






CVPR2024
会议之眼 快讯
会议介绍
2024 年 CVPR (Computer Vision and Pattern Recogntion Conference) 即国际计算机视觉与模式识别会议,于6月17日至21日正在美国西雅图召开。CVPR是计算机视觉和模式识别领域的顶级会议之一。与ICCV和ECCV并称为计算机领域的的三大顶会。它是CCF(中国计算机协会)和CE(会议之眼)评级都为A类的会议。

会议地点介绍
西雅图,一个融合了自然美景与都市活力的美国城市,以其清新的空气、繁荣的科技产业和多样的艺术氛围吸引着世界的目光。这里不仅有迷人的海滨风光和雄伟的山脉,还有充满活力的市中心和丰富的文化体验。特约小编也是趁着这次大会领略了西雅图的迷人风光。这里的美景令人心旷神怡,仿佛置身于一幅动人的画卷之中。


重要数据
根据CVPR官方的最新公告,CVPR 2024已经成为该会议历史上规模最大、参与人数最多的一届。初步统计显示,参会人数已突破一万两千人。另外,本次会议汇聚了谷歌、微软、英伟达、腾讯等科技巨头,它们不仅在多个论文发表中展示了自己的研究成果,还主办了一系列研讨会和教程,极大地丰富了会议内容。以下是特约小编从现场发回的照片和视频,让我们一起领略这场科技盛会的热情和活力吧!


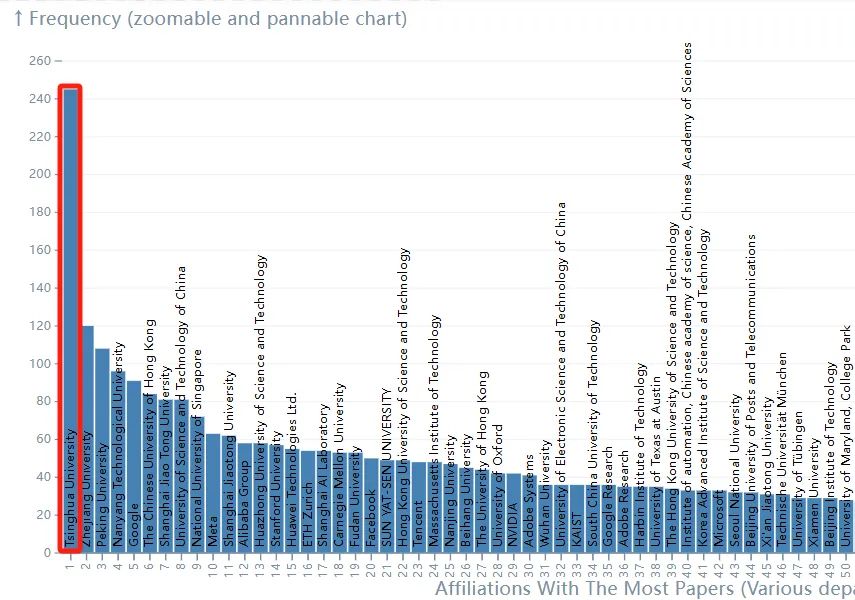
清华大学领跑CVPR 2024论文接收榜
CVPR 2024的论文接收数量统计中,清华大学以显著的数量优势位居榜首,其论文接收数量不仅远超排名第十四的斯坦福大学和排名第二十四的麻省理工学院,也领先于在榜单上位列第五的科技巨头谷歌,展现了稳健的学术贡献。这一成绩反映出该校在计算机视觉领域的持续研究努力和学术积累。
会议实况
CVPR 2024 受瞩目的研讨会
在CVPR 2024大会上,Siddhant Bansal等人主持的"First Joint Egocentric Vision (EgoVis) "研讨会广受好评。这场专注于第一人称视角视觉技术的研讨会,成功吸引了众多学者和专家的兴趣,为该领域的研究和应用提供了新的视角和启发。


随着CVPR 2024的隆重启动,一系列精彩的演讲、研讨和竞赛等活动正蓄势待发。小编将不断带来CVPR的前沿消息和深度报道,敬请保持关注,把握每一次深入了解行业前沿的机会。让我们共同见证这场学术盛会所带来的创新火花和思维启迪!

















 6016
6016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









