






首先回顾一下注意力机制。
注意力机制的本质是自主意志对无意识的客观活动进行有意识选择,从而实现了对价值的选择倾向。
在这个过程中,自主意志(意志线索)称为查询(query),客观活动(非意志线索)称为键(key),客观价值称为值(value),原理如图所示:
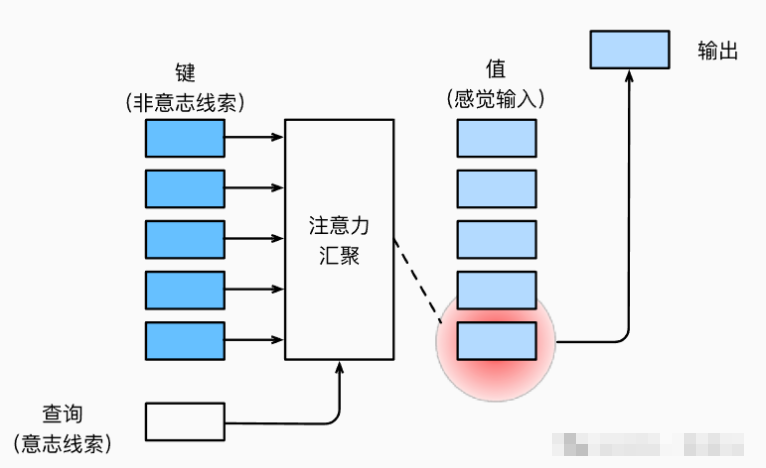
查询(query)和不同的键(key)在注意力汇聚层中经过计算,得到了对应的注意力权重,通过这个权重,我们可以修改不同键对应的值占输出的比例大小,从而实现对值(value)的选择倾向。
在一般情况下,这种注意力计算方式就可以满足我们的需要。通过注意力计算,模型会选择性地关注到查询(query)比较在意的特征,然后调整值(value)的输出。然而,当我们想要关注的特征类别比较多时(比如当查询和键都是文本序列时,我们既要关注近距离的词语关系又要关注长距离的语义依赖),就捉襟见肘了,因为一次注意力计算关注的特征毕竟还是有限的。
为了将注意力计算关注的特征扩大到更大的范围,让模型从不同的角度捕捉输入的特征,我们可以将注意力计算中的查询、键和值都用h个不同的全连接层进行线性变换以分成h份,每一份都称为一个头,每一个头以不同的方式关注输入数据的不同部分,并行地学习不同的关系从而获得更加丰富的上下文信息,这样不同的注意力头就可以学习到不同的注意力权重和表示,使得模型具备更强的表达能力,这就是多头注意力,原理如图:
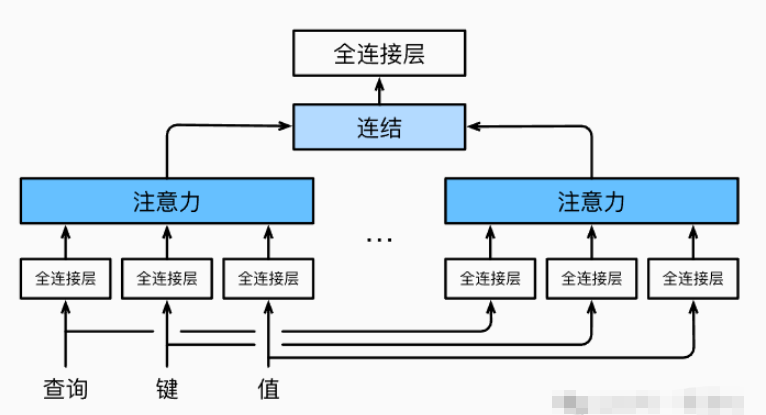
如图所示,我们让查询、键、值都经过不同的全连接层线性投影为h个不同的头,然后并行地送到注意力汇聚中经过注意力计算后拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 产生最终输出,这种设计被称为多头注意力(multihead attention)。
但是,我们要提出一个问题,多头注意力就一定会捕捉到更多的特征并学习到不同的关系吗?
在多头注意力中,每个头都有自己的线性变换(即通过独立的权重矩阵对输入进行变换),这意味着每个头可以从不同的特征维度或角度来观察输入,但是这种线性变换也有一定概率会把每个头映射到相似的空间。
所以,多头注意力机制并非“保证”每个头能学习到完全不同的特征,但从概率上和计算上,独立的权重和不同的线性变换让不同头有较高的可能性关注到不同的特征和关系。即便某些头可能会有相似的关注区域,但整体而言,多头注意力依然增强了模型捕捉复杂特征的能力。

在这种设计下,每个头可以并行关注到输入的不同特征和关系,使得模型在表示复杂的语义时表现得更加精准和高效。
下面,我们来看看代码(引自《动手学深度学习》)

import math
import torch
from torch import nn
from d2l import torch as d2l
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
# 初始化多头注意力类,继承自nn.Module,初始化必要的参数
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads # 保存头的数量
self.attention = d2l.DotProductAttention(dropout) # 使用点积注意力机制
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias) # 查询的线性变换
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias) # 键的线性变换
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias) # 值的线性变换
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias) # 多头输出的线性变换
def forward(self, queries, keys, values, valid_lens):
# queries, keys, values 的形状: (batch_size, 查询或“键-值”对个数, num_hiddens)
# valid_lens 的形状: (batch_size, ) 或 (batch_size, 查询的个数)
# 变换 queries, keys, values 为多头格式,形状变为
# (batch_size*num_heads, 查询或“键-值”对的个数, num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 如果有valid_lens,则将其扩展到与多头数量匹配,
# 形状为 (batch_size*num_heads, 查询的个数)
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# 使用点积注意力机制计算多头注意力输出,形状为:
# (batch_size*num_heads, 查询的个数, num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# 重新变换输出的形状,拼接多头输出为 (batch_size, 查询的个数, num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat) # 最终输出通过线性层调整维度
def transpose_qkv(X, num_heads):
"""为了多头注意力的并行计算调整形状"""
# 输入X的形状: (batch_size, 查询或“键-值”对的个数, num_hiddens)
# 重新调整形状,将嵌入分为多个头的格式,
# 输出形状变为: (batch_size, 查询或“键-值”对的个数, num_heads, num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 调整轴顺序,以便不同头之间的计算可以并行
# 形状变为: (batch_size, num_heads, 查询或“键-值”对的个数, num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 将维度展平以进行计算,输出形状为:
# (batch_size*num_heads, 查询或“键-值”对的个数, num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv的操作,将输出还原为初始形状"""
# 输入形状: (batch_size*num_heads, 查询的个数, num_hiddens/num_heads)
# 重新调整为分组后的格式 (batch_size, num_heads, 查询的个数, num_hiddens/num_heads)
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
# 调整轴顺序,将头和查询的维度交换
# 输出形状: (batch_size, 查询的个数, num_heads, num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 合并头的维度,最终形状为: (batch_size, 查询的个数, num_hiddens)
return X.reshape(X.shape[0], X.shape[1], -1)
总的来说,多头注意力提升了模型的特征表达能力,增强了其对复杂数据结构的理解能力。由于其每个头可以关注不同的特征或模式,所以整体上提供了更加丰富的上下文信息,有助于捕捉复杂的依赖关系,让模型能更好地理解全局信息,提高泛化性。未来的优化方向可以着重关注减少计算成本、增强表示能力、平衡局部与全局信息、改进注意力计算方式、优化参数量和提高自适应性与鲁棒性等等。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









