









需求跟踪矩阵能够确保需求在整个生命周期内得到有效控制,精准追踪并覆盖潜在漏洞,强化测试验证环节,从而提升项目交付的质量与效率。若未创建需求跟踪矩阵,可能会导致需求遗漏、变更管理失控、测试覆盖不全面等问题,进而增加项目风险,使项目成本易于超支。
因此,创建需求跟踪矩阵至关重要,以下是5大常见步骤(附注意事项):

1、需求收集及规范化
在构建需求跟踪矩阵前,需对需求进行全面的收集和整理,明确所有需求来源,如用户需求文档、业务需求文档、利益相关者文档等。
对需求进行分类整理,分为功能需求、非功能需求、接口需求、性能需求等。
注意事项:
为每个需求分配唯一的ID或编号,如REQ-001.
避免模糊描述,如系统刷新要快速应改为页面加载时间≤1秒。
确保需求完整性和明确性,尤其不能遗漏重要需求。

2、建立需求与其他工件间的映射关系
需要将需求与设计文档、测试用例、代码模块、测试脚本等相关联,能够实现双向追溯。
向前追溯:需求→设计→开发→测试。
向后追溯:测试结果→缺陷→需求验证。
我们根据项目的复杂程度,对追溯层级进行选择。如简单项目的层级:需求→测试,而大型复杂场景,则需要建立多层级。
注意事项:
确保需求的双向可追溯性。
层级选择需要综合考虑项目复杂程度及开发效率。
避免过渡关联,仅跟踪关键路径,减少维护成本。

3、设计需求跟踪矩阵
根据项目特点设计可操作的RTMA表格,以适配团队协作。基础字段一般包括:需求ID、描述、来源、优先级、状态;而扩展字段包括:设计文档、测试用例ID、测试覆盖率等。
注意事项:
我们需要根据项目的规模和复杂程度来灵活调整需求跟踪矩阵的内容。
统一命名规则,以便于管理和团队协作。
表格应随项目进展不断更新并保留历史记录。
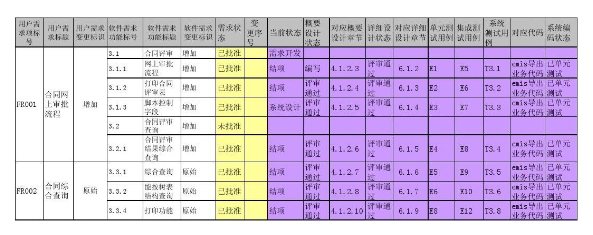
4、创建需求跟踪矩阵
根据项目实际情况,填写矩阵内容,并定期更新最新状态。如新需求需要同步更新,而代码提交或测试执行后续更新对应字段。要确保每个需求关联最好一个测试用例。
注意事项:
矩阵需专人负责和维护,以防止信息延迟或失真。
存档旧版本:保留历史版本以应对审计。
自动化集成:有条件可与CI/CD、测试管理平台集成,提高效率。
为了进一步提高测试效率,我们可以使用AI工具,如CoCodeAI自动生成测试用例、测试脚本和测试报告功能,使用AI自动生成每个需求的多维度测试用例、测试报告,提高测试覆盖度和全面性,保障测试质量,减轻测试人员工作量。
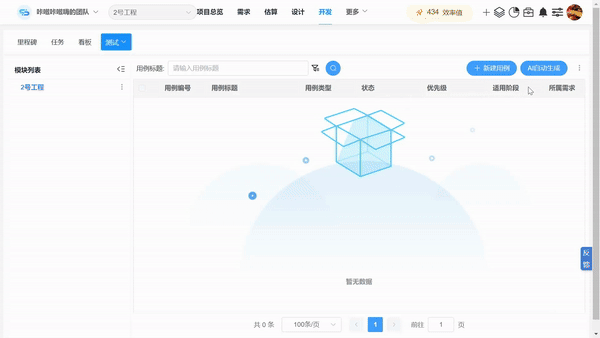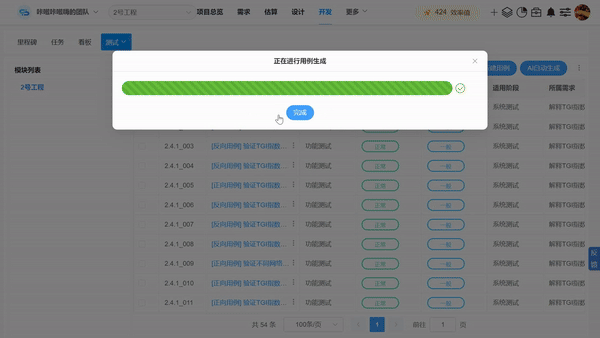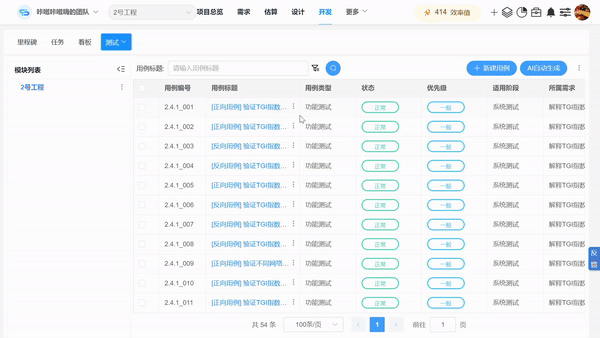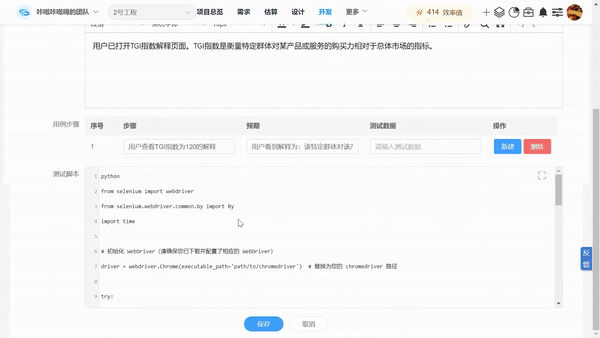
5、审查与验证
我们需要确保需求被完整实现和测试,定期组织跨职能团队开评审会,进行审查矩阵RTM。检查是否存在未实现、未测试、是否关联测试用例或存在冲突的需求等。
注意事项:
定期组织评审会,需求提出人、开发、测试共同参与审查。
优先验证高优先级的需求。
重点关注缺陷问题,若测试未通过,需追溯至需求定义是否清晰。
需持续优化与改进RTM流程,以提升需求质量。


















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









