







目录
二、顶点数组对象(Vertex Array Object,VAO)
最终封装完成之后,我们就可以在application文件中很方便的利用封装好的类快速的生成并调用最后渲染图像了。
4.1关闭了渲染窗口程序却没有自动退出,也就是控制台还在循环中,没有return
编辑4.2在我们着色器渲染的过程中,GetUniformLocation会一直调用
话不多说,我把我看的视频链接贴出来,下面的笔记是由视频学习和自己的补充而来。这次是(11-15)的笔记
跟着这个小哥的教学视频学的(YouTube原视频,科学上网AI字幕) ► http://bit.ly/2lt7ccM
这个是哔哩哔哩网站有人搬运的 ►https://www.bilibili.com/video/BV1MJ411u7Bc/?share_source=copy_web&vd_source=80ce9fa9cc5a33fdc2b9a467859dd047
一、OpenGL uniforms
1.1OpenGL uniforms是什么
在OpenGL中,uniforms是一种特殊类型的变量,它们是在OpenGL着色器程序中声明的全局变量。uniforms的特殊之处在于它们是从应用程序中发送给着色器的常量值,而且它们在整个绘制调用期间保持不变。这使得应用程序能够将数据从CPU(中央处理器)发送到GPU(图形处理器),供着色器在渲染过程中使用。
在OpenGL中,uniforms通常用于向着色器传递变换矩阵、光照参数、纹理单元等与特定渲染场景相关的信息。通过更改uniforms的值,应用程序可以动态地调整渲染效果,而不必修改着色器代码。
在应用程序中,你可以通过OpenGL的API设置这些uniforms的值,以便在渲染时影响着色器的输出。我们可以在画完前后进行更改uniform的值,但是在着色器画的时候,是不能改变的。
1.2怎么使用OpenGL uniforms及其作用
我们来看看例子:
#shader fragment
#version 330 core
layout(location = 0) out vec4 color;
uniform vec4 u_Color;
void main()
{
//color = vec4(1.0, 0.0, 0.0, 1.0);
color = u_Color;
}以上是一个片段着色器的代码,我们在其间引入了一个uniform变量 u_Color。我们可以在OpenGL上下文中通过OpenGL提供的接口中拿到这个变量的索引值然后去设置这个值:
//现在我们需要给着色器中的uniform变量传递值,依然是通过索引,来找到这个变量在GPU中的位置
int location = glGetUniformLocation(shaderID, "u_Color");
//因为有多种原因可能造成uniform变量被更改或者移除等等,比如重写了着色器,拼错了变量,这个时候找不uniform变量就会返回-1,我们做个断言
ASSERT(location == -1);
//把值传进去
GLCall(glUniform4f(location, 0.2f, 0.3f, 0.8f, 1.0f));最关键的是我们想要改变一种颜色,也就是这个值的时候,我们不需要去着色器代码里面修改,而是可以直接通过CPU运行的程序中传入数据,去更改这个值,我们可以动态改变一下,更改部分如下:
//用作变化的Uniform颜色变量
float r = 0.0f;
float increment = 0.05f;
/* Loop until the user closes the window */
while (!glfwWindowShouldClose(window))
{
/* Render here */
glClear(GL_COLOR_BUFFER_BIT);
//我们可以在每次画之前从cpu更改uniform变量的值然后传入,这样就可以有变化的效果了
GLCall(glUniform4f(location, r, 0.3f, 0.8f, 1.0f));
//当我们使用索引缓冲区之后,我们就不是DrawArrays了,而是DrawElement了
GLCall(glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, nullptr));
if (r > 1.0f)
increment = -0.05f;
else if(r < 0.0f)
increment = 0.05f;
r += increment;
/* Swap front and back buffers */
glfwSwapBuffers(window);
/* Poll for and process events */
glfwPollEvents();
}二、顶点数组对象(Vertex Array Object,VAO)
2.1什么是OpenGl顶点数组对象
当我们再绘制不同的顶点数据或者是其他数据时,我们需要重新进行一遍绑定设置等等操作来完成绘制不同,这时候就引出顶点数组对象。
在OpenGL中,顶点数组对象(Vertex Array Object,VAO)是一种OpenGL对象,用于存储顶点数据的状态信息,包括顶点坐标、法线、纹理坐标等。VAO可以看作是一种包含了多个顶点属性配置的容器,使得你可以在绘制时轻松地切换和使用不同的顶点数据。
2.2创建和使用顶点数组对象
使用顶点数组对象的一般步骤如下:
创建顶点数组对象(VAO): 使用 glGenVertexArrays 函数创建一个或多个顶点数组对象的标识符。
GLuint VAO;
glGenVertexArrays(1, &VAO);绑定顶点数组对象: 使用 glBindVertexArray 函数将创建的顶点数组对象绑定到OpenGL上下文。
glBindVertexArray(VAO);创建和绑定顶点缓冲对象(VBO): 将顶点数据存储在顶点缓冲对象中,使用 glGenBuffers 创建 VBO,使用 glBindBuffer 将 VBO 绑定到 GL_ARRAY_BUFFER 目标。
GLuint VBO;
glGenBuffers(1, &VBO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);配置顶点属性指针: 使用 glVertexAttribPointer 函数配置顶点属性指针,告诉OpenGL如何解释顶点数据。
// 位置属性
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);这个例子假设顶点数据包含位置信息,每个顶点包含3个浮点数。
解绑定顶点数组对象和顶点缓冲对象:
使用 glBindVertexArray(0) 和 glBindBuffer(GL_ARRAY_BUFFER, 0) 解绑定VAO和VBO。
glBindVertexArray(0);
glBindBuffer(GL_ARRAY_BUFFER, 0);使用顶点数组对象: 当需要绘制物体时,使用 glBindVertexArray 将相应的顶点数组对象绑定到OpenGL上下文,然后调用渲染函数。
glBindVertexArray(VAO);
// 绘制物体的渲染调用
glDrawArrays(GL_TRIANGLES, 0, 3);
glBindVertexArray(0);顶点数组对象的使用可以帮助你更有效地组织和管理顶点数据,特别是在绘制多个物体或者在渲染循环中多次切换不同的顶点数据时。
其实可能还不太明白,其实使用的时候确实都是要走绑定顶点缓冲区,然后设置顶点的布局等等,但是我们现在把上面一套流程放进了一个叫VAO的对象中,也就是生成绑定它就相当于走完了内部的一套流程,在换顶点数据或者顶点布局的时候,就不需要再写一遍这么麻烦了,相当于是封装了一层,我们后续可以看看其实也是真的要封装一层的,我们可以通过在换顶点布局或者顶点数据的时候体现流程:
老一套的流程是:
| 1.解绑并重新绑定新的着色器程序 | glUseProgram(0); glUseProgram(shaderID); |
| 2.解绑和重新绑定顶点缓冲区 | glBindBuffer(GL_ARRAY_BUFFER, 0); glBindBuffer(GL_ARRAY_BUFFER, buffer)); |
| 3.重新设置顶点的布局 | glEnableVertexAttribArray(0); glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(float) * 2, 0); |
| 4.绑定我们的索引缓冲区 | glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo)); |
| 5.绘制调用 | glDrawElements |
引入VAO之后,我们要更改数据就变成了这样:
| 1.解绑并重新绑定新的着色器程序 | glUseProgram(0); glUseProgram(shaderID); |
| 2.绑定顶点数组(包含了绑定顶点缓冲区,设置顶点的布局,方便直接绑定别的,可以切换) | glBindVertexArray(vao); |
| 3.绑定索引缓冲 | glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo); |
| 4.绘制调用 | glDrawElements |
其中管理顶点数组对象的功能和逻辑,我们需要封装一套比较好的类专业就可以方便操作复杂的渲染对象了。
2.3VAO是否必须要创建
另外这个顶点数组对象对于OpenGL是强制性的,因为即使我们没有创建它,还是走的老一套流程,其实状态还是由顶点数组对象来维护的,这里提一下如果我们不使用VAO会遇到的问题:
在OpenGL上下文中,我们其实可以我们选择使用配置,然后选择用什么OpenGL的版本,其中就有配置文件的选择设置
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);其中兼容性配置文件(GLFW_OPENGL_COMPAT_PROFILE)和核心配置文件(GLFW_OPENGL_CORE_PROFILE)运行区别是兼容性配置文件会使VAO Object 0 为默认对象,就是即使不创建也能有个默认的,但是核心配置文件就不会,如果不创建就会报错失败,所以我们在这种情况下就必须要自己创建了。
当然这个VAO还有展开的说法,NVIDIA有关论文建议并不要使用VAO,OPENGL则规范建议使用VAO,而这些需要一些测试才能真正知道实际性能,这些如果要展开可以自己去看看有关的信息,探索一下实际的影响。
2.4VAO是在哪里被绑定的
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(float) * 2, 0);在这个设置布局的函数代码中第一个索引,就是告诉vao这是第几个缓冲区的,也就是我们可以靠一个vao操作多个缓冲区,这样就不用反复了也可以创建多个VAO对应不同的缓冲区和不同的顶点规格,每次就换绑一个vao就行,可以视情况而定,可以混合使用,随机应变。
三、抽象与封装
接下来我们看到一个main里面写了太多的代码了,这显然不是c++的风格,所以我们开始抽象这些步骤中的一些东西,然后方便调用。下面我会贴出代码,代码中我基本都注释了意义以及函数所要做的内容,头文件和cpp文件一起,注意区分。
封装之后的文件暂为如下结构:
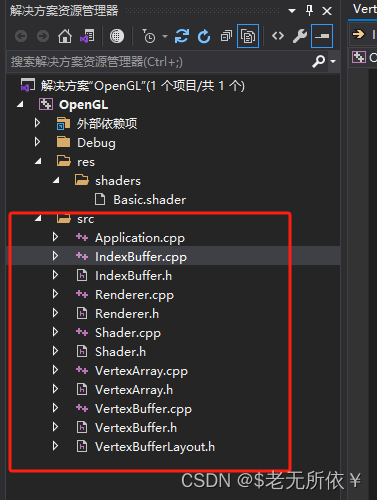
3.1 Renderer渲染器类
现在还没有添加渲染器类和一些逻辑代码,先把我们需要用到的有关渲染的全局定义和方法放入,比如宏和打印错误函数等等:
#pragma once
#include <GL/glew.h>
#include <iostream>
/*渲染器*/
#define ASSERT(x) if(!x) __debugbreak();
//该宏用作自动包裹你要监控错误的函数,但还有些许的不足可以改善
#define GLCall(x) GLClearError();\
x;\
ASSERT(GLLogCall(#x, __FILE__, __LINE__));
//清除OpenGL报错的函数
void GLClearError();
//获取OpenGL错误信息的函数
bool GLLogCall(const char* function, const char* file, const int line);
#include "Renderer.h"
//清除OpenGL报错的函数
void GLClearError()
{
//get一次就清除一条,一直get到为0条错误为止
while (glGetError());
}
//获取OpenGL错误信息的函数
bool GLLogCall(const char* function, const char* file, const int line)
{
while (GLenum error = glGetError())
{
std::cout << "[OpenGL Error] (" << error << ")"
<< "Function:" << function
<< "file Name(" << file << ")"
<< "line(" << line << ")" << std::endl;
return false;
}
return true;
}
3.2 Shader着色器类
我们把动态从文件加载着色器代码编译然后创建着色器的整个过程都封装一下
#pragma once
#include <iostream>
#include <fstream>
#include <sstream>
#include <GL/glew.h>
#include <unordered_map>
//着色器类型的枚举
enum class SHADERTYPE
{
NONE = -1,
VERTEXSHADER = 0,
FRAGMENTSHADER = 1
};
//储存着色器资源代码的结构体
struct shaderProgramSource
{
std::string VertexSource;
std::string FragmentSource;
};
class Shader
{
private:
std::string m_FilePath;
unsigned int m_shaderID;
unsigned int m_RendererID;
// 为uniform变量创建缓存
std::unordered_map<std::string, unsigned int> m_UniformLocationCache;
public:
Shader(const std::string& filepath);
~Shader();
void Bind() const;
void UnBind() const;
//设置一个uniform变量
void SetUniform4f(const std::string& name, float v0, float v1, float v2, float v3);
private:
//获取uniform变量的储存位置
unsigned int GetUniformLocation(const std::string& name);
unsigned int CompileShader(unsigned int type, const std::string& source);
unsigned int CreateShader(const std::string& vertexShader, const std::string& fragmentShader);
};
#include "Shader.h"
#include "Renderer.h"
//动态划分一个文件中多个Shader源码的函数
shaderProgramSource ParseShader(const std::string& filePath)
{
std::fstream stream(filePath);
std::string line;
std::stringstream ss[2];
SHADERTYPE type = SHADERTYPE::NONE;
while (getline(stream, line))
{
if (line.find("#shader") != std::string::npos)
{
if (line.find("vertex") != std::string::npos)
// this is vertexshader parse
type = SHADERTYPE::VERTEXSHADER;
else if ((line.find("fragment") != std::string::npos))
// this is fragmentshader parse
type = SHADERTYPE::FRAGMENTSHADER;
}
else
{
ss[(int)type] << line << '\n';
}
}
return { ss[0].str(), ss[1].str() };
}
Shader::Shader(const std::string& filepath)
:m_FilePath(filepath), m_RendererID(0)
{
shaderProgramSource source = ParseShader(m_FilePath);
std::cout << "VertexShader" << std::endl;
std::cout << source.VertexSource << std::endl;
std::cout << "FragmentShader" << std::endl;
std::cout << source.FragmentSource << std::endl;
m_RendererID = CreateShader(source.VertexSource, source.FragmentSource);
GLCall(glUseProgram(m_RendererID));
}
Shader::~Shader()
{
GLCall(glDeleteProgram(m_RendererID));
}
void Shader::Bind() const
{
GLCall(glUseProgram(m_RendererID));
}
void Shader::UnBind() const
{
GLCall(glUseProgram(0));
}
void Shader::SetUniform4f(const std::string& name, float v0, float v1, float v2, float v3)
{
GLCall(glUniform4f(GetUniformLocation(name), v0, v1, v2, v3));
}
unsigned int Shader::GetUniformLocation(const std::string& name)
{
//遍历找,如果找到就返回存储的location,找不到才去glGetUniformLocation获取
if (m_UniformLocationCache.find(name) != m_UniformLocationCache.end())
return m_UniformLocationCache[name];
//现在我们需要给着色器中的uniform变量传递值,依然是通过索引,来找到这个变量在GPU中的位置
GLCall(int location = glGetUniformLocation(m_RendererID, name.c_str()));
//因为有多种原因可能造成uniform变量被更改或者移除等等,比如重写了着色器,拼错了变量,这个时候找不到uniform变量就会返回-1,我们做个打印
if (location == -1)
std::cout << "Uniform Not Exist : " << name << std::endl;
m_UniformLocationCache[name] = location;
return location;
}
unsigned int Shader::CompileShader(unsigned int type, const std::string& source)
{
unsigned int id = glCreateShader(type);
const char* src = source.c_str();
// shader
// Specifies the handle of the shader object whose source code is to be replaced.
// count
// Specifies the number of elements in the stringand length arrays.
// string
// Specifies an array of pointers to strings containing the source code to be loaded into the shader.
// length
// Specifies an array of string lengths.
glShaderSource(id, 1, &src, nullptr);
glCompileShader(id);
// 这里讲述如何从GL接口中拿到参数值以及抛出错误,因为有些gl接口是没有返回值的
int result;
//i是id,v是来自于glEnum的参数,以及一个接收结果的参数
glGetShaderiv(id, GL_COMPILE_STATUS, &result);
if (result == GL_FALSE)
{
int length;
glGetShaderiv(id, GL_INFO_LOG_LENGTH, &length);
//这里动态分配一个char数组
char* message = (char*)alloca(length * sizeof(char));
glGetShaderInfoLog(id, length, &length, message);
std::cout << "failed to compileShader" <<
(type == GL_VERTEX_SHADER ? "VertexShader" : "fragmentShader") << std::endl;
std::cout << message << std::endl;
glDeleteShader(id);
return 0;
}
return id;
}
unsigned int Shader::CreateShader(const std::string& vertexShader, const std::string& fragmentShader)
{
//typedef unsigned int GLuint;
//这里我们知道,其实OpenGL定义了一系列自己的类型,
//可以快速调用,但这里还是用纯C++的类型来使用
unsigned int program = glCreateProgram();
unsigned int vs = CompileShader(GL_VERTEX_SHADER, vertexShader);
unsigned int fs = CompileShader(GL_FRAGMENT_SHADER, fragmentShader);
glAttachShader(program, vs);
glAttachShader(program, fs);
glLinkProgram(program);
glValidateProgram(program);
glDeleteShader(vs);
glDeleteShader(fs);
return program;
}3.3 VBO及VertexBuffer顶点缓冲区类
#pragma once
class VertexBuffer
{
public:
VertexBuffer(const void* data, unsigned int size);
~VertexBuffer();
void Bind() const;
void UnBind() const;
private:
//渲染器ID
unsigned int m_RendererID;
};
#include "VertexBuffer.h"
#include "Renderer.h"
VertexBuffer::VertexBuffer(const void* data, unsigned int size)
{
GLCall(glGenBuffers(1, &m_RendererID));
//声明之后需要绑定,因为在GPU中的缓冲区都是有编号的,或者说是有管理的
GLCall(glBindBuffer(GL_ARRAY_BUFFER, m_RendererID));
//现在要给一个缓冲区塞数据,每个接口函数都可以通过说明文档来查看参数的意义和使用
GLCall(glBufferData(GL_ARRAY_BUFFER, size, data, GL_STATIC_DRAW));
}
VertexBuffer::~VertexBuffer()
{
GLCall(glDeleteBuffers(1, &m_RendererID));
}
void VertexBuffer::Bind() const
{
GLCall(glBindBuffer(GL_ARRAY_BUFFER, m_RendererID));
}
void VertexBuffer::UnBind() const
{
GLCall(glBindBuffer(GL_ARRAY_BUFFER, 0));
}
3.4 VertexBufferLayout顶点布局类
#pragma once
#include "GL/glew.h"
#include <vector>
#include "Renderer.h"
//我们需要封装这个类,来更好的设置布局,可以看到想要调用glVertexAttribPointer函数,我们要传入参数如下
//index:我们从第几个顶点开始访问
//size:一个顶点属性值里面有几个数值
//type:每个值的数据类型
//normalized:是否要转化为统一的值
//stride:步幅 每个顶点属性值的大小,就是到下一个顶点的开始的字节偏移量。
//pointer:在开始访问到顶点属性值的时候开始的指针位置(注意和Index的区别)
//这就是这个类要做的,可以快速地push你想要的布局,存入std::vector<VertexBufferElement> m_Elements;中
struct VertexBufferElement
{
unsigned int type;
unsigned int count;
unsigned char normalized;
static unsigned int GetSizeOfType(unsigned int type)
{
switch (type)
{
case GL_FLOAT: return 4;
case GL_UNSIGNED_INT: return 4;
case GL_UNSIGNED_BYTE: return 1;
}
ASSERT(false)
return 0;
}
};
class VertexBufferLayout
{
private:
std::vector<VertexBufferElement> m_Elements;
unsigned int m_Stride;
public:
VertexBufferLayout()
:m_Stride(0) {};
/*
这是一个通用的模板函数 Push,它接受一个模板类型 T 和一个整数 count。
在函数体内,有一个 static_assert(false) 语句,这个语句会在编译时产生一个错误,
意味着该通用模板函数不能被使用。这是因为通用模板没有实现,
而是在特定类型的特化版本中实现。也就是使用的时候必须要标出所push的内容是什么类型
*/
template<typename T>
void Push(unsigned int count)
{
static_assert(false);
}
/*
template<> 是对 C++ 模板的特化语法。
在这里,它表示对 template<typename T>
这个通用模板的特定类型的特化版本。
*/
template<>
void Push<float>(unsigned int count)
{
m_Elements.push_back({ GL_FLOAT, count, GL_FALSE });
m_Stride += count * VertexBufferElement::GetSizeOfType(GL_FLOAT);
}
template<>
void Push<unsigned int>(unsigned int count)
{
m_Elements.push_back({ GL_UNSIGNED_INT, count, GL_FALSE });
m_Stride += count * VertexBufferElement::GetSizeOfType(GL_UNSIGNED_INT);
}
template<>
void Push<unsigned char>(unsigned int count)
{
m_Elements.push_back({ GL_UNSIGNED_BYTE, count, GL_TRUE });
m_Stride += count * VertexBufferElement::GetSizeOfType(GL_UNSIGNED_BYTE);
}
//第一个const表示返回的对象为const常量对象,不能更改
//第二个const表示一个约束,在该函数内部,不允许修改对象的成员变量
inline const std::vector<VertexBufferElement> GetElements() const { return m_Elements; }
inline unsigned int GetStride() const { return m_Stride; }
};
3.5 VAO及VertexArray顶点阵列类
一个顶点数组需要做的是将一个顶点缓冲区与某种顶点布局绑定起来。
顶点阵列类需要实现的功能就是 把任意一个顶点缓冲区与任意顶点布局绑定,动态的进行。然后还能在其间添加索引缓冲区,而且抽象还可以让数据能从cpu动态的传入gpu,这样能处理数据大的情况下cpu和gpu各司其职,发挥各自所长
#pragma once
#include "VertexBuffer.h"
#include "VertexBufferLayout.h"
//顶点阵列类:
class VertexArray
{
private:
unsigned int m_RendererID;
public:
VertexArray();
~VertexArray();
void Bind() const;
void UnBind() const;
/*我们拿到顶点缓冲,然后绑定,再给入布局,即封装起来*/
void AddBuffer(const VertexBuffer& vb, const VertexBufferLayout& layout);
};
#include "VertexArray.h"
#include "Renderer.h"
VertexArray::VertexArray()
{
//glGenVertexArrays生产一个VertexArray,通过成员变量m_RendererID接出来,给绑定函数使用
GLCall(glGenVertexArrays(1, &m_RendererID));
}
VertexArray::~VertexArray()
{
GLCall(glDeleteVertexArrays(1, &m_RendererID));
}
void VertexArray::Bind() const
{
GLCall(glBindVertexArray(m_RendererID));
}
void VertexArray::UnBind() const
{
GLCall(glBindVertexArray(0));
}
void VertexArray::AddBuffer(const VertexBuffer& vb, const VertexBufferLayout& layout)
{
Bind();
vb.Bind();
//从VertexBufferLayout拿到所需参数,而那些参数的由来就是cpu操作存储的了
const auto& elements = layout.GetElements();
unsigned int offset = 0;
for (unsigned int i = 0; i < elements.size(); i++)
{
const auto& element = elements.at(i);
//可用的顶点数组索引
GLCall(glEnableVertexAttribArray(i));
//index:我们从第几个顶点开始访问
//size:一个顶点属性值里面有几个数值
//type:每个值的数据类型
//normalized:是否要转化为统一的值
//stride:步幅 每个顶点属性值的大小,就是到下一个顶点的开始的字节偏移量。
//pointer:在开始访问到顶点属性值的时候开始的指针位置(注意和Index的区别)
GLCall(glVertexAttribPointer(i, element.count, element.type,
element.normalized, layout.GetStride(), (const void*)offset));
offset += element.count * VertexBufferElement::GetSizeOfType(element.type);
}
}这样我们就完成了顶点阵列类的封装了,这样如果我们一个飞机的顶点数据进来,我们选中门,选中机翼,只需要创建不同的VertexBufferLayout对象就行了,布局对象就会取出所要渲染的顶点,然后进行着色器渲染,十分的动态。
3.6 IndexBuffer索引缓冲区类
封装好的索引缓冲区个数需要输出,是因为顶点缓冲区就是存放所有顶点信息的,而我们知道,为了空间节约,重复顶点用索引缓冲区来调度,这样只需要在画每一块不同但是有重复顶点的时候,调用出来并知道顶点个数,就可以方便后续使用和渲染了
#pragma once
class IndexBuffer
{
public:
IndexBuffer(const unsigned int* data, unsigned int count);
~IndexBuffer();
//绑定函数均为const函数,即不能修改成员变量
void Bind() const;
void UnBind() const;
//获取索引缓冲区顶点个数,后续需要使用
inline unsigned int GetCount() const { return m_Count; }
private:
//渲染器ID
unsigned int m_RendererID;
unsigned int m_Count;
};
#include "IndexBuffer.h"
#include "Renderer.h"
IndexBuffer::IndexBuffer(const unsigned int* data, unsigned int count)
:m_Count(count)
{
ASSERT(sizeof(unsigned int) == sizeof(GLuint));
//这里声明一个索引缓冲区
GLCall(glGenBuffers(1, &m_RendererID));
//声明之后需要绑定,因为在GPU中的缓冲区都是有编号的,或者说是有管理的,GL_ELEMENT_ARRAY_BUFFER用到这个枚举名
GLCall(glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_RendererID));
//现在要给一个缓冲区塞数据,每个接口函数都可以通过说明文档来查看参数的意义和使用
GLCall(glBufferData(GL_ELEMENT_ARRAY_BUFFER, count * sizeof(unsigned int), data, GL_STATIC_DRAW));
}
IndexBuffer::~IndexBuffer()
{
GLCall(glDeleteBuffers(1, &m_RendererID));
}
void IndexBuffer::Bind() const
{
GLCall(glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_RendererID));
}
void IndexBuffer::UnBind() const
{
GLCall(glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, 0));
}
最终封装完成之后,我们就可以在application文件中很方便的利用封装好的类快速的生成并调用最后渲染图像了。
#include <GL/glew.h>
#include <GLFW/glfw3.h>
#include <iostream>
#include <fstream>
#include <sstream>
#include "Renderer.h"
#include "VertexBuffer.h"
#include "IndexBuffer.h"
#include "VertexArray.h"
#include "Shader.h"
int main()
{
//std::cout << "Hello OpenGL" << std::endl;
//std::cin.get();
GLFWwindow* window;
/* Initialize the library */
if (!glfwInit())
return -1;
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
/* Create a windowed mode window and its OpenGL context */
window = glfwCreateWindow(640, 480, "Hello World", NULL, NULL);
if (!window)
{
glfwTerminate();
return -1;
}
/* Make the window's context current */
glfwMakeContextCurrent(window);
//设置一些框架因素
glfwSwapInterval(2);
if (glewInit() != GLEW_OK)
std::cout << "GLEWInit ERROR!" << std::endl;
std::cout << "OpenGL的版本是:" << glGetString(GL_VERSION) << std::endl;
{
//声明一个float数组,顶点属性列表
float positions[] = {
-0.5f, -0.5f, //0
0.5f, -0.5f, //1
0.5f, 0.5f, //2
-0.5f, 0.5f //3
};
unsigned int indices[]{
0,1,2,
2,3,0
};
//通过封装的顶点阵列类来完成绑定缓冲区以及设置顶点布局
VertexArray va;
//通过封装好的VertexBuffer类进行上述操作
VertexBuffer vb(positions, 4 * 2 * sizeof(float));
//声明一个布局对象,然后写入布局的参数,操作顶点阵列类中的AddBuffer,完成自动绑定操作
VertexBufferLayout vlayout;
vlayout.Push<float>(2);
va.AddBuffer(vb, vlayout);
//通过封装好的IndexBuffer类进行上述操作
IndexBuffer ib(indices, 6);
//通过封装好的着色器类来创建着色器
Shader shader("res/shaders/Basic.shader");
shader.SetUniform4f("u_Color", 0.2f, 0.3f, 0.8f, 1.0f);
//解除绑定的顶点缓冲区和着色器程序
va.UnBind();
shader.UnBind();
vb.UnBind();
ib.UnBind();
//用作变化的Uniform颜色变量
float r = 0.0f;
float increment = 0.05f;
/* Loop until the user closes the window */
while (!glfwWindowShouldClose(window))
{
/* Render here */
glClear(GL_COLOR_BUFFER_BIT);
//重新绑定新的缓冲区和着色器程序
shader.Bind();
//当引入了VAO之后,就不需要再绑定Buffer和指定属性了,直接绑定VAO就行了
GLCall(va.Bind());
GLCall(ib.Bind());
//我们可以在每次画之前从cpu更改uniform变量的值然后传入,这样就可以有变化的效果了
GLCall(shader.SetUniform4f("ucolor", r, 0.3f, 0.8f, 1.0f));
//当我们使用索引缓冲区之后,我们就不是DrawArrays了,而是DrawElement了
GLCall(glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, nullptr));
if (r > 1.0f)
increment = -0.05f;
else if (r < 0.0f)
increment = 0.05f;
r += increment;
/* Swap front and back buffers */
glfwSwapBuffers(window);
/* Poll for and process events */
glfwPollEvents();
}
//glDeleteProgram(shaderID);
}
glfwTerminate();
return 0;
}四、封装过程中遇到的问题
在这个封装的过程中我们遇到了两个问题:
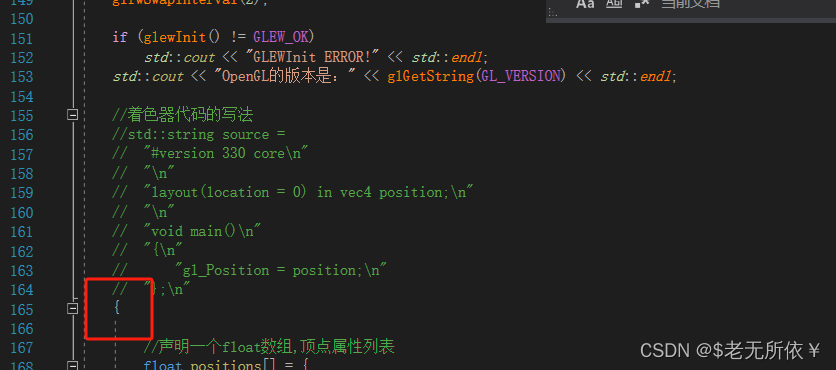
4.1关闭了渲染窗口程序却没有自动退出,也就是控制台还在循环中,没有return
我们需要用大括号把glew初始化之后的到glfwTerminate之前的代码括起来,这里应该是OpenGL的上下文中,需要有循环标志,但是现在在glfwTerminate结束之前并没有结束循环的标志的原因(原理可能不准确)
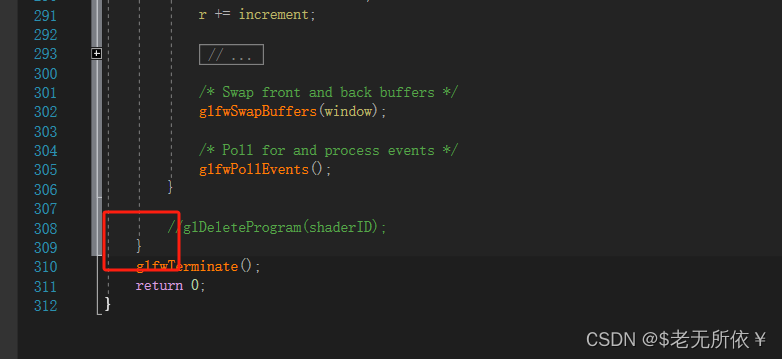
4.2在我们着色器渲染的过程中,GetUniformLocation会一直调用
因为在渲染的过程中,我们一直在而此时我们着色器程序一直在获取变量的索引,好更新其只,但是我们其实只需要开始给值就行了,所以需要引出一个缓存来存贮一下查出来的location,避免反复寻找。
// 为uniform变量创建缓存
std::unordered_map<std::string, unsigned int> m_UniformLocationCache;
//遍历找,如果找到就返回存储的location,找不到才去glGetUniformLocation获取
if (m_UniformLocationCache.find(name) != m_UniformLocationCache.end())
return m_UniformLocationCache[name];这里多嘴提一句std::map 和 std::unordered_map
std::map 和 std::unordered_map 是 C++ 标准库中的两个关联容器,用于实现键-值(key-value)对的存储和检索。它们之间的主要区别在于底层实现和性能特征。
底层实现:
std::map: 基于红黑树实现的有序关联容器。红黑树是一种自平衡的二叉搜索树,它保持了元素的有序性,使得元素按照键的顺序存储。
std::unordered_map: 基于哈希表实现的无序关联容器。哈希表使用哈希函数将键映射到桶(buckets),从而实现快速的元素查找。
性能特征:
std::map: 由于采用了红黑树的有序性,std::map 提供了按键有序存储的特性,但在插入和查找操作中可能略微慢于哈希表。
std::unordered_map: 由于采用了哈希表,std::unordered_map 在插入和查找操作上通常更快,但不保证元素的顺序。
元素顺序:
std::map: 元素按键的比较顺序有序存储。
std::unordered_map: 元素没有明确定义的顺序,通常按照哈希函数散列的结果分布。
查找复杂度:
std::map: 插入、删除和查找操作的平均复杂度是 O(log n),其中 n 是元素的数量。
std::unordered_map: 插入、删除和查找操作的平均复杂度是 O(1),但最坏情况下可能是 O(n)。
以上就是我们这一次的学习总结了,有什么问题可以在评论区留言一起讨论,Thanks。

















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









