










神经网络 = 人工神经网络(Artificial Neural Network)
M-P模型(McCulloch-Pitts神经元模型)的三个功能:
1、 能接受n个M-P模型传递过来的信号
2、 能够在信号的传递过程中为信号分配权重
3、 能过将得到的信号进行汇总、变换并输出
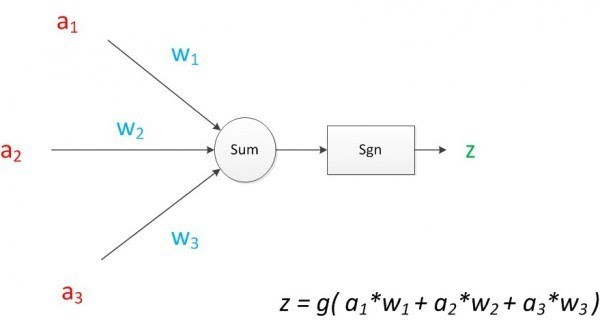
神经元模型如图所示
把N个M-P神经元按照一定的层次结构连接即可形成神经网络,形成神经元组成的有向无环图(DAG图)。
目前主流的神经网络模型结构基本都是一类及其特殊的DAG图
主流的人工神经网络模型是以层(Layer)为基本单位:
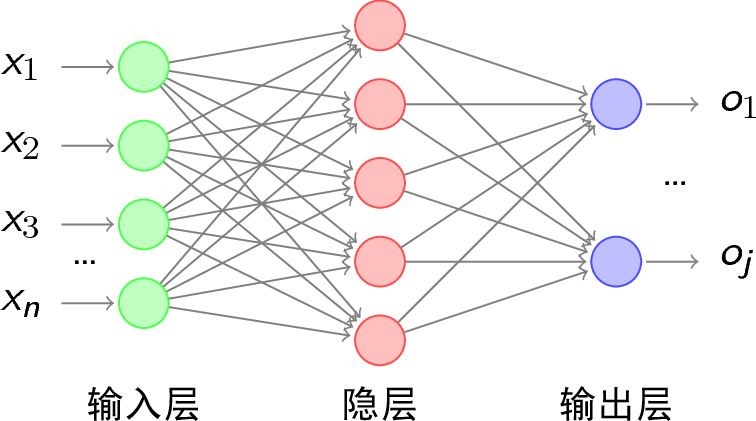
每层都是由若干个M-P神经元排列组成的神经层,整张神经网络即为由若干个神经层堆叠而成的一个结构。
同一层中的所有M-P神经元会共享激活函数和偏置量,所以会针对层的结构定义激活函数和偏置量,而不是针对神经元定义。
主流的人工神经网络结构其实可以称为多层感知机模型(Multi-Layer Perceptron,MLP)
MLP模型的工作原理:
输入层和输出层即为整个模型的出口和入口
隐藏层则会把上一层的输出当成输出,经过内部处理后把输出转给下一层
神经网络算法三个部分:
1、通过将输入进行一层一层的变换来得到输出
2、通过输出与真实值的比较得到损失函数的梯度
3、利用得到的这个梯度来更新模型的各个参数
损失函数(Loss Function):
后面有介绍
前向传播算法:
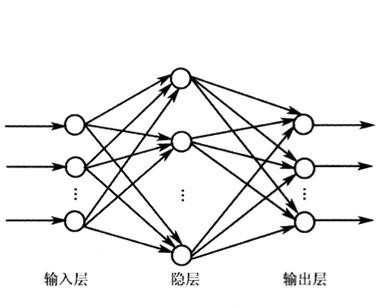
数据流是向输出的方向走的,其中没有环路。
神经网络通过前向传播算法获取各层的激活值,通过输出层的激活值和损失函数来做决策并获得得失,通过反向传播算法算出各个层的局部梯度,并用各种优化器更新参数。
对于神经网络而言,梯度下降是训练的全部。
激活函数(Activation Function):
激活函数是模型整个结构中的非线性扭曲力
神经网络的每层都会有一个激活函数
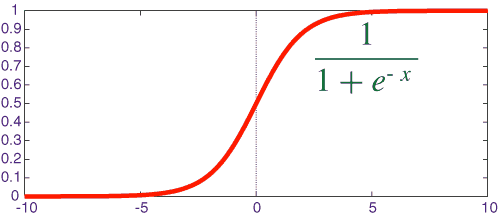
1、逻辑函数(Sigmoid):
使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。
其自身的缺陷,最明显的就是饱和性。从函数图可以看到,其两侧导数逐渐趋近于0,杀死梯度。
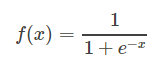
函数图像:
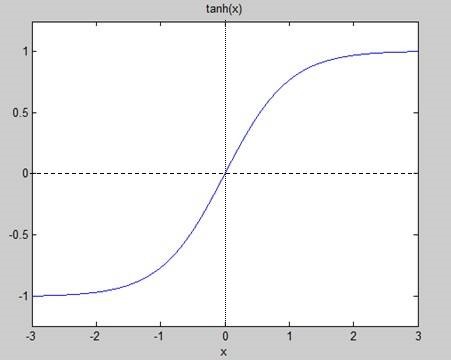
2、正切函数(Tanh):
非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。
相对于sigmoid的好处是他的输出的均值为0,克服了第二点缺点。但是当饱和的时候还是会杀死梯度。
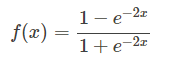
函数图:
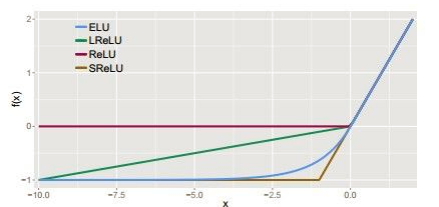
3、线性整流函数(Rectified Linear Unit,ReLU):
最近几年比较受欢迎的一个激活函数
无饱和区,收敛快、计算简单、有时候会比较脆弱,如果变量的更新太快,还没有找到最佳值,就进入小于零的分段就会使得梯度变为0,无法更新直接死掉了。
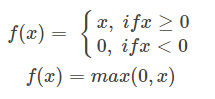
函数图:
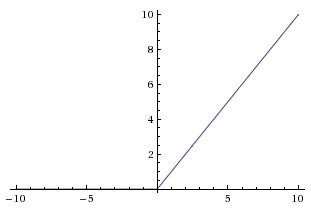
4、ELU函数(Exponential Linear Unit):
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。
因为函数指数项所以计算难度会增加
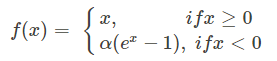
函数图:
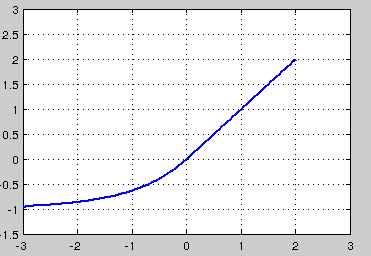
5、Softplus函数:
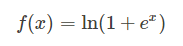
函数图:
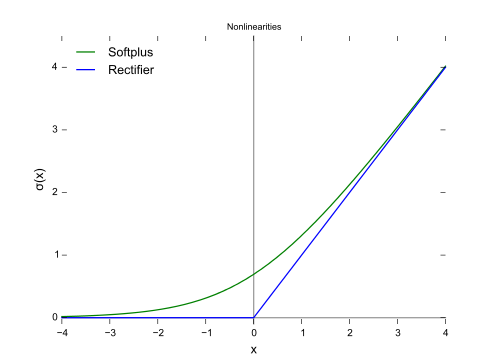
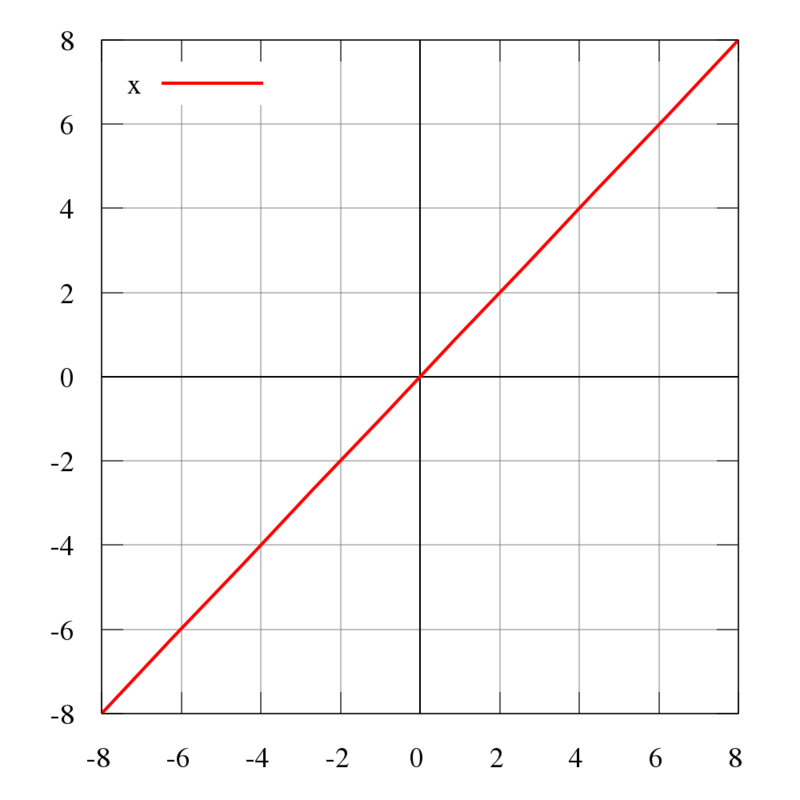
6、恒同映射(Identity):
7、Maxout:
他是ReLU和LReLU的一般化公式(如ReLU就是将w1和b1取为0)。所以他用于ReUL的优点而且没有死区,但是它的参数数量却增加了一倍。
maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
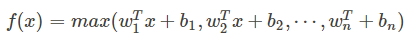
8、其他几种激活函数的比较如图:
神经网络之所以为非线性模型的关键,关键在于激活函数。
神经网络通过权值矩阵w和偏置量b来连接相邻两层
权限矩阵w和偏置量b,w比b重要:
w能从激活函数得到的函数值(激活值)映射到另一个维度的空间上
b能在此基础上再进一步平移的操作,打破对称性。
损失函数(Loss Function):
损失函数是一种衡量损失和错误程度的函数,他是模型对数据拟合程度的反映。
拟合得越差,损失函数的值就应该越大。
结合梯度下降法,当损失函数在函数值比较大时,它对应的梯度也要比较大。
损失函数(loss function) = 误差部分(lossterm) + 正则化部分(regularization term)
1、距离损失函数:
神经网络欧式距离损失函数用于连续值训练样本的拟合
该损失函数对应着最小平方误差准则
模型预测和真值的欧氏距离越大,损失越大,反之。
2、交叉熵损失函数:
交叉熵(Cross Entropy),其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小
3、Log-Likeligood损失函数:
模型预测的真值对应的类的概率的负对数。
反向传播算法(Back propagation,BP):
和前向传播算法方向相反,目的是利用梯度来更新结构中的参数以使得损失函数最小化。
用来训练人工神经网络的最常用且最有效的算法。
主要思想:
1、将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
2、由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
3、在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
BP算法首先得到损失函数的梯度
BP算法其次使用梯度更新局部的参数
图解:
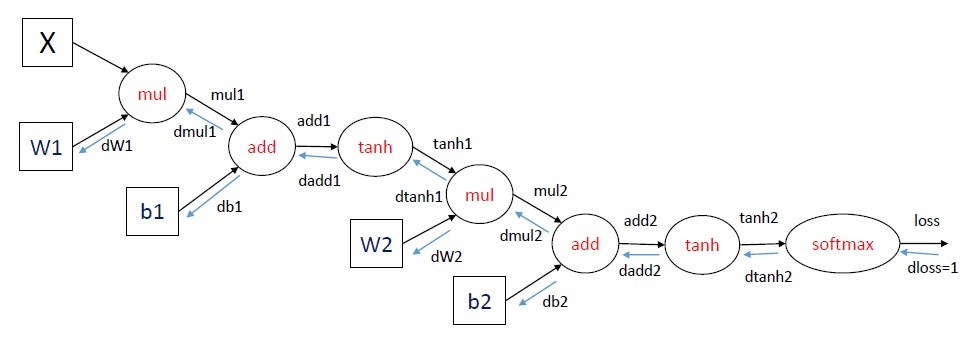
损失函数的选择:
常用结合
1、 Sigmoid系以外的激活函数 + 距离损失函数
2、 Sigmoid + Cross Entropy:解决梯度消失问题
3、 Softmax + Cross Entropy / log-likelihood
特殊的层结构:
附加层(SubLayer):该层不会独立存在,会依附在某个层之后,以实现某种特定的功能。
CostLayer:
CostLayer是一个比较特殊的SubLayer,它附加在输出层的后面,能根据输出进行相应的变换并得到模型的损失。也就是根据输出得到损失。
思想:
为了在Layer的输出的基础上进行一些变换以得到更好的输出,优化Layer的输出。
SubLayer的行为:
在前向传播中,根据自身属性和算法来优化从父层处得到的更新
在反向传播中:
1、 SubLayer之间的关联以及SubLayer和Root Layer之间的关联不会被更新,仅仅作为占位符。
2、 作为局部优化器
3、 Layer之间关联的更新是通过Leaf Layer完成的
参数的更新:
优化器的框架的三个方法:
1、 接收欲更新的参数,并进行相对应处理的方法
2、 利用梯度和自身属性来更新参数的方法
3、 完成参数更新后,更新自身属性的方法
1)、Vanilla Update:
相当于最普通的梯度下降法,通常以小批量梯度下降法形式出现。
2)、Momentum Update:
通过尝试模拟物体运动的惯性以期望增加算法收敛速度和稳定性
3)、Nesterov Momentum Update:
基于Momentum Update方法。
核心思想:
让算法有前瞻性,利用下一步的梯度,而不是这一步的梯度来合成最终的更新步伐、
4)、RMSProp:
与Momentum Update系的方法的根本不同在于:
Momentum系算法通过搜索更优的更新方向来进行优化,而该算法通过实时调整学习速率来进行优化。
5)、Adam:
应用最广泛的算法,效果最好的算法,高效,稳定,适用于大多数场景。
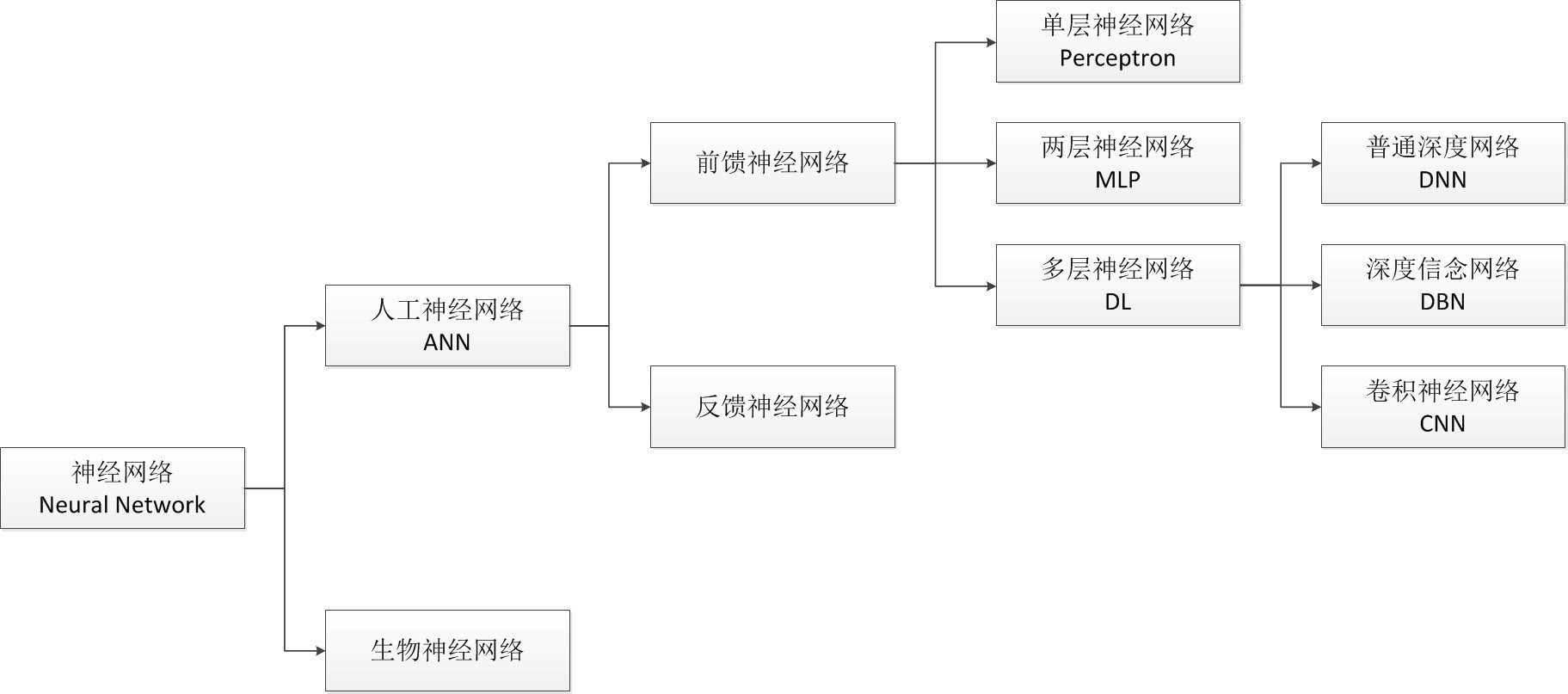
按层数划分神经网络:
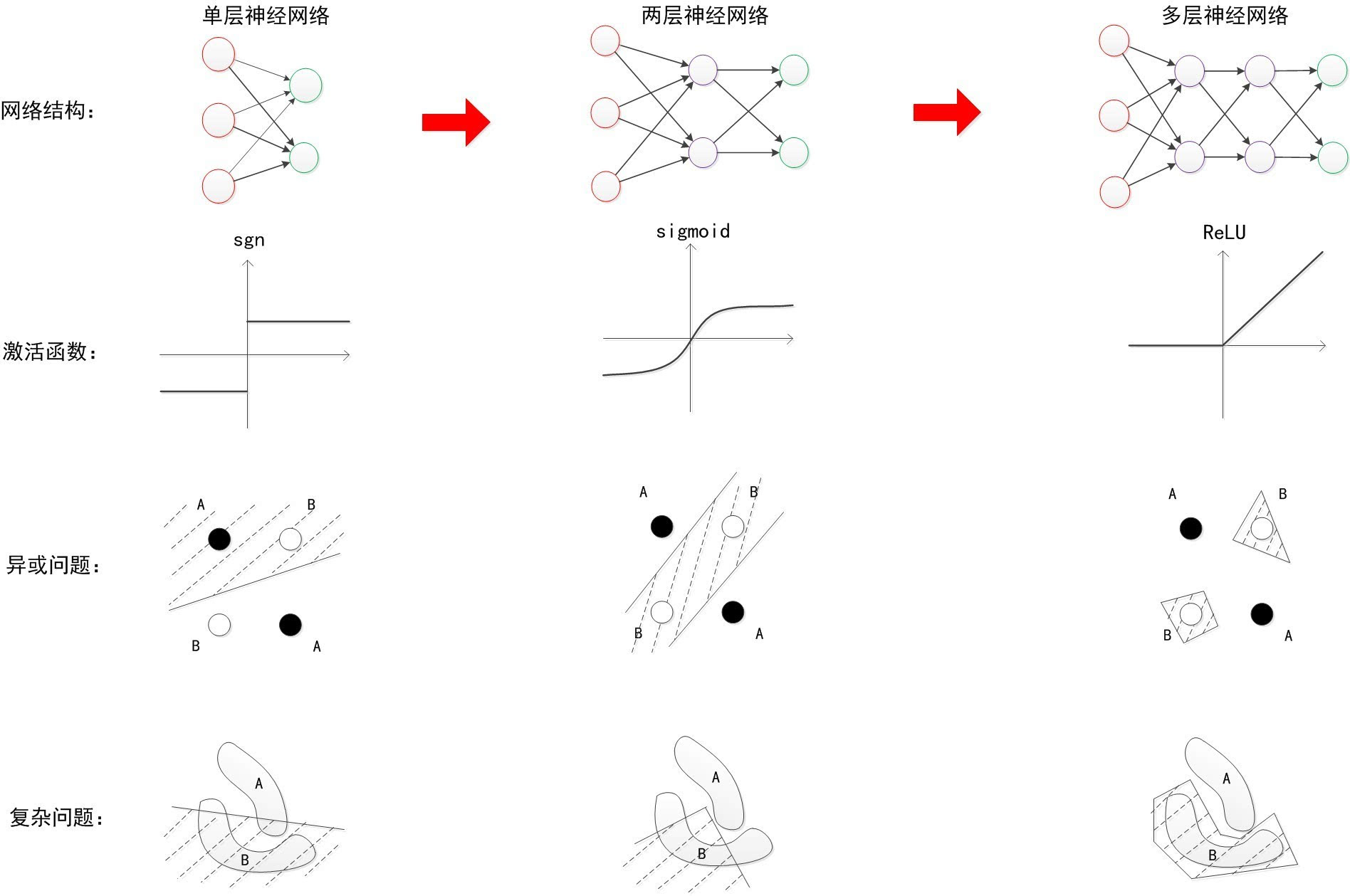

参考:
http://blog.csdn.net/u014595019/article/details/52562159
https://www.2cto.com/kf/201605/512845.html

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









