







一、模型部署简介
近几年来,随着算力的不断提升和数据的不断增长,深度学习算法有了长足的发展。深度学习算法也越来越多的应用在各个领域中,比如图像处理在安防领域和自动驾驶领域的应用,再比如语音处理和自然语言处理,以及各种各样的推荐算法。如何让深度学习算法在不同的平台上跑的更快,这是深度学习模型部署所要研究的问题。
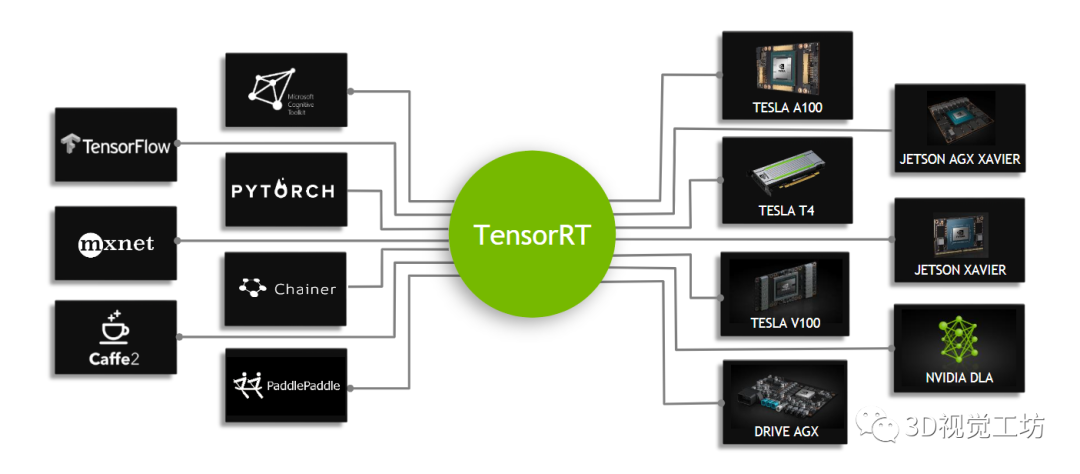
目前主流的深度学习部署平台包含GPU、CPU、ARM。模型部署框架则有英伟达推出的TensorRT,谷歌的Tensorflow和用于ARM平台的tflite,开源的caffe,百度的飞浆,腾讯的NCNN。其中基于GPU和CUDA的TensorRT在服务器,高性能计算,自动驾驶等领域有广泛的应用。
二、使用TensorRT进行推理
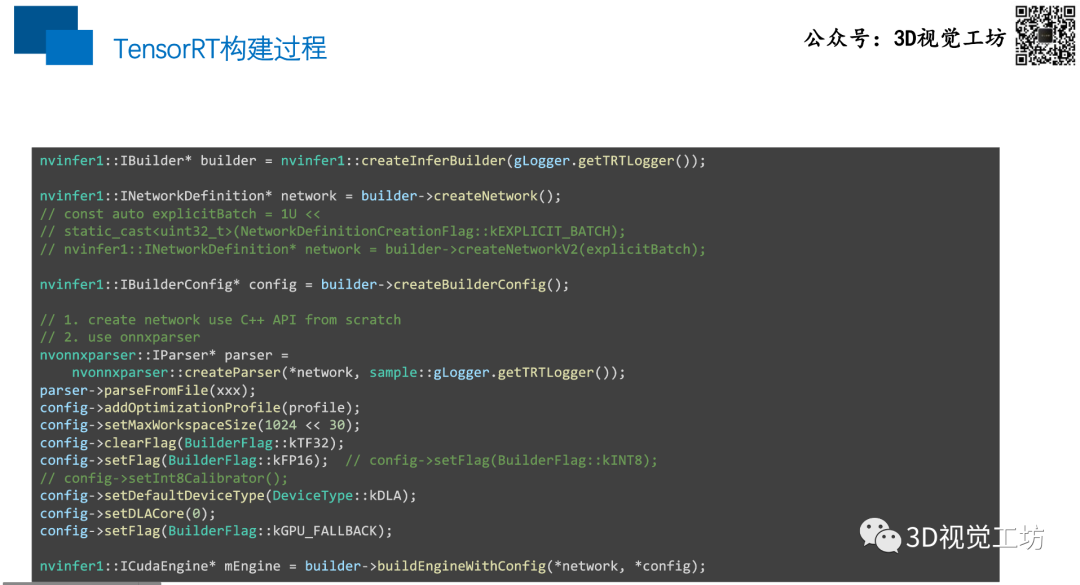
1、构建TensorRT Engine
使用TensorRT进行推理,共分为两个阶段。
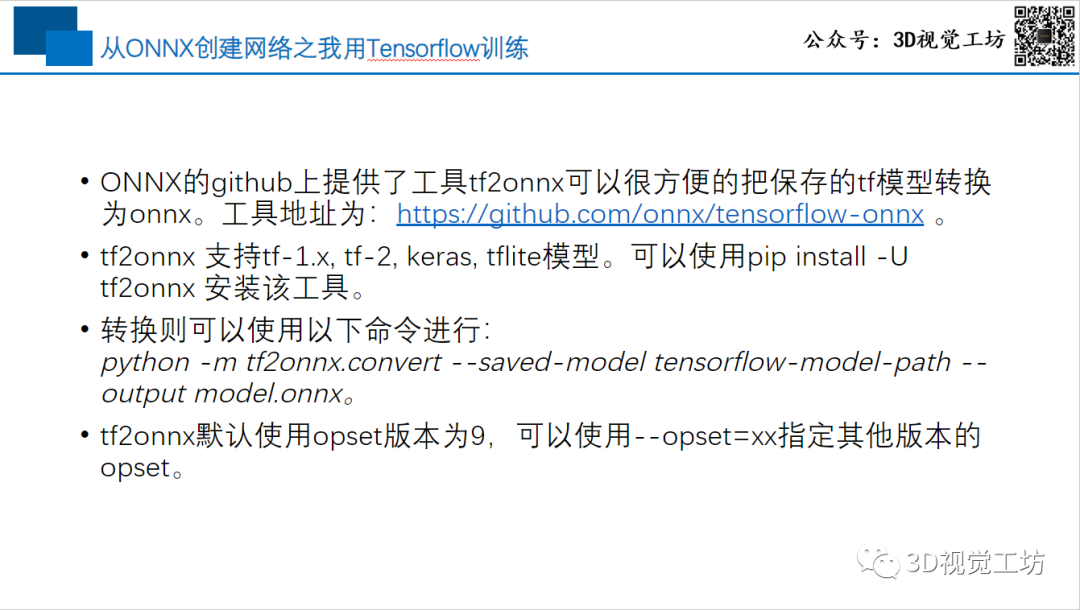
第一个阶段主要是构建TensorRT引擎。目前的主流方式是从onnx转换为TensorRT的引擎。而从各种训练框架都有非常丰富的工具,可以将训练后的模型转换到onnx。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5937
5937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









