







Transformer不仅很强大,而且允许扩展到更大的尺寸。
它之所以如此强大,是因为它抛弃了之前广泛采用的循环网络和卷积网络,而采用了一种特殊的结构----注意力机制来建模文本。
它是一个利用注意力机制来提高模型训练速度的模型。
注意力机制
-
注意力机制能够让模型知道图像中不同局部信息的重要性。
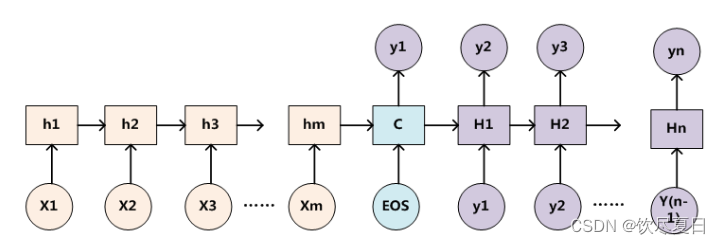
常见的深度学习模型CNN、RNN、LSTM、AE等,其实都可以归为一种通用框架Encoder-Decoder。在文本处理领域,有一类常见的任务就是从一个句子生成另一个句子,比如翻译,其中 x i x_i xi是输入单词的向量表示, y i y_i yi表示输出单词。
S o u r c e = < x 1 , x 2 , . . . x m > Source = <x_1,x_2,...x_m> Source=<x1,x2,...xm>
T a r g e t = < y 1 , y 2 , . . . y n > Target = <y_1, y_2,...y_n> Target=<y1,y2,...yn>
Source经过Encoder生成中间的语义编码C。
C = F ( x 1 , x 2 , . . . x m ) C=F(x_1,x_2,...x_m) C=F(x1,x2,...xm)
C经过Decoder之后,输出翻译后的句子。在循环神经网络中,先根据C生成 y 1 y_1 y1,再基于(C, y 1 y_1 y1)生成 y 2 y_2 y2,依次类推。
y i = G ( C , y 1 , y 2 , . . . , y i − 1 ) y_i=G(C,y_1,y_2,...,y_{i-1}) yi=G(C,y1,y2,...,yi−1)
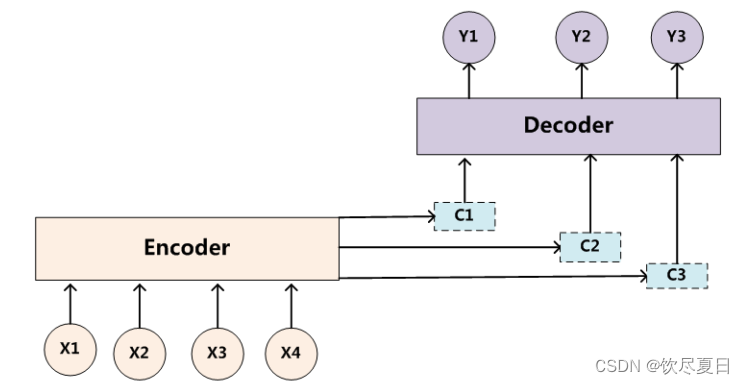
Soft Attention模型
- 传统的循环神经网络中
y
1
、
y
2
、
y
3
y_1、y_2、y_3
y1、y2、y3的计算都是基于同一个C,而Source中不同单词对
y
1
、
y
2
、
y
3
y_1、y_2、y_3
y1、y2、y3的影响是不同的,故这不是最好的方案,由此考虑用不同的权重向量来计算
C
1
、
C
2
、
C
3
C_1、C_2、C_3
C1、C2、C3
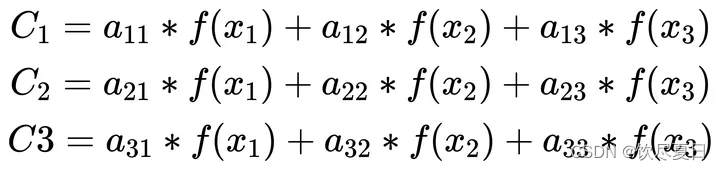
(
a
11
,
a
12
,
a
13
)
、
(
a
21
,
a
22
,
a
23
)
、
(
a
31
,
a
32
,
a
33
)
(a_{11},a_{12},a_{13})、(a_{21},a_{22},a_{23})、(a_{31},a_{32},a_{33})
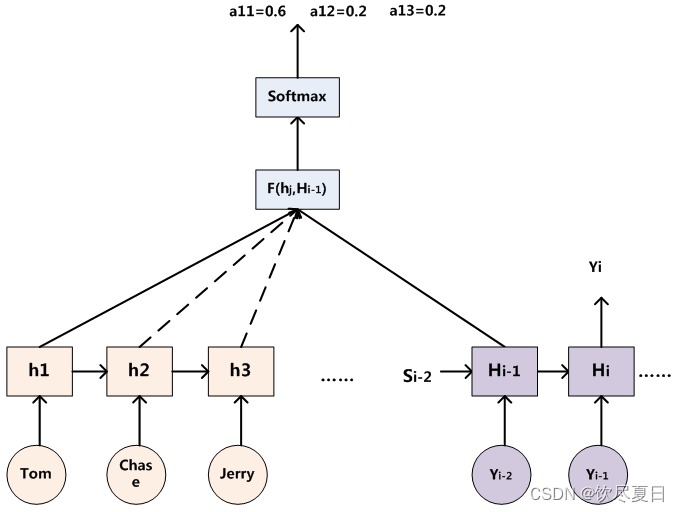
(a11,a12,a13)、(a21,a22,a23)、(a31,a32,a33)的计算方法如下图所示。
模型中:
h
1
=
f
(
T
o
m
)
,
h
2
=
f
(
h
1
,
C
h
a
s
e
)
,
h
3
=
f
(
h
2
,
J
e
r
r
y
)
h_1 = f(Tom),h_2=f(h_1,Chase),h_3=f(h_2,Jerry)
h1=f(Tom),h2=f(h1,Chase),h3=f(h2,Jerry)
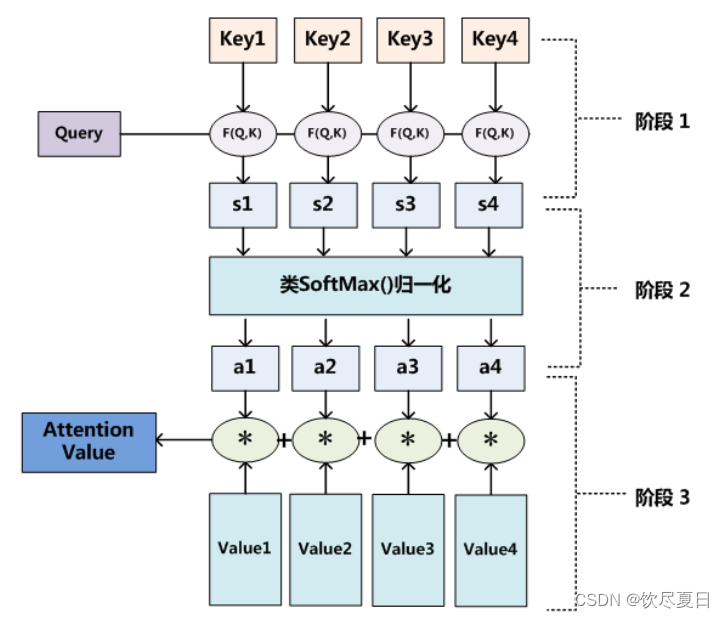
其中F函数的实现方法有多种,比如余弦相似度、MLP等。
Attention机制的本质
- 把Source想象成是内存里的一块存储空间,它里面存储的数据按<Key,Value>存储。给定Query,然后取出相应的内容。这里与一般的hash查询方式不同的是,每个地址都只取一部分内容,然后对所有的Value加权求和。















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









