态的动作;(3)过渡概率,它提供了达到不同后续状态的估计,反映了智能体相互作用的环境;(4)奖励函数,即给定状态-动作对的观察反馈(图1)。
Applications of reinforcement learning in health care
最近,强化学习方法正在医疗保健领域进行研究,以产生最佳政策,以建议干预措施和建议行动,以消除人为水平的偏见和错误。它有能力模仿类似人类的学习方法,可以使用电子健康记录来制定治疗政策、干预建议系统和行动建议系统,并且它有可能通过帮助临床医生做出更好的决定来改善护理。最近的强化学习算法的鲁棒性有助于开发的系统适应患者身体状态的突然变化。Yu等人讨论了RL技术在医疗保健领域的广泛应用。其中一个主要应用是动态治疗方案,它为需要长期护理的个体患者提供连续的临床决策(例如,药物剂量、干预时间或治疗类型)。Komorowski等人5使用48个变量来描述患者状态,包括人口统计学、合并症、生命体征和实验室值。他们每隔4小时汇总每位患者的数据,将每个描述聚类到750个离散的、互斥的组中以创建状态空间,并应用策略迭代RL算法来学习静脉输液和血管加压药物的最佳给药策略,以最大限度地提高90天的生存概率。Prasad等6每10分钟提取一次呼吸机支持患者的记录,并应用基于rl的拟合q -迭代(FQI)方法优化机械通气(MV)和镇静脱机时间。另一个主要应用是医疗诊断的自动化,其中诊断是通过连续的决策过程制定的。Ling等人7提出了一种新的临床诊断推理方法,该方法应用深度q学习(DQN)学习最优策略,通过从外部资源(维基百科和梅奥诊所)中迭代搜索候选诊断来获得最终诊断。其他应用包括卫生资源调度和分配、最优过程控制、药物发现和开发等(表1)。
4. Knowledge Gaps
Challenges in reward formulation
这一部分中,绿色代表大致方法,蓝色代表论文结果。
正如yuetal所详细描述的,2强化学习的奖励函数的形成是在医疗保健中应用这种模型最具挑战性的方面之一,特别是在术中应用。奖励函数用于生成在给定时间点t在状态St采取行动以过渡到状态t1的奖励分数Rtþ1。制定奖励函数需要全面理解短期和长期目标,以及如何定义状态和环境。大多数强化学习算法都是在游戏或机器人环境中进行测试和评估的,因为这些信息很容易获得。然而,在医疗保健应用中,奖励函数必须通过属性值来生成,这些值表明来自生命体征、临床记录、临床图像、实验室数据、人口统计和社会经济信息的状态变化的受益或损害程度。
例如,Komorowski等人5训练了一种针对ICU患者败血症的液体和血管加压剂给药算法,该算法完全基于最小化90天死亡率的概率,而忽略了任何短期健康指标,如血压或容积状况。尽管病人死亡率随着医生和代理人的行为变得更加不同而增加,但在如此高死亡率的环境中,完全基于死亡的奖励功能是否有效尚不清楚。平均而言,该算法建议使用更高剂量的血管加压剂和静脉输液。此外,当医生和模型建议相匹配时,死亡率最低。
一些思考:
绝大部分容易导致病人死亡的操作医生都基于以往的学习和经验规避了,但是对于RL agent来说这只是未探索过的部分。
Dai等人11开发了一种更复杂的状态表示和奖励政策制定方法,他们使用多个深度神经网络创建了一个9维状态表示,并基于h*和h之间的平方距离创建了一个奖励函数,其中h是目标健康状态,h*是使用深度神经网络设计的模拟的结果状态。尽管这种方法有望创建更一般化的状态定义和奖励函数,但作者报告了有限的模型优化,导致不可靠的治疗建议。
Yu等人使用演员评论方法开发了一种监督版本的强化学习。行动者-评论家方法使用行动者提出最佳行动(政策优化),评论家评估行动质量(计算建议行动的质量)他们的目的是训练一种算法来识别ICU患者何时需要MV,并推荐异丙酚的最佳剂量,以保持患者在MV时稳定镇静。他们使用13个生命体征以及年龄和体重来定义状态,并且只使用生命体征稳定性的短期变化作为奖励功能的基础。
为了更好地定义强化学习问题中短期奖励函数公式的最佳实践,Prasad等人研究了针对给定背景更好地定制奖励权重的策略。他们报告了更大的有效样本量(由于他们的方法,与其他技术相比,需要更少的数据来收敛)在他们优化的奖励函数方法应用后;然而,对于如何通过这种策略提高RL的整体表现,我们还缺乏相关知识。值得注意的是,他们的方法高度依赖于医生在培训中使用的行动的“正确性”水平。
具体针对什么给定背景呢?
Challenges in patient state determination
构建外科强化学习系统的第一步是定义状态,其中每个状态都是对患者生理状态的完整描述。收集和总结每个患者州代表的相关健康信息至关重要。这些汇总的信息应该被组织或预处理成一个简洁和可管理的形式,以有效和高效地训练学习代理。
目前的大部分工作利用的医疗数据可能包括患者的静态特征(例如,年龄、性别、种族、合并症等人口统计数据)、纵向测量(例如,生命体征、实验室值、生理、病理)、3和/或医学图像11。这些原始数据随后被转换为统一的高维矢量,作为最终状态表示。使用预定义的离散化方法或可训练的方法,包括但不限于线性模型和深度神经网络。例如,Komorowski等人5将48个变量的数千种组合合并为750种离散的互斥状态。
与电子健康记录相关的数据质量、不一致、噪声和缺失使这一过程变得混乱。尽管已经提出了许多方法来解决这些问题,但考虑到潜在的噪声和偏差对患者状态的形成的影响,目前尚不清楚当前状态形成方法对这些问题的鲁棒性。这样的理解对于在手术中建立一个成功的强化学习系统至关重要。
更重要的是,目前的大部分工作使用MDP来模拟患者的状态和轨迹。在目前的医学实践中,病人的生理状态是用容易测量或观察到的特性如血压来近似的;然而,决定这些属性价值的潜在生理学是无法观察到的。因此,部分可观察的MDP (POMDP)方法可能更优越,因为理论上它可以利用未观察到的关系来确定患者的状态。
Challenges in modeling physiological response to agent actions
人体生理的复杂性使得训练和实施用于手术决策的强化学习算法非常困难,有许多不可观察的变量经常被忽略。人体对刺激作出反应的动态机制仍未完全了解,因此很难建立模型,因为这种反应通常具有对身体不同部位有不同影响的系统成分。
Technology gaps
当前医疗保健中的ML实现主要基于集中式模型,其中数据被聚合并存储在中心环境中,然后用于训练和实现所选的ML算法。尽管在基础设施方面进行了大量投资,但由于同时处理数百或数千名患者的流临床数据的带宽限制,这种方法仍然远远不能提供真正的实时执行。除了技术成本和限制之外,由于受保护的健康信息的不断传输和聚合,还存在隐私和安全问题。另一种方法是设备ML,由于其对隐私的优先关注而获得了极大的关注。设备ML具有许多优点,包括减少网络拥塞、减少执行时间和更好地保护受保护的健康信息。通过一种称为联邦学习的技术,设备上的机器学习得到了进一步的加强,该技术于2016年由谷歌首次提出,15允许设备上的机器学习算法在不共享和聚合底层数据的情况下共享和聚合知识。
Future directions
奖励功能设计的详细研究对于在给定环境中正确引导agent走向预期结果至关重要。该算法模仿了人类的试错学习方法,这是开发人工决策算法的一个重要特征。该算法的目标是改善临床决策过程。许多致力于解决这个问题的工作的一个根本缺陷是,假设医生是衡量代理人行为正确性的黄金标准。验证医生行为“正确性”的一种方法是从医生治疗的患者池中随机取样状态和基于这些状态所采取的行动。在这些情况下,医生的行动将与主题专家小组提出的行动进行比较。尽管这种方法在某些方面可能优于依赖单个医生来决定最“正确”的行动,但它仍然无法解决机器仍然无法捉摸的医学方面的问题,例如医生对病人的印象和医学艺术本身。16 .患者在性格和生理上都是高度个性化的,这消除了临床决策的一刀切方法的概念,这需要为每位患者定制动态方法考虑到手术决策的复杂性、高风险和不确定性,合作的决策方法通常是必要的,所有利益相关者(医生、其他医疗团队成员、患者和患者家属)可以共同设计一个计划,提高患者的满意度,并可能减少与不希望的治疗相关的成本未来在外科环境中实施的强化学习应该包含动态奖励功能,以接受来自患者和围手术期护理团队所有成员的输入。这种协同奖励功能可以平衡个体患者和外科医生的风险厌恶与其他团队成员强调的预期收益和术后护理轨迹。通过让患者更多地控制自己的算法影响的临床护理,协作和动态奖励功能有可能提高患者的整体满意度。在医疗保健和外科手术中适当使用强化学习可以通过帮助患者和临床医生做出更好的决定并取得更好的结果来改善护理。














 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









