








作为Python开发人员和数据科学家,我希望构建Web应用程序来展示我的工作。尽管我喜欢设计和编写前端代码,但很快就会成为网络应用程序开发和机器学习的佼佼者。因此,我必须找到一个可以轻松地将我的机器学习模型与其他开发人员集成的解决方案,这些开发人员可以比我更好地构建强大的Web应用程序
通过为我的模型构建REST API,我可以将我的代码与其他开发人员分开。这里有一个明确的分工,这对于定义职责很有帮助,并且阻止我直接阻止那些不参与项目机器学习方面的队友。另一个优点是我的模型可以由在不同平台上工作的多个开发人员使用。
在本文中,我将构建一个简单的Scikit-Learn模型,并使用Flask RESTful将其部署为REST API 。本文特别适用于没有广泛计算机科学背景的数据科学家。
关于模型
在这个例子中,我整理了一个简单的Naives Bayes分类器来预测电影评论中发现的短语的情绪。
这些数据来自Kaggle比赛,电影评论的情感分析。评论被分成单独的句子,句子进一步分成单独的短语。所有短语都具有情感分数,以便可以训练模型,其中哪些单词对句子具有积极,中立或消极的情绪。
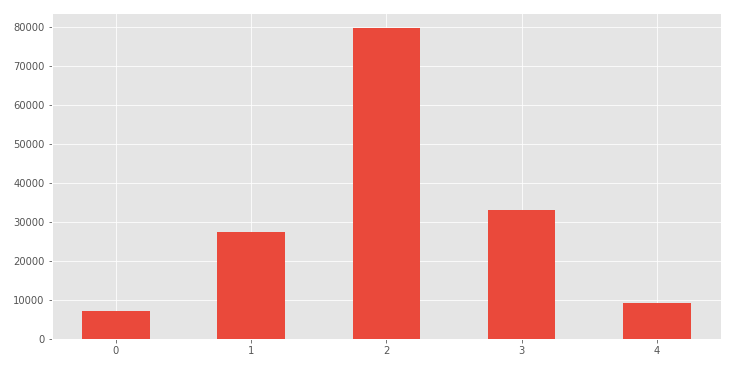
从Kaggle数据集中分配评级
大多数短语都有中性评级。起初,我尝试使用多项式朴素贝叶斯分类器来预测5种可能类别中的一种。但是,由于大多数数据的评级为2,因此该模型的表现不佳。我决定保持简单,因为本练习的主要内容主要是关于部署为REST API。因此,我将数据限制在极端类别,并训练模型仅预测负面或正面情绪。

事实证明,多项式朴素贝叶斯模型在预测正面和负面情绪方面非常有效。您可以在此Jupyter笔记本演练中快速了解模型培训过程。在Jupyter笔记本中训练模型后,我将代码转移到Python脚本中,并为NLP模型创建了一个类对象。您可以在此链接中找到我的Github仓库中的代码。您还需要挑选模型,以便快速将训练过的模型加载到API脚本中。
现在我们有了模型,让我们将其部署为REST API。
REST API指南
为API的Flask应用程序启动一个新的Python脚本。
导入库和加载Pickles
下面的代码块包含很多Flask样板和加载分类器和矢量化器pickles的代码。
from flask import Flask
from flask_restful import reqparse, abort, Api, Resource
import pickle
import numpy as np
from model import NLPModel
app = Flask(__name__)
api = Api(app)
# create new model object
model = NLPModel()
# load trained classifier
clf_path = 'lib/models/SentimentClassifier.pkl'
with open(clf_path, 'rb') as f:
model.clf = pickle.load(f)
# load trained vectorizer
vec_path = 'lib/models/TFIDFVectorizer.pkl'
with open(vec_path, 'rb') as f:
model.vectorizer = pickle.load(f)
创建一个参数解析器
解析器将查看用户发送给API的参数。参数将在Python字典或JSON对象中。对于这个例子,我们将专门寻找一个名为的密钥query。查询将是用户希望我们的模型预测短语是正面还是负面的短语。
# argument parsing
parser = reqparse.RequestParser()
parser.add_argument('query')
资源类对象
资源是Flask RESTful API的主要构建块。每个类别可以具有对应于的REST API的主要行动,如方法:GET,PUT,POST,和DELETE。GET将是主要方法,因为我们的目标是提供预测。在get下面的方法中,我们提供了有关如何处理用户查询以及如何打包将返回给用户的JSON对象的说明。
class PredictSentiment(Resource):
def get(self):
# use parser and find the user's query
args = parser.parse_args()
user_query = args['query']
# vectorize the user's query and make a prediction
uq_vectorized = model.vectorizer_transform(
np.array([user_query]))
prediction = model.predict(uq_vectorized)
pred_proba = model.predict_proba(uq_vectorized)
# Output 'Negative' or 'Positive' along with the score
if prediction == 0:
pred_text = 'Negative'
else:
pred_text = 'Positive'
# round the predict proba value and set to new variable
confidence = round(pred_proba[0], 3)
# create JSON object
output = {'prediction': pred_text, 'confidence': confidence}
return output
端点
以下代码将基本URL设置为情绪预测器资源。您可以想象您可能有多个端点,每个端点指向可以进行不同预测的不同模型。一个示例可以是端点,'/ratings'其将指导用户到另一个模型,该模型可以预测给定类型,预算和生产成员的电影评级。您需要为第二个模型创建另一个资源对象。这些可以一个接一个地添加,如下所示。
api.add_resource(PredictSentiment, '/')
# example of another endpoint
api.add_resource(PredictRatings, '/ratings')
名称==主要区块
这里不多说。如果要将此API部署到生产环境,请将debug设置为False。
if __name__ == '__main__':
app.run(debug=True)
用户请求
以下是用户如何访问您的API以便他们获得预测的一些示例。
使用Jupyter笔记本中的Requests模块:
url = 'http://127.0.0.1:5000/'
params ={'query': 'that movie was boring'}
response = requests.get(url, params)
response.json()
Output: {'confidence': 0.128, 'prediction': 'Negative'}
使用curl:
$ curl -X GET http://127.0.0.1:5000/ -d query='that movie was boring'
{
"prediction": "Negative",
"confidence": 0.128
}
使用HTTPie:
$ http http://127.0.0.1:5000/ query=='that movie was boring'
HTTP/1.0 200 OK
Content-Length: 58
Content-Type: application/json
Date: Fri, 31 Aug 2018 18:49:25 GMT
Server: Werkzeug/0.14.1 Python/3.6.3
{
"confidence": 0.128,
"prediction": "Negative"
}现在,我的队友可以通过向这个API发出请求来为他们的应用添加情绪预测,而无需将Python和JavaScript混合在一起。
完整app.py 代码
有时在一个地方查看所有代码会很有帮助。
from flask import Flask
from flask_restful import reqparse, abort, Api, Resource
import pickle
import numpy as np
from model import NLPModel
app = Flask(__name__)
api = Api(app)
model = NLPModel()
clf_path = 'lib/models/SentimentClassifier.pkl'
with open(clf_path, 'rb') as f:
model.clf = pickle.load(f)
vec_path = 'lib/models/TFIDFVectorizer.pkl'
with open(vec_path, 'rb') as f:
model.vectorizer = pickle.load(f)
# argument parsing
parser = reqparse.RequestParser()
parser.add_argument('query')
class PredictSentiment(Resource):
def get(self):
# use parser and find the user's query
args = parser.parse_args()
user_query = args['query']
# vectorize the user's query and make a prediction
uq_vectorized = model.vectorizer_transform(np.array([user_query]))
prediction = model.predict(uq_vectorized)
pred_proba = model.predict_proba(uq_vectorized)
# Output either 'Negative' or 'Positive' along with the score
if prediction == 0:
pred_text = 'Negative'
else:
pred_text = 'Positive'
# round the predict proba value and set to new variable
confidence = round(pred_proba[0], 3)
# create JSON object
output = {'prediction': pred_text, 'confidence': confidence}
return output
# Setup the Api resource routing here
# Route the URL to the resource
api.add_resource(PredictSentiment, '/')
if __name__ == '__main__':
app.run(debug=True)
文件结构
我想要包含的最后一件事是对这个简单API的文件结构的一点概述。
<span style="color:rgba(0, 0, 0, 0.84)">情绪-CLF /
├──README.md
├──app.py <strong>#瓶REST API脚本</strong>
├──build_model.py <strong>#脚本来构建和酸洗分类</strong>
├──model.py <strong>的分类类对象#脚本</strong>
├─ ─util.py <strong>#辅助函数</strong>
├──requirements.txt
└──LIB /
├──数据/ <strong>从Kaggle#数据</strong>
│├──sampleSubmission.csv
│├──test.tsv
│└──train.tsv
└─ ─型号/ <strong>#腌制模型导入到API脚本</strong>
├──SentimentClassifier.pkl
└──TFIDFVectorizer.pkl</span>部署
一旦您构建了模型和REST API并在本地完成测试,您就可以像将任何Flask应用程序部署到Web上的许多托管服务一样部署API。通过在Web上部署,各地的用户都可以向您的URL发出请求以获取预测。部署指南包含在Flask文档中。
闭幕
这只是为情绪分类器构建Flask REST API的一个非常简单的示例。一旦您训练并保存了相同的过程,就可以应用于其他机器学习或深度学习模型。
除了将模型部署为REST API之外,我还使用REST API来管理数据库查询,以便通过从Web上抓取来收集数据。这使我可以与全栈开发人员协作,而无需管理其React应用程序的代码。如果移动开发人员想要构建应用程序,那么他们只需熟悉API端点即可。
原文: https://towardsdatascience.com/deploying-a-machine-learning-model-as-a-rest-api-4a03b865c166

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









