






实验要求
使用Kaggle猫狗分类的原始数据集,实现模型最终的准确率达到75%及以上。
-
为了进一步掌握使用深度学习框架进行图像分类任务的具体流程如:读取数据、构造网络、训练和测试模型
-
掌握经典卷积神经网络
VGG16、ResNet50的基本结构
实验环境
mac m3 pro, 数据集下载地址:https://www.microsoft.com/en-us/download/details.aspx?id=54765
实验原理
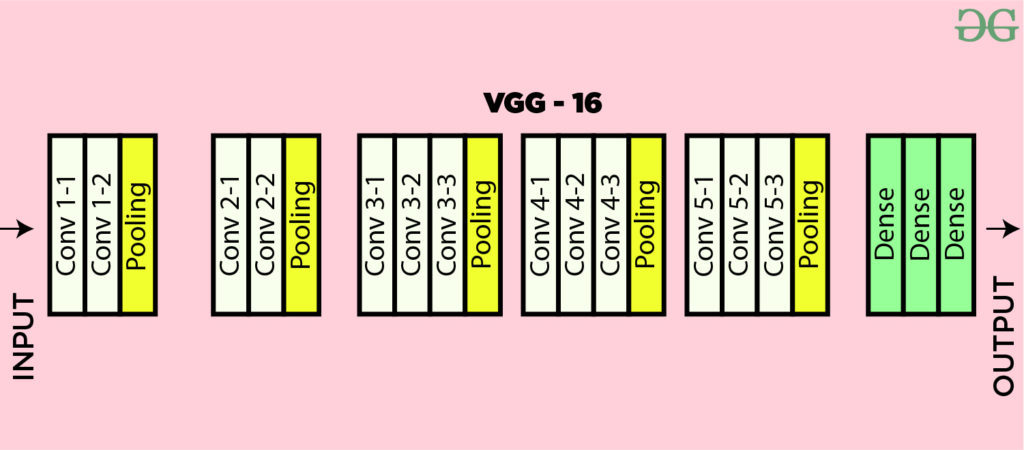
VGG16采取了深层小核叠加的方式增大了感受野,达到了与大卷积核同样的效果,可以识别更大的特征。它的结构非常的规整,使用了重复的block.VGG的参数量较大,训练的速度较慢,参数可达到一亿个。
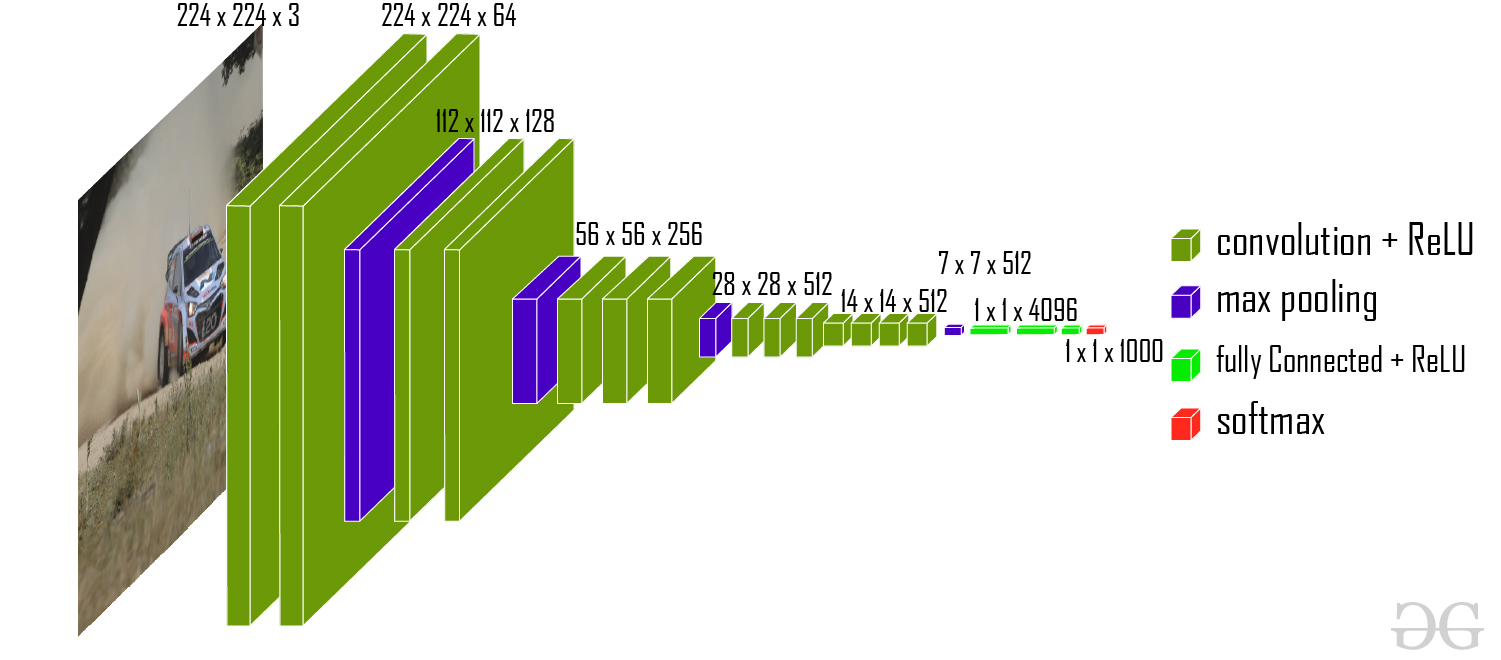
残差网络则解决了深层模型收敛较慢的问题,他在模块设计中增加了旁路,使得深层模型加快收敛。
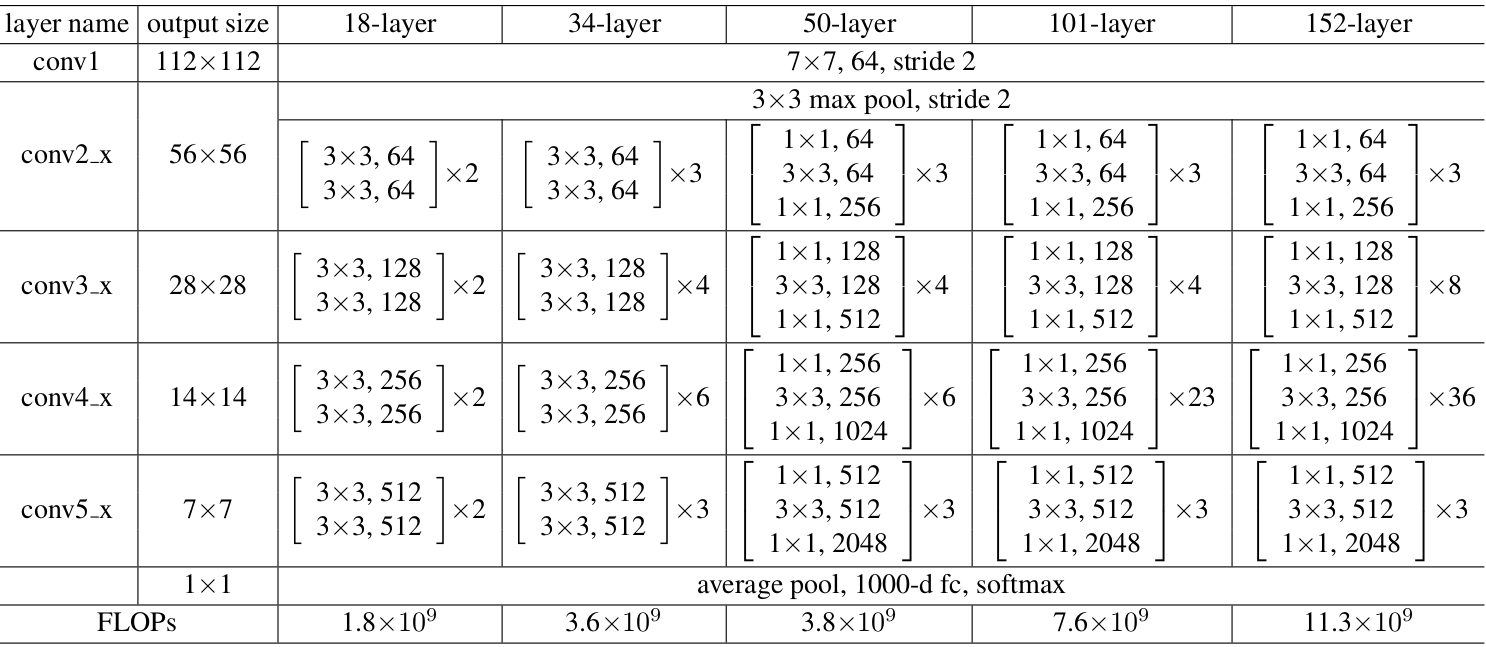
实验过程1: VGG16
数据预处理
-
文件格式处理:在查看文件格式时,发现虽然文件的拓展名都是.jpg,但是实际上它们的格式除了jpg,jpeg, png这几种可以处理的格式外,还包含有不能处理的格式如bmp, gif等。所以使用单独的脚本test.py将不符合要求的文件从数据集中删除,使接下来的程序可以正确运行。
# test.py
import os
from pathlib import Path
from PIL import Image
# 数据集目录
data_dir = Path('data')
# 允许的图片格式
valid_formats = {'JPEG', 'PNG'}
# 遍历所有文件,检查格式
for img_path in data_dir.glob("**/*"):# 只处理文件(排除文件夹)
if img_path.is_file():
try:
with Image.open(img_path) as img:
# 获取实际格式
actual_format = img.format
# 如果文件格式不在允许的格式列表中,则删除该文件
if actual_format not in valid_formats:
print(f"Deleting {img_path}, format is {actual_format}")os.remove(img_path)
except Exception as e:
print(f"Error with {img_path}: {e}")
-
数据预处理transforms.Resize((224, 224))将图片尺寸进行调整。transforms.ToTensor将图片转化为可处理的张量,而且值在01之间。将图片标准化以加快训练速度。
-
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch import device
from PIL import Image
# 数据预处理:包括图像尺寸调整,转换为Tensor,归一化
transform = transforms.Compose([
transforms.Resize((224, 224)), # VGG16 的输入大小是 224x224
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化,虽然没有预训练模型,也可以用这个标准
])
加载数据集
从'data'文件夹,将数据集作为train_data加载,使用上面定义的transform对其进行预处理。定义迭代器train_loader,以每批32个数据随机加载训练数据。
# 加载数据集
train_data = datasets.ImageFolder('data', transform=transform) # 加载数据集的根目录,cat和dog会自动作为子类
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
启用硬件加速
使用Mac silicon的mps硬件加速
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
定义VGG16网络
整体使用3*3的卷积核,前两大层结构为卷积-卷积-池化,后三个大层为卷积-卷积-卷积-池化,再加上3个全连接层,一共16层。
# VGG16.py
import torch.nn as nn
# 自定义VGG16模型
class VGG16(nn.Module):
def __init__(self, num_classes=2):
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), # 输入3通道图像,输出64通道
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096), # 输入大小根据特征图大小来决定
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes), # 输出2个类别(猫和狗)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1) # 展平
x = self.classifier(x)
return x
定义resnet50网络
import torch
import torch.nn as nn
from torch.autograd import Variable
# 检查MPS是否可用
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
class convolutional_block(nn.Module): # convolutional_block层
def __init__(self, cn_input, cn_middle, cn_output, s=2):
super(convolutional_block, self).__init__()
self.step1 = nn.Sequential(nn.Conv2d(cn_input, cn_middle, (1, 1), (s, s), padding=0, bias=False),
nn.BatchNorm2d(cn_middle, affine=False), nn.ReLU(inplace=True),
nn.Conv2d(cn_middle, cn_middle, (3, 3), (1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(cn_middle, affine=False), nn.ReLU(inplace=True),
nn.Conv2d(cn_middle, cn_output, (1, 1), (1, 1), padding=0, bias=False),
nn.BatchNorm2d(cn_output, affine=False))
self.step2 = nn.Sequential(nn.Conv2d(cn_input, cn_output, (1, 1), (s, s), padding=0, bias=False),
nn.BatchNorm2d(cn_output, affine=False))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x_tmp = x
x = self.step1(x)
x_tmp = self.step2(x_tmp)
x = x + x_tmp
x = self.relu(x)
return x
class identity_block(nn.Module): # identity_block层
def __init__(self, cn, cn_middle):
super(identity_block, self).__init__()
self.step = nn.Sequential(nn.Conv2d(cn, cn_middle, (1, 1), (1, 1), padding=0, bias=False),
nn.BatchNorm2d(cn_middle, affine=False), nn.ReLU(inplace=True),
nn.Conv2d(cn_middle, cn_middle, (3, 3), (1, 1), padding=1, bias=False),
nn.BatchNorm2d(cn_middle, affine=False), nn.ReLU(inplace=True),
nn.Conv2d(cn_middle, cn, (1, 1), (1, 1), padding=0, bias=False),
nn.BatchNorm2d(cn, affine=False))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x_tmp = x
x = self.step(x)
x = x + x_tmp
x = self.relu(x)
return x
class Resnet(nn.Module): # 主层
def __init__(self, c_block, i_block):
super(Resnet, self).__init__()
self.conv = nn.Sequential(nn.Conv2d(3, 64, (7, 7), (2, 2), padding=(3, 3), bias=False),
nn.BatchNorm2d(64, affine=False), nn.ReLU(inplace=True), nn.MaxPool2d((3, 3), 2, 1))
self.layer1 = c_block(64, 64, 256, 1)
self.layer2 = i_block(256, 64)
self.layer3 = c_block(256, 128, 512)
self.layer4 = i_block(512, 128)
self.layer5 = c_block(512, 256, 1024)
self.layer6 = i_block(1024, 256)
self.layer7 = c_block(1024, 512, 2048)
self.layer8 = i_block(2048, 512)
self.out = nn.Linear(2048, 2, bias=False)
self.avgpool = nn.AvgPool2d(7, 7)
def forward(self, input):
x = self.conv(input)
x = self.layer1(x)
for i in range(2):
x = self.layer2(x)
x = self.layer3(x)
for i in range(3):
x = self.layer4(x)
x = self.layer5(x)
for i in range(5):
x = self.layer6(x)
x = self.layer7(x)
for i in range(2):
x = self.layer8(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
# 创建模型并移动到MPS设备
net = Resnet(convolutional_block, identity_block).to('mps')
定义超参
二分类问题num_classes=2,将模型移动到mps训练。分类问题使用交叉熵损失函数,使用adam优化器,学习率0.0001,训练10代。
# 实例化模型
# model = VGG16(num_classes=2)
# model = models.vgg16(pretrained=True)
model = models.resnet50(pretrained=True)
# model = Resnet(convolutional_block, identity_block)
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
训练模型
训练模型十代,保存模型, 并绘制结果。
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 零化梯度
optimizer.zero_grad()
# 向前传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确度
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 打印每个 epoch 的训练损失和准确度
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}, Accuracy: {100 * correct / total:.2f}%")
# 保存训练好的模型
torch.save(model.state_dict(), 'vgg16_cat_dog_from_scratch.pth')
分析
从输出可以看出,VGG16经过前两代训练之后,模型的准确度快速上升。直到第6代开始准确率上升速度减缓,最终在第十代达到93.78%的准确率。模型的效果很好。
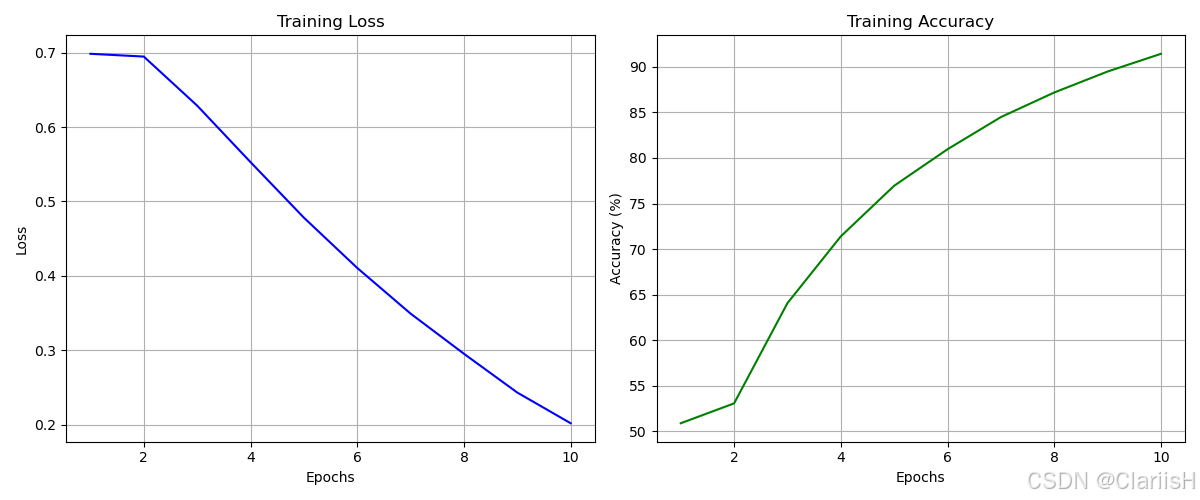
Resnet则在一开始就有较高的准确率,约达到70%,接着在10代达到95%以上的准确率。
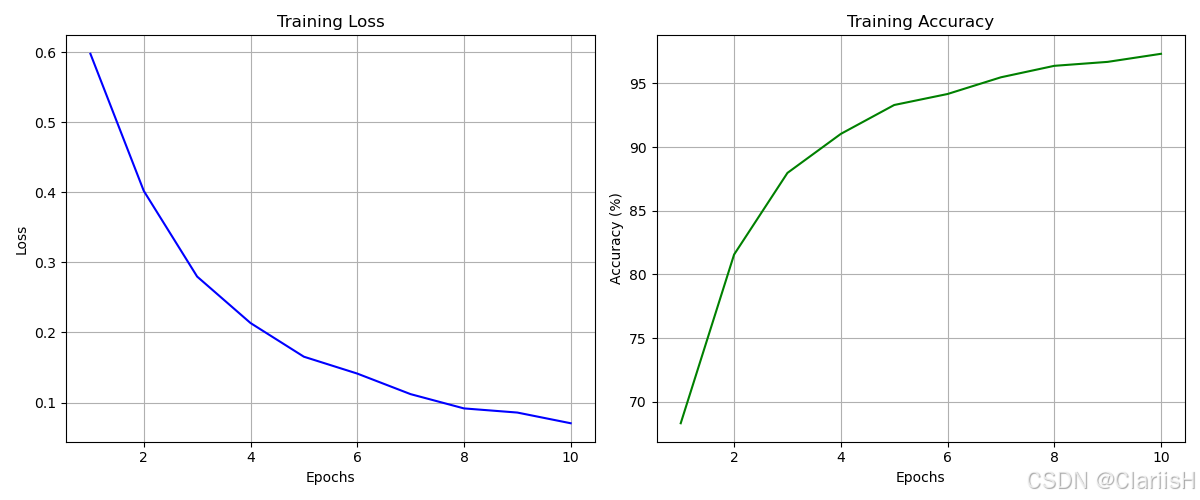
对于预训练模型,VGG16的表现在一开始就达到了95%的准确率,在经过四代训练后,准确率达到了99%。
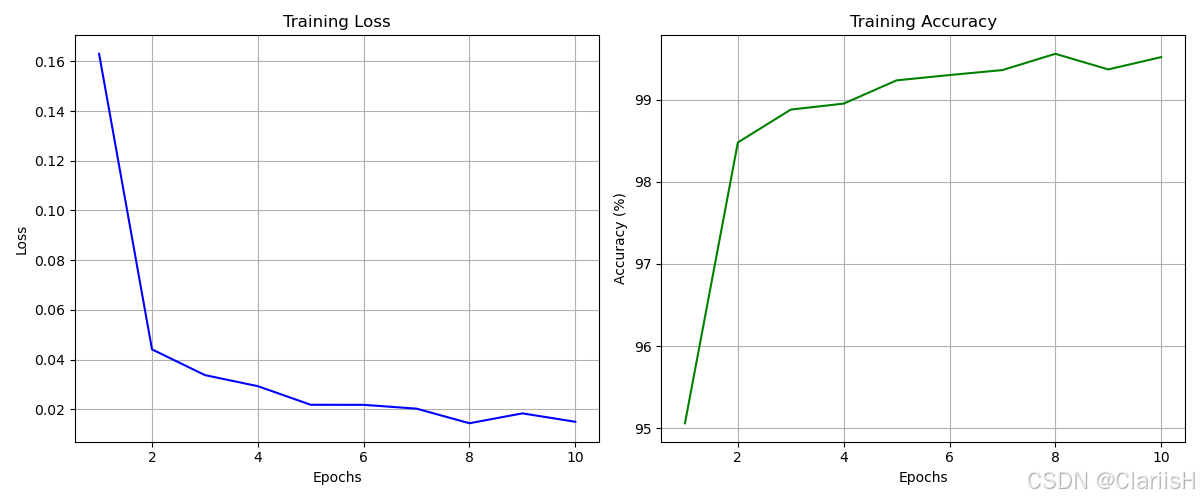
而Resnet50的预训练模型则在一开始达到了97%的准确率,在两代训练后准确率就提升至99%。
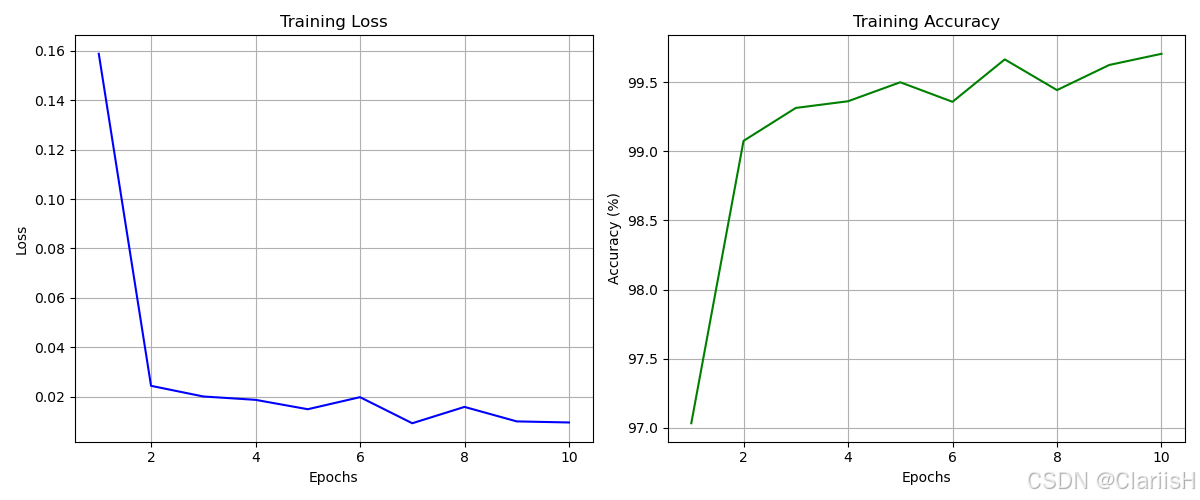
由以上实验可知,ResNet50在模型收敛速度和最终准确率上均优于VGG16,包括自己搭建的模型和预先训练的模型表现。两者的预训练的模型的表现均很好,初始准确率就能达到95%以上,最终准确率均能达到99%以上。

















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









