






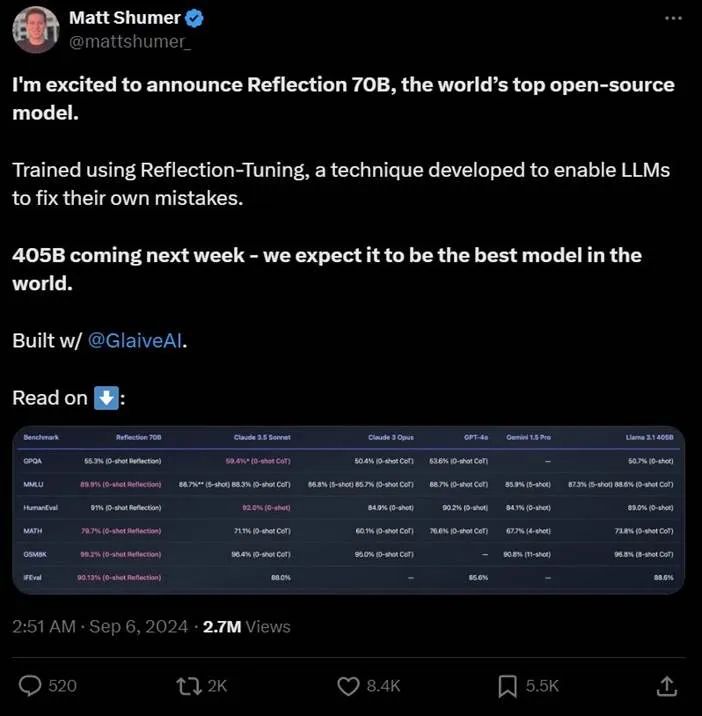
在2024年9月6日,大模型的圈子迎来了一位新成员——Reflection 70B,它横扫了MMLU、MATH、IFEval、GSM8K等知名的模型基准测试,完美超越了GPT-4o,同时也超越了Claude3.5 Sonnet成为了新的大模型之王,Reflection 70B到底是什么来头?它为什么能超越GPT-4o呢?
首先是官宣推文:
其次是这个模型成为了HuggingFace上最热门的项目:
Hugging Face:https://huggingface.co/mattshumer/Reflection-70B
体验网址:https://reflection-playground-production.up.railway.app/
看了上面官宣推文中给出的测试结果,大家肯定会认为这是由一个公司做出来的,但是并不是,出人意料的是,这个大模型是由两位开发者用三周的时间手搓出来的。一位是发帖的 HyperWrite CEO Matt Shumer,另一位是 AI 创业公司 Glaive AI 的创始人 Sahil Chaudhary。他们表示,Reflection 70B 的底层模型建立在 Meta 的 Llama 3.1 70B Instruct 上,并使用原始的 Llama Chat 格式,确保了与现有工具和 pipeline 的兼容性。
技术细节
首先看一条推文:
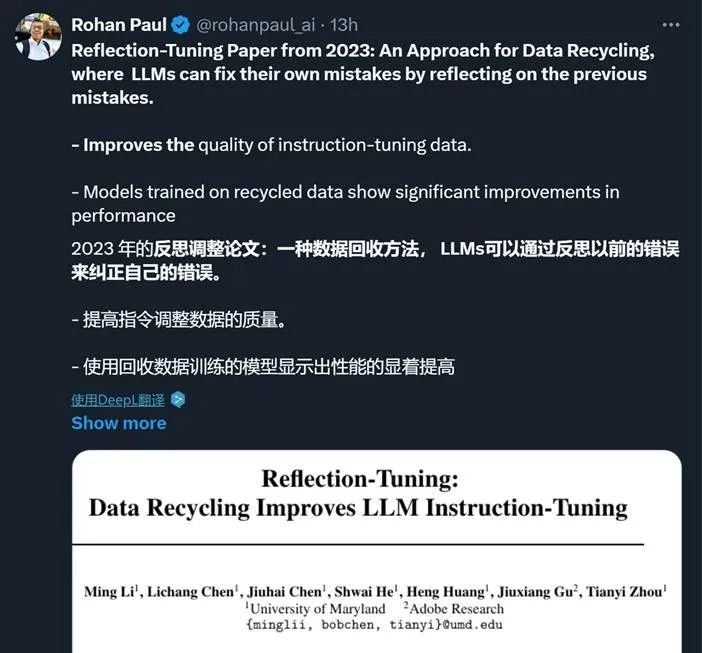
推文中说这个模型使用了一个数据回收方法——Reflection-Tuning,在下文我会详细讲一下这种技术:
以下是对Reflection-Tuning技术细节的中文翻译:
1. 动机:
-
训练数据的质量对指令微调的效果至关重要,因为低质量的数据会导致大型语言模型(LLM)输出不一致或误导性的结果。Reflection-Tuning旨在通过改进数据集中的指令-响应对来解决这个问题。
-
该方法利用一个"神谕"模型(例如ChatGPT)对指令和响应进行自我反思和优化,生成高质量的数据,从而提高LLM的训练效果,而不需要额外的模型或大量的人工干预。
2. 方法论:
Reflection-Tuning由两个主要阶段组成:指令反思和响应反思。
2.1 指令反思:
-
过程:使用神谕模型(如ChatGPT)根据预定的标准对原始数据集中的指令-响应对进行评估,并对指令进行改进。
-
改进标准:
-
话题的复杂性
-
对响应细节的要求
-
响应所需的知识
-
指令的模糊性
-
是否涉及逻辑推理或问题解决
-
-
关键反思:模型基于这些标准生成反馈或反思,并根据这些反思产生修改后的指令-响应对。链式思维(或树式思维)提示被用来确保改进的逻辑性和一致性。
2.2 响应反思:
-
过程:在改进指令后,使用类似的方法对响应进行优化。神谕模型根据新标准对响应进行反思,并生成与改进后的指令更匹配的响应。
-
响应反思的标准:
-
有效性
-
相关性
-
准确性
-
细节程度
-
-
最终输出的是一个回收的指令-响应对,用于目标LLM的训练。
3. 建模细节:
-
符号表示:
-
设 ( f_\theta ) 为目标LLM,其参数为 ( \theta ),而 ( g ) 为神谕模型(如ChatGPT)。
-
指令 ( x ) 和响应 ( y ) 组成的数据对为 ((x_0, y_0)),来自数据集 ( D_0 ),模型通过反思生成新的指令-响应对 ((x{\text{ins}}, y{\text{ins}}))。
-
通过基于关键反思的反馈引导生成新的改进后的指令-响应对。
-
4. 实验设置:
-
数据集:该方法在Alpaca数据集(52,000个指令样本)和WizardLM数据集(250,000个指令样本)上进行测试,这些数据集是指令微调的基准数据集。
-
训练细节:
-
方法应用于Llama2-7b等模型,使用Adam优化器,批量大小为128,学习率为(2 \times 10^{-5})。
-
训练持续三轮,每个序列的最大长度为2048个标记。
-
5. 评估指标:
-
成对比较:GPT-4和ChatGPT作为评估者,比较不同模型生成的输出。每个响应根据相关性、准确性等标准进行评分,并与人类偏好对齐。
-
排行榜:回收后的模型在Alpaca-Eval和Huggingface Open LLM排行榜上进行评估,取得了较高的胜率,超越了其他经过指令微调的模型。
6. 实验结果:
-
性能:Reflection-Tuning显著提高了模型在指令遵从性和响应质量方面的表现。回收后的模型在同等规模的模型中始终表现优越,有时甚至超过了参数量更大的模型。
-
数据质量改进:反思过程增加了Alpaca数据集中指令的复杂性,提升了响应的细节水平,生成的指令-响应对更加连贯、质量更高。
7. 讨论:
-
统计分析:该方法显著增加了Alpaca数据集中指令的长度,同时简化了WizardLM数据集中过于复杂的指令。它还提高了指令与响应之间的连贯性。
-
在更大模型上的表现:在13B参数规模的模型上进一步验证了Reflection-Tuning的有效性。即使使用较小的数据集进行训练,回收后的模型依然在多个排行榜上取得了高胜率。
8. 结论:
-
Reflection-Tuning证明了数据回收在指令微调中的重要性,显著提升了指令遵从数据集的质量。通过利用LLM的自我改进能力,这一方法在不需要大规模重新训练的情况下提升了模型的可靠性和性能。
总结来说,Reflection-Tuning是通过改进训练数据,提高大型语言模型指令遵从性的一种先进方法。这种方法有效地增强了模型在多个基准上的表现。
网络上的测试
目前,不少网友已经开始测试 Reflection 70B,并反馈了一些积极结果。比如面对一个关于杯子和硬币的问题(先把硬币放入杯子,再把杯子放到床上,然后把杯子翻转过来,硬币会在哪里?),模型会反复反思自己的答案,并给出一个考虑到各种特殊情况的最终答案。
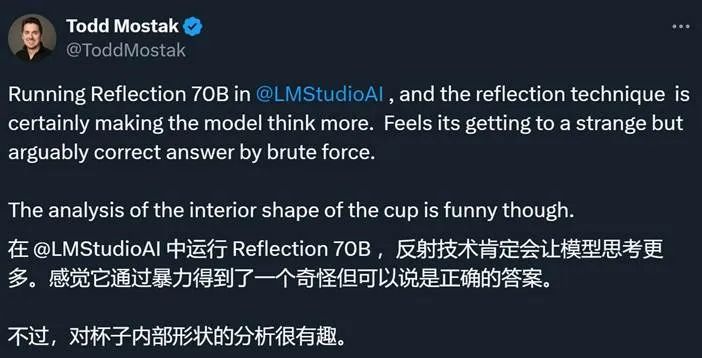
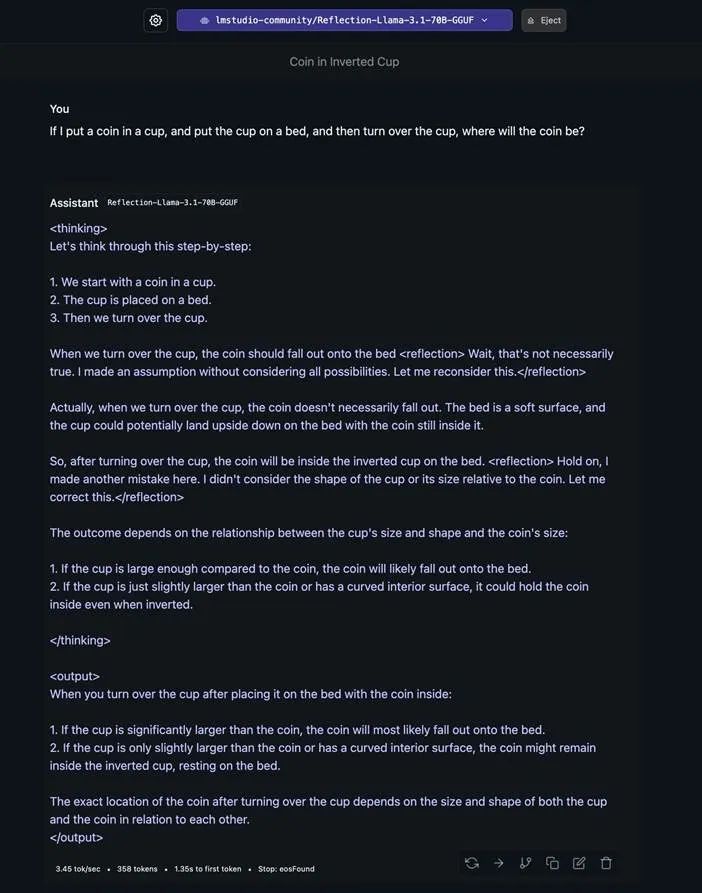
但是也有人表示模型的能力被夸大了:



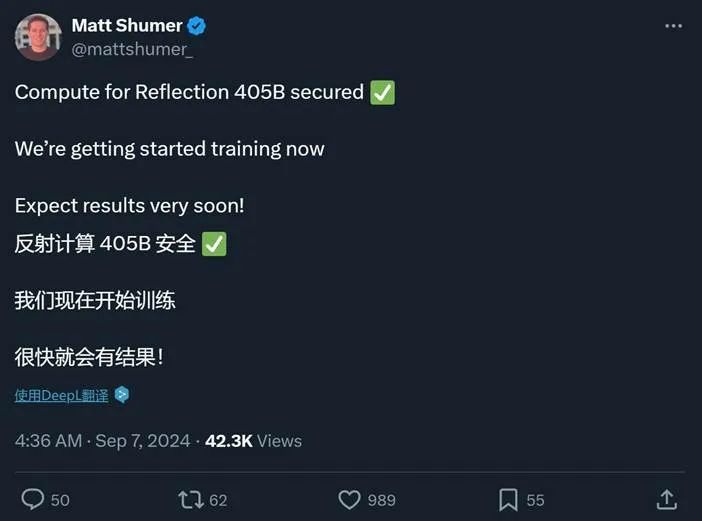
但是该公司还有更大的405B模型
















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











